-
mysql一条语句是如何被执行的——带你了解mysql语句执行内部顺序
写在前面
mysql一条更新语句是如何被执行的——带你了解mysql更新语句执行内部顺序
select * from table where id=1;- 1
日常开发中,执行以上的SQL语句时,所呈现给我们的是输入一条SQL,输出一行结果,却不知道这条语句在 MySQL 内部的执行过程。
今天咱们就捋一捋一条SQL语句在MySql中是如何执行的。
一、MySQL基本架构
MySQL 是典型的 C/S 架构,即 Client/Server 架构,服务器端程序使用的 mysqld。整体的 MySQL 流程如下图所示:

Server(SQL) 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
下图便是一条SQL语句的执行过程了:
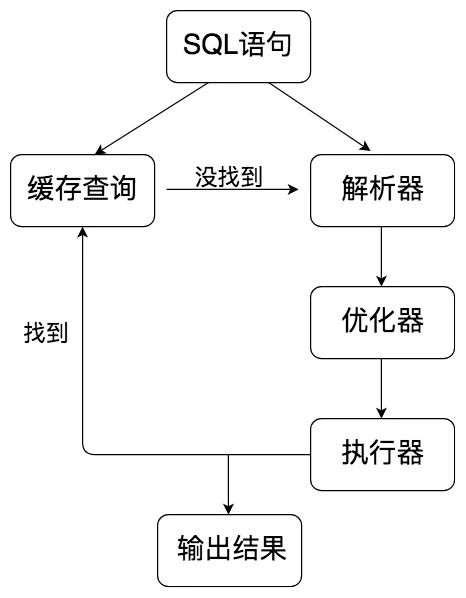
超详细架构图

1、连接器
在MySQL拿到这条SQL语句之前,首先你得先连接到MySQL数据库,这时候接待你的就是连接器。
连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接命令一般是这么写的:
mysql -h$ip -P$port -u$user -p- 1
连接命令中的 mysql 是客户端工具,用来跟服务端建立连接。
在完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。
如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,可以在 show processlist 命令中看到它。
以下其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。

客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。这时候如果你要继续,就需要重连,然后再执行请求了。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程通常是比较复杂的,所以我建议你在使用中要尽量减少建立连接的动作,也就是尽量使用长连接。
但是全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
怎么解决这个问题呢?你可以考虑以下两种方案。
- 定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
- 使用数据库连接池。
2、查询缓存
连接建立完成后,你就可以执行 select 语句了。执行逻辑就会来到第二步:查询缓存。
之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。
Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
需要说明的是,因为查询缓存往往效率不高(如果数据频繁修改,缓存失效的频率非常高,这样的话缓存使用效率就会很低,除非是一张系统表,数据改动不大,才适合使用缓存),所以在 MySQL8.0 之后就抛弃了这个功能。将参数 query_cache_type 设置成 DEMAND,对于默认的 SQL 语句都不使用查询缓存。
而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定:select SQL_CACHE * from table where ID=1;- 1
3、解析器
解析器的作用就是对SQL进行词法分析和语法分析。
如果有语法问题,会直接提示语法错误:elect * from t where ID=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1- 1
- 2
- 3
(1)Parser词法解析
词法分析就是把一个完整的SQL语句打碎成一个个的单词。
比如说一个简单的SQL语句:select name from user where id=1;- 1
它会被打碎成8个符号,每个符号是什么类型,从哪里开始到哪里结束。
(2)语法分析
第二部就是语法分析,语法分析会对SQL做一些语法检查,比如单引号有没有闭合,然后根据MySQL定义的语法规则,根据SQL语句生成一个数据结构。这个数据结构我们把它叫做解析树(select_lex)。

词法语法分析是一个非常基础的功能,Java的编译器、百度搜索引擎如果要识别语句,必须也要有词法语法分析功能。任何数据库的中间件,要解析SQL完成路由功能,也必须要有词法和语法分析功能,比如MyCat,Sharding-JDBC(用到了Druid Parser)。在市面上也有很多的开源的词法解析的工具(比如LEX、Yacc)。
(3)预处理器
如果写了一个词法和语法都正确的SQL,但是表名或者字段不存在,会在哪里报错?是在数据库的执行层还是解析器?
