-
插入一百万数据的最优解分析和耗时
很多业务情况会有导入功能,可能是提交一批数据进行插入,所以现在需要用一种可行性高的读取以及插入的实现方案。
本文gitee项目地址:BigDataImportProject: 从文件读取大数据量,并写入到数据库中
在dev分支中
机器:cpu是Amd1500x,内存16G,固态硬盘
第一步,有数据量
使用WriteTxtDataService类去生成一百万的数据,创建文件后,使用FileOutputStream写入到文件中。
- private static void writeData() throws IOException {
- try (FileOutputStream fos = new FileOutputStream(Constant.getFilePath())) {
- byte[] c = new byte[2];
- c[0] = 0x0d;
- c[1] = 0x0a;
- String value = new String(c);
- int a = Constant.allNum;
- Random random = new Random();
- while (a > 0) {
- long str = random.nextLong();
- fos.write((str + value).getBytes());
- a--;
- }
- }
- }
第二步,分批读取数据
将所需的数据集分批读取,这里采用了BufferReader去读取文件,这个读取的过程非常快,因为这个jdk下的包,直接操作字节数据的,从跳跃万行数据到写入仅需十多毫秒,看机器情况。
(前提:文件内容不会发生改变,是只读文件)
步骤如下:
①指定当前批次batchNum,每批次所读取的数据量大小batchCount。②根据这两个值,跳跃到需读取的行
②读取batchCount行后,写入到list中
- private static List
getListByBatch(int batchNum) throws IOException { - Integer batchCount = Constant.batchCount;
- File file = new File(Constant.getFilePath());
- BufferedReader bufferedReader = new BufferedReader(new FileReader(file));
- int currentNode = (batchNum - 1) * batchCount;
- // 移动到所要读取的行
- for (int i = 0; i < currentNode; i++) {
- bufferedReader.readLine();
- }
- int count = 0;
- String s = null;
- List
list = new LinkedList<>(); - // 读取批次
- while ((s = bufferedReader.readLine()) != null && count < batchCount) {
- count++;
- list.add(s);
- }
- return list;
- }
第三步,开启数据库连接的批处理
这一步非常重要,rewriteBatchedStatements=true,可以让MySQL接收批量提交的sql,这样我们在进行事务的批量提交时,就能够一次性把sql发送给MySQL。否则就是一条条发送给MySQL,效率极低。
- Connection conn =
- DriverManager.getConnection("jdbc:mysql://localhost:3306/" +
- Constant.databaseName + "?rewriteBatchedStatements=true",
- Constant.userName,
- Constant.passWord);
第四步,批量插入
获取到构建好的数据集,关闭事务的自动提交,并且添加多批数据,一次性提交事务给MySQL,结合前面的rewriteBatchedStatements,这样MySQL就能够一次性处理大批数量的sql语句。
- public static void saveInfoByBatch(List
list) { - PreparedStatement pstmt = null;
- try {
- conn.setAutoCommit(false);
- String sql = "insert into " + Constant.tableName + " values (?)";
- pstmt = MySqlOptUtil.getPreparedStmt(conn, sql);
- for (String aList : list) {
- pstmt.setString(1, aList);
- // 添加数据
- pstmt.addBatch();
- }
- // 执行事务
- pstmt.executeBatch();
- conn.commit();
- } catch (SQLException e) {
- e.printStackTrace();
- MySqlOptUtil.closeStmt(pstmt);
- }
- }
有朋友就好奇了,我组装一条大sql去插入会怎么样?
前提是要将MySQL的max_allowed_packet设置的很大,默认是1MB的,我改成了100MB,实际业务场景传输的数据量的包大小可能会更大~
这里也有实现方式,只不过组装数据的时候比较麻烦,但是设置一批10000条数据去提交的情况下,批量提交和组装大sql的提交,效率是差不多的,以下是实现代码:
- public static void saveInfo(List
list) { - Connection conn = null;
- PreparedStatement pstmt = null;
- try {
- conn = MySqlOptUtil.getConn();
- StringBuilder builder = new StringBuilder();
- builder.append("insert into ").append(Constant.tableName).append(" (big_value) values ");
- list.forEach(t -> builder.append("('").append(t).append("'),"));
- String sql = builder.toString();
- sql = sql.substring(0, sql.length() - 1);
- pstmt = MySqlOptUtil.getPreparedStmt(conn, sql);
- pstmt.executeUpdate();
- } catch (SQLException e) {
- log.error("执行失败", e);
- } finally {
- MySqlOptUtil.closeStmt(pstmt);
- MySqlOptUtil.closeConn(conn);
- }
- }
还有的大兄弟会说,我们业务都是用mybatis的呀,哪有人用jdbc,所以这里我也引入了mybatis-pus的依赖,做了插入,批量条数设置为集合的长度了,因为默认的一千条太慢了。
- private static void saveInfoByMybatisPlus(List
list) { - List
tableList = list.stream().map(t -> new BigTable().setBigValue(t)).collect(Collectors.toList()); - BigTableSerive bigTableSerive = SpringUtil.getBean(BigTableSerive.class);
- bigTableSerive.saveBatch(tableList, tableList.size());
- }
当然rewriteBatchedStatements也是要开启的
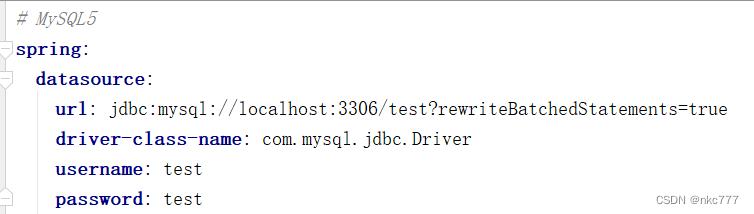

