-
论文阅读 (71):Optimal Margin Distribution Machine for Multi-Instance Learning
1 概述
1.1 题目
2021IJCAI:多示例学习优化间隔分布机 (Optimal margin distribution machine for multi-Instance learning)
1.2 摘要
最近的间隔理论研究表明,间隔分布 (Margin distribution) 对泛化能力的影响重于最小间隔 (Minimal margin)。受此启发,提出了多示例 (Multi-instance learning, MIL) 最优间隔分布机 (ODM),其通过优化间隔分布来鉴别关键实例。进一步扩展随机加速镜像近似方法 (Stochastic accelerated mirror prox method) 来解决该公式化的极小极大问题。
1.3 Bib
@inproceedings{Zhang:2021:23832389, author = {Teng Zhang and Hai Jin}, title = {Optimal margin distribution machine for multi-instance learning}, booktitle = {International Conference on International Joint Conferences on Artificial Intelligence}, pages = {2383--2389}, year = {2021} url = {https://www.ijcai.org/proceedings/2020/0330.pdf} }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2 基础知识
令 X ⊆ R n \mathcal{X}\subseteq\mathbb{R}^n X⊆Rn和 Y = { − 1 , 1 } \mathcal{Y}=\{-1,1\} Y={−1,1}分别表示输入和输出空间。对于任意的 m ≤ 1 m\leq1 m≤1,整数的集合 { 1 , … , m } \{1,\dots,m\} {1,…,m}表示为 [ m ] [m] [m]。与某个正定核 κ \kappa κ关联的特征映射表示为: ϕ : X → H \phi:\mathcal{X}\to\mathbb{H} ϕ:X→H。
2.1 ODM
定义有标记实例 ( x , y ) (\boldsymbol{x},y) (x,y)的间隔 γ ( x , y ) \gamma(\boldsymbol{x},y) γ(x,y)为Sign决策值,即 γ ( x , y ) = y w T ϕ ( x ) \gamma(\boldsymbol{x},y)=y\boldsymbol{w}^T\phi(\boldsymbol{x}) γ(x,y)=ywTϕ(x),其可以作为预测的置信度 (Confidence)。间隔越大,预测的标签也越可信。
众所周知,SVM使用最大边界理论来描绘决策边界,所获得的分割超平面包含少量实例,也称支持向量,余下的实例则是可以忽略的。当噪声实例存在时,学习者可能被误导,从而产生次优决策边界。
与此相应,优化间隔分布是一个更健壮性的策略,其通过探索整个数据集来防止噪声实例的干扰。描述间隔分布最简单的方法是通过第一和第二统计,即间隔均值和方差。此外,同时最大化均值和最小化方差可以产生更严格的泛化边界。优化间隔分布机 (Optimal margin distribution machine, ODM) 被初定义为😮:
min w , γ ‾ , ξ i , ϵ i 1 2 ∥ w ∥ 2 − η γ ‾ + λ m ∑ i ∈ [ m ] ( ξ i 2 + ϵ i 2 ) , s.t. γ ( x i , y i ) ≥ γ ‾ − ξ i , γ ( x i , y i ) ≤ γ ‾ + ϵ i , ∀ i ∈ [ m ] , (1) \tag{1}minw,γ,ξi,ϵi s.t.21∥w∥2−ηγ+mλ∑i∈[m](ξi2+ϵi2),γ(xi,yi)≥γ−ξi,γ(xi,yi)≤γ+ϵi,∀i∈[m],(1)其中 η \eta η喝 λ \lambda λ是正则权衡参数, γ ‾ \overline{\gamma} γ是间隔均值,以及 ξ i \xi_i ξi和 ϵ i \epsilon_i ϵi是 γ ( x , y ) \gamma(\boldsymbol{x},y) γ(x,y)和间隔均值之间的偏差,因此公式1中的最后一项 ∑ i ∈ [ m ] ( ξ i 2 + ϵ i 2 ) / m \sum_{i\in[m]}(\xi_i^2+\epsilon_i^2)/m ∑i∈[m](ξi2+ϵi2)/m其实是间隔方差。min w , γ ¯ , ξ i , ϵ i 1 2 ‖ w ‖ 2 − η γ ¯ + λ m ∑ i ∈ [ m ] ( ξ i 2 + ϵ i 2 ) , s.t. γ ( x i , y i ) ≥ γ ¯ − ξ i , γ ( x i , y i ) ≤ γ ¯ + ϵ i , ∀ i ∈ [ m ] ,
为了使得模型清晰有效,ODM被引入了三个改进:- 固定间隔均值;
- 不同的偏差分配不同的权重;
- 允许偏差小于给定阈值 θ \theta θ以获取稀疏解。具体如下:
min w , ξ i , ϵ i F ( w ) = 1 2 ∥ w ∥ 2 + λ m ∑ i ∈ [ m ] ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 , s.t. y i w T ϕ ( x i ) ≥ 1 − θ − ξ i , y i w T ϕ ( x i ) ≤ 1 + θ + ϵ i , ∀ i ∈ [ m ] . (2) \tag{2}
minw,ξi,ϵi s.t. F(w)=21∥w∥2+mλ∑i∈[m](1−θ)2ξi2+νϵi2,yiwTϕ(xi)≥1−θ−ξi,yiwTϕ(xi)≤1+θ+ϵi,∀i∈[m].(2)其中 v v v是不同偏差的权衡参数,以及 ( 1 − θ ) 2 (1-\theta)^2 (1−θ)2用于缩放第二项的替代损失。min w , ξ i , ϵ i F ( w ) = 1 2 ‖ w ‖ 2 + λ m ∑ i ∈ [ m ] ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 , s.t. y i w T ϕ ( x i ) ≥ 1 − θ − ξ i , y i w T ϕ ( x i ) ≤ 1 + θ + ϵ i , ∀ i ∈ [ m ] . 3 方法
给定包含 m m m个的训练集 S = { B i , y i } i ∈ [ m ] \mathcal{S}=\{\mathcal{B}_i,y_i\}_{i\in[m]} S={Bi,yi}i∈[m],其中 B i = { x i , 1 , … , x i , m i } \mathcal{B}_i=\{\boldsymbol{x}_{i,1},\dots,\boldsymbol{x}_{i,m_i}\} Bi={xi,1,…,xi,mi}是第 i i i个包、 y i ∈ { ± 1 } y_i\in\{\pm1\} yi∈{±1}是包标签,以及 m i m_i mi是包中实例的数量。在不失一般性的前提下,假设前 p p p个是正包,余下 m − p m-p m−p是负包,即所有包可以被排序为:
y i = { 1 , i ∈ [ p ] , − 1 , i ∈ [ m ] ∖ [ p ] . y_i=\left\{\right. yi={1,−1,i∈[p],i∈[m]∖[p].包的标签预测由其实例的最大决策值决定,即 f ( B i ) = max j ∈ [ m i ] w T ϕ ( x i , j ) f(\mathcal{B}_i)=\max_{j\in[m_i]}\boldsymbol{w}^T\phi(\boldsymbol{x}_{i,j}) f(Bi)=maxj∈[mi]wTϕ(xi,j)。代入公式2有:1 , i ∈ [ p ] , − 1 , i ∈ [ m ] ∖ [ p ] .
