-
seaborn学习2:displot()
displot()
此函数提供了对多种方法的访问,用于可视化数据的单变量或二变量分布,包括由语义映射和跨多个子图的分面定义的数据子集。
seaborn.displot(data=None, *, x=None, y=None, hue=None, row=None, col=None, weights=None, kind='hist', rug=False, rug_kws=None, log_scale=None, legend=True, palette=None, hue_order=None, hue_norm=None, color=None, col_wrap=None, row_order=None, col_order=None, height=5, aspect=1, facet_kws=None, **kwargs)可以分别使用:
histplot() == (with kind="hist"; the default) kdeplot() == (with kind="kde") ecdfplot() == (with kind="ecdf"; univariate-only)- 1
- 2
- 3
参数:
-
data
输入数据结构。可以是可分配给命名变量的长格式向量集合,也可以是将在内部重塑的宽格式数据集。
参数:
x, y:data中的变量名输入数据的变量;数据必须为数值型。
hue:data中的名称,可选将会产生具有不同颜色的元素的变量进行分组。这些变量可以是类别变量或者数值型变量,尽管颜色映射在后面的情况中会有不同的表现。
size:data中的名称,可选将会产生具有不同尺寸的元素的变量进行分组。这些变量可以是类别变量或者数值型变量,尽管尺寸映射在后面的情况中会有不同的表现。
style:data中的名称,可选将会产生具有不同风格的元素的变量进行分组。这些变量可以为数值型,但是通常会被当做类别变量处理。
data:DataFrame长格式的 DataFrame,每列是一个变量,每行是一个观察值。
row, col:data中的变量名,可选确定网格的分面的类别变量。
col_wrap:int, 可选以此宽度“包裹”列变量,以便列分面跨越多行。与
row分面不兼容。row_order, col_order:字符串列表,可选以此顺序组织网格的行和/或列,否则顺序将从数据对象中推断。
palette:色盘名,列表,或者字典,可选用于
hue变量的不同级别的颜色。应当是color_palette()可以解释的东西,或者将色调级别映射到 matplotlib 颜色的字典。hue_order:列表,可选指定
hue变量层级出现的顺序,否则会根据数据确定。当hue变量为数值型时与此无关。hue_norm:元组或者 Normalize 对象,可选当
hue变量为数值型时,用于数据单元的 colormap 的标准化。如果hue为类别变量则与此无关。sizes:列表、典或者元组,可选当使用
sizes时,用于确定如何选择尺寸。此变量可以一直是尺寸值的列表或者size变量的字典映射。当size为数值型时,此变量也可以是指定最小和最大尺寸的元组,这样可以将其他值标准化到这个范围。size_order:列表,可选指定
size变量层次的表现顺序,不指定则会通过数据确定。当size变量为数值型时与此无关。size_norm:元组或者 Normalize 对象,可选当
size变量为数值型时,用于数据单元的 scaling plot 对象的标准化。legend:“brief”, “full”, 或者 False, 可选用于决定如何绘制坐标轴。如果参数值为“brief”, 数值型的
hue以及size变量将会被用等间隔采样值表示。如果参数值为“full”, 每组都会在坐标轴中被记录。如果参数值为“false”, 不会添加坐标轴数据,也不会绘制坐标轴。kind:string, 可选绘制图的类型,与 seaborn 相关的图一致。可选项为(
scatter及line).height:标量, 可选每个 facet 的高度(英寸)。参见
aspect。aspect:标量, 可选每个 facet 的长宽比,因此“长宽比*高度”可以得出每个 facet 的宽度(英寸)。
facet_kws:dict, 可选以字典形式传给
FacetGrid的其他关键字参数.kwargs:键值对传给后续绘制函数的其他关键字参数。
返回值:
g:FacetGrid返回包含图像的
FacetGrid对象,图像可以进一步调整。具体看官方文档:
http://seaborn.pydata.org/generated/seaborn.displot.html#seaborn.displot
import seaborn as sns %matplotlib inline import numpy as np- 1
- 2
- 3
np.random.seed(1) data = np.random.normal(size=100) sns.displot(x=data)- 1
- 2
- 3

np.random.seed(1) data = np.random.normal(size=100) sns.displot(x=data,kind="hist")- 1
- 2
- 3
np.random.seed(1) data = np.random.normal(size=100) sns.displot(x=data,kind="kde")- 1
- 2
- 3

np.random.seed(1) data = np.random.normal(size=100) sns.displot(x=data,kind="ecdf")- 1
- 2
- 3

np.random.seed(1) data = np.random.normal(size=100) sns.displot(x=data,kind="hist",kde = True,color="red")- 1
- 2
- 3

