-
目标检测 YOLO 系列模型
前言
YOLO (You Only Look Once) 系列模型追求实时目标检测,因此会在一定程度上牺牲精度,以实现更高的检测速度。
如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。
目标检测评价指标
IoU
模型预测框的 IoU 值与 IoU 阈值进行比较,若大于阈值,即为正确的检测,否则为错误的检测。

mAP
目标检测中,每个预测框都对应一个置信度,不同的置信度阈值,意味着最终留下的预测框的不同。
AP 是针对目标检测中某个单独的类别的检测效果,即在同一 IoU 阈值下,通过调整置信度阈值,得到 P-R 曲线,其下方面积即为 AP 值。相应地,mAP 即是所有类别的 AP 值取平均后的结果。
mAP = 1 C ∑ i = 1 C AP i \text{mAP}=\frac{1}{C}\sum_{i=1}^C \text{AP}_i mAP=C1i=1∑CAPi

YOLOv1
论文链接:[CVPR16 - Joseph Redmon] You Only Look Once: Unified, Real-Time Object Detection
网络架构
整体网络架构如下:

可以看到开始的输入被固定为 448x448x3,输出被固定为 7x7x30,其中输出的含义为将原始输入图片划分为 7x7 的网格,其中每个网格包含 30 维信息(x, y, w, h 均为归一化后结果):- 1~5:当前网格对应预测框 1 的信息,框中心 x、y 坐标,宽度 w,高度 h,置信度 c
- 6~10:当前网格对应预测框 2 的信息,框中心 x、y 坐标,宽度 w,高度 h,置信度 c
- 11~30:对 20 个类别的预测概率
损失函数

其中对 w、h 开根再求差,是为了放大小物体检测框的权重,因为 y = x y=\sqrt{x} y=x 在数值较小时变化更剧烈。模型特点
- 优点:
- 快速、简单
- 不足:
- 每个网格只预测一个类别,如果物体重叠,则难以识别
- 只有两个预选框,小物体检测效果一般
YOLOv2
论文链接:[CVPR17 - Joseph Redmon] YOLO9000:Better, Faster, Stronger
改进方案
- Batch Normalization
- v2 舍弃 Dropout,卷积后全部加入 Batch Normalization,即网络的每一层的输入都做了归一化,使收敛更容易
- 经过 BN 处理后的网络会提升 2% 的 mAP
- 更大的分辨率
- v1 训练时用 224x224,测试时使用 448x448;因此 v2 训练时再额外进行 10 次 448x448 的微调
- 该项改进提升 4% 的 mAP
- 网络结构改变
- 采用 Darknet-19,去除所有全连接层,进行 19 次卷积,且再进行 5 次降采样,以及多次 1x1 卷积,节省大量参数
- 每一层卷积核尺寸都较小,原因在于多个小卷积核比一个大卷积核更省参数,以及多个小卷积核,每次卷积后再进行 BN,网络输出更稳定
- 最终输出从 7x7 提升至 13x13,预测的框更多了

- 聚类提取先验框
- faster-rcnn 中选取的先验框比例都是常规的,而 v2 中先验框大小通过对训练集中标注的边框进行 k-means 聚类,其中聚类采用的距离形式如下(欧式距离对大框和小框不公平):
d ( box, centroids ) = 1 − IOU ( box, centroids ) d(\text { box, centroids })=1-\operatorname{IOU}(\text { box, centroids }) d( box, centroids )=1−IOU( box, centroids ) - 根据 k 和 Avg IOU 曲线,选择 k = 5
- faster-rcnn 中选取的先验框比例都是常规的,而 v2 中先验框大小通过对训练集中标注的边框进行 k-means 聚类,其中聚类采用的距离形式如下(欧式距离对大框和小框不公平):
- 预测框偏移量计算
- 原先的
x
=
x
p
+
w
p
∗
t
x
x=x_p+w_p*tx
x=xp+wp∗tx 为直接偏移量,存在收敛问题,导致模型不稳定;因此修改为相对网格的偏移,使得中心点不会偏移出网格:

- 计算举例(根据预测值,以及一开始聚类得到的先验框大小,得到最终的预测框):