min w , ξ i , ϵ i 1 2 ∥ w ∥ 2 + λ 1 p ∑ i = 1 p ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 + λ 2 q ∑ i = p + 1 m ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 , s.t. y i max j ∈ [ m i ] w T ϕ ( x i , j ) ≥ 1 − θ − ξ i , y i max j ∈ [ m i ] w T ϕ ( x i , j ) ≤ 1 + θ + ϵ i , ∀ i ∈ [ m ] , (3) \tag{3}w,ξi,ϵimin s.t. 21∥w∥2+pλ1∑i=1p(1−θ)2ξi2+νϵi2+qλ2∑i=p+1m(1−θ)2ξi2+νϵi2,yimaxj∈[mi]wTϕ(xi,j)≥1−θ−ξi,yimaxj∈[mi]wTϕ(xi,j)≤1+θ+ϵi,∀i∈[m],(3)其中 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是权衡参数。min w , ξ i , ϵ i 1 2 ‖ w ‖ 2 + λ 1 p ∑ i = 1 p ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 + λ 2 q ∑ i = p + 1 m ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 , s.t. y i max j ∈ [ m i ] w T ϕ ( x i , j ) ≥ 1 − θ − ξ i , y i max j ∈ [ m i ] w T ϕ ( x i , j ) ≤ 1 + θ + ϵ i , ∀ i ∈ [ m ] ,
对于每一个正包 B i \mathcal{B}_i Bi,引入二元向量:
a i = [ a i , 1 ; … ; a i , m i ] ∈ { 0 , 1 } m i \boldsymbol{a}_i=[a_{i,1};\dots;a_{i,m_i}]\in\{0,1\}^{m_i} ai=[ai,1;…;ai,mi]∈{0,1}mi来指示具有最大决策值的关键实例。依据标准多示例假设,每个正包中只有一个正实例,则有 e T a i = 1 \boldsymbol{e}^T\boldsymbol{a}_i=1 eTai=1,其中 e \boldsymbol{e} e是一个全1向量。令 c = [ a 1 ; … , a p ] \boldsymbol{c}=[\boldsymbol{a}_1;\dots,\boldsymbol{a}_p] c=[a1;…,ap],以及 C \mathcal{C} C表示其领域。然后公式3中的约束 y i max j ∈ [ m i ] w T ϕ ( x i , j ) ≥ 1 − θ − ξ i y_i \max _{j \in\left[m_i\right]} \boldsymbol{w}^{T} \phi\left(\boldsymbol{x}_{i, j}\right) \geq 1-\theta-\xi_i yimaxj∈[mi]wTϕ(xi,j)≥1−θ−ξi可以重写为 max a i ∑ j ∈ [ m i ] a i , j w T ϕ ( x i , j ) ≥ 1 − θ − ξ i \max_{\boldsymbol{a}_i}\sum_{j\in[m_i]}a_{i,j}\boldsymbol{w}^T\phi(\boldsymbol{x}_{i,j})\geq1-\theta-\xi_i maxai∑j∈[mi]ai,jwTϕ(xi,j)≥1−θ−ξi。
负包 B i \mathcal{B}_i Bi中所有的实例都是负的,公式3与之相应的约束可以替换为:
{ − w T ϕ ( x i , j ) ≥ 1 − θ − ξ i , − w T ϕ ( x i , j ) ≤ 1 + θ + ϵ i , ∀ j ∈ [ m i ] . \left\{\right. {−wTϕ(xi,j)≥1−θ−ξi,−wTϕ(xi,j)≤1+θ+ϵi,∀j∈[mi].为了使得包更灵活,允许包有不同的松弛变量:− w T ϕ ( x i , j ) ≥ 1 − θ − ξ i , − w T ϕ ( x i , j ) ≤ 1 + θ + ϵ i , ∀ j ∈ [ m i ] .
