-
TASK04分组|joyfulpandas
必须搜索的关键字要加上""import numpy as np import pandas as pd- 1
- 2
#pandas.melt()可以实现将宽数据——》长数据 pandas.melt(frame,id_vars=None,value_vars=None,var_name=None,col_level=None,ignore_index=True) frame要处理的数据框 id_vars不需要被转换的列名 value_vars 需要转换的列名,默认剩余全部 var_name,value_name 自定义设置对应的列名 ignore_index是否忽略原始索引 col_level 多层索引 MultiIndex- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
实操例子:
import pandas as pd df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'}, 'B': {0: 1, 1: 3, 2: 5}, 'C': {0: 2, 1: 4, 2: 6} }) #默认数据集 print(df) #默认转换 print(pd.melt(df,id_vars=['A'],value_vars=['B'])) print(pd.melt(df,id_vars=['A'],value_vars=['B','C'])) #设置列明 print(pd.melt(df,id_vars=['A'],value_vars=['B','C'],var_name='My_VARname',value_name='My_Value')) #忽略索引 print(pd.melt(df,id_vars=['A'],value_vars=['B','C'],ignore_index=False)) #不能用’False‘代表False #多重索引 df.columns=[list('ABC'),list('DEF')] print(df) #选择最外层索引 print(pd.melt(df,id_vars=['A'],value_vars=['B','C'],col_level=0)) #记得要选择索引层数 ,第一层的选择0,第二层选择1,第三层选择2 print(pd.melt(df,id_vars=['E','D'],value_vars=['F'],col_level=1)) print(pd.melt(df,id_vars=[('A','D')],value_vars=['C','F'])) #不能选择不同层且不同列的id_vars- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
一、分组模式及其对象
1. 分组的一般模式
实现分组操作,必须明确三个要素: 分组依据 \color{#FF0000}{分组依据} 分组依据、 数据来源 \color{#00FF00}{数据来源} 数据来源、 操作及其返回结果 \color{#0000FF}{操作及其返回结果} 操作及其返回结果。
df.groupby(分组依据)[数据来源].使用操作- 1
每组返回一个标量值
- 依据性别分组,统计全国人口寿命的平均值中的代码就应该如下:
df.groupby('Gender')['Longevity'].mean()- 1
- 如果想要按照性别统计身高中位数
df=pd.read_csv("") print(df) df.groupby('Gender')['Height'].median()- 1
- 2
- 3
2. 分组依据的本质
根据多个维度进行分组,在
groupby中传入相应列名构成的列表- 现希望根据学校和性别进行分组,统计身高的均值就可以如下写出
df.groupby(['School', 'Gender'])['Height'].mean()- 1
- 根据学生体重是否超过总体均值来分组,同样还是计算身高的均值
condition=df.Weight>df.Weight.mean() #分组条件 df.groupby(condition)['Height'].mean()- 1
- 2
- 3
【练一练】
请根据上下四分位数分割,将体重分为high、normal、low三组,统计身高的均值。
# df_temp=df.loc[(df.Weight>=df.Weight.mean())] # df_temp_1=df.loc[(df.Weight- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

【END】
从索引可以看出,其实最后产生的结果就是按照条件列表中元素的值(此处是
True和False)来分组,下面用随机传入字母序列来验证这一想法:
`np.random.choice(list,n)从列表中随机选取值生成n大小的数组item=np.random.choice(list("abc"),df.shape[0]) df.groupby(item)['Height'].mean() #此处的索引是原先的item中的元素,如果传入多个序列进入`groupby`,那么最后分组的依据就是这两个序列对应行的唯一组合: df.groupby([condition, item])['Height'].mean()- 1