select * from user where name='zhangsan';- 1
解析器可以分析语法,但是它怎么知道数据库里面有什么表,表里面有什么字段的呢?实际上解析SQL的环节里面有个预处理器。它会检查生成的解析树,解决解析器无法解析的语义,比如,它会检查表和列名是否存在,检查名字和别名,保证没有歧义。
预处理之后得到一个新的解析树。
(4)MySQL 8.0对Parser所做的改进
1、背景介绍
众所周知,MySQL Parser是利用C/C++实现的开源yacc/lex组合,也就是 GNU bison/flex。Flex负责生成tokens, Bison负责语法解析。开始介绍MySQL 8.0的新特新之前,我们先简单了解一下通用的两种Parser。一种是Bottom-up parser,另外一种是Top-down parser。2、Bottom-up parser
Bottom-up解析是从parse tree底层开始向上构造,然后将每个token移进(shift),进而规约(reduce)为较大的token,最终按照语法规则的定义将所有token规约(reduce)成为一个token。移进过程是有先后顺序的,如果按照某种顺序不能将所有token规约为一个token,解析器将会回溯重新选定规约顺序。如果在规约(reduce)的过程中出现了既可以移进生成一个新的token,也可以规约为一个token,这种情况就是我们通常所说的shift/reduce conflicts.3、Top-down parser
Top-down解析是从parse tree的顶层开始向下构造历。这种解析的方法是假定输入的解析字符串是符合当前定义的语法规则,按照规则的定义自顶开始逐渐向下遍历。遍历的过程中如果出现了不满足语法内部的逻辑定义,解析器就会报出语法错误。如果愿意详细了解这两种parser的却别,可以参考https://qntm.org/top。
4、MySQL8.0对parser所做的改进
Bison是一个bottom-up的parser。但是由于历史原因,MySQL的语法输入是按照Top-down的方式来书写的。这样的方式导致MySQL的parser语法上有包含了很多的reduce/shift conflicts;另外由于一些空的或者冗余的规则定义也使得的MySQL parser越来越复杂。为了应对未来越来越多的语法规则,以及优化MySQL parser的解析性能,MySQL 8.0对MySQL parser做了非常大的改进。当前的MySQL 8.0.1 Milestone release的代码中对于Parser的改进仍未全部完成,还有几个相关的worklog在继续。改进之后,MySQL parser可以达到如下状态:
(1)MySQL parser将会成为一个不涉及状态信息(即:不包含执行状态的上下文信息)的bottom-up parser;
(2)减少parse tree上的中间节点,减少冗余规则
(3)更少的reduce/shift conflicts
(4)语法解析阶段,只包含以下简单操作:
① 创建parse tree node
② 返回解析的最终状态信息
③ 有限的访问系统变量
(5)MySQL parser执行流程将会由
SQL input -> lex. scanner -> parser -> AST (SELECT_LEX, Items etc) -> executor变成
SQL input -> lex. scanner -> parser -> parse tree -> AST -> executor
下面我们通过看一个MySQL 8.0 中对SELECT statement所做的修改来看一下MySQL parser的改进。
SELECT statement可以说是MySQL中用处非常广泛的一个语句,比如CREATE VIEW, SELECT, CREATE TABLE, UNION, SUBQUERY等操作。 通过下图我们看一下MySQL8.0之前的版本是如何支持这些语法规则的。

MySQL8.0中对于这些语法规则的支持如下图:

通过如上两个图的对比,显然MySQL8.0的parser清爽了许多。当然我们也清晰的看到MySQL8.0中对于MySQL parser所做的改进。相同的语法规则只有一处定义,消除了过去版本中按照top-down方式书写的冗余语法定义。当然通过这样的简化也可以看到实际的效果, shift/reduce conflicts也减少了很多:
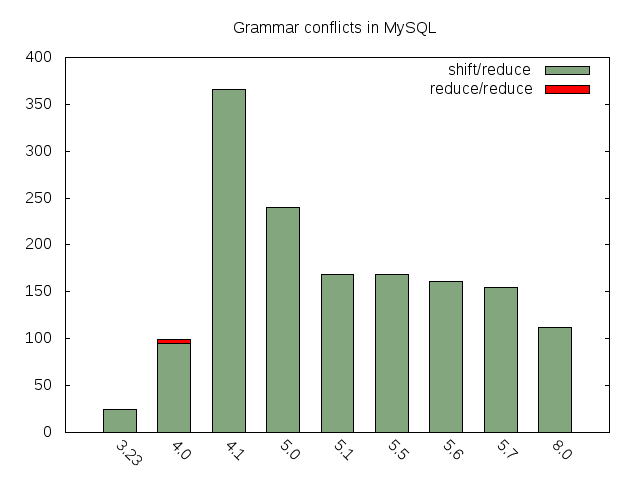
下面我们看看MySQL 8.0是如何将所有的SELECT statement操作定义为一个Query specification,并为所有其他操作所引用的:Parse tree上所有的node都定义为Parse_tree_node的子类。Parse_tree_node的结构体定义如下:
typedef Parse_tree_node_tmpl<Parse_context> Parse_tree_node; template<typename Context> class Parse_tree_node_tmpl { ... private: /* False right after the node allocation. The contextualize/contextualize_ function turns it into true. */ #ifndef DBUG_OFF bool contextualized; #endif//DBUG_OFF /* 这个变量是由于当前仍旧有未完成的相关worklog,parser的refactor还没有彻底完成。当前的parser中还有一部分上下文依赖的关系没有独立出来。 等到整个parse refactor完成之后该变量就会被移除。 */ bool transitional; public: /* Memory allocation operator are overloaded to use mandatory MEM_ROOT parameter for cheap thread-local allocation. Note: We don't process memory allocation errors in refactored semantic actions: we defer OOM error processing like other error parse errors and process them all at the contextualization stage of the resulting parse tree. */ static void *operator new(size_t size, MEM_ROOT *mem_root) throw () { return alloc_root(mem_root, size); } static void operator delete(void *ptr,size_t size) { TRASH(ptr, size); } static void operator delete(void *ptr, MEM_ROOT *mem_root) {} protected: Parse_tree_node() { #ifndef DBUG_OFF contextualized= false; transitional= false; #endif//DBUG_OFF } public: ... /* True if contextualize/contextualized function has done: */ #ifndef DBUG_OFF bool is_contextualized() const { return contextualized; } #endif//DBUG_OFF /* 这个函数是需要被所有子类继承的,所有子类需要定义属于自己的上下文环境。通过调用子类的重载函数,进而初始化每个Parse tree node。 */ virtual bool contextualize(THD *thd); /** my_parse_error() function replacement for deferred reporting of parse errors @param thd current THD @param pos location of the error in lexical scanner buffers */ void error(THD *thd) const; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
当前MySQL8.0的源码中执行流程为:
mysql_parse | parse_sql | MYSQLparse | Parse_tree_node::contextualize() /* 经过Bison进行语法解析之后生成相应的Parse tree node。然后调用contextualize对Parse tree node进行上下文初始化。 初始化上下文后形成一个AST(Abstract Syntax Tree)节点。*/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接下来我们以SELECT statement来看一下PT_SELECT_STMT::contexualize()做些什么工作:
class PT_select_stmt : public Parse_tree_node { bool contextualize(Parse_context *pc) { // 这里初始化Parse_tree_node if (super::contextualize(pc)) return true; pc->thd->lex->sql_command= m_sql_command; // 调用PT_query_specification来进行上下文初始化 return m_qe->contextualize(pc) || contextualize_safe(pc, m_into); } private: PT_query_expression *m_qe;//通过m_qe来引用query_expression } class PT_query_expression : public Parse_tree_node { ... bool contextualize(Parse_context *pc) { // 判断是否需要独立的名空间 pc->select->set_braces(m_parentheses || pc->select->braces); m_body->set_containing_qe(this); if (Parse_tree_node::contextualize(pc) || // 初始化SELECT主体上下文 m_body->contextualize(pc)) return true; // 这里会初始化ORDER, LIMIT子句 if (!contextualized && contextualize_order_and_limit(pc)) return true; // 这里会对SELECT表达式里包含的存储过程或者UDF继续进行上下文初始化 if (contextualize_safe(pc, m_procedure_analyse)) return true; if (m_procedure_analyse && pc->select->master_unit()->outer_select() != NULL) my_error(ER_WRONG_USAGE, MYF(0), "PROCEDURE", "subquery"); if (m_lock_type.is_set && !pc->thd->lex->is_explain()) { pc->select->set_lock_for_tables(m_lock_type.lock_type); pc->thd->lex->safe_to_cache_query= m_lock_type.is_safe_to_cache_query; } } ... private: bool contextualized; PT_query_expression_body *m_body; /* 这个类包含了SELECT语句的主要部分,select_list, FROM, GROUP BY, HINTs等子句。 