-
API 文档搜索引擎
提示:以下是本篇文章正文内容,Java系列学习将会持续更新一、项目简介
该项目类似于百度搜索引擎,在搜索框内输入一个 Java API 文档的关键字,对后端发出请求,后端将处理后的若干条查询结果返回给前端展示,并且按照一定的权重排序展示出来。每条搜索结果包含了标题、描述、URL,点击标题可以跳转到官方文档。
- 开发环境:IDEA、Maven、JDK 1.8、MySQL
- 相关技术:正排索引、倒排索引、分词技术、线程池、Spring Boot、JSON、Ajax
- 本地资源:Java API 文档
官方文档下载地址
项目主要分为3个模块:
- 索引模块:扫描本地 API 文档,分析内容(使用 Ansj 分词技术),构建正排+倒排索引;
- 搜索模块:输入查询词,基于倒排索引检索,根据分词权重+正排索引,展示查询结果;
- 前端模块:编写简单页面,对搜索结果作 CSS 布局,结合标签跳转到对应的 API 文档;
二、索引模块
2-1 ansj 分词
引入 ansj 依赖,将本地的 API 文档 进行分词处理,以便计算每个词的权重。
<dependency> <groupId>org.ansjgroupId> <artifactId>ansj_segartifactId> <version>5.1.6version> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
将分出来的词,放入 List 中。
List<String> words = ToAnalysis.parse(str);- 1
2-1 正排索引
正向索引就是:通过title(文档ID),去找value(目标文档),然后确定出包含的 文档 URL、content,将这些文档展示给用户。

正排索引的表中,tilte 是不重复的,每一个 title 对应唯一的 URL 和 content。
构建: 遍历每个文档的标题,并且存储其 URL 和 content。如何提取本地的.html文档的内容?
使用 Java 正则表达式 去除HTML文件中的<标签>, 只保留文本格式。return contentBuilder.toString() // 首先去掉 .replaceAll("- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2-2 倒排索引
倒排索引就是:通过value(关键词),去找key(文档ID),然后将找到的结果,即这些文档,展示给用户;
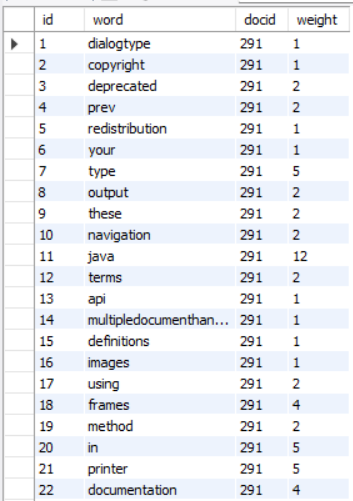
倒排索引的表中,(word, weight) 的组合是不重复的,每一组合都会有对应的文档ID,单词权重。
构建: 遍历每个文档中的所有词,每个文档插入countDifferentWord条数据到表中,(word[i], docid, weight(word[i]))。如何计算单词的权重?
