-
Tez的web UI简单体验
Tez的web UI简单体验
前言
由于CDP7默认是Hive On Tez,不再有Map Reduce和Spark什么事,查看监控、分析数据倾斜等原因导致的HQL任务跑不快的问题没有使用Spark那会儿那么容易。加之DataPhin中台各种封装隐藏了很多Log,更是不方便调优。笔者在USDP集群上简单测试下效果,尝试从Tez的web UI看出点端倪。
Hive On Tez运行原理可以参考:https://lizhiyong.blog.csdn.net/article/details/126688391
Web UI访问
USDP2大数据集群安装好之后:http://zhiyong2:9999/tez/
大概是这样:

相当的朴素。。。经过笔者多次测试,只有需要调度到Yarn上的任务才会显示在这个web UI中。普通的select操作如果不用Yarn跑,并不会显示在这里。
启动运算任务
笔者采用了Java手写JDBC的方式执行HQL,之后使用了Hive的Cli方式执行。
JDBC方式启动任务
Hive3.1.2的Maven冲突真的是一言难尽。。。
String sql_Insert = "insert into db_lzy.digital_monster values(1000,'暴龙兽1')"; String sql_Select = "select distinct name,rpad(name,50,'*') from db_lzy.digital_monster"; //聪明的你一定比肤浅的SQL Boy们更熟悉中间的过程 final String HIVE_JDBC_DRIVER = "org.apache.hive.jdbc.HiveDriver"; final String HIVE_HOST = "192.168.88.101"; final String HIVE_PORT = "10000"; final String HIVE_USER = "root"; final String HIVE_PASSWORD = "123456"; String HIVE_URL = "jdbc:hive2://" + HIVE_HOST + ":" + HIVE_PORT + "/default"; Connection conn = null; Statement stmt = null; ResultSet resultSet = null; Class.forName(HIVE_JDBC_DRIVER); conn = DriverManager.getConnection(HIVE_URL, HIVE_USER, HIVE_PASSWORD); stmt = conn.createStatement(); //聪明的你一定比肤浅的SQL Boy们更熟悉中间的过程 boolean execute = stmt.execute(sql_Insert); resultSet = stmt.executeQuery(sql_Select);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这样子必定失败。。。然后就可以获取到2个失败记录:


一屏截不下,真宽。。。Client的类型当然是HS2,执行引擎就是默认的MR。
由于是宿主机的Idea吊起JVM访问虚拟机,Client的IP=192.168.88.1这个网关也没什么毛病。分别来看看。
去重查询失败