这里m_body变量其实是PT_query_expression_body的子类 PT_query_expression_body_primary */ PT_order *m_order; // ORDER BY node PT_limit_clause *m_limit; // LIMIT node PT_procedure_analyse *m_procedure_analyse; //存储过程相关 Default_constructible_locking_clause m_lock_type; bool m_parentheses; } class PT_query_expression_body_primary : public PT_query_expression_body { { if (PT_query_expression_body::contextualize(pc) || m_query_primary->contextualize(pc)) return true; return false; } private: PT_query_primary *m_query_primary; // 这里是SELECT表达式的定义类PT_query_specification的父类 } // PT_query_specification是SELECT表达式的定义类,它定义了SELECT表达式中绝大部分子句 class PT_query_specification : public PT_query_primary { typedef PT_query_primary super; private: PT_hint_list *opt_hints; Query_options options; PT_item_list *item_list; PT_into_destination *opt_into1; Mem_root_array_YY<PT_table_reference *> from_clause; // empty list for DUAL Item *opt_where_clause; PT_group *opt_group_clause; Item *opt_having_clause; bool PT_query_specification::contextualize(Parse_context *pc) { if (super::contextualize(pc)) return true; pc->select->parsing_place= CTX_SELECT_LIST; if (options.query_spec_options & SELECT_HIGH_PRIORITY) { Yacc_state *yyps= &pc->thd->m_parser_state->m_yacc; yyps->m_lock_type= TL_READ_HIGH_PRIORITY; yyps->m_mdl_type= MDL_SHARED_READ; } if (options.save_to(pc)) return true; // 这里开始初始化SELECT list项 if (item_list->contextualize(pc)) return true; // Ensure we're resetting parsing place of the right select DBUG_ASSERT(pc->select->parsing_place == CTX_SELECT_LIST); pc->select->parsing_place= CTX_NONE; // 初始化SELECT INTO子句 if (contextualize_safe(pc, opt_into1)) return true; // 初始化FROM子句 if (!from_clause.empty()) { if (contextualize_array(pc, &from_clause)) return true; pc->select->context.table_list= pc->select->context.first_name_resolution_table= pc->select->table_list.first; } // 初始化WHERE条件 if (itemize_safe(pc, &opt_where_clause) || // 初始化GROUP子句 contextualize_safe(pc, opt_group_clause) || // 初始化HAVING子句 itemize_safe(pc, &opt_having_clause)) return true; pc->select->set_where_cond(opt_where_clause); pc->select->set_having_cond(opt_having_clause); // 初始化HINTs if (opt_hints != NULL) { if (pc->thd->lex->sql_command == SQLCOM_CREATE_VIEW) { // Currently this also affects ALTER VIEW. push_warning_printf(pc->thd, Sql_condition::SL_WARNING, ER_WARN_UNSUPPORTED_HINT, ER_THD(pc->thd, ER_WARN_UNSUPPORTED_HINT), "CREATE or ALTER VIEW"); } else if (opt_hints->contextualize(pc)) return true; } return false; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
综上我们以SELECT statement为例对MySQL8.0在MySQL parser方面所做的改进进行了简单介绍。这样的改进对于MySQL parser也许是一小步,但对于MySQL未来的可扩展确实是迈出了一大步。Parse tree独立出来,通过Parse tree再来构建AST,这样的方式下将简化MySQL对于Parse tree的操作,最大的受益者就是Prepared statement。等到MySQL parse的所有worklog完成之后,MySQL用户期盼多年的global prepared statement也就顺其自然实现了。
当然MySQL parser的改进让我们已经看到Oracle MySQL在对MySQL optimizier方面对于PARSER,optimizer, executor三个阶段的松解耦工作已经展开了。未来期待Optimizer生成的plan也可以像当前的parser一样成为一个纯粹的Plan,执行上下文与Plan也可以独立开来。只有到了executor阶段才生成相应的执行上下文。这样一来对于MySQL optimizer未来的可扩展势必会起到如虎添翼的作用。
4、优化器
MySQL拿到SQL后,会将它转化它认为最优的语句以及选择最优的执行方案,比如调整join语句中表的连接顺序、去除无效的条件、当表中有多个索引时决定选择哪一个等等。

数据库层面优化
众所周知,数据库运行速度最重要的是其本身的基础设计:1、表结构是否合理,字段是否符合标准规范,是否满足程序运行的基础单元。例如频繁更新的应哟个程序通常有很多表,较少的列,而分析大量数据的应用程序则有很少的表,很多的列。
2、是否正确使用了索引,来提高查询效率?
