其实模型的参数量好算,但浮点运算数并不好确定,我们一般也就根据参数量直接估计计算量了。但是像卷积之类的运算,它的参数量比较小,但是运算量非常大,它是一种计算密集型的操作。反观全连接结构,它的参数量非常多,但运算量并没有显得那么大。
FLOPs(Floating-point Operations):浮点运算次数,理解为计算量,可以用来衡量算法的复杂度。一个乘法或一个加法都是一个FLOPs
FLOPS(Floating-point Operations Per Second):每秒浮点运算次数,理解为计算速度,是一个衡量硬件性能的指标。
MACCs(multiply-accumulate operations):乘-加操作次数,MACCs 大约是 FLOPs 的一半。将
MAC(Memory Access Cost):内存访问成本
Params:是指模型训练中需要训练的参数总数
注意了:下面的阐述如果没有特别说明,默认都是batch为1。
全连接层
全连接 权重
(目前全连接层已经逐渐被 Global Average Pooling 层取代了) 注意,全连接层的权重参数量(内存占用)远远大于卷积层。
一维卷积层
一维卷积 kernel大小为
输出特征图有
个像素 每个像素对应一个立体卷积核
在输入特征图上做立体卷积卷积出来的;
二维卷积层
卷积层卷积核(Kernel)的高和宽:
- 输出特征图中有
- 每个像素对应一个立体卷积核
其中输出特征图尺寸
那我们现在来计算一下参数量,如果了解卷积的原理,应该也不难算出它的参数量(可能有人会说卷积原理怎么理解,这里推荐一篇写得通俗易懂的文章:https://zhuanlan.zhihu.com/p/77471866
分组卷积
对于尺寸为

图* 标准卷积示意图
分组卷积中,通过指定组数
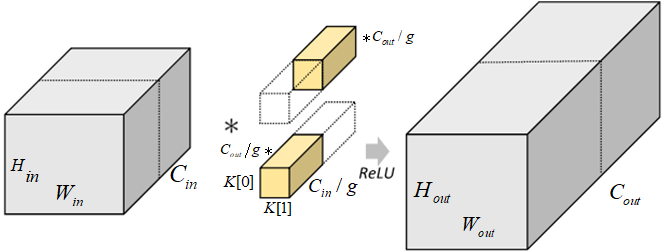
图 分组卷积示意图
使用分组卷积后,参数和计算量则变为:
$$MACCs=(\frac{C_{in}}{g}*K[0]*K[1])*H_{out}·W_{out}*\frac{C_{out}}{g}*g\
=(C_{in}*K[0]·K[1])*H_{out}·W_{out}*C_{out}*\frac{1}{g}$$
深度可分离卷积层
深度可分离卷积是将常规卷积因式分解为两个较小的运算,它们在一起占用的内存更少(权重更少),并且速度更快。深度可分离卷积中,
- 先进行 深度卷积,与常规卷积相似,不同之处在于将输入通道分groups组,groups等于输入通道数。深度卷积输入通道数和输出通道数相等
- 在进行 逐点卷积,也就是1x1卷积

class DepthwiseSeparableConv(nn.Module): def __init__(self, in_channels, out_channels, kernel_size, stride, padding, dilation, bias): super(DepthwiseSeparableConv, self).__init__() # Use `groups` option to implement depthwise convolution depthwise_conv = nn.Conv1d(in_channels, in_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=in_channels, bias=bias) pointwise_conv = nn.Conv1d(in_channels, out_channels, 1, bias=bias) self.net = nn.Sequential(depthwise_conv, pointwise_conv) def forward(self, x): return self.net(x)