{ ξ s ( i , j ) } i ∈ [ m ] ∖ [ p ] , j ∈ [ m i ] , { ϵ s ( i , j ) } i ∈ [ m ] ∖ [ p ] , j ∈ [ m i ] , \{\xi_{s(i,j)}\}_{i\in[m]\setminus[p],j\in[m_i]},\qquad\{\epsilon_{s(i,j)}\}_{i\in[m]\setminus[p],j\in[m_i]}, {ξs(i,j)}i∈[m]∖[p],j∈[mi],{ϵs(i,j)}i∈[m]∖[p],j∈[mi],其中索引 s ( i , j ) = J i − 1 − J p + j + p s(i,j)=J_{i-1}-J_p+j+p s(i,j)=Ji−1−Jp+j+p的范围为 p + 1 p+1 p+1到 J m − J p + p J_m-J_p+p Jm−Jp+p,以及 J i = ∑ t = 1 i m t J_i=\sum_{t=1}^im_t Ji=∑t=1imt ( J 0 = 0 J_0=0 J0=0)。这个就是把所有的索 s ( i , j ) s(i,j) s(i,j)重新索引至 p p p到所有包的数量加 p p p。结合以上,公式3转换为:
min c ∈ C min w , ξ i , ϵ i 1 2 ∥ w ∥ 2 + λ 1 p ∑ i = 1 p ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 + λ 2 q ∑ i = p + 1 m ∑ j ∈ [ m i ] ξ s ( i , j ) 2 + ν ϵ s ( i , j ) 2 ( 1 − θ ) 2 , s.t. ∑ j ∈ [ m i ] a i , j w T ϕ ( x i , j ) ≥ 1 − θ − ξ i , ∑ j ∈ [ m i ] a i , j w T ϕ ( x i , j ) ≤ 1 + θ + ϵ i , ∀ i ∈ [ p ] , − w T ϕ ( x i , j ) ≥ 1 − θ − ξ s ( i , j ) , − w T ϕ ( x i , j ) ≤ 1 + θ + ϵ s ( i , j ) , ∀ i ∈ [ m ] \ [ p ] , ∀ j ∈ [ m i ] . (4) \tag{4}minc∈C s.t. minw,ξi,ϵi21∥w∥2+pλ1∑i=1p(1−θ)2ξi2+νϵi2+qλ2∑i=p+1m∑j∈[mi](1−θ)2ξs(i,j)2+νϵs(i,j)2,∑j∈[mi]ai,jwTϕ(xi,j)≥1−θ−ξi,∑j∈[mi]ai,jwTϕ(xi,j)≤1+θ+ϵi,∀i∈[p],−wTϕ(xi,j)≥1−θ−ξs(i,j),−wTϕ(xi,j)≤1+θ+ϵs(i,j),∀i∈[m]\[p],∀j∈[mi].(4)作为核方法,由于潜在的无限维特征映射,通常通过对偶形式处理公式4的内部最小化。引入对偶变量 u = [ u 1 ; … ; u 2 ( J m − J p + p ) ] ⪰ 0 \boldsymbol{u}=\left[u_1 ; \ldots ; u_2\left(J_m-J_p+p\right)\right] \succeq \mathbf{0} u=[u1;…;u2(Jm−Jp+p)]⪰0,公式4的拉格朗日形式为:min c ∈ C min w , ξ i , ϵ i 1 2 ‖ w ‖ 2 + λ 1 p ∑ i = 1 p ξ i 2 + ν ϵ i 2 ( 1 − θ ) 2 + λ 2 q ∑ i = p + 1 m ∑ j ∈ [ m i ] ξ s ( i , j ) 2 + ν ϵ s ( i , j ) 2 ( 1 − θ ) 2 , s.t. ∑ j ∈ [ m i ] a i , j w T ϕ ( x i , j ) ≥ 1 − θ − ξ i , ∑ j ∈ [ m i ] a i , j w T ϕ ( x i , j ) ≤ 1 + θ + ϵ i , ∀ i ∈ [ p ] , − w T ϕ ( x i , j ) ≥ 1 − θ − ξ s ( i , j ) , − w T ϕ ( x i , j ) ≤ 1 + θ + ϵ s ( i , j ) , ∀ i ∈ [ m ] ∖ [ p ] , ∀ j ∈ [ m i ] .
min c ∈ C max u ∈ U − 1 2 u T [ K − K − K K ] u − ( 1 − θ ) 2 4 u T [ 1 λ 1 I 0 0 1 λ 2 ν I ] u − [ ( θ − 1 ) e ( θ + 1 ) e ] T u (5) \tag{5}c∈Cminu∈Umax−21uT[K−K−KK]u−4(1−θ)2uT[λ11I00λ2ν1I]u−[(θ−1)e(θ+1)e]Tu(5)其中 U \mathcal{U} U是非负象限,以及 K i , j = Ψ i ⊤ Ψ j ∈ R q × q \mathbf{K}_{i, j}=\boldsymbol{\Psi}_i^{\top} \boldsymbol{\Psi}_j \in \mathbb{R}^{q \times q} Ki,j=Ψi⊤Ψj∈Rq×q是带有min c ∈ C max u ∈ U − 1 2 u T [ K − K − K K ] u − ( 1 − θ ) 2 4 u T [ 1 λ 1 I 0 0 1 λ 2 ν I ] u − [ ( θ − 1 ) e ( θ + 1 ) e ] T u
Ψ i = { ∑ j ∈ [ m i ] a i , j ϕ ( x i , j ) i ∈ [ p ] , j ∈ [ m i ] − ϕ ( x i , j ) i ∈ [ m ] \ [ p ] , j ∈ [ m i ] \boldsymbol{\Psi}_i=Ψi={∑j∈[mi]ai,jϕ(xi,j)−ϕ(xi,j)i∈[p],j∈[mi]i∈[m]\[p],j∈[mi]的核矩阵。{ ∑ j ∈ [ m i ] a i , j ϕ ( x i , j ) i ∈ [ p ] , j ∈ [ m i ] − ϕ ( x i , j ) i ∈ [ m ] ∖ [ p ] , j ∈ [ m i ]