3、您是否为每个表的建立,考虑使用合适的存储引擎,充分考虑到每个存储引擎的特点和优势。忒特别是,事务存储引擎或非事务存储引擎,这对于性能和可扩展性非常重要。
4、您是否为每个表使用了适当的行格式,当然这取决于您所选择的存储引擎。比如,压缩表使用较少的磁盘空间,需要更少的磁盘I/O来读写数据。压缩表适用于所有InnoDB表的所有类型的工作负载,以及只读MyISAM表
5、应用程序是否使用了合适的锁策略。比如,尽可能的允许共享访问,以便可以提升读的性能,当然对请求的独占也是非常关键的。这一点同样取决于存储引擎的选择,InnoDB存储引擎自身可以处理大多数锁定问题,从而实现很好的并发性能。
6、用于缓存的所有内存区域的大小设置是否合理?也就是说,大到足以容纳经常访问的数据,但又不会大到使物理内存过载并导致分页。要配置的主要内存区域是 InnoDB 缓冲池和 MyISAM 密钥缓存。
硬件层面的优化
随着数据库的使用场景越来越丰富,任何数据库都最终会遇到硬件性能瓶颈。DBA必须评估是否可以调整应用程序和重新配置服务器已避免这谢瓶颈,或者增加足够的硬件资源。主要的硬件瓶颈来源于以下几点:1、磁盘寻道。也就是磁盘找到一条数据所需要的时间。现在的磁盘,平均时间通常低于 10 毫秒,因此理论上我们每秒可以进行大约 100 次寻道。这个时间随着新磁盘的增加而缓慢改善,并且很难针对单个表进行优化。优化寻道时间的方法是将数据分布到多个磁盘上。
2、磁盘读写。当磁盘在正确的位置时,我们需要读取或写入数据。现在的磁盘,一个磁盘可提供至少 10–20MB/s 的吞吐量。这比查找更容易优化,因为您可以从多个磁盘并行读取。
3、CPU 时钟周期。当数据在主存中时,我们必须对其进行处理以获得我们的结果。与内存相比,拥有一张大表是最常见的限制因素。但是对于小表,速度通常不是问题。
4、内存带宽。当 CPU 需要的数据超出 CPU 高速缓存的容量时,主内存带宽就会成为瓶颈。对于大多数系统来说,这是一个不常见的瓶颈,但还是需要注意。
5、执行器
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)。
select * from T where ID=10; ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'- 1
- 2
- 3
上一条SQL,ID 字段没有索引的话,执行逻辑应该是这样子的:
1.调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
2.调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
3.执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
4.至此,这个语句就执行完成了。对于有索引的表,第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。
数据库的慢查询日志中看到一个 rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。
在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。
6、存储引擎
MySQL 的存储引擎采用了插件的形式,每个存储引擎都面向一种特定的数据库应用环境。同时开源的 MySQL 还允许开发人员设置自己的存储引擎,下面是一些常见的存储引擎:
1、InnoDB 存储引擎:它是 MySQL 5.5 版本之后默认的存储引擎,最大的特点是支持事务、行级锁定、外键约束等。