- 2
- 3
- 4

通过drop_duplicates知道具体的类别df[['School', 'Gender']].drop_duplicates() #dataframe drop_duplicates()得到唯一值的方法 df.groupby([df['School'],df['Gender']]).mean() #得到平均值- 1
- 2
- 3
- 4
3.Groupby对象
gb=df.groupby(['School','Grade']) #ngroups得到分组个数 gb.ngroups #groups属性可以返回从组名映射到组索引列表的字典 #gb.groups返回从组名到组索引列表的字典 res=gb.groups res.keys()- 1
- 2
- 3
- 4
- 5
- 6
- 7
【练一练】
上一小节介绍了可以通过
drop_duplicates得到具体的组类别,现请用groups属性完成类似的功能。df.groupby(['School','Gender']).groups- 1
【END】 size
当
size作为DataFrame的属性时,返回的是表长乘以表宽的大小,但在groupby对象上表示统计每个组的元素个数gb.size()- 1
通过
get_group方法可以直接获取所在组对应的行,此时必须知道组的具体名字:gb.get_group(('Fudan University','Freshman'))- 1
4. 分组的三大操作
-
每组返回一个标量值(每一个组返回一个标量值)
平均值、中位数、组容量size等 -
每组返回一个Series类型 (返回一个序列)
-
每组返回一个DataFrame类型(返回的整个组所在行的本身)
分组的三大操作:聚合、变换和过滤
二、聚合函数
1. 内置聚合函数
直接定义在groupby对象的聚合函数,速度经过内部优化,优先考虑
gb=df.groupby('Gender')['Height'] gb.idxmin() gb.quantile(0.95)- 1
- 2
- 3
【练一练】
请查阅文档,明确
all/any/mad/skew/sem/prod函数的含义。
max/min/mean/median/count/all/any/idxmax/idxmin/mad/nunique/skew/quantile/sum/std/var/sem/size/prodidxmax:返回在请求的轴上第一次出现最大值的索引
DataFrame.idxmax(axis=0, skipna=True)
idxmin:返回在请求的轴上出现最小值的索引
DataFrame.idxmin(axis=0, skipna=True):axis=0,1 skipna:是否跳过空值
sem:计算组平均值的标准差,不包括缺失值 ( 标准误)
sem(ddof=1) ddof:自由度
std(ddof=1):标准差
var
size:组大小
count组元素大小
max组最大值
min组最小值
median组中间值
sum计算每组的和
ohlc:计算除缺失值外的和
prod:计算可迭代对象中所有元素的积
skew求偏度
all:如果所有元素不为False:True,否则为False
any如果元素中有一个True则返回True
mad返回所请求轴的值的平均绝对偏差,数据集的平均绝对偏差是每个数据点与平均值之间的平均距离
nunique:唯一值的个数
GroupBy.iter()
GroupBy.groups 返回从组名到组索引列表的字典
GroupBy.indices 索引
GroupBy.get_group获取所在组对应的行【END】
这些聚合函数当传入的数据来源包含多个列时,将按照列进行迭代计算:
gb=df.groupby('Gender')[['Height','Weight']] gb.max()- 1
- 2
2. agg方法
- 无法同时使用多个函数
- 无法对特定的列使用特定的聚合函数
- 无法使用自定义的聚合函数
- 无法直接对结果的列名在聚合前进行自定义命名
如何通过
agg函数解决这四类问题
[a]使用多个函数
当使用多个聚合函数时,需要用列表的形式把内置聚合函数对应的字符串传入,先前提到的所有字符串都是合法的。gb.agg(['sum','idxmax','skew'])- 1

结果为多级索引,第一层为数据源,第二层为使用的聚合方法【b】对特定的列使用特定的聚合函数
gb.agg({'Height':['mean','max'], 'Weight':'count'})- 1
【练一练】
请使用【b】中的传入字典的方法完成【a】中等价的聚合任务。
gb.agg({'Height':['sum','idxmax','skew'],"Weight":['sum','idxmax','skew']})- 1
【c】使用自定义函数
在agg中可以使用具体的自定义函数, 需要注意传入函数的参数是之前数据源中的列,逐列进行计算 \color{#FF0000}{需要注意传入函数的参数是之前数据源中的列,逐列进行计算} 需要注意传入函数的参数是之前数据源中的列,逐列进行计算#lambda函数 gb.agg(lambda x:x.mean()-x.min())- 1
- 2
【练一练】
在
groupby对象中可以使用describe方法进行统计信息汇总,请同时使用多个聚合函数,完成与该方法相同的功能。count:数量统计,此列共有多少有效值
