-
半量化交易(二)
个人交易中的专业背景限制、资金成本限制、对股市的理解限制等等,使个人在进行量化交易时,可能出现程序推荐股票不是自己像买股票这种情况,由于投资者自身能力有限,不能全面的考虑可能出现的各种可能,所有在选择上可能存在异常的偏差。因此,本问将为个人投资者介绍另一种简单容易实现的方法,半量化交易。本文接下来也将对半量化股票的选股、指标建立、模型搭建、数据存储进行研究。
按照数据存储的方式不同,我们将数据划分为4个层次:
ODS层:存储原始数据
DW层:存储根据ODS层计算处理、晒选出来的数据
DM层:存储DW 层中根据数据合并组合,形成的大宽表。
APP层:直接可以拿来使用的数据

三、具体实现
数据源为我们选择非常友好的tushare 数据。https://tushare.pro/register?reg=379880
里面有非常多的数据,质量也非常好,非常推荐。
在这里,我们主要选择两个方面的数据:1、日线行情数据 2、基础数据中的备用数据。

具体实现:
我们定义一个时间函数,用来对计算交易日期。并通过下面方法来获取最近一个交易日的日期。
- # 引入 datetime 模块
- import datetime
- def getYesterday(days):
- #输入距离今天几天
- today=datetime.date.today()
- #间隔天数
- interval_day=datetime.timedelta(days=days)
- #今天往前推
- yesterday=today-interval_day
- date_time = str(yesterday).replace('-','')
- return date_time
- def compute_time():
- # 今天
- now_day = getYesterday(0)
- #一个月前
- month_day = getYesterday(30)
- #昨2年前
- history_day = getYesterday(365*2)
- return now_day,month_day,history_day
- #获取交易列表
- trade_time=pro.trade_cal(exchange='', is_open=1,start_date=month_day, end_date=now_day)
- #获取最近的交易日期
- trade_time = trade_time['cal_date'].tail(1).values[0]
数据的获取方法也非常简单,先读取数据库表中数据的交易日(记得去重),判断最近一个交易日是否在数据库中,如果有就不导入,如果无就进行数据获取。这样数据就获取出来了。

- #基础表数据存入数据库
- def bak_basic_to_sql(trade_time):
- #查询数据库中已经存在的基础表,避免重复插入
- all_time = connect_sql("select DISTINCT trade_time from `ods_bak_basic` ")
- #将所有时间转换为列表,循环
- if all_time['trade_time'].values.tolist()==[]: #判断是否为空
- print("数据库表 ods_bak_basic 数据为空 ,可导入")
- #获取最近交易日的基础信息
- bak_basic_data = pro.bak_basic(trade_date=trade_time)
- #对表数据进行重新命名
- bak_basic_data = bak_basic_data.rename(columns={'trade_date': 'trade_time','close':'close_price'})
- #数据插入数据库中
- inset_into_sql(bak_basic_data,'ods_bak_basic')
- print('ods_bak_basic {} 日数据插入成功'.format(trade_time))
- else:
- if trade_time in all_time['trade_time'].values.tolist():
- print("数据库表 ods_bak_basic 存在 {} 日期数据,不可导入".format(trade_time))
- else:
- print("数据库表 ods_bak_basic 不存在 {} 该日期数据,可导入".format(trade_time))
- #获取最近交易日的基础信息
- bak_basic_data = pro.bak_basic(trade_date=trade_time)
- #对表数据进行重新命名
- bak_basic_data = bak_basic_data.rename(columns={'trade_date': 'trade_time','close':'close_price'})
- #数据插入数据库中
- inset_into_sql(bak_basic_data,'ods_bak_basic')
- print('ods_bak_basic {} 日数据插入成功'.format(trade_time))
- return bak_basic_data
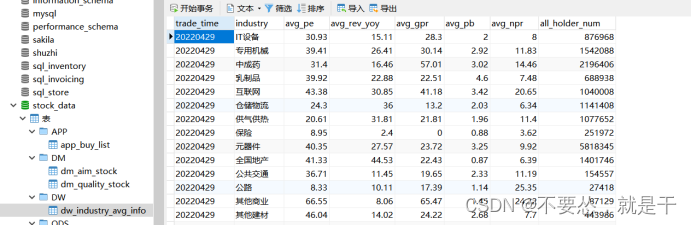
2、DW 层
DW层里面存储行业数据,计算行业的平均(用数据透视方法就可以算了)市盈率、市净率、毛利润、同比收入等指标,每日计算一次,存储到数据库中。这里计算时需要注意一下,去除异常值。
- #将数据交易日、行业、市盈率、市净率、收入同比、毛利率、净利润等指标统计数据存入数据库中
- def industry_avg_inset_sql(bak_basic_data,trade_time):
- #查询数据库中已经存在的基础表,避免重复插入
- all_time = connect_sql("select DISTINCT trade_time from `dw_industry_avg_info` ")
- #将所有时间转换为列表,循环
- if all_time['trade_time'].values.tolist()==[]:
- print("数据库表 dw_industry_avg_info 为空,可导入")
- #d对数据进行处理
- industry_avg_info = industry_avg_compute(bak_basic_data)
- inset_into_sql(industry_avg_info,'dw_industry_avg_info')
- print('dw_industry_avg_info {} 日数据插入成功'.format(trade_time))
- else:
- if trade_time in all_time['trade_time'].values.tolist():
- print("数据库表 dw_industry_avg_info 存在 {} 日期数据,不可导入".format(trade_time))
- else:
- print("数据库表 dw_industry_avg_info 不存在 {} 该日期数据,可导入".format(trade_time))
- #d对数据进行处理
- industry_avg_info = industry_avg_compute(bak_basic_data)
- #数据插入数据库中
- inset_into_sql(industry_avg_info,'dw_industry_avg_info')
- print('dw_industry_avg_info {} 日数据插入成功'.format(trade_time))
3、DM层
DM层存储两个方面的数据。
- 结合行业平均等指标,筛选出来的优质股票信息。
- 根据优质股票信息,筛选出具有突破形态和“碗口战法”形态的股票信息。
获取数据时候需要注意一下请求频率,很容易超时。我解决的办法时将股票列表存储到一个list里面,每次pop一个数据,成功则过,失败了,将请求失败的股票append回去股票列表继续请求。这样可以重复请求,和请求失败导致程序中停问题。