为了克服混合整数规划的求解困难,一些凸松弛方法被使用,例如半正定规划松弛,以及最大松弛 (Minimax relaxation)。本文则使用后者。改变最大最小的顺序,有:
max u ∈ U min c ∈ C D ( u , c ) , \max _{\boldsymbol{u} \in \mathcal{U}}\min _{\boldsymbol{c} \in \mathcal{C}}D(\boldsymbol{u},\boldsymbol{c}), u∈Umaxc∈CminD(u,c),其中 D ( u , c ) D(\boldsymbol{u},\boldsymbol{c}) D(u,c)是公式5中的优化目标。此外,通过重写内部优化,以上公式转换为:
max u ∈ U min c ∈ C d s.t. D ( u , c k ) ≥ d , ∀ c k ∈ C . (6) \tag{6} \max _{\boldsymbol{u} \in \mathcal{U}}\min _{\boldsymbol{c} \in \mathcal{C}}d\quad\text{s.t. }D(\boldsymbol{u},\boldsymbol{c}_k)\geq d,\forall\boldsymbol{c}_k\in\mathcal{C}. u∈Umaxc∈Cminds.t. D(u,ck)≥d,∀ck∈C.(6)进一步于内优化引入对偶变量 v = [ v 1 ; … ; v ∣ C ∣ ] ⪰ 0 \boldsymbol{v}=\left[v_1 ; \ldots ; v_{|\mathcal{C}|}\right] \succeq \mathbf{0} v=[v1;…;v∣C∣]⪰0,公式6的拉格朗日形式为:
min v ⪰ 0 max d { d + ∑ k : c k ∈ C v k ( D ( u , c k ) − d ) } . \min _{\boldsymbol{v} \succeq 0} \max _d\left\{d+\sum_{k: \boldsymbol{c}_k \in \mathcal{C}} v_k\left(D\left(\boldsymbol{u}, \boldsymbol{c}_k\right)-d\right)\right\} . v⪰0mindmax{d+k:ck∈C∑vk(D(u,ck)−d)}.设置 d d d的derivative为 0 0 0,有 ∑ k : c k ∈ C v k = 1 \sum_{k: c_k \in \mathcal{C}} v_k=1 ∑k:ck∈Cvk=1,以及对偶问题转换为:
min v ∈ V ∑ k : c k ∈ C v k D ( u , c k ) , (7) \tag{7} \min _{\boldsymbol{v} \in \mathcal{V}} \sum_{k: c_k \in \mathcal{C}} v_k D\left(\boldsymbol{u}, \boldsymbol{c}_k\right), v∈Vmink:ck∈C∑vkD(u,ck),(7)其中 V = { v ∈ R + ∣ C ∣ ∣ e ⊤ v = 1 } \mathcal{V}=\left\{\boldsymbol{v} \in \mathbb{R}_{+}^{|\mathcal{C}|} \mid e^{\top} \boldsymbol{v}=1\right\} V={v∈R+∣C∣∣e⊤v=1}是 R ∣ C ∣ \mathbb{R}^{|\mathcal{C}|} R∣C∣上的单纯形 (Simplex)为了简洁, ∑ k : c k ∈ C v k D ( u , c k ) \sum_{k: \boldsymbol{c}_k \in \mathcal{C}} v_k D\left(\boldsymbol{u}, \boldsymbol{c}_k\right) ∑k:ck∈CvkD(u,ck)表示为 G ( u , v ) G(\boldsymbol{u}, \boldsymbol{v}) G(u,v),代入公式7,有:
max u ∈ U min v ∈ V G ( u , v ) . \max _{\boldsymbol{u} \in \mathcal{U}} \min _{\boldsymbol{v} \in \mathcal{V}} G(\boldsymbol{u}, \boldsymbol{v}) . u∈Umaxv∈VminG(u,v). G ( u , v ) G(\boldsymbol{u}, \boldsymbol{v}) G(u,v)是负正定象限函数的凸组合,因此 v v v凸 u u u凹,以及根据Siont最大理论,这里存在一个鞍点 ( u ⋆ , v ⋆ ) ∈ U × V \left(\boldsymbol{u}^{\star}, \boldsymbol{v}^{\star}\right) \in \mathcal{U} \times \mathcal{V} (u⋆,v⋆)∈U×V使得:
min v ∈ V max u ∈ U G ( u , v ) ≤ max u ∈ U G ( u , v ⋆ ) = G ( u ⋆ , v ⋆ ) = min v ∈ V G ( u , v ⋆ ) ≤ max u ∈ U min v ∈ V G ( u , v ) . (8) \tag{8}v∈Vminu∈UmaxG(u,v)≤u∈UmaxG(u,v⋆)=G(u⋆,v⋆)=v∈VminG(u,v⋆)≤u∈Umaxv∈VminG(u,v).(8)结合最大不等式:min v ∈ V max u ∈ U G ( u , v ) ≤ max u ∈ U G ( u , v ⋆ ) = G ( u ⋆ , v ⋆ ) = min v ∈ V G ( u , v ⋆ ) ≤ max u ∈ U min v ∈ V G ( u , v ) .