unipue:不同的值有多少个
std:标准差
min:最小值
25%:四分之一分位数
50%:二分之一分位数
75%:四分之三分位数
max:最大值
mean:均值gb.agg(["count","unique","std","min", ( "25%",lambda x:x.quantile(0.25)), ("50%",lambda x:x.quantile(0.5)), ("75%",lambda x:x.quantile(0.75)), "max","mean"])- 1
- 2
- 3
- 4
- 5
【END】
由于传入的是序列,因此序列上的方法和属性都是可以在函数中使用的,只需保证返回值是标量即可。下面的例子是指,如果组的指标均值,超过该指标的总体均值,返回High,否则返回Low。
def my_func(s): res = 'High' if s.mean() <= df[s.name].mean(): res = 'Low' return res gb.agg(my_func)- 1
- 2
- 3
- 4
- 5
- 6
【d】聚合结果重命名
如果想要对聚合结果的列名进行重命名,只需要将上述函数的位置改写成元组,元组的第一个元素为新的名字,第二个位置为原来的函数,包括聚合字符串和自定义函数,现举若干例子说明:
gb.agg(['range', lambda x:x.max()-x.min()]) => gb.agg([('range', lambda x: x.max()-x.min()), ('my_sum', 'sum')]) gb.agg({'Height': [('my_func', my_func), 'sum'], 'Weight': lambda x:x.max()})- 1
- 2
- 3
- 4

注意,使用对一个或者多个列使用单个聚合的时候,重命名需要加方括号,否则就不知道是新的名字还是手误输错的内置函数字符串(都需要加方括号):gb.agg([('my_sum', 'sum')]) gb.agg({'Height': [('my_func', my_func), 'sum'], 'Weight': [('range', lambda x:x.max())]})- 1
- 2
三、变换和过滤
1. 变换函数与transform方法
变换函数的返回值为同长度的序列,最常用的内置变换函数是累计函数:
cumcount/cumsum/cumprod/cummax/cummin
它们的使用的方式和聚合函数类似,完成的是组内累计操作
在groupby 对象上还定义了填充类和滑窗类的变换函数gb.cummax().head()- 1
【练一练】
在
groupby对象中,rank方法也是一个实用的变换函数,请查阅它的功能并给出一个使用的例子。Rank
final GroupBy.rank(method=‘average’, ascending=True, na_option=‘keep’, pct=False, axis=0)
- method:{‘average’, ‘min’, ‘max’, ‘first’, ‘dense’},默认使用’average’方法
- na_option:
keep:将 NA 值保留在原处。
顶部:如果上升,则为最小排名。
底部:如果下降,则为最小排名。 - pct:计算每个组中数据的百分比排名。 False
- axis:要计算秩的对象的轴。
ascending=True(升序)
df = pd.DataFrame( { "group": ["a", "a", "a", "a", "a", "b", "b", "b", "b", "b"], "value": [2, 4, 2, 3, 5, 1, 2, 4, 1, 5], } ) for method in ['average', 'min', 'max', 'dense', 'first']: df[f'{method}_rank']=df.groupby('group')['value'].rank(method) print(gb.rank(method)) df- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
【END】
当用自定义变换时需要使用
transform方法,被调用的自定义函数, 其传入值为数据源的序列 \color{#FF0000}{其传入值为数据源的序列} 其传入值为数据源的序列,与agg的传入类型是一致的,其最后的返回结果是行列索引与数据源一致的DataFrame。现对身高和体重进行分组标准化,即减去组均值后除以组的标准差:
gb.transform(lambda x:(x-x.mean())/x.std()).head()- 1
【练一练】
对于
transform方法无法像agg一样,通过传入字典来对指定列使用特定的变换,如果需要在一次transform的调用中实现这种功能,请给出解决方案。def plus10(x): return x+10 def minus10(x): return x-10 def my_transform(gb,dict): return gb.transform((lambda y:(lambda x:y[x.name](x)))(dict)) res=my_transform(gb,{'Height':plus10,'Weight':minus10}) print(gb.transform(lambda x:{'Height':eval('x.cummin()'),'Weight':eval('x.rank()')}[x.name]).head())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