点进来可以看到执行的HQL。所谓的细节,信息也不是很多。。。
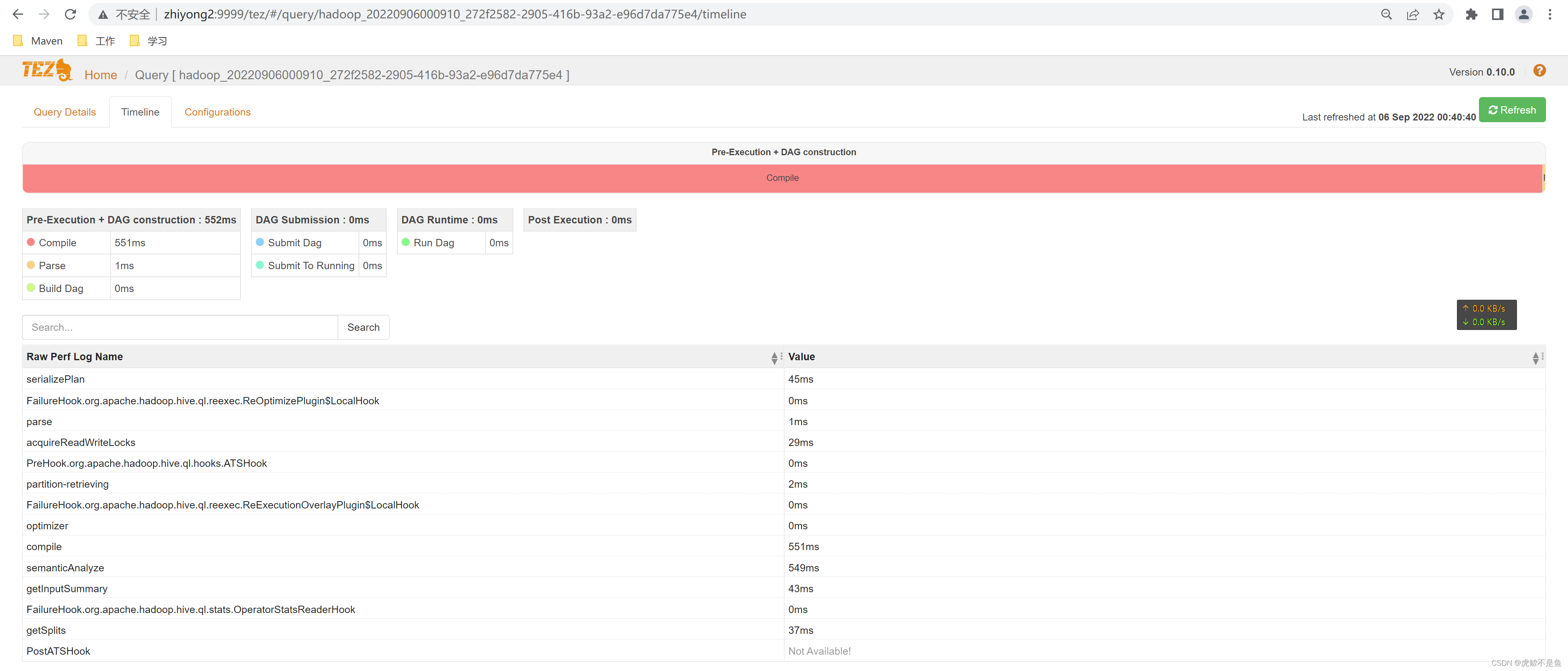
这里可以看到时间线TimeLine。从中可以看出编译耗时最长【551ms】,并且编译完在SQL转换AST时就失败了。


这些配置可以参考。
于是可以初步判断这个HQL任务是解析AST时失败。
插入数据失败

这个任务在Idea会报错:
Exception in thread "main" java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException: Invalid resource request, requested resource type=[memory-mb] < 0 or greater than maximum allowed allocation. Requested resource=<memory:8192, vCores:1>, maximum allowed allocation=<memory:5000, vCores:8>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:5000, vCores:8> at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.throwInvalidResourceException(SchedulerUtils.java:397) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.checkResourceRequestAgainstAvailableResource(SchedulerUtils.java:379) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.validateResourceRequest(SchedulerUtils.java:288) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.normalizeAndValidateRequest(SchedulerUtils.java:259) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.normalizeAndValidateRequest(SchedulerUtils.java:223) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.validateAndCreateResourceRequest(RMAppManager.java:529) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.createAndPopulateNewRMApp(RMAppManager.java:381) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.submitApplication(RMAppManager.java:320) at org.apache.hadoop.yarn.server.resourcemanager.ClientRMService.submitApplication(ClientRMService.java:645) at org.apache.hadoop.yarn.api.impl.pb.service.ApplicationClientProtocolPBServiceImpl.submitApplication(ApplicationClientProtocolPBServiceImpl.java:277) at org.apache.hadoop.yarn.proto.ApplicationClientProtocol$ApplicationClientProtocolService$2.callBlockingMethod(ApplicationClientProtocol.java:563) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:872) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:818) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2678) at org.apache.hive.jdbc.HiveStatement.waitForOperationToComplete(HiveStatement.java:401) at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:266) at com.zhiyong.JdbcDemo.main(JdbcDemo.java:78) Process finished with exit code 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
这种任务Map Reduce居然嫌弃5G内存太小了,想要8G。。。也是在做梦。。。这年头除非数据量大的离谱,很少有跑MapReduce任务的软件厂了。。。