min v ∈ V max u ∈ U G ( u , v ) ≤ max u ∈ U min v ∈ V G ( u , v ) , \min _{\boldsymbol{v} \in \mathcal{V}} \max _{\boldsymbol{u} \in \mathcal{U}} G(\boldsymbol{u}, \boldsymbol{v})\leq \max _{\boldsymbol{u} \in \mathcal{U}} \min _{\boldsymbol{v} \in \mathcal{V}} G(\boldsymbol{u}, \boldsymbol{v}), v∈Vminu∈UmaxG(u,v)≤u∈Umaxv∈VminG(u,v),因此MI-ODM制定为:
min v ∈ V max u ∈ U G ( u , v ) . (9) \tag{9} \min _{\boldsymbol{v} \in \mathcal{V}} \max _{\boldsymbol{u} \in \mathcal{U}} G(\boldsymbol{u}, \boldsymbol{v}). v∈Vminu∈UmaxG(u,v).(9)最优质为鞍点 ( u ⋆ , v ⋆ ) \left(\boldsymbol{u}^{\star}, \boldsymbol{v}^{\star}\right) (u⋆,v⋆)。4 优化
简要地介绍最大问题,并详述用于快速最优值求解的随机加速镜像近似方法。
4.1 最大问题
根据一阶凸性不等式, G ( u , ⋅ ) G(\boldsymbol{u},\cdot) G(u,⋅)和 G ( ⋅ , v ) G(\cdot,\boldsymbol{v}) G(⋅,v)均为凸函数,对于任意的对 ( u ^ , v ^ ) ∈ U × V (\hat{\boldsymbol{u}}, \hat{\boldsymbol{v}}) \in \mathcal{U} \times \mathcal{V} (u^,v^)∈U×V,有:
G ( u , v ^ ) − G ( u ^ , v ^ ) ≤ − ∂ u G ( u ^ , v ^ ) ⊤ ( u ^ − u ) , ∀ u ∈ U , G ( u ^ , v ^ ) − G ( u ^ , v ) ≤ ∂ v G ( u ^ , v ^ ) ⊤ ( v ^ − v ) , ∀ v ∈ V .G(u,v^)−G(u^,v^)≤−∂uG(u^,v^)⊤(u^−u),∀u∈U,G(u^,v^)−G(u^,v)≤∂vG(u^,v^)⊤(v^−v),∀v∈V.叠加以上不等式,并增广 u \boldsymbol{u} u和 v \boldsymbol{v} v,有:G ( u , v ^ ) − G ( u ^ , v ^ ) ≤ − ∂ u G ( u ^ , v ^ ) ⊤ ( u ^ − u ) , ∀ u ∈ U , G ( u ^ , v ^ ) − G ( u ^ , v ) ≤ ∂ v G ( u ^ , v ^ ) ⊤ ( v ^ − v ) , ∀ v ∈ V .
G ( u , v ^ ) − G ( u ^ , v ) ≤ g ( w ^ ) ⊤ ( w ^ − w ) , ∀ u , v , (10) \tag{10} G(\boldsymbol{u}, \hat{\boldsymbol{v}})-G(\hat{\boldsymbol{u}}, \boldsymbol{v}) \leq g(\hat{\boldsymbol{w}})^{\top}(\hat{\boldsymbol{w}}-\boldsymbol{w}), \forall \boldsymbol{u}, \boldsymbol{v}, G(u,v^)−G(u^,v)≤g(w^)⊤(w^−w),∀u,v,(10)其中 w = [ u ; v ] \boldsymbol{w}=[\boldsymbol{u} ; \boldsymbol{v}] w=[u;v],以及 g ( w ^ ) = [ − ∂ u G ( w ^ ) ; ∂ v G ( w ^ ) ] g(\hat{\boldsymbol{w}})=\left[-\partial_{\boldsymbol{u}} G(\hat{\boldsymbol{w}}) ; \partial_{\boldsymbol{v}} G(\hat{\boldsymbol{w}})\right] g(w^)=[−∂uG(w^);∂vG(w^)]。与一般的凸优化相比, g ( w ^ ) g(\hat{\boldsymbol{w}}) g(w^)扮演着梯度的角色。因此对于任意的 u \boldsymbol{u} u和 v \boldsymbol{v} v,有:
max u ∈ U G ( u , v ^ ) − min v ∈ V G ( u ^ , v ) ≤ g ( w ^ ) ⊤ ( w ^ − w ) . (11) \tag{11} \max _{\boldsymbol{u} \in \mathcal{U}} G(\boldsymbol{u}, \hat{\boldsymbol{v}})-\min _{\boldsymbol{v} \in \mathcal{V}} G(\hat{\boldsymbol{u}}, \boldsymbol{v}) \leq g(\hat{\boldsymbol{w}})^{\top}(\hat{\boldsymbol{w}}-\boldsymbol{w}) . u∈UmaxG(u,v^)−v∈VminG(u^,v)≤g(w^)⊤(w^−w).(11)公式11的LHS可以进一步分解为当前点 G ( u ^ , v ^ ) G(\hat{\boldsymbol{u}}, \hat{\boldsymbol{v}}) G(u^,v^)与鞍点 ( u ⋆ , v ⋆ ) \left(\boldsymbol{u}^{\star}, \boldsymbol{v}^{\star}\right) (u⋆,v⋆)之间的间隔:
max u ∈ U G ( u , v ^ ) − G ( u ⋆ , v ⋆ ) + G ( u ⋆ , v ⋆ ) − min v ∈ V G ( u ^ , v ) = max u ∈ U G ( u , v ^ ) − min v ∈ V u ∈ U max U G ( u , v ) ⏟ ≥ 0 + max u ∈ U min v ∈ V G ( u , v ) − min v ∈ V G ( u ^ , v ) ⏟ ≥ 0 .u∈UmaxG(u,v^)−G(u⋆,v⋆)+G(u⋆,v⋆)−v∈VminG(u^,v)=≥0 u∈UmaxG(u,v^)−v∈Vu∈UminUmaxG(u,v)+≥0 u∈Umaxv∈VminG(u,v)−v∈VminG(u^,v).两个间隔均非负,其值越小越接近鞍点。公式11的LHS可以看作是一般凸优化中的“对偶间隔”,并作为算法设计的停止标准。max u ∈ U G ( u , v ^ ) − G ( u ⋆ , v ⋆ ) + G ( u ⋆ , v ⋆ ) − min v ∈ V G ( u ^ , v ) = max u ∈ U G ( u , v ^ ) − min v ∈ V u ∈ U max U G ( u , v ) ⏟ ≥ 0 + max u ∈ U min v ∈ V G ( u , v ) − min v ∈ V G ( u ^ , v ) ⏟ ≥ 0 . 4.2 随机加速镜像近似