【END】
前面提到了
transform只能返回同长度的序列,但事实上还可以返回一个标量,这会使得结果被广播到其所在的整个组,这种 标量广播 \color{#FF0000}{标量广播} 标量广播的技巧在特征工程中是非常常见的。例如,构造两列新特征来分别表示样本所在性别组的身高均值和体重均值:gb.transform('mean').head()- 1
2. 组索引与过滤
过滤在分组中是对于组的过滤,而索引是对于行的过滤
组过滤作为行过滤的推广,指的是如果对一个组的全体所在行进行统计的结果返回True则会被保留,False则该组会被过滤,最后把所有未被过滤的组其对应的所在行拼接起来作为DataFrame返回。
在groupby对象中,定义了filter方法进行组的筛选 ,其中自定义函数的输入参数为数据源构成的DataFrame本身,在之前例子中定义的groupby对象中,传入的就是df[['Height', 'Weight']],因此所有表方法和属性都可以在自定义函数中相应地使用,同时只需保证自定义函数的返回为布尔值即可。例如,在原表中通过过滤得到所有容量大于100的组:
gb.filter(lambda x:x.shape[0]>100).head()- 1
【练一练】
从概念上说,索引功能是组过滤功能的子集,请使用
filter函数完成loc[...]的功能,这里假设"..."是元素列表。def myloc(x,listA): result = True for i in listA: if i not in x['Height'].values: result = False return result gb.filter(lambda x:myloc(x,[158.9,162.5]))- 1
- 2
- 3
- 4
- 5
- 6
- 7
四、跨列分组
1. apply的引入
之前几节介绍了三大分组操作,但事实上还有一种常见的分组场景,无法用前面介绍的任何一种方法处理,例如现在如下定义身体质量指数BMI:
B M I = W e i g h t H e i g h t 2 {\rm BMI} = {\rm\frac{Weight}{Height^2}} BMI=Height2Weight
其中体重和身高的单位分别为千克和米,需要分组计算组BMI的均值。首先,这显然不是过滤操作,因此
filter不符合要求;其次,返回的均值是标量而不是序列,因此transform不符合要求;最后,似乎使用agg函数能够处理,但是之前强调过聚合函数是逐列处理的,而不能够 多列数据同时处理 \color{#FF0000}{多列数据同时处理} 多列数据同时处理。由此,引出了apply函数来解决这一问题。2. apply的使用
在设计上,
apply的自定义函数传入参数与filter完全一致,只不过后者只允许返回布尔值。现如下解决上述计算问题:定义身体质量指数BMI:
B M I = W e i g h t H e i g h t 2 {\rm BMI} = {\rm\frac{Weight}{Height^2}} BMI=Height2Weight首先,这显然不是过滤操作,因此
filter不符合要求;其次,返回的均值是标量而不是序列,因此transform不符合要求;最后,似乎使用agg函数能够处理,但是之前强调过聚合函数是逐列处理的,而不能够 多列数据同时处理 \color{#FF0000}{多列数据同时处理} 多列数据同时处理。由此,引出了apply函数来解决这一问题。def BMI(x): Height=x['Height']/100 Weight=x['Weight'] BMI_value=Weight/Height**2 return BMI_value.mean() gb.apply(BMI)- 1
- 2
- 3
- 4
- 5
- 6
除了返回标量之外,
apply方法还可以返回一维Series和二维DataFrame【a】标量情况:结果得到的是
Series,索引与agg的结果一致gb=df.groupby(['Gender','Test_Number'])[['Height','Weight']] gb.apply(lambda x:0) gb.apply(lambda x:[0,0]) #虽然是列表,但是作为返回值仍然看作标量 [out]: Gender Test_Number Female 1 [0, 0] 2 [0, 0] 3 [0, 0] Male 1 [0, 0] 2 [0, 0] 3 [0, 0] dtype: object- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
【b】
Series情况:得到的是DataFrame,行索引与标量情况一致,列索引为Series的索引gb.apply(lambda x:pd.Series([0,0],index=['a','b']))- 1
【练一练】
请尝试在
apply传入的自定义函数中,根据组的某些特征返回相同长度但索引不同的Series,会报错吗?