因为按照用户的搜索逻辑来说,文档标题的权重是自然要比内容中的单词权重高一些的。所以在计算时,适当的给标题提高权重。int weight = titleCount * 10 + contentCount;- 1
三、搜索模块
- 键入
query关键词,先对 query 进行分词,得到queryList。 - q
queryList中可能出现多个关键词。针对每个关键词去倒排索引中查找,每个关键词都有若干条结果,把所有结果添加到 List中。 - 再对 List 中的所有结果,根据权重值排倒序(权重值高的靠前)。
- 此时,将所有结果以 JSON 的格式传递给前端,前端进行分页展示。
每页包含20条结果,每条结果包含标题、内容(全文的前120字+后120字)、URL。
四、数据库
- 我们使用的数据库是 MySQL 。
- 我们在学习过 Spring 后,我们为了代码的便洁,不再采用传统的 JDBC 操作,而是引入了 MyBatis 。
出现的问题: 由于数据量非常大
(正排索引1万条, 倒排索引20万条),导致构建索引的过程非常耗时,同时搜索时性能也比较差。优化的过程:
-
最开始 —— 单线程+当行插入——耗时>3小时。
-
第一次优化:单线程+批量插入——耗时约3分钟。
使用mapper.xml + @Mapper的方式执行 SQL 语句。
原因:单纯的@Insert的使用,无法完成SQL的批量插入。
正排索引每次插入10条,因为正排索引的单条数据量就比较大(包含了文本内容)。
倒排索引每次插入10000条,单条数据量小。
<mapper namespace="com.wangshaoyu.search.indexer.mapper.IndexDatabaseMapper"> <insert id="batchInsertForwardIndexes" useGeneratedKeys="true" keyProperty="docId" keyColumn="docid"> insert into forward_indexes (title, url, content) values <foreach collection="list" item="doc" separator=", "> (#{doc.title}, #{doc.url}, #{doc.content}) foreach> insert> <insert id="batchInsertInvertedIndexes"> insert into inverted_indexes (word, docid, weight) values <foreach collection="list" item="record" separator=", "> (#{record.word}, #{record.docId}, #{record.weight}) foreach> insert> mapper>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 第二次优化:多线程+批量插入——耗时约16秒。
ThreadPoolExecutor executor = new ThreadPoolExecutor( 8, 20, 30, TimeUnit.SECONDS, new ArrayBlockingQueue<>(5000), (Runnable task) -> { Thread thread = new Thread(task); thread.setName("批量插入线程"); return thread; }, new ThreadPoolExecutor.AbortPolicy() );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 第三次优化:在构建好的倒排索引表中,添加索引关联到 word 和 weight。
-- 插入数据后,再构建索引 ALTER TABLE `searcher`.`inverted_indexes` ADD INDEX `INDEX_word_weight` (`word` ASC, `weight` DESC); ;- 1
- 2
- 3
- 4
五、展示效果
项目访问地址:http://1.15.76.95:8019
主页:
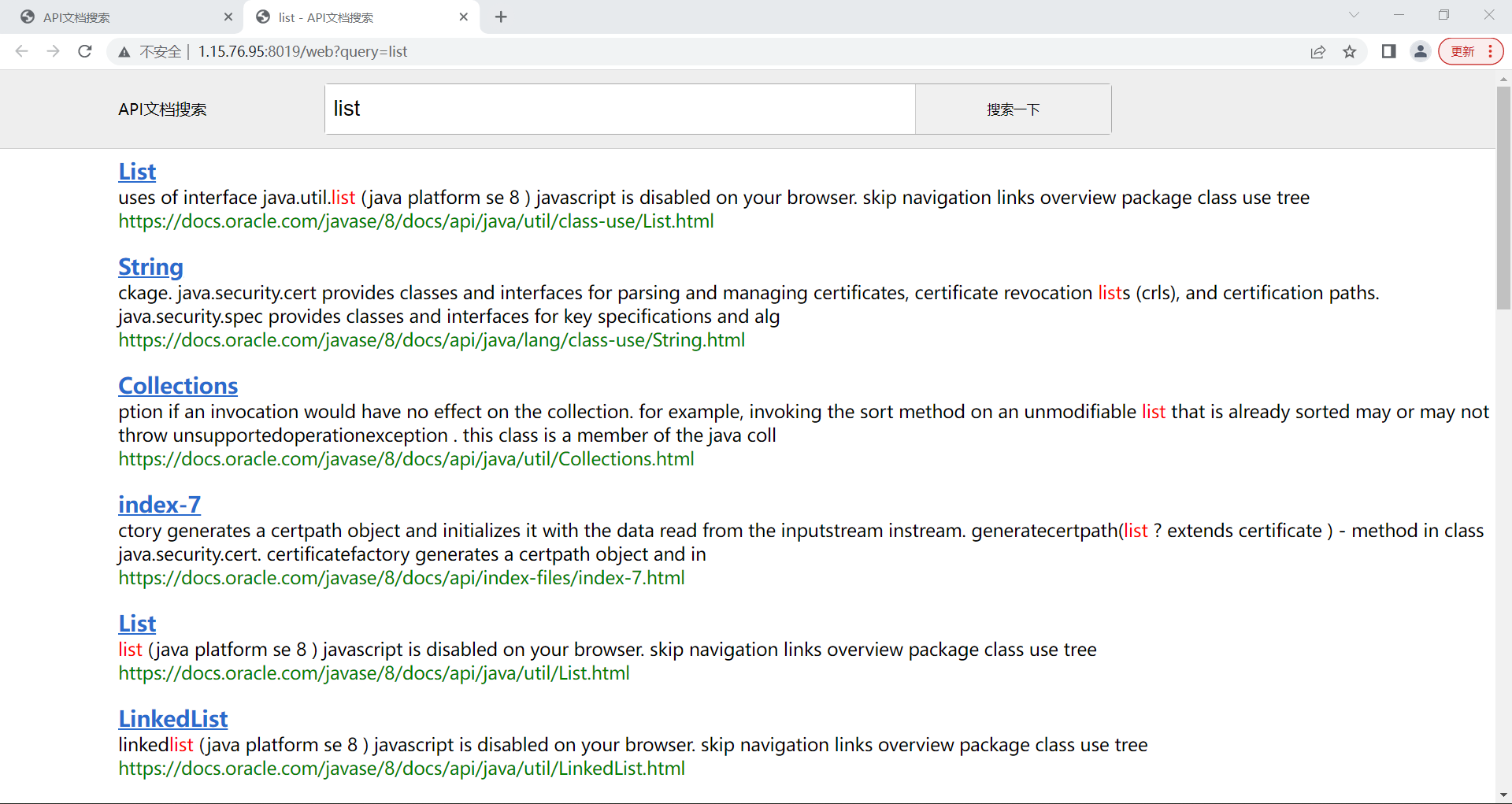
查询结果页:
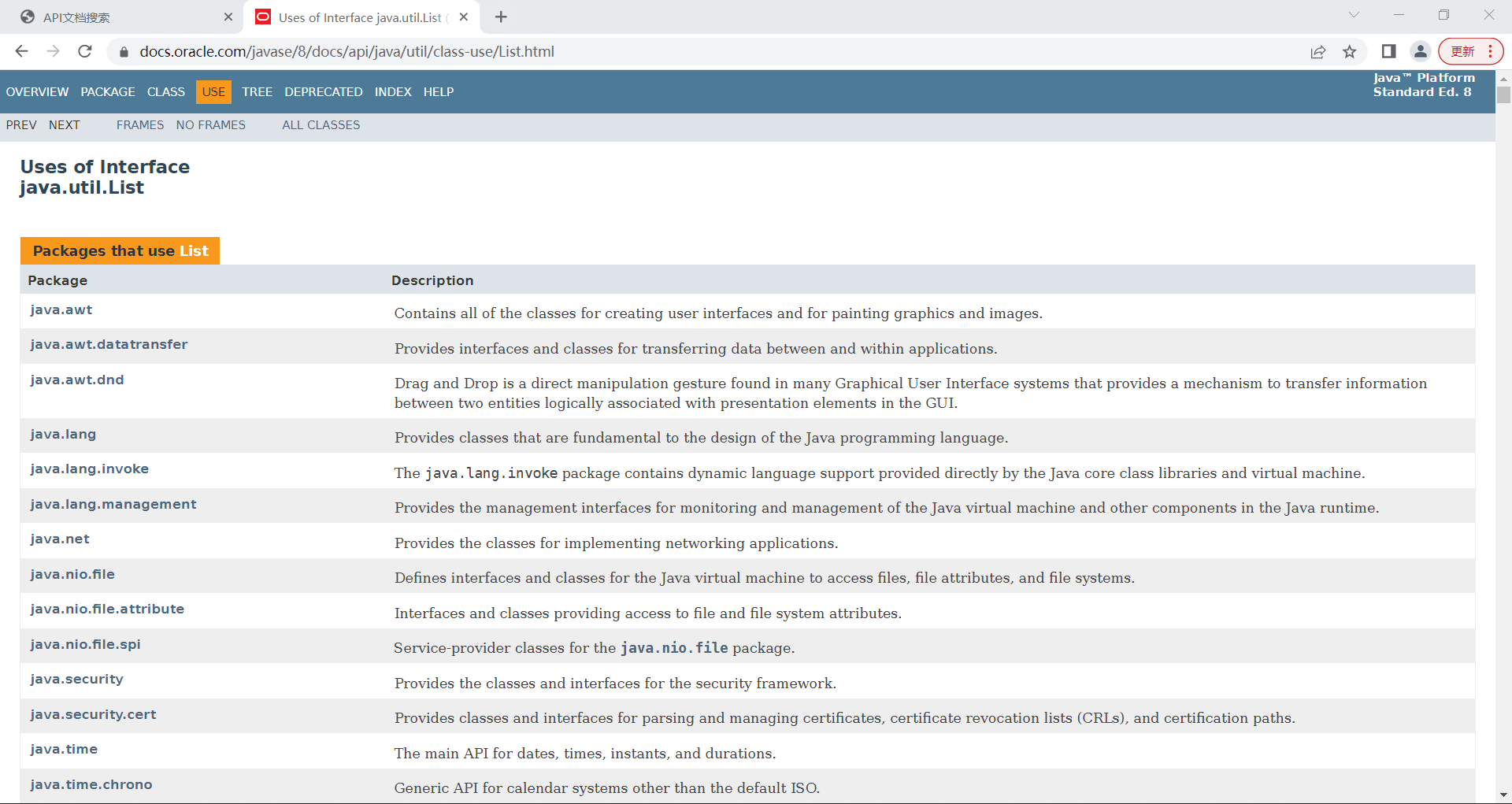
点击跳转到官方文档:
六、待优化
- 前端页面的优化。
- 分词技术不够好,有些连续的单词没必要分,有些分出来的词没有意义,应该舍弃。
- 搜索不够好:目前不具备模糊查询的效果。
- 应该添加过滤器
搜索引擎过滤器:许多搜索引擎(例如Google和Bing)都为用户提供了打开安全过滤器的选项。激活此安全过滤器后,它会过滤掉所有搜索结果中的不适当链接。如果用户知道具有显式内容或成人内容的网站的实际网址,则他们可以在不使用搜索引擎的情况下访问该内容。一些提供商提供面向儿童的引擎版本。
总结:
提示:这里对文章进行总结:
以上就是今天的学习内容,该项目类似于百度搜索引擎,在搜索框内输入一个 Java API 文档的关键字,对后端发出请求,后端将处理后的若干条查询结果返回给前端展示,并且按照一定的权重排序展示出来。之后的学习内容将持续更新!!! -
相关阅读:
数据分析中的数学:从基础到应用20240617
springmvc-页面跳转&表单标签&其他标签&tomcat控制台中文乱码问题
贪心算法(一)
运用程序化交易系统的能力表现在哪些方面?
追剧系列 《计算机程序的构造和解释》
全国大学生电子设计竞赛参赛分享
A1078 Hashing(25分)PAT 甲级(Advanced Level) Practice(C++)满分题解【哈希表】
NCB:神经元线粒体应激记忆可通过mtDNA水平升高跨代遗传
六级作文---3.图画类
访问学者在美国访学生活的实用攻略
- 原文地址:https://blog.csdn.net/qq15035899256/article/details/126688080