u \boldsymbol{u} u和 v \boldsymbol{v} v的可行域分别对应框约束和单纯形。镜像下降方法用于探索其结构信息。对于变量 u \boldsymbol{u} u,欧式距离镜像图 ψ U = ∥ u ∥ 2 2 / 2 \psi_\mathcal{U}=\|\boldsymbol{u}\|_2^2/2 ψU=∥u∥22/2可以工作的很好,对于变量 v \boldsymbol{v} v,负熵镜像图 ψ V ( v ) = ∑ k log v k \psi_\mathcal{V}(\boldsymbol{v})=\sum_k\log v_k ψV(v)=∑klogvk很适用,因为它可以使得时间复杂度与维度的依赖程度是对数的。
镜像下降方法在镜像映射引起的对偶空间中执行梯度下降。为了使得最大结构得以像一般优化问题那样容易处理,引入联合镜像图 ψ ( w ) = a ψ U ( u ) + b ψ V ( v ) \psi(\boldsymbol{w})=a\psi_\mathcal{U}(\boldsymbol{u})+b\psi_\mathcal{V}(\boldsymbol{v}) ψ(w)=aψU(u)+bψV(v),其中 a = 2 / τ J m − J p + p a=\sqrt{2}/\tau\sqrt{J_m-J_p+p} a=2/τJm−Jp+p,以及 b = 1 / log ∣ C ∣ b=1/\sqrt{\log|\mathcal{C}|} b=1/log∣C∣。这表明 ∇ ψ U ( u ) = u \nabla\psi\mathcal{U}(\boldsymbol{u})=\boldsymbol{u} ∇ψU(u)=u,以及 ∇ ψ V ( v ) = log v + e \nabla\psi_\mathcal{V}(\boldsymbol{v})=\log\boldsymbol{v}+\boldsymbol{e} ∇ψV(v)=logv+e。结合在一起有 ∇ ψ ( w ) = [ a u ; b log v + b e ] \nabla\psi(\boldsymbol{w})=[a\boldsymbol{u};b\log\boldsymbol{v}+b\boldsymbol{e}] ∇ψ(w)=[au;blogv+be]。
如图1所示,在第 t t t次迭代中,首先将当前点 w t = [ u t ; v t ] \boldsymbol{w}_t=\left[\boldsymbol{u}_t ; \boldsymbol{v}_t\right] wt=[ut;vt]映射到对偶空间 ∇ ψ ( w t ) = \nabla \psi\left(\boldsymbol{w}_t\right)= ∇ψ(wt)= [ a u t ; b log v t + b e ] \left[a \boldsymbol{u}_t ; b \log \boldsymbol{v}_t+b \boldsymbol{e}\right] [aut;blogvt+be]并执行一次梯度下降
∇ ( w ^ t ) = ∇ ψ ( w t ) − η g ( w t ) = [ a u t + η ∂ u G ( u t , v t ) ; b log v t + b e − η ∂ v G ( u t , v t ) ] ,=∇(w^t)=∇ψ(wt)−ηg(wt)[aut+η∂uG(ut,vt);blogvt+be−η∂vG(ut,vt)],其中 η \eta η是步长大小,然后将 ∇ ψ ( w ^ t ) \nabla \psi\left(\hat{\boldsymbol{w}}_t\right) ∇ψ(w^t)映射回最初的空间,即找到 w ^ t = [ u ^ t ; v ^ t ] \hat{\boldsymbol{w}}_t=\left[\hat{\boldsymbol{u}}_t ; \hat{\boldsymbol{v}}_t\right] w^t=[u^t;v^t]:∇ ( w ^ t ) = ∇ ψ ( w t ) − η g ( w t ) = [ a u t + η ∂ u G ( u t , v t ) ; b log v t + b e − η ∂ v G ( u t , v t ) ] ,
[ a u ^ t b log v ^ t + b e ] = [ a u t + η ∂ u G ( u t , v t ) b log v t + b e − η ∂ v G ( u t , v t ) ] , \left[\right]=\left[a u ^ t b log v ^ t + b e \right], [au^tblogv^t+be]=[aut+η∂uG(ut,vt)blogvt+be−η∂vG(ut,vt)],其表明 u ^ t = u t + η ∂ u G ( u t , v t ) / a \hat{\boldsymbol{u}}_t=\boldsymbol{u}_t+\eta \partial_{\boldsymbol{u}} G\left(\boldsymbol{u}_t, \boldsymbol{v}_t\right) / a u^t=ut+η∂uG(ut,vt)/a且 v ^ t = \hat{\boldsymbol{v}}_t= v^t= v t exp ( − η ∂ v G ( u t , v t ) / b ) \boldsymbol{v}_t \exp \left(-\eta \partial_{\boldsymbol{v}} G\left(\boldsymbol{u}_t, \boldsymbol{v}_t\right) / b\right) vtexp(−η∂vG(ut,vt)/b)。最后,基于镜像图中的Bregman距离执行映射 [ u ^ t ; v ^ t ] \left[\hat{\boldsymbol{u}}_t ; \hat{\boldsymbol{v}}_t\right] [u^t;v^t]到 U × V \mathcal{U} \times \mathcal{V} U×V。特别地,欧式距离镜像图使用常用的欧氏距离,负熵镜像图使用Kullback-Leible散度。这可以制定为以下子优化问题:a u t + η ∂ u G ( u t , v t ) b log v t + b e − η ∂ v G ( u t , v t )
u t + 1 = arg min u ∈ U ∥ u − u ^ t ∥ 2 2 , v t + 1 = arg min v ∈ V v T log v v ^ t .ut+1=vt+1=u∈Uargmin∥u−u^t∥22,v∈VargminvTlogv^tv.u t + 1 = \argmin u ∈ U ‖ u − u ^ t ‖ 2 2 , v t + 1 = \argmin v ∈ V v T log v v ^ t . 