会报错gb.apply(lambda x: pd.Series([0,0],index=['a',np.random.choice(list('EDR'))])) TypeError: Series.name must be a hashable type- 1
- 2
【END】
【c】
DataFrame情况:得到的是DataFrame,行索引最内层在每个组原先agg的结果索引上,再加一层返回的DataFrame行索引,同时分组结果DataFrame的列索引和返回的DataFrame列索引一致。gb.apply(lambda x:pd.DataFrame(np.ones(2,2)),index=['a','b'],columns=pd.Index([('w','x'),('y','z')])) [out]: w y x z Gender Test_Number Female 1 a 1.0 1.0 b 1.0 1.0 2 a 1.0 1.0 b 1.0 1.0 3 a 1.0 1.0 b 1.0 1.0 Male 1 a 1.0 1.0 b 1.0 1.0 2 a 1.0 1.0 b 1.0 1.0 3 a 1.0 1.0 b 1.0 1.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
【练一练】
请尝试在
apply传入的自定义函数中,根据组的某些特征返回相同大小但列索引不同的DataFrame,会报错吗?如果只是行索引不同,会报错吗?#列索引不同 gb.apply(lambda x:pd.DataFrame(np.ones((2,2)),index=['e','x'],columns=pd.Index(['w',np.random.choice(list('kjid'))]))) #不报错- 1
- 2
- 3
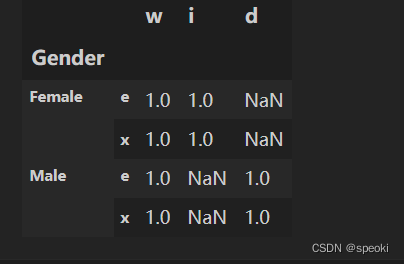
#行索引不同 gb.apply(lambda x:pd.DataFrame(np.ones((2,2)),index=pd.Index(['w',np.random.choice(list('kjid'))]),columns=['e','x']))- 1
- 2

【END】
最后需要强调的是,
apply函数的灵活性是以牺牲一定性能为代价换得的,除非需要使用跨列处理的分组处理,否则应当使用其他专门设计的groupby对象方法,否则在性能上会存在较大的差距。同时,在使用聚合函数和变换函数时,也应当优先使用内置函数,它们经过了高度的性能优化,一般而言在速度上都会快于用自定义函数来实现。【练一练】
在
groupby对象中还定义了cov和corr函数,从概念上说也属于跨列的分组处理。请利用之前定义的gb对象,使用apply函数实现与gb.cov()同样的功能并比较它们的性能。print(gb.cov()) print(gb.apply(lambda x:x.cov())) import datetime b1=datetime.datetime.now() gb.cov() b2=datetime.datetime.now() print('gb.cov():',b2-b1) c1=datetime.datetime.now() gb.apply(lambda x:x.cov()) c2=datetime.datetime.now() print('gb.apply()',c2-c1) [out]: Height Weight Gender Female Height 25.542739 24.838146 Weight 24.838146 29.224655 Male Height 49.681137 47.803901 Weight 47.803901 60.412648 Height Weight Gender Female Height 25.542739 24.838146 Weight 24.838146 29.224655 Male Height 49.681137 47.803901 Weight 47.803901 60.412648 gb.cov(): 0:00:00.000988 gb.apply() 0:00:00.002007- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
五、练习
Ex1:汽车数据集
现有一份汽车数据集,其中
Brand, Disp., HP分别代表汽车品牌、发动机蓄量、发动机输出。df=pd.read_csv('../data/car.csv') df.head(3)- 1
- 2
- 先过滤出所属
Country数超过2个的汽车,即若该汽车的Country在总体数据集中出现次数不超过2则剔除,再按Country分组计算价格均值、价格变异系数、该Country的汽车数量,其中变异系数的计算方法是标准差除以均值,并在结果中把变异系数重命名为CoV。
价格变异系数=std/mean
#第一问 gb=df.groupby('Country') df2=gb.filter(lambda x:x.shape[0]>2) #过滤掉Country数超过2的汽车,得到Country数超过2的数据 gb=df2.groupby('Country') gb['Price'].agg(['mean','count',('Cov',lambda x:x.std()/x.mean())])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 按照表中位置的前三分之一、中间三分之一和后三分之一分组,统计
Price的均值。
df = pd.read_csv('../data/car.csv') df.head(3) #构造groupby对象 #第一问 gb=df.groupby('Country') df2=gb.filter(lambda x:x.shape[0]>2) #过滤掉Country数超过2的汽车,得到Country数超过2的数据 gb=df2.groupby('Country') gb['Price'].agg(['mean','count',('Cov',lambda x:x.std()/x.mean())]) #第二问 #mask函数返回为false的元素 #方法1 df.shape[0] #60个 condition=['front']*20+['middle']*20+['back']*20 #生成20个front,20个middle,20个back print(condition) print('方法1',df.groupby(condition)['Price'].mean()) #改进一下可以写成 condition=['front']*(df.shape[0]//3)+['middle']*(df.shape[0]//3)+['back']*(df.shape[0]//3) print('方法1改进',df.groupby(condition)['Price'].mean()) #方法2 condition=pd.Series(['middle']*df.shape[0]).mask(df.index<df.shape[0]//3,'front').mask(df.index>=2*df.shape[0]//3,'back') #初始值都为middle,将前1/3替换成front,将后1/3替换成back print('方法2',df.groupby(condition)['Price'].mean())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 对类型