- #将筛选出来的优质股票信息存储到数据库中
- def quality_stock_to_sql(trade_time):
- #查询数据库中已经存在的基础表,避免重复插入
- all_time = connect_sql("select DISTINCT trade_time from `dm_quality_stock` ")
- #将所有时间转换为列表,循环
- if all_time['trade_time'].values.tolist()==[]:
- print("数据库表 dm_quality_stock 为空,可导入")
- #对数据进行处理
- dm_quality_stock = quality_stock_deal(trade_time)
- inset_into_sql(dm_quality_stock,'dm_quality_stock')
- print('dm_quality_stock {} 日数据插入成功'.format(trade_time))
- else:
- if trade_time in all_time['trade_time'].values.tolist():
- print("数据库表 dm_quality_stock 存在 {} 日期数据,不可导入".format(trade_time))
- else:
- print("数据库表 dm_quality_stock 不存在 {} 该日期数据,可导入".format(trade_time))
- #d对数据进行处理
- dm_quality_stock = quality_stock_deal(trade_time)
- #数据插入数据库中
- inset_into_sql(dm_quality_stock,'dm_quality_stock')
- print('dm_quality_stock {} 日数据插入成功'.format(trade_time))
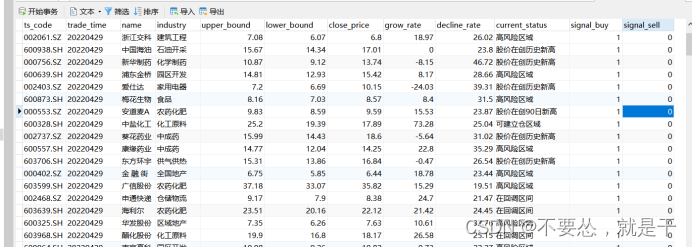
4、APP层
该层存储的是目标股票状态。更具波浪理论,我们选择使用中线理论,对股票一段时间内的波段进行计算,推算出股票的目前状态,所处的历史位置,以及计算股票的回调区间、利润区间。
- def app_buy_list_to_sql(trade_time):
- #查询数据库中已经存在的基础表,避免重复插入
- all_time = connect_sql("select DISTINCT trade_time from `app_buy_list` ")
- #将所有时间转换为列表,循环
- if all_time['trade_time'].values.tolist()==[]:
- print("数据库表 app_buy_list 为空,可导入")
- #对数据进行处理
- app_buy_list_sql_deal(trade_time)
- else:
- if trade_time in all_time['trade_time'].values.tolist():
- print("数据库表 app_buy_list 存在 {} 日期数据,不可导入".format(trade_time))
- else:
- print("数据库表 app_buy_list 不存在 {} 该日期数据,可导入".format(trade_time))
- #d对数据进行处理
- app_buy_list_sql_deal(trade_time)
四、实践一下
我们采取保守策略,所有只筛选“可建仓区域的股票” 。具体效果还是可以的。


好了,大概就这样,后面慢慢更新。
-
相关阅读:
React高阶组件详解
范数-空间范数
LLFormer 论文阅读笔记
Java并发编程学习十:线程协作
leetcode:279.完全平方数
pandas连接oracle数据库并拉取表中数据到dataframe中、筛选当前时间(sysdate)到一天之前的所有数据(筛选一天范围数据)
测试用例常见的7种设计方法
linux 多台机器修改时间同步
记一次调试YOLOv5+DeepSort车辆跟踪项目的经过
Prometheus+grafana监控--初探
- 原文地址:https://blog.csdn.net/weixin_42013825/article/details/126710277