图1:镜像下降的一个迭代 这两个子优化问题都有近似解,前者将 u ^ t \hat{\boldsymbol{u}}_t u^t映射到非负象限,因此 u t + 1 = max { u ^ t , 0 } \boldsymbol{u}_{t+1}=\max\{\hat{u}_t,0\} ut+1=max{u^t,0}。后者中引入对偶变量 z z z,则拉格朗日形式为:
max z min v v T log ( v / v ^ t ) + z ( e T v − 1 ) . \max _z \min _{\boldsymbol{v}} \boldsymbol{v}^{T} \log \left(\boldsymbol{v} / \hat{v}_t\right)+z\left(\boldsymbol{e}^{T} \boldsymbol{v}-1\right) . zmaxvminvTlog(v/v^t)+z(eTv−1).设置 v v v的derivative为 0 0 0,有 log ( v / v ^ t ) + e + \log \left(\boldsymbol{v} / \hat{\boldsymbol{v}}_t\right)+\boldsymbol{e}+ log(v/v^t)+e+ z e = 0 z \boldsymbol{e}=\mathbf{0} ze=0,其表明 v t + 1 = v ^ t exp ( − 1 − z ) \boldsymbol{v}_{t+1}=\hat{\boldsymbol{v}}_t \exp (-1-z) vt+1=v^texp(−1−z)。注意 v t + 1 \boldsymbol{v}_{t+1} vt+1属于一个单纯形,因此 1 = e ⊤ v t + 1 = e ⊤ v ^ t exp ( − 1 − z ) = ∥ v ^ t ∥ 1 exp ( − 1 − z ) 1=\boldsymbol{e}^{\top} \boldsymbol{v}_{t+1}=\boldsymbol{e}^{\top} \hat{\boldsymbol{v}}_t \exp (-1-z)=\left\|\hat{\boldsymbol{v}}_t\right\|_1 \exp (-1-z) 1=e⊤vt+1=e⊤v^texp(−1−z)=∥v^t∥1exp(−1−z)。代入到 exp ( − 1 − z ) = 1 / ∥ v ^ t ∥ 1 \exp (-1-z)=1 /\left\|\hat{v}_t\right\|_1 exp(−1−z)=1/∥v^t∥1,得到近似解 v t + 1 = v ^ t / ∥ v ^ t ∥ 1 v_{t+1}=\hat{v}_t /\left\|\hat{v}_t\right\|_1 vt+1=v^t/∥v^t∥1。有了 y t + 1 ≜ [ u t + 1 ; v t + 1 ] \boldsymbol{y}_{t+1} \triangleq\left[\boldsymbol{u}_{t+1} ; \boldsymbol{v}_{t+1}\right] yt+1≜[ut+1;vt+1]后,从 w t \boldsymbol{w}_t wt;当在对偶空间执行梯度下降时,使用 y t + 1 \boldsymbol{y}_{t+1} yt+1而非 w t \boldsymbol{w}_t wt。换言之,一个两步镜像下降方法在每次迭代中执行,其从同一点开始,但第二次使用的梯度在第一次的结束点进行评估。该过程已被证明有很好的收敛性。 图2展示了该方法的一次迭代。
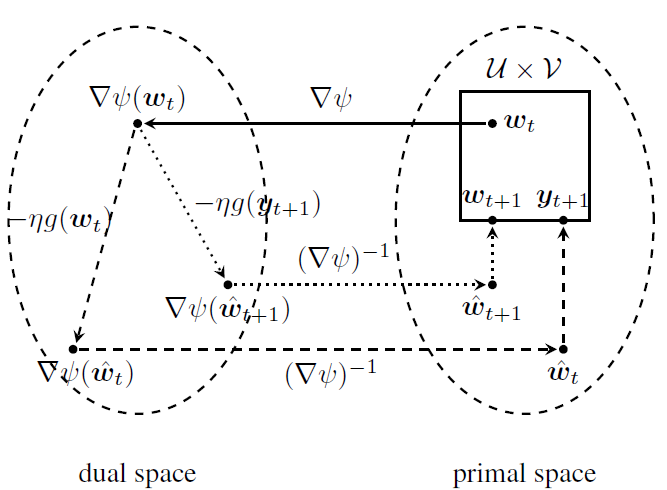
图2:镜像近似的一次迭代 镜像近似方法可以进一步通过Nesterov加速技术提速。方法是在 { w t } \left\{\boldsymbol{w}_t\right\} {wt}和 { y t } \left\{\boldsymbol{y}_t\right\} {yt}之外额外保留两个序列 { w ‾ t } \left\{\underline{\boldsymbol{w}}_t\right\} {wt}和 { w ‾ t } \left\{\overline{\boldsymbol{w}}_t\right\} {wt},其是 { w t } \left\{\boldsymbol{w}_t\right\} {wt}和 { y t } \left\{\boldsymbol{y}_t\right\} {yt}的结合。特别地,在第 t t t次迭代中,首先更新 w ‾ t = ( 1 − γ t ) w ˉ t + γ t y t \underline{\boldsymbol{w}}_t=\left(1-\gamma_t\right) \bar{\boldsymbol{w}}_t+\gamma_t \boldsymbol{y}_t wt=(1−γt)wˉt+γtyt,其中 γ t \gamma_t γt是Nesterov加速系数,通常设置为 2 / ( t + 1 ) 2 /(t+1) 2/(t+1)。随后,两部镜像近似基于 w ‾ t \underline{\boldsymbol{w}}_t wt来获得 y t + 1 \boldsymbol{y}_{t+1} yt+1和 w t + 1 \boldsymbol{w}_{t+1} wt+1。此外,为了使得数据集更好的适应大数据,该方法被扩展为一个随机版本,关键问题转换为找到无偏梯度 ∂ u G ~ ( u t , v t ) \partial_{\boldsymbol{u}} \widetilde{G}\left(\boldsymbol{u}_t, \boldsymbol{v}_t\right) ∂uG (ut,vt)和 ∂ v G ~ ( u t , v t ) \partial_{\boldsymbol{v}} \widetilde{G}\left(\boldsymbol{u}_t, \boldsymbol{v}_t\right) ∂vG (ut,vt)。注意 G ( u , v ) = G(\boldsymbol{u}, \boldsymbol{v})= G(u,v)= ∑ k : c k ∈ C v k D ( u , c k ) \sum_{k: c_k \in \mathcal{C}} v_k D\left(\boldsymbol{u}, \boldsymbol{c}_k\right) ∑k:ck∈CvkD(u,ck),则有