- 原先的
x
=
x
p
+
w
p
∗
t
x
x=x_p+w_p*tx
x=xp+wp∗tx 为直接偏移量,存在收敛问题,导致模型不稳定;因此修改为相对网格的偏移,使得中心点不会偏移出网格:
- 特征融合
- 最后一层感受野(特征图上的点能看到原始图像的区域)太大了,小目标可能丢失,因此与之前的特征进行融合

- 最后一层感受野(特征图上的点能看到原始图像的区域)太大了,小目标可能丢失,因此与之前的特征进行融合
- 适配多尺度输入
- 由于网络中不再有全连接层,因此可以适配多尺度的输入
改进结果

YOLOv3
论文链接:[arXiv18 - Joseph Redmon] YOLOv3: An Incremental Improvement
改进方案
- 多 scale
- 为了检测不同大小的物体,设计了 3 个 scale
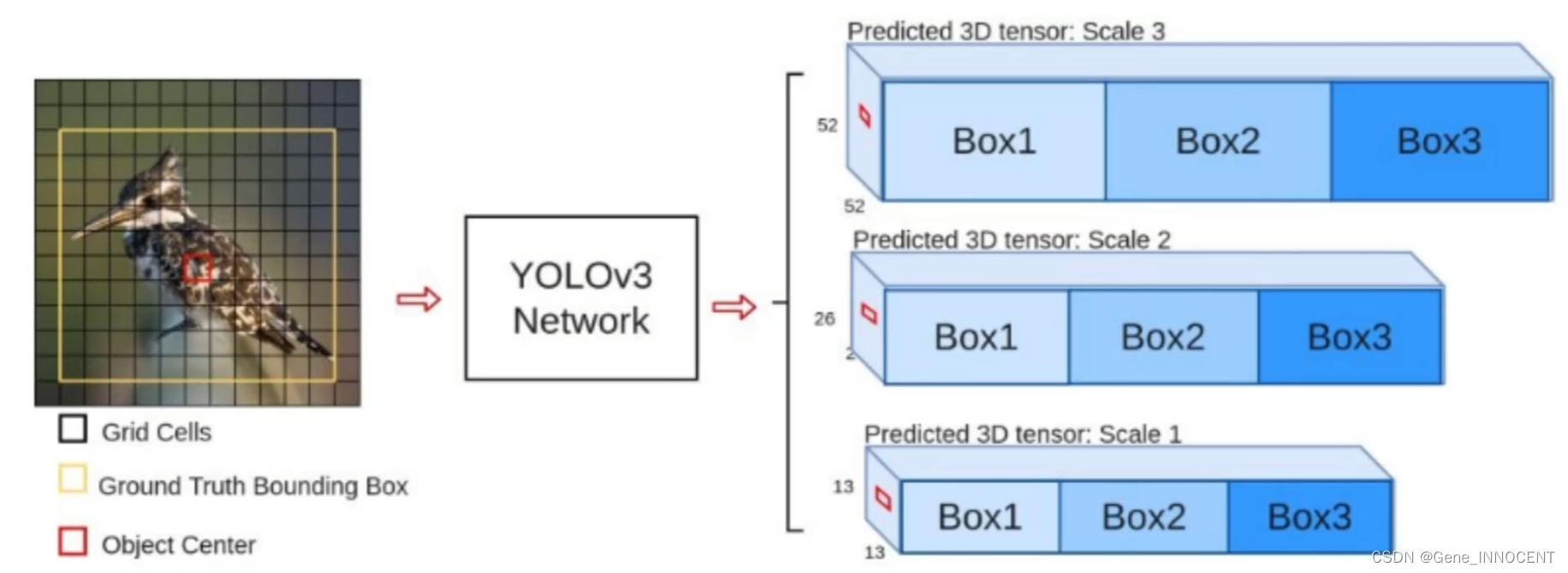
- 为了检测不同大小的物体,设计了 3 个 scale
- 网络架构修改
- 将 multi scale 进行融合
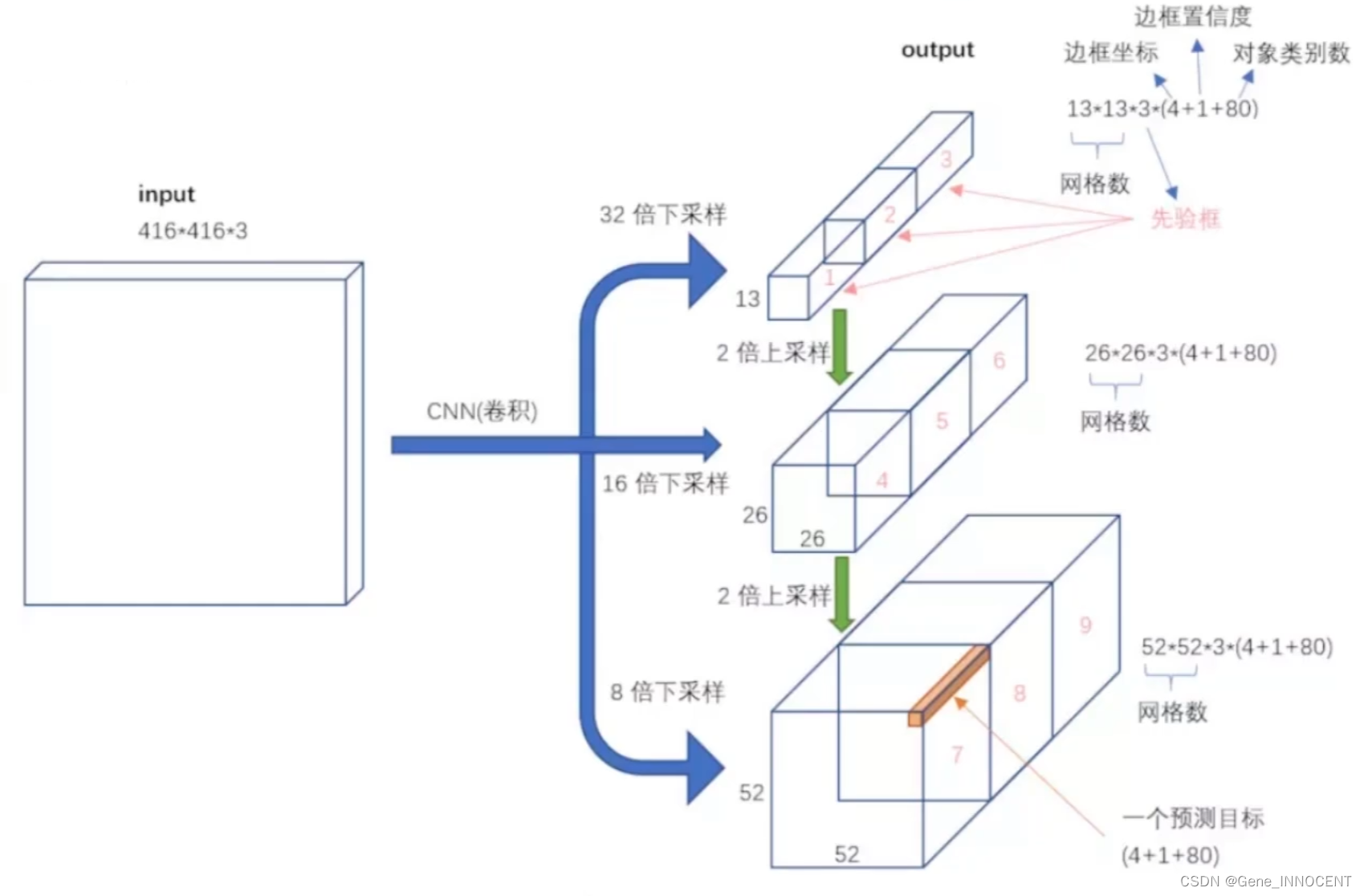

