-
java读取movielens数据txt
各位好,我是菜鸟小明哥,movielens数据是常见的推荐方面的开源数据集,另一个推荐方面的数据集是新闻MIND,本文将从movielens再次出发,做基础的推荐方法,比如基本的基于标题的相似性,word2vector,ALS,等等,以及NLP方面的推荐。
For deep learning QQ Second Group 629530787
I'm here waiting for you
如题,本文只说读取txt文件,java读取及spark读取为rdd
1,测试string基本属性,这样就可以与py对齐了
- //相加及打印字符char
- String ksc="m1k3jd";//new String("939dkkw")
- String bsc ="te102id0";
- String vsc = ksc + bsc;
- System.out.println(vsc);
- for (int ii=0;iiSystem.out.println(vsc.charAt(ii));//相加后返回public static String addString(String a, String b) {// return new String(a+b);return a+b;}//这两种方法都可以,没发现差别
2,java一般读取方法
鉴于java没有办法设置默认参数,就不再重载设置了(再写一遍这个函数),因此不要默认参数了。另外,读取文件可能会有异常(1,找不到文件;2,解码错误),java要求
java: 未报告的异常错误java.io.IOException; 必须对其进行捕获或声明以便抛出
- public static void readTXT(String file,String encoding) {
- File fil=new File(file);
- try {
- InputStreamReader reader = new InputStreamReader(new FileInputStream(fil), encoding);
- BufferedReader buffReader = new BufferedReader(reader);
- if (fil.isFile()&&fil.exists()){
- String line;
- while ((line= buffReader.readLine())!=null){
- System.out.println(line);
- }
- }
- }catch (FileNotFoundException e){
- System.out.println("file not found");
- }catch (UnsupportedEncodingException e) {
- System.out.println("encoding is not right");
- //throw new RuntimeException(e);
- } catch (IOException e) {
- System.out.println("reading file ups error");
- //throw new RuntimeException(e);
- }
- }
当我采用UTF-8进行解码发现并没有报错,我擦,而py则不行,需要"ISO-8859-1"解码。
将上面的打印行注释,其他不变,结果发现并没有上面的catch抛出,而且行数相同。都是3883
3,解析每行的数据:一般方法
最笨我直接split也就行了啊,每行存一个String数组,OJBK
- String vsc3=new String("6::Heat (1995)::Action|Crime|Thriller");
- String res[]=vsc3.split("::");
- for (String resi :res)
- System.out.println(resi);
4, 序列化接口Serializable(可以继承这个,也可自己写)
一般是读取文件(需要预先知道数据存储格式/形式)或者保存数据,转换数据格式之用。
上面2中只是读取了一下,并没有转换格式,下面采用读取每行的细节,
- public static class Serialize{
- private int movieId;
- private String title;
- private String tag;
- public Serialize(){
- }//构造函数
- public Serialize(int movieId,String title,String tag){
- this.movieId=movieId;
- this.title=title;
- this.tag=tag;
- }
- public static Serialize parseSerialize(String string){
- String[] str3=string.split("::");
- int movieId;
- String title,tag;
- movieId = Integer.parseInt(str3[0]);
- title=str3[1];
- tag=str3[2];
- return new Serialize(movieId,title,tag);
- }
- }
使用记录:
- Serialize example = Serialize.parseSerialize(vsc3);
- System.out.println(example.movieId+","+example.title+","+example.tag);
5,spark-rdd读取
注意设置以下环境不然报错,我的是java-18 MacPro,Idea C
螺丝刀那里进去,modify options add VM options,不设置就会报错。
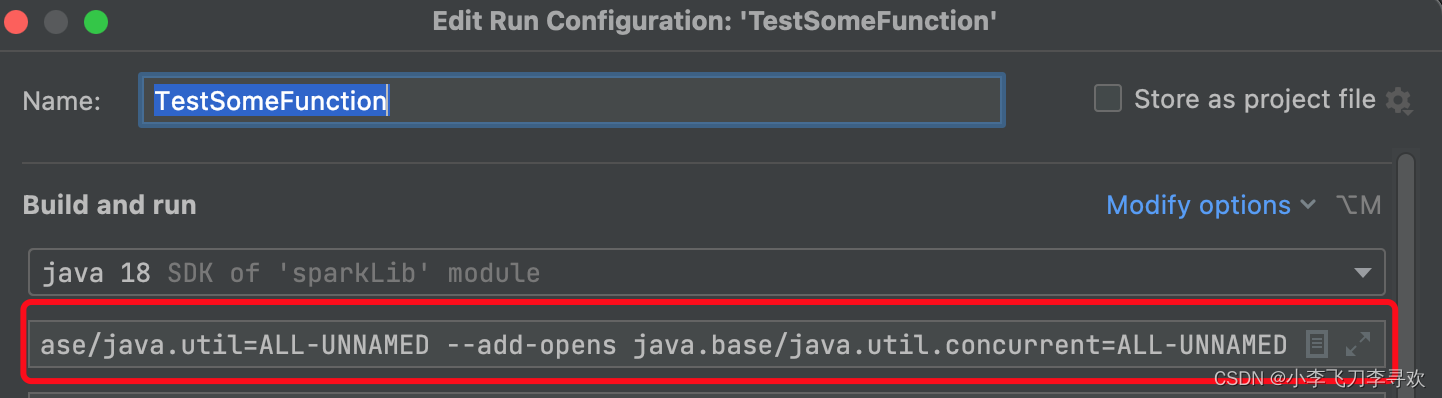
--add-opens java.base/java.lang=ALL-UNNAMED --add-opens java.base/java.lang.reflect=ALL-UNNAMED --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.util.concurrent=ALL-UNNAMED代码如下:也参考了这个资料
4中写的class没有问题,但在spark中如果需要读取列就不行了,因为没有写读取列的方法。如下:不写这方法,spark-rdd读取不到数据
- public int getMovieId3(){
- return movieId;
- }
- public String getTitle3(){
- return title;
- }
- public String getTag3(){
- return tag;
- }
spark读取txt文件代码:
- SparkConf conf = new SparkConf().setAppName("JavaALS001").setMaster("local[*]");
- JavaSparkContext sc = new JavaSparkContext(conf);
- JavaRDD
distFile = sc.textFile(file); - JavaRDD
rdd = distFile.map(new Function - public Serialize call(String s) {
- return Serialize.parseSerialize(s);
- }
- });
- SQLContext sqlContext = new SQLContext(sc);
- Dataset
df = sqlContext.createDataFrame(rdd,Serialize.class);
- df.show(12);
结果如下:列名是不是和上面的方法名字一样

愿我们终有重逢之时,
而你还记得我们曾经讨论的话题。
- 相关阅读:
洛谷 P3128 [USACO15DEC] Max Flow P
Python异常类
三肽Isovaleryl-Val-Val-Sta-乙酯化、120849-36-7
https的加密原理
C++ (Chapter 2)
【图像分类】【深度学习】【Pytorch版本】VggNet模型算法详解
HDU - 2955 - Robberies
vue3全局状态的管理——Pinia
2022年7月系统集成项目管理工程师认证招生简章
MQTT 基础--遗嘱和遗嘱:第 9 部分
- 原文地址:https://blog.csdn.net/SPESEG/article/details/126747206