从时间线可以看出,同样是编译完做AST解析转换时报错了。。。
Hive Cli方式启动任务
Hive Cli方式启动无Shuffle任务
hive (db_lzy)> insert into db_lzy.digital_monster values(1000,'暴龙兽1'); Query ID = root_20220906002627_7ddef917-17ff-44e4-bd73-e33acbaef415 Total jobs = 1 Launching Job 1 out of 1 2022-09-06 00:26:29 INFO client.AHSProxy: Connecting to Application History server at zhiyong3/192.168.88.102:10201 2022-09-06 00:26:29 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2 Status: Running (Executing on YARN cluster with App id application_1662378283798_0003) ---------------------------------------------------------------------------------------------- VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED ---------------------------------------------------------------------------------------------- Map 1 .......... container SUCCEEDED 1 1 0 0 0 0 Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0 ---------------------------------------------------------------------------------------------- VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 11.34 s ---------------------------------------------------------------------------------------------- Status: DAG finished successfully in 11.34 seconds Query Execution Summary ---------------------------------------------------------------------------------------------- OPERATION DURATION ---------------------------------------------------------------------------------------------- Compile Query 0.82s Prepare Plan 16.34s Get Query Coordinator (AM) 0.04s Submit Plan 0.56s Start DAG 0.14s Run DAG 11.34s ---------------------------------------------------------------------------------------------- Task Execution Summary ---------------------------------------------------------------------------------------------- VERTICES DURATION(ms) CPU_TIME(ms) GC_TIME(ms) INPUT_RECORDS OUTPUT_RECORDS ---------------------------------------------------------------------------------------------- Map 1 3615.00 5,280 577 3 1 Reducer 2 502.00 1,390 18 1 0 ---------------------------------------------------------------------------------------------- Loading data to table db_lzy.digital_monster OK col1 col2 Time taken: 31.919 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
这么简单的一句insert操作,Tez提交到了Yarn,并且花费31.919s后执行成功。
并且在HDFS生成了小文件:
[root@zhiyong2 conf]# hadoop fs -ls /zhiyong-1/user/hive/warehouse/db_lzy.db/digital_monster Found 2 items -rw-r--r-- 3 root supergroup 598 2022-08-05 12:59 /zhiyong-1/user/hive/warehouse/db_lzy.db/digital_monster/000000_0 -rw-r--r-- 3 root supergroup 489 2022-09-06 00:26 /zhiyong-1/user/hive/warehouse/db_lzy.db/digital_monster/000000_0_copy_1- 1
- 2
- 3
- 4
- 5
Tez在运行时会在web UI显示:

完成后点进去看到:

在时间线可以看到:

可以看到run成功时,编译和AST解析转换、构建DAG其实总共1s多。集群本身资源充足,提交DAG和Yarn吊起任务其实也就1s左右。比较耗时的是DAG运行的那11s。耗时最多的生成执行计划【16s】居然没有出现在Tez的web UI【只出现在Hive的Cli】。。。
其实单表【当然包括读写性能很好的大宽表】没什么好看的,性能瓶颈大多是由于上古年代的SAS盘阵列后IO依然低达30m/s,交换机带宽不足【例如还不都是全千兆口】,光纤损耗高等导致读写慢从而影响了Map过程,致使任务慢。这种问题换硬盘、改阵列、多来几组大带宽交换机,减少跨机房跨机架甚至跨地区组集群的不科学规划【没错,说的就是用多区域云主机组集群的】,尽量把Hive表的文件存放在离计算节点近的机器【数据本地性】,都有良好的效果。
如果是where的条件很多,数据量又大,需要启用向量化执行等功能,运算密集型任务+CPU+内存再调参【给Tez分配更多计算资源】即可。。。
一般来说,+机器能解决的问题不是太过于恐怖的问题。怕就怕+机器也解决不了的问题。。。
Hive Cli方式启动有Shuffle任务
肤浅的SQL Boy们总是不听劝,不喜欢用读写性能更好的大宽表,坚持要做多表Join来拉宽这种性能极烂的骚操作。。。这种不合理的操作反倒是大多数情况。。。简单做个测试:
create table db_lzy.td_tb1( `id` int, `location_1` string, `location_2` string ) stored as parquet ; --Hive的Cli最好手动换单行去运行 insert into db_lzy.td_tb1 values(1,'cn','bj'); insert into db_lzy.td_tb1 values(2,'cn','sh'); insert into db_lzy.td_tb1 values(3,'cn','gz'); insert into db_lzy.td_tb1 values(4,'cn','tj'); insert into db_lzy.td_tb1 values(5,'jp','cs'); insert into db_lzy.td_tb1 values(6,'jp','gd');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
成功后:
hive (db_lzy)> select * from db_lzy.td_tb1; OK td_tb1.id td_tb1.location_1 td_tb1.location_2 1 cn bj 2 cn sh 3 cn gz 4 cn tj 5 jp cs 6 jp gd Time taken: 0.219 seconds, Fetched: 6 row(s) hive (db_lzy)> select * from db_lzy.digital_monster; OK digital_monster.num digital_monster.name 1 亚古兽 2 暴龙兽 3 机械暴龙兽 4 丧尸暴龙兽 5 战斗暴龙兽 6 大地暴龙兽 7 闪光暴龙兽 1000 暴龙兽1 Time taken: 0.197 seconds, Fetched: 8 row(s) hive (db_lzy)>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
来个性能极差的Join:
select t1.num, t1.name, t2.id, t2.location_1, t2.location_2 from db_lzy.digital_monster t1 left join db_lzy.td_tb1 t2 on t1.num=t2.id ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
压缩成1行后执行:
hive (db_lzy)> select t1.num,t1.name,t2.id,t2.location_1,t2.location_2 from db_lzy.digital_monster t1 left join db_lzy.td_tb1 t2 on t1.num=t2.id; Query ID = root_20220906012440_25c33094-952c-4b31-9b3b-a8e45fda1861 Total jobs = 1 Launching Job 1 out of 1 Tez session was closed. Reopening... 2022-09-06 01:24:41 INFO client.AHSProxy: Connecting to Application History server at zhiyong3/192.168.88.102:10201 2022-09-06 01:24:41 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2 Session re-established. Session re-established. Status: Running (Executing on YARN cluster with App id application_1662378283798_0006) ---------------------------------------------------------------------------------------------- VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED ---------------------------------------------------------------------------------------------- Map 1 .......... container SUCCEEDED 1 1 0 0 0 0 Map 3 .......... container SUCCEEDED 1 1 0 0 0 0 Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0 ---------------------------------------------------------------------------------------------- VERTICES: 03/03 [==========================>>] 100% ELAPSED TIME: 10.92 s ---------------------------------------------------------------------------------------------- Status: DAG finished successfully in 10.92 seconds Query Execution Summary ---------------------------------------------------------------------------------------------- OPERATION DURATION ---------------------------------------------------------------------------------------------- Compile Query 0.41s Prepare Plan 0.13s Get Query Coordinator (AM) 0.00s Submit Plan 8.72s Start DAG 0.64s Run DAG 10.92s ---------------------------------------------------------------------------------------------- Task Execution Summary ---------------------------------------------------------------------------------------------- VERTICES DURATION(ms) CPU_TIME(ms) GC_TIME(ms) INPUT_RECORDS OUTPUT_RECORDS ---------------------------------------------------------------------------------------------- Map 1 4173.00 9,760 1,291 8 8 Map 3 2593.00 3,990 160 6 6 Reducer 2 1339.00 2,630 10 14 0 ---------------------------------------------------------------------------------------------- OK t1.num t1.name t2.id t2.location_1 t2.location_2 1 亚古兽 1 cn bj 2 暴龙兽 2 cn sh 3 机械暴龙兽 3 cn gz 4 丧尸暴龙兽 4 cn tj 5 战斗暴龙兽 5 jp cs 6 大地暴龙兽 6 jp gd 7 闪光暴龙兽 NULL NULL NULL 1000 暴龙兽1 NULL NULL NULL Time taken: 20.856 seconds, Fetched: 8 row(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
显然Join的select查数据就要比没有Join的表慢1个数量级。。。
web UI中:

明显和之前无Shuffle的任务不同。


DAG Counters中还有很多细节。

在Graphical View中可以看到具体的DAG图。先走2个Map任务读取t1和t2表,然后来个Reduce去Join起来,最终输出结果,没什么毛病。

这里可以看到3个子任务的细节。

这里貌似还有日志【可以跳转到Yarn的Web UI】。

半差不差。

这个Vertex Swimlane有点像总体的时间线,鼠标放上去有细节显示:
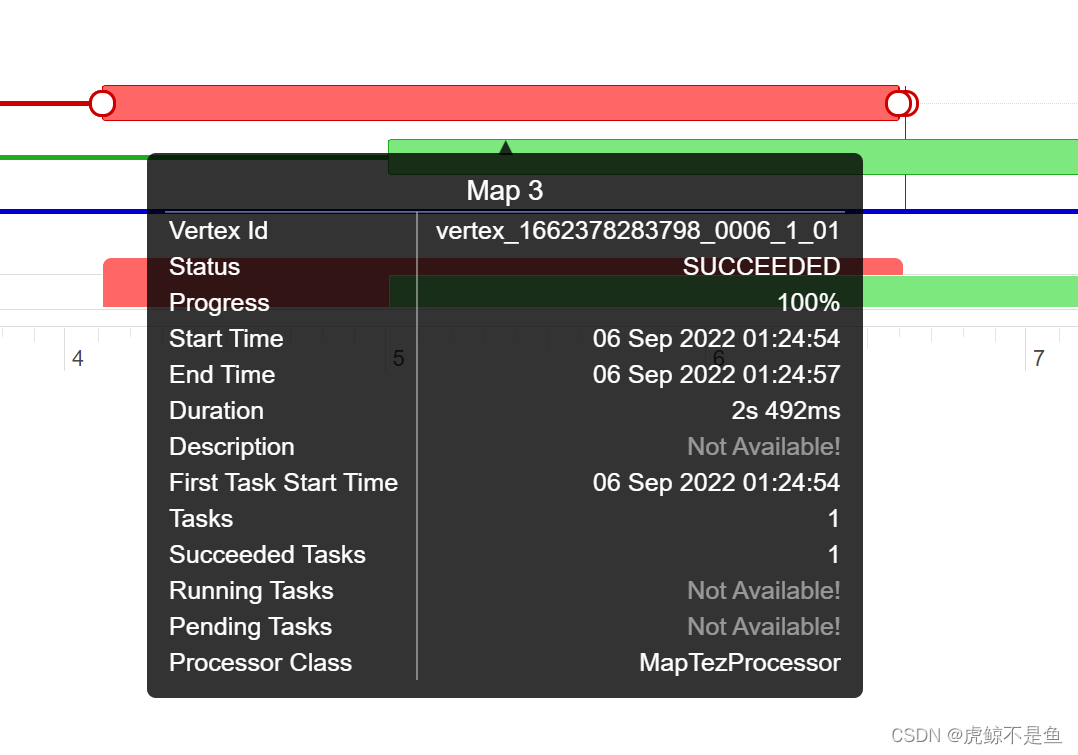
这样就可以看到每个小阶段的耗时情况。
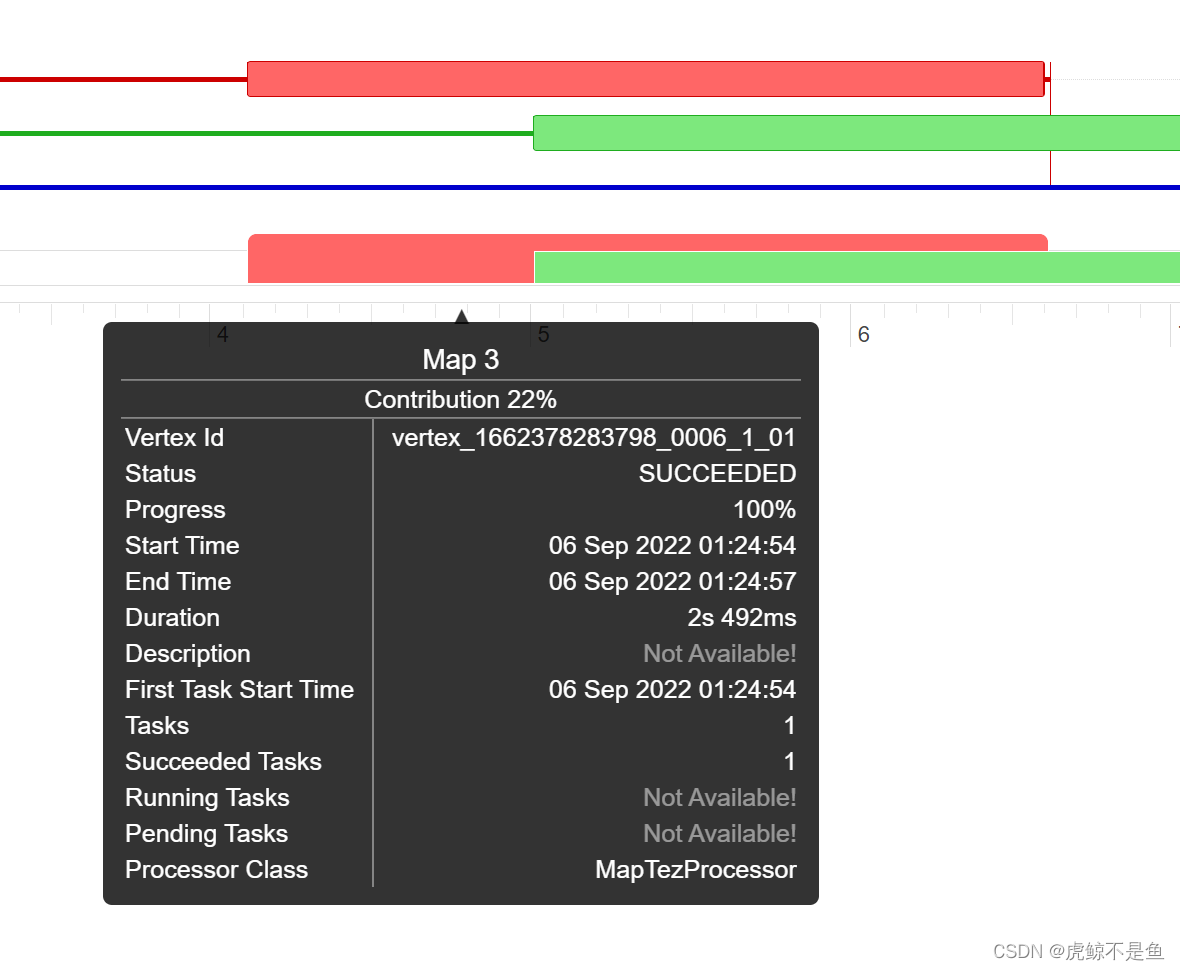
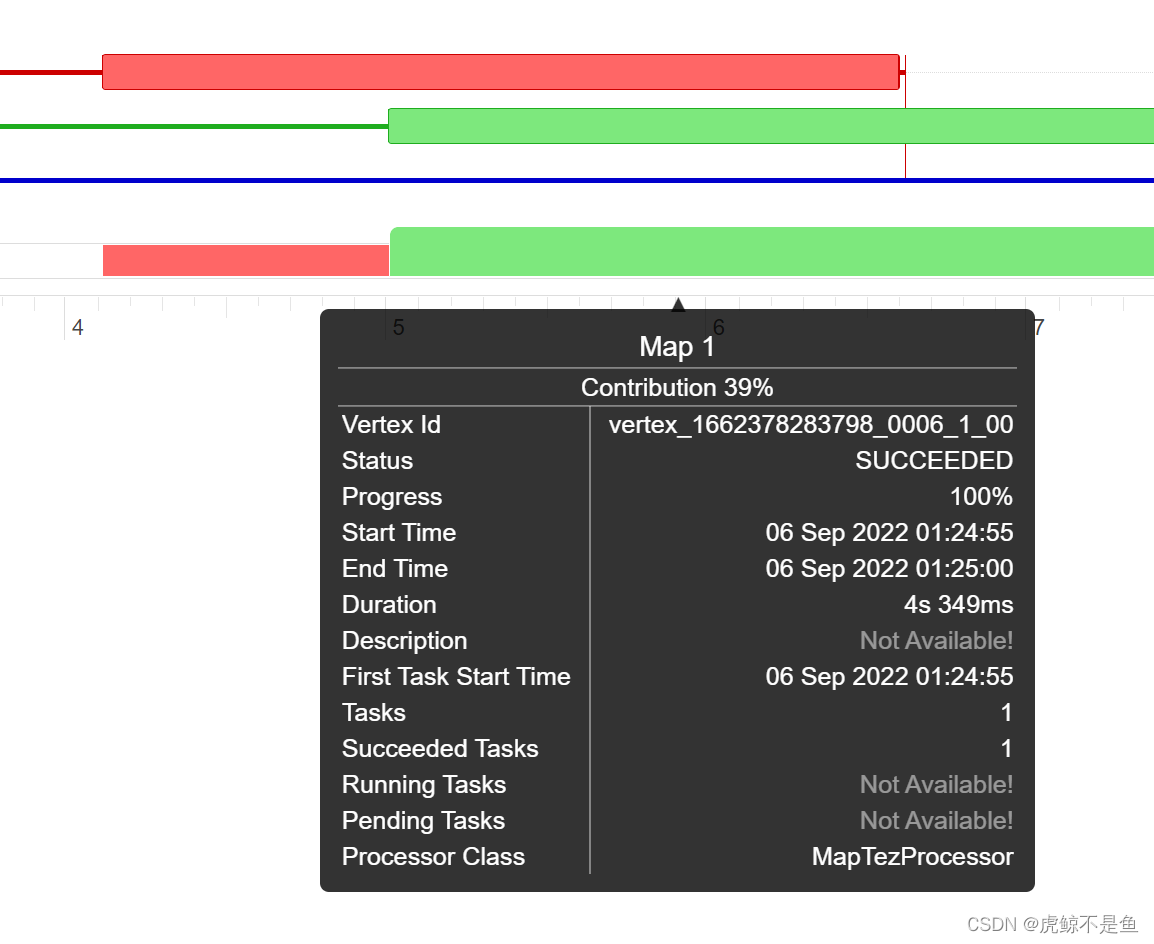