- 将 multi scale 进行融合
改进效果
神图:效率与性能远程其它模型

YOLOv4
论文链接:[CVPR20 - Alexey Bochkovskiy] YOLOv4: Optimal Speed and Accuracy of Object Detection
网络架构

注意其中的 multi-scale 融合,从 YOLOv3 中只有第二部分(自下而上),增加了第三部分(自上而下),并且融合的方式从原先的直接相加,变为了深度拼接。优化策略
- 数据增广:Mosaic 图片拼接,增加样本多样性

YOLOv5
代码实现:YOLOv5 in PyTorch
图片来源:YOLOv5网络详解、YOLOv5 解读,训练,复现网络架构

其中骨干网络有如下多个选择:

另外,上述结构有下述几个特点:- 整体架构采用了 FPN (Feature Pyramid Networks) + PAN (借鉴PANet) 的形式,其中 FPN 是自顶向下的上采样,将感受野更大的特征,逐步上采样与感受野更小的特征融合;PAN 则是自底向上的下采样,将感受野更小的特征,逐步下采样与感受野更大的特征融合。

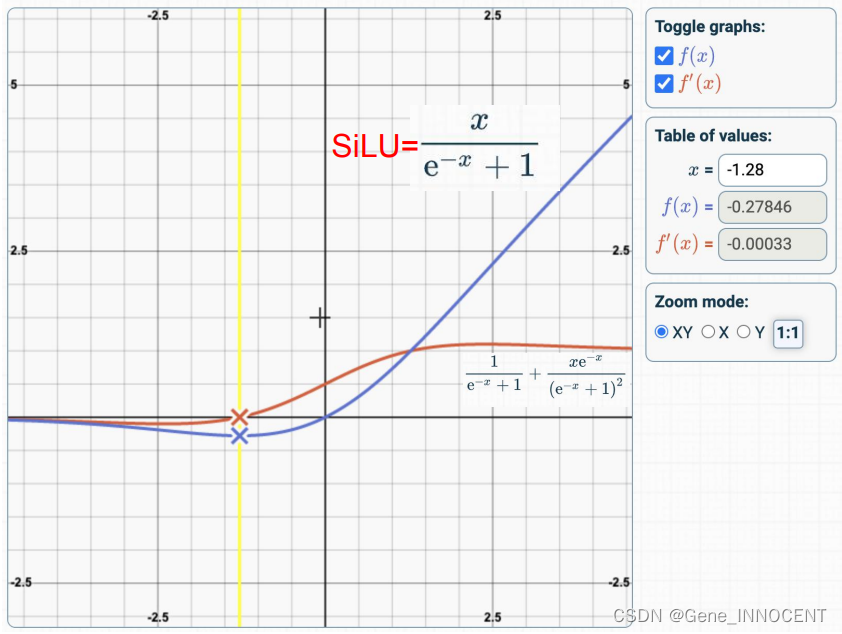
- YOLOv5 作者根据实验最终确定激活函数为 SiLU,即
f
(
x
)
=
x
⋅
σ
(
x
)
=
x
/
(
1
+
e
−
x
)
f(x)=x\cdot \sigma(x)=x/(1+e^{-x})
f(x)=x⋅σ(x)=x/(1+e−x)
- 将 SPP (Spatial Pyramid Pooling) 改为 SPPF,将并行的池化改为串行池化,通过实验证明性能得到提升;另外该结构主要目的是将不同尺度的池化结果融合在一起

数据增广
-
数据增广:Augment HSV (Hue, Saturation, Value)

-
数据增广:Mix up(根据透明度融合)

-
数据增广:Copy paste

Anchor 框的确定
YOLOv5 默认开启 autoanchor,即根据训练数据的 label 重新确定 anchor 宽高,其开启与否受参数
--noautoanchor控制。在训练时,YOLOv5 会首先判断原始 anchor 框与训练数据的 label 框是否适配,其会计算一个叫 bpr 的指标,具体代码如下,其中 wh ([n, 2]) 表示训练数据中 n 个框的宽高,k ([9, 2]) 表示 9 个 anchor 的宽高。
代码具体步骤为:(1)将 wh 的宽高除以 anchor 的宽高,比例越接近 1 则越匹配(2)每一个 anchor 框留下离 1 最远的宽或高(3)每一个 gt(训练数据的真实框)在 9 个 anchor 中留下一个最接近的 anchor(4)bpr 即为每一个超过阈值的 anchor 的平均匹配值
def metric(k): # compute metric r = wh[:, None] / k[None] x = torch.min(r, 1 / r).min(2)[0] # ratio metric best = x.max(1)[0] # best_x aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold bpr = (best > 1 / thr).float().mean() # best possible recall return bpr, aat- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果 bpr 小于 0.98,则 YOLOv5 会对 gt 框直接进行 kmeans 聚类,且不同于 YOLOv2,YOLOv5 聚类时的距离依然是欧式距离。
Anchor 框的匹配
在 YOLOv5 中,每一个 cell 内的对象,会同时考虑相邻两个格子的 anchor,即一共 3x3=9 个 anchor。如下图所示,当 gt 中心靠近右下角,则会将右边和下边两个 cell 的 anchor 也考虑进来。