实际的打印结果显示,mybatis-plus是组装成一条大sql去提交数据的,所以和分一条条sql的性能没什么大的区别,(通过上述分点得知)。
线程对比的实际执行效果:
单线程:

多线程:
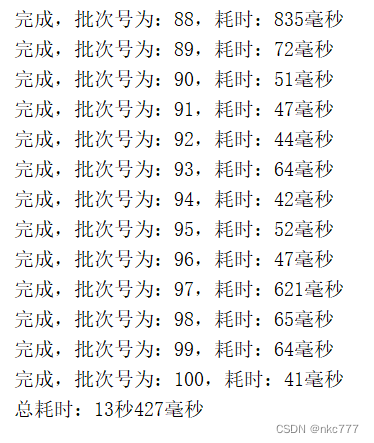
由此可见,单线程和多线程的效率相差不大。
原生jdbc和mybatis-plus的执行效果对比

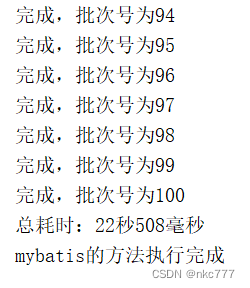
因为有容器的加载,所以jdbc的耗时比main方法的耗时会多个一两秒。
接口请求的情况下,原生jdbc平均耗时16秒,mybatis-plus平均耗时23秒。
相差百分之三四十!你问我选哪种,撸码肯定还是mybatis-plus的。性能差距在可接受的范围之内。
总结
- 要开启rewriteBatchedStatements=true,使得数据集可以大批提交
- 当每条sql的数据量很大时,根据实际数据量的情况,考虑是减少单条sql数据量,还是增大max_allowed_packet单次允许提交的数据量,一般是前者
- 使用BufferReader去操作文件读取会非常快,毫秒级的处理响应
参考文章:
集成mybatis-plus:SpringBoot集成Mybatis-Plus - 腾讯云开发者社区-腾讯云
-
相关阅读:
“谈谈如何理解索引?谈谈如何理解事物?”我来带你模拟面试~
Socks5代理与代理IP技术:网络工程师的全能武器
ChatGLM2-6B Lora 微调训练医疗问答任务
私有gitlab的搭建和配置教程
StarRocks 支持 Apache Hudi 原理解
Container is running beyond memory limits
基于JSP的二手车交易网站
Jetson平台180度鱼眼相机畸变校正调试记录
大数据培训企业开发案例实时读取目录文件到HDFS案例
ELK Stack日志采集架构详解
- 原文地址:https://blog.csdn.net/weixin_41605123/article/details/126688101