标准卷积为:
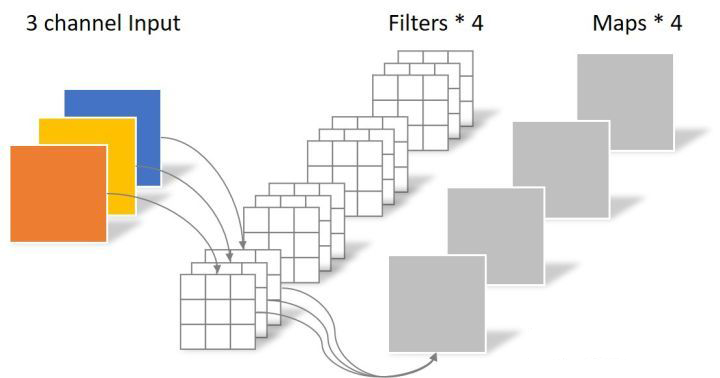
深度卷积,将输入分成
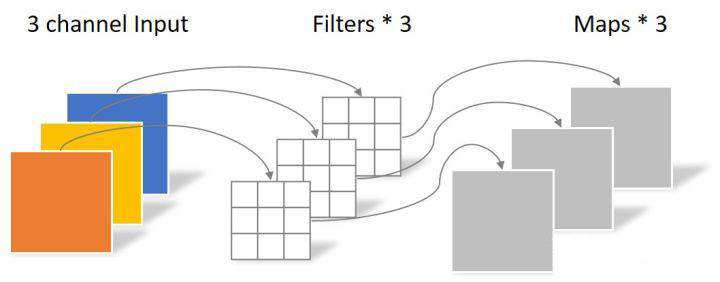
逐点卷积
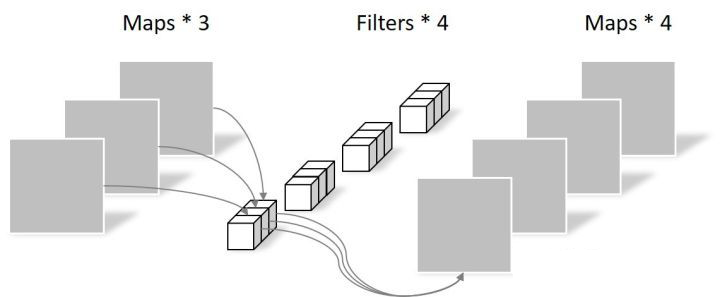
所以深度可分离卷积的参数量和计算量为:
LSTM层
关于LSTM的原理可以参考这一篇文章:循环神经网络(RNN)及衍生LSTM、GRU详解,如果想要算清楚,请务必要看,由于相似内容太多我就不搬移过来了
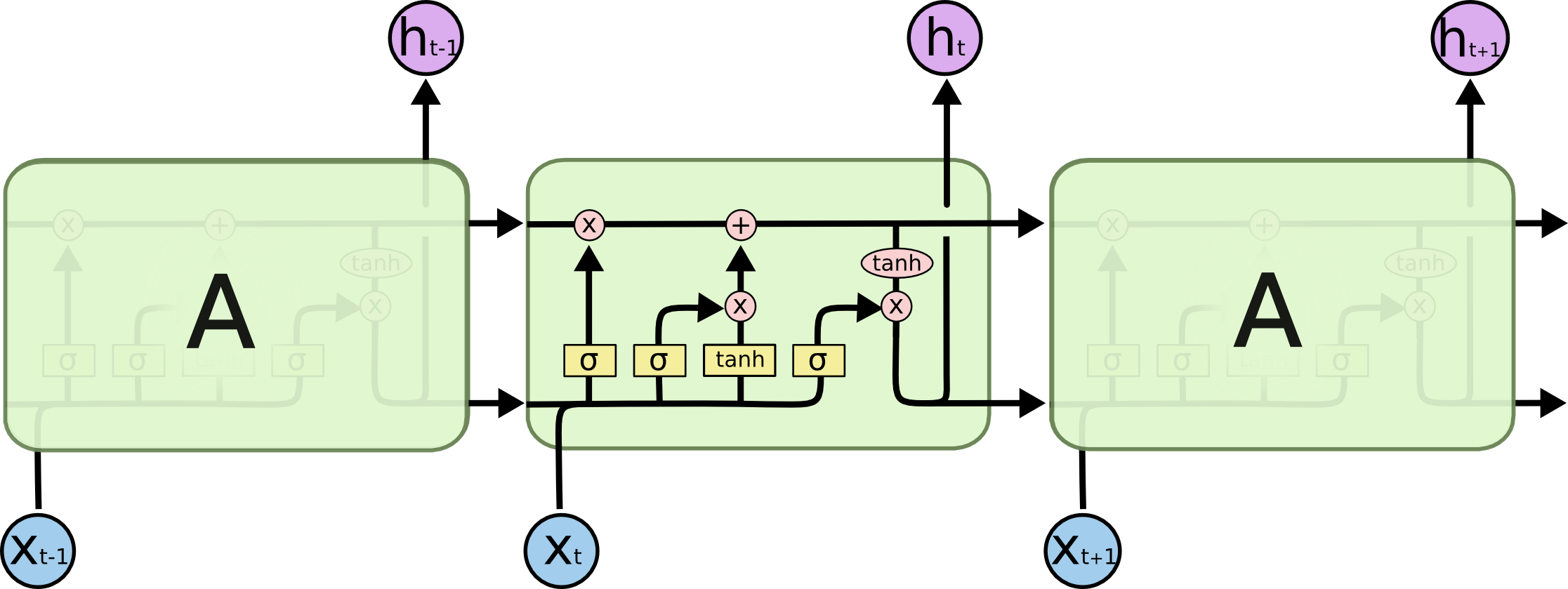
一个time_step的LSTM计算量为:
第三库计算工具
模型参数数量(params):指模型含有多少参数,直接决定模型的大小,也影响推断时对内存的占用量,单位通常为 M,GPU 端通常参数用 float32 表示,所以模型大小是参数数量的 4 倍。
以AlexNet模型为例


import torch import torch.nn as nn import torchvision class AlexNet(nn.Module): def __init__(self,num_classes=1000): super(AlexNet,self).__init__() self.feature_extraction = nn.Sequential( nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding=2,bias=False), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3,stride=2,padding=0), nn.Conv2d(in_channels=96,out_channels=192,kernel_size=5,stride=1,padding=2,bias=False), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3,stride=2,padding=0), nn.Conv2d(in_channels=192,out_channels=384,kernel_size=3,stride=1,padding=1,bias=False), nn.ReLU(inplace=True), nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False), nn.ReLU(inplace=True), nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, padding=0), ) self.classifier = nn.Sequential( nn.Dropout(p=0.5), nn.Linear(in_features=256*6*6,out_features=4096), nn.ReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(in_features=4096, out_features=4096), nn.ReLU(inplace=True), nn.Linear(in_features=4096, out_features=num_classes), ) def forward(self,x): x = self.feature_extraction(x) x = x.view(x.size(0),256*6*6) x = self.classifier(x) return x if __name__ =='__main__': # model = torchvision.models.AlexNet() model = AlexNet() # 打印模型参数 #for param in model.parameters(): #print(param) #打印模型名称与shape for name,parameters in model.named_parameters(): print(name,':',parameters.size())
计算参数量与可训练参数量
def get_parameter_number(model): total_num = sum(p.numel() for p in model.parameters()) trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad) return {'Total': total_num, 'Trainable': trainable_num} total_num, trainable_num = get_parameter_number(model) print("trainable_num/total_num: %.2fM/%.2fM" % (trainable_num / 1e6, total_num / 1e6))
torchsummary
import torchsummary as summary summary.summary(model, (3, 224, 224))
打印结果
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 96, 55, 55] 34,848 ReLU-2 [-1, 96, 55, 55] 0 MaxPool2d-3 [-1, 96, 27, 27] 0 Conv2d-4 [-1, 192, 27, 27] 460,800 ReLU-5 [-1, 192, 27, 27] 0 MaxPool2d-6 [-1, 192, 13, 13] 0 Conv2d-7 [-1, 384, 13, 13] 663,552 ReLU-8 [-1, 384, 13, 13] 0 Conv2d-9 [-1, 256, 13, 13] 884,736 ReLU-10 [-1, 256, 13, 13] 0 Conv2d-11 [-1, 256, 13, 13] 589,824 ReLU-12 [-1, 256, 13, 13] 0 MaxPool2d-13 [-1, 256, 6, 6] 0 Dropout-14 [-1, 9216] 0 Linear-15 [-1, 4096] 37,752,832 ReLU-16 [-1, 4096] 0 Dropout-17 [-1, 4096] 0 Linear-18 [-1, 4096] 16,781,312 ReLU-19 [-1, 4096] 0 Linear-20 [-1, 1000] 4,097,000 ================================================================ Total params: 61,264,904 Trainable params: 61,264,904 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.57 Forward/backward pass size (MB): 9.96 Params size (MB): 233.71 Estimated Total Size (MB): 244.24 ----------------------------------------------------------------