∂ u G ( u t , v t ) = [ ∂ u D ( u t , c 1 ) , … , ∂ u D ( u t , c ∣ C ∣ ) ] v t ∂ v G ( u t , v t ) = [ D ( u t , c 1 ) , … , D ( u t , c ∣ C ∣ ) ] .∂uG(ut,vt)=[∂uD(ut,c1),…,∂uD(ut,c∣C∣)]vt∂vG(ut,vt)=[D(ut,c1),…,D(ut,c∣C∣)].随机采样的索引 i t i_t it基于 v t \boldsymbol{v}_t vt在 { 1 , 2 , … , ∣ C ∣ } \{1,2, \ldots,|\mathcal{C}|\} {1,2,…,∣C∣}的分布获得,有 ∂ u G ~ ( u t , v t , i t ) = \partial_{\boldsymbol{u}} \widetilde{G}\left(\boldsymbol{u}_t, \boldsymbol{v}_t, i_t\right)= ∂uG (ut,vt,it)= ∂ u D ( u t , c i t ) \partial_{\boldsymbol{u}} D\left(\boldsymbol{u}_t, \boldsymbol{c}_{i_t}\right) ∂uD(ut,cit). 另一方面,均匀采样的索引 j t j_t jt来自 { 1 , 2 , … , ∣ C ∣ } \{1,2, \ldots,|\mathcal{C}|\} {1,2,…,∣C∣},有 ∂ v G ~ ( u t , v t , j t ) = \partial_{\boldsymbol{v}} \widetilde{G}\left(\boldsymbol{u}_t, \boldsymbol{v}_t, j_t\right)= ∂vG (ut,vt,jt)= [ 0 , … , ∣ C ∣ D ( u t , c j t ) … , 0 ] \left[0, \ldots,|\mathcal{C}| D\left(\boldsymbol{u}_t, \boldsymbol{c}_{j_t}\right) \ldots, 0\right] [0,…,∣C∣D(ut,cjt)…,0]。这可以表示为:∂ u G ( u t , v t ) = [ ∂ u D ( u t , c 1 ) , … , ∂ u D ( u t , c | C | ) ] v t ∂ v G ( u t , v t ) = [ D ( u t , c 1 ) , … , D ( u t , c | C | ) ] .
E [ ∂ u G ~ ( u t , v t , i t ) ∣ u t , v t ] = ∂ u G ( u t , v t ) , E [ ∂ v G ~ ( u t , v t , j t ) ∣ u t , v t ] = ∂ v G ( u t , v t ) ,E[∂uG (ut,vt,it)∣ut,vt]E[∂vG (ut,vt,jt)∣ut,vt]=∂uG(ut,vt),=∂vG(ut,vt),以及 g ~ ( w t ) = [ − ∂ u G ~ ( u t , v t , i t ) ; ∂ v G ~ ( u t , v t , j t ) ] \widetilde{g}\left(\boldsymbol{w}_t\right)=\left[-\partial_u \widetilde{G}\left(\boldsymbol{u}_t, \boldsymbol{v}_t, i_t\right) ; \partial_{\boldsymbol{v}} \widetilde{G}\left(\boldsymbol{u}_t, \boldsymbol{v}_t, j_t\right)\right] g (wt)=[−∂uG (ut,vt,it);∂vG (ut,vt,jt)]是 g ( w t ) g\left(\boldsymbol{w}_t\right) g(wt)的期望无偏估计。E [ ∂ u G ~ ( u t , v t , i t ) ∣ u t , v t ] = ∂ u G ( u t , v t ) , E [ ∂ v G ~ ( u t , v t , j t ) ∣ u t , v t ] = ∂ v G ( u t , v t ) ,
综合以上步骤,将获得随机加速镜像近似方法MI-ODM,如算法1。

-
相关阅读:
score_inverse_problems运行环境,pycharm重新安装,jax,jaxlib的GPU版本安装-230831
批量归一化(部分理解)
比较聚合模型实战文本匹配
LeetCode //C - 142. Linked List Cycle II
设计模式(一)——单例模式(Singleton)
【CNN】白话迁移学习中域适应
Vue_Bug NPM下载速度过慢
园区网典型配置案例
SSM+Mysql实现的共享单车管理系统(功能包含分角色,登录、用户管理、服务点管理、单车管理、分类管理、学生信息管理、单车租赁、信息统计、系统设置等)
PAT (Basic Level) Practice 1023~1044
- 原文地址:https://blog.csdn.net/weixin_44575152/article/details/126693677