2、MyISAM 存储引擎:在 MySQL 5.5 版本之前是默认的存储引擎,不支持事务,也不支持外键,最大的特点是速度快,占用资源少。
3、Memory 存储引擎:使用系统内存作为存储介质,以便得到更快的响应速度。不过如果 mysqld 进程崩溃,则会导致所有的数据丢失,因此我们只有当数据是临时的情况下才使用 Memory 存储引擎。
4、NDB 存储引擎:也叫做 NDB Cluster 存储引擎,主要用于 MySQL Cluster 分布式集群环境,类似于 Oracle 的 RAC 集群。
5、Archive 存储引擎:它有很好的压缩机制,用于文件归档,在请求写入时会进行压缩,所以也经常用来做仓库。
需要注意的是,数据库的设计在于表的设计,而在 MySQL 中每个表的设计都可以采用不同的存储引擎,我们可以根据实际的数据处理需要来选择存储引擎,这也是 MySQL 的强大之处。
SQL语句执行时间分析
1、开启profiling
首先我们需要看下 profiling 是否开启,开启它可以让 MySQL 收集在 SQL 执行时所使用的资源情况,命令如下:select @@profiling;- 1

profiling=0 代表关闭,我们需要把 profiling 打开,即设置为 1:mysql> set profiling=1;- 1
2、随便执行一个sql查询
select * from wucai.heros;- 1
3、查看当前会话所产生的所有 profiles
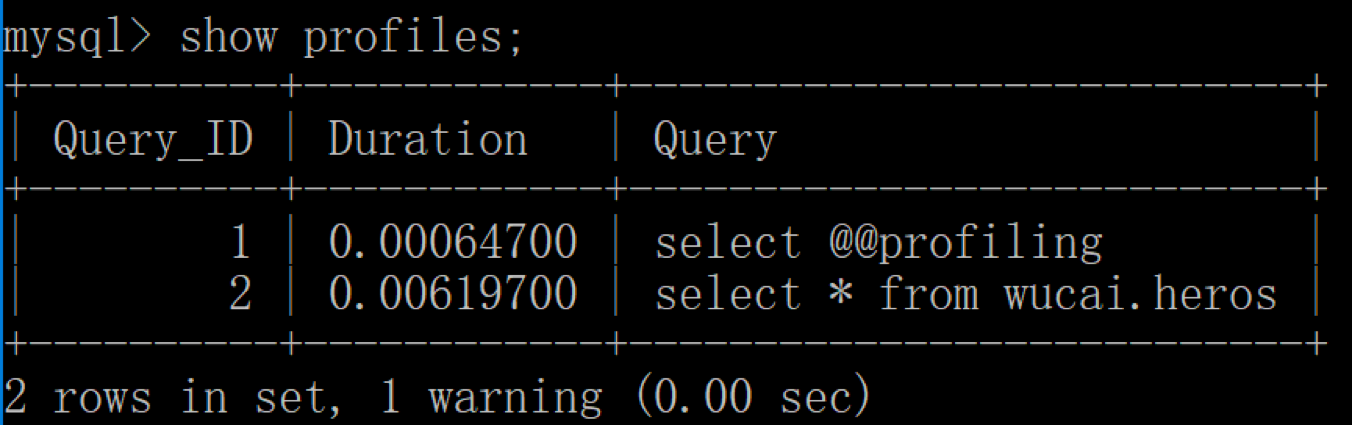
你会发现我们刚才执行了两次查询,Query ID 分别为 1 和 2。4、如果我们想要获取上一次查询的执行时间,可以使用:
mysql> show profile;- 1

5、也可以查询指定的 Query ID,比如:mysql> show profile for query 2;- 1
6、
在 8.0 版本之后,MySQL 不再支持缓存的查询。一旦数据表有更新,缓存都将清空,因此只有数据表是静态的时候,或者数据表很少发生变化时,使用缓存查询才有价值,否则如果数据表经常更新,反而增加了 SQL 的查询时间。
使用 select version() 来查看 MySQL 的版本情况

参考资料
https://zhuanlan.zhihu.com/p/299667488
http://mysql.taobao.org/monthly/2017/04/02/
https://blog.csdn.net/qq_43842093/article/details/124810925
https://blog.csdn.net/bingo199/article/details/122625491 -
相关阅读:
Java基本问题:求教
springboot系列(八):mybatis-plus之条件构造器使用手册|超级详细,建议收藏
大数据——Zookeeper ZBA协议(四)
TechSmith Camtasia 2023 for Mac 屏幕录像视频录制编辑软件
2023CSP-J游寄
实战 | 电商业务性能测试(二): Jmeter 参数化功能实现注册登录的数据驱动
Linux C语言(10)
安卓Java面试题 91- 100
【OpenCV】基于cv2的图像阈值化处理【超详细的注释和解释】掌握基本操作
【字符串匹配算法】KMP、哈希
- 原文地址:https://blog.csdn.net/A_art_xiang/article/details/126658793