torchstat
from torchstat import stat stat(model, (3, 224, 224)) # Total params: 61,264,904 # ------------------------------------------ # Total memory: 4.98MB # Total MAdd: 1.72GMAdd # Total Flops: 862.36MFlops # Total MemR+W: 244.14MB
thop
from thop import profile input = torch.randn(1, 3, 224, 224) flops, params = profile(model, inputs=(input, )) print(flops, params) # 861301280.0 61264904.0
torchinfo
from torchinfo import summary summary(model, input_size=inputs.shape,)
ptflops
from ptflops import get_model_complexity_info flops, params = get_model_complexity_info(model, (3, 224, 224), as_strings=True, print_per_layer_stat=True) print('Flops: ' + flops) print('Params: ' + params)
复杂度对模型的影响
- 时间复杂度决定了模型的训练/预测时间。如果复杂度过高,则会导致模型训练和预测耗费大量时间,既无法快速的验证想法和改善模型,也无法做到快速的预测。
- 空间复杂度决定了模型的参数数量。由于维度诅咒的限制,模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,这会导致模型的训练更容易过拟合。
- 当我们需要裁剪模型时,由于卷积核的空间尺寸通常已经很小(3x3),而网络的深度又与模型的表征能力紧密相关,不宜过多削减,因此模型裁剪通常最先下手的地方就是通道数。
Inception 系列模型是如何优化复杂度的
Inception V1中的 1*1 卷积降维同时优化时间复杂度和空间复杂度
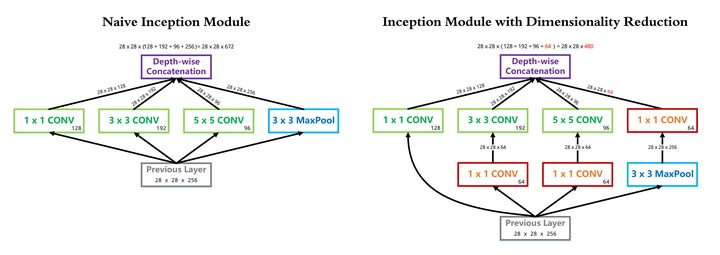
Inception V1中使用 GAP 代替 Flatten
Inception V2中使用 两个3*3卷积级联代替5*5卷积分支
Inception V3中使用 N*1与1*N卷积级联代替N*N卷积
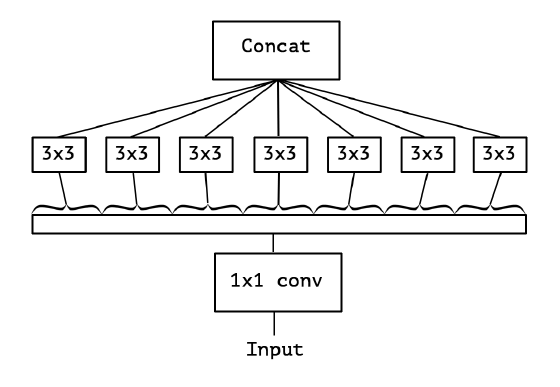
Xception 中使用 深度可分离卷积(Depth-wise Separable Convolution)
参考文献
【知乎】卷积神经网络的复杂度分析
【知乎】神经网络模型复杂度分析
【知乎】深度可分离卷积
作者:凌逆战
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。
本文章不做任何商业用途,仅作为自学所用,文章后面会有参考链接,我可能会复制原作者的话,如果介意,我会修改或者删除。