这里的Map3和Map1可不单单是先后顺序,还有一部分重叠,Map3的柱图被Map1遮盖了!!!
于是可以看出先后执行2个Map任务【Map1和Map3】读数据,读完后执行了一个Reduce任务【Reduce2】去做Shuffle混洗和汇总结果。
由于Map1读的t1表数据量比Map3读的t2表数据量大一点,故运行时间稍长。
这类有Shuffle的多表Join任务分析问题相当麻烦,且随着参与Join的表个数增多、条件越发复杂、HQL越套越长,性能指数级下降,最终遇到明显的性能问题就不得不考虑调优【调参也是调优的一种】。Shuffle过多时,可以将常用的、数据量不大的表缓存到Alluxio或者使用Alluxio做RSS【Spark可以,Tez尚未尝试】加速Shuffle。
查看Yarn日志
最稳妥的当然是查看Yarn的日志。
yarn logs -applicationId application_1662378283798_0006 > /root/tezLog1- 1
重定向后的Log删减掉无用内容后也有1000多行。。。
这种Info级别的Log删除无用部分后依旧很多很乱,直接看不可能不累。如果是肤浅的SQL Boy们最喜欢的几十个表Join写几千行的一句HQL,那Yarn的Log复杂度可能不是人看的。。。Web UI的实际意义
由于人都是对图形更敏感,根据每个stage的耗时情况结合DAG可以分析出整个Tez任务的瓶颈在哪里,协助定位有性能问题的HQL段【聚焦主要问题】,从而可以高效地分析问题,并且有针对性地调优,解决因数据倾斜、SX锁、资源不足等多种原因导致的性能差的问题。
如果只局限于从SQL层面肉眼分析,只从数据库的那种传统模式考虑SQL层面的优化,例如agg运算不动,先agg再union all数据集再agg,不能说完全无用。。。数据倾斜之类的问题可能根本不是出现在这里。对于非SQL问题,不去看Log,只是傻傻地改HQL,可能也是南辕北辙。
转载请注明出处:https://lizhiyong.blog.csdn.net/article/details/126717025

-
相关阅读:
excel如何加密(excel加密的三种方法)
c++通过tensorRT调用模型进行推理
TDA4VM/VH 单核软复位原理与实现实现
Git学习笔记8
MATLAB算法实战应用案例精讲-【优化算法】混合领导优化算法(HLBO)(附MATLAB和Python代码实现)
MySQL的优化多种方法
如何挂载镜像文件(两种方法) 以及利用镜像文件配置本地yum源
R16 Type II量化反馈码本的产生
基于.net的应用开发技术-作业二
TSINGSEE青犀视频AI分析/边缘计算/AI算法·厨师帽检测功能——多场景高效运用
- 原文地址:https://blog.csdn.net/qq_41990268/article/details/126717025