以自带数据集为例
#企鹅种类 penguins = pd.read_csv("penguins.csv") penguins- 1
- 2
- 3
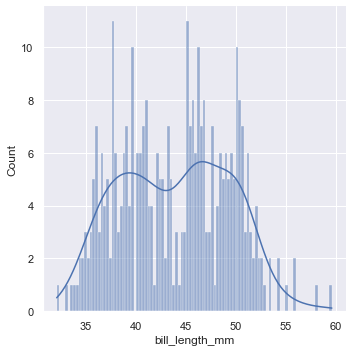
sns.displot(data=penguins,x="bill_length_mm")- 1

sns.displot(data=penguins,x="bill_length_mm",bins = 100)- 1

sns.displot(data=penguins,x="bill_length_mm",bins = 100,kde=True)- 1
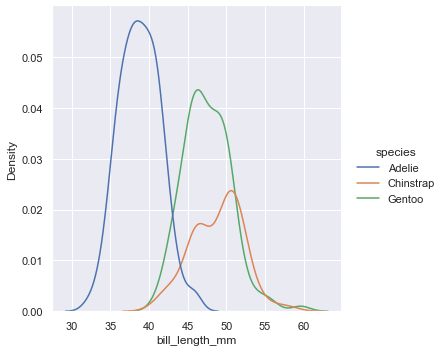
sns.displot(data=penguins,x="bill_length_mm",hue="species")- 1

sns.displot(data=penguins,x="bill_length_mm",hue="species",shrink = 0.7)- 1

sns.displot(data=penguins,x="bill_length_mm",kind="kde")- 1

sns.displot(data=penguins,x="bill_length_mm",kind="kde",hue="species")- 1
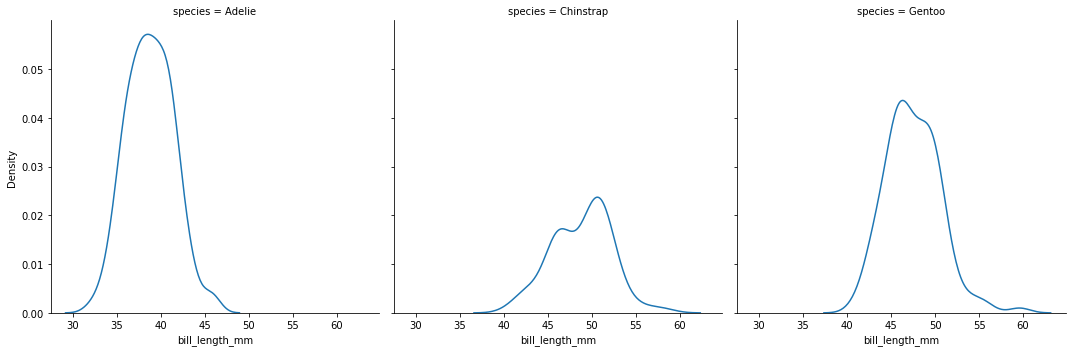
sns.displot(data=penguins,x="bill_length_mm",kind="kde",col="species")- 1
sns.displot(data=penguins,x="bill_length_mm",kind="kde",row="species",col="sex")- 1

-
相关阅读:
go语言并发实战——日志收集系统(四) 利用tail包实现对日志文件的实时监控
Unity/WebGL打包/跨域问题/简单解决“......has been blocked by CORS policy: ......“
一种新的数据聚类启发式优化方法——黑洞算法(基于Matlab代码实现)
Redis 消息队列:构建消息代理的 4 个简单步骤
后端工程师求职实录:二线城市就业攻略与心得分享
SpringCloud 完整版--(Spring Cloud Netflix 体系)
智慧安防视频监控系统EasyCVR平台突然运行异常,是什么原因?
小程序传值对象数值到另一个页面大小限制
合宙Air101 的LCD怎么用Arudino IDE驱动
Git 使用技巧:5个提高效率的命令,不再只会pull和push
- 原文地址:https://blog.csdn.net/weixin_43788986/article/details/126765601