随后,YOLOv5 会去计算 gt 和每个 anchor 的宽高比例,即:
r w = w g w a , r h = h g h a r_w=\frac{w_{g}}{w_{a}},r_h=\frac{h_g}{h_a} rw=wawg,rh=hahg随后计算 r w r_w rw 和其倒数的最大值,以及宽度和高度的最大差异 r max r^{\max} rmax,即:
r w max = max ( r w , 1 / r w ) r h max = max ( r h , 1 / r h ) r max = max ( r w max , r h max ) rmaxw=max(rw,1/rw)rmaxh=max(rh,1/rh)rmax=max(rmaxw,rmaxh)rwmaxrhmaxrmax=max(rw,1/rw)=max(rh,1/rh)=max(rwmax,rhmax)若 r max r^{\max} rmax 小于阈值 anchor_t(通常为 4.0),则匹配成功,保留;否则丢弃。
输出框的确定
每个 cell 的 anchor 框匹配后,再搭配上网络在该 cell 上输出的 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th,即可得到最终的预测边框:
b x = 2 σ ( t x ) − 0.5 + c x b y = 2 σ ( t y ) − 0.5 + c y b w = ( 2 σ ( t w ) ) 2 ⋅ w a b h = ( 2 σ ( t h ) ) 2 ⋅ h a bx=2σ(tx)−0.5+cxby=2σ(ty)−0.5+cybw=(2σ(tw))2⋅wabh=(2σ(th))2⋅habxbybwbh=2σ(tx)−0.5+cx=2σ(ty)−0.5+cy=(2σ(tw))2⋅wa=(2σ(th))2⋅ha
其中 c x , c y , w a , h a c_x,c_y,w_a,h_a cx,cy,wa,ha 分别为当前 cell 左上角坐标,以及 anchor 框的宽高。损失函数
Loss = λ b o x ⋅ L b o x + λ o b j ⋅ L o b j + λ c l s ⋅ L c l s \text{Loss}=\lambda_{box}\cdot L_{box}+\lambda_{obj}\cdot L_{obj}+\lambda_{cls}\cdot L_{cls} Loss=λbox⋅Lbox+λobj⋅Lobj+λcls⋅Lcls
L b o x L_{box} Lbox 刻画了每一对匹配的 gt 和 anchor 的 CIoU 损失,即:
L CIoU = 1 − IoU + ρ 2 c 2 + α ⋅ v v = 4 π 2 ( arctan w g h g − arctan w a h a ) 2 α = v 1 − IoU + v LCIoU=1−IoU+ρ2c2+α⋅vv=4π2(arctanwghg−arctanwaha)2α=v1−IoU+vLCIoUvα=1−IoU+c2ρ2+α⋅v=π24(arctanhgwg−arctanhawa)2=1−IoU+vv
其中 ρ \rho ρ 为两个框的中心点距离, c c c 为两个框的最小外接矩形的对角线长度。另外, L o b j L_{obj} Lobj 和 L c l s L_{cls} Lcls 均采用了 BCEWithLogitsLoss,其中正类权重分别由 obj_pw 与 cls_pw 两个超参控制,并且 L o b j L_{obj} Lobj 为 “每个 cell 的预测框的置信度” 与 “预测框与该 cell 上的 gt 的 IoU” 之间的损失。
参考资料
-
相关阅读:
MySQL数据库事务控制
C /C++ 中的堆栈使用
AspNetCore配置多环境log4net配置文件
动态链接库(五)--导出类
Git实战技巧-如何同时撤回远程和本地分支合并操作
【ESD专题】从原理上分析TVS管PCB Layout的经验法则
Springboot日志记录方案—官方原版
【案例实战】SpringBoot整合阿里云文件上传OSS
nodejs毕业设计源码基于node.js的博客系统
01.oracle介绍
- 原文地址:https://blog.csdn.net/qq_41552508/article/details/126676272