Type分组,对Price和HP分别计算最大值和最小值,结果会产生多级索引,请用下划线把多级列索引合并为单层索引。
#问题3 gb2=df.groupby('Type') ggb2=gb2[['Price','HP']] gb2['Price'].max() gb2['Price'].min() gb2['HP'].max() gb2['HP'].min() gb2.agg({'Price':['max','min'],'HP':['max','min']}) print(ggb2.agg(['min','max']))res.columns=res.columns.map(lambda x:'_'.join(x)) res.head()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

- 对类型
Type分组,对HP进行组内的min-max归一化。
当用自定义变换时需要使用transform方法,被调用的自定义函数,其传入值为数据源的序列,与agg的传入类型是一致的,其最后的返回结果是行列索引与数据源一致的DataFrame。
gb2=df.groupby('Type') gb2['HP'].agg(['min','max']) #归一化 (x-min(x))/max(x)-min(x) def normalize(x): xmin,xmax=x.min(),x.max() return (x-xmin)/(xmax-xmin) gb2['HP'].transform(normalize).head()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 对类型
Type分组,计算Disp.与HP的相关系数。
gb2[['Disp.','HP']].corr().head()- 1
Ex2:实现transform函数
groupby对象的构造方法是my_groupby(df, group_cols)
#构造一个groupby对象 class my_groupby: def __init__(self,v_df,group_cols): #判断group_cols的类型 1代表list 0代表单个字符串 self.Type = 1 if type(group_cols) == list else 0 #存放df数据 self.df = v_df.copy() #groups用来存放分组的组类别 self.groups = v_df.drop_duplicates(group_cols) self.groups = self.groups[group_cols].values #如果是list,要把组的名用_连接起来方便后续查找 #并且新建index_name存放需要设计的行索引名 if self.Type: self.groups = [x[0]+'_'+x[1] for x in self.groups] index_name = ['id']+group_cols else: index_name = ['id']+[group_cols] #多列索引合并 self.df.set_index(group_cols,inplace=True,append=True) #设置新的行索引名,方便后续操作 self.df.rename_axis(index=index_name,inplace=True) #将行索引中的id索引放回列中,为了合并剩余的多级索引 self.df.reset_index(['id'],inplace=True) #合并剩余的多级索引 也就是从df的行索引名的角度与上面的groups变量保持一致 if self.Type: new_idx= self.df.index.map(lambda x:x[0]+'_'+x[1]) self.df.index = new_idx #用来设置选择的目标列 def __getitem__(self, col): self.my_col = [col] if isinstance(col, str) else list(col) #用来保存返回类型 1代表series 其他代表df self.return_type = len(self.my_col) return self def transform(self,my_func): df_list = [] #额外锁定id列 目的是为了保持分组前的相对位置 self.df = self.df[['id']+self.my_col] #遍历 for group_name in self.groups: #拿到单个组数据 single_group = self.df.loc[group_name] single_group.set_index(['id'],inplace=True) #这里的try...catch是为了满足跨列访问的要求 try: item = single_group.apply(my_func,axis=0) except: item = single_group.apply(my_func,axis=1) #如果是Series但长度为1(标量情况) if isinstance(item,pd.Series) and item.shape[0] == 1: #向量化 item = single_group.apply(lambda x:item[0],axis=1) #把单次的结果放入list中 df_list.append(item) #合并每组的结果 res = pd.concat(df_list) #判断是否为Series类型 if isinstance(res, pd.Series): res = res.to_frame(self.my_col[0]) #按之前的序号排序 res.reset_index(['id'],inplace=True) res.sort_values('id',inplace=True) res.set_index('id',inplace=True) #移除id列 res.reset_index(['id'],inplace=True,drop=True) #如果满足条件df转成Series if self.return_type == 1: return res[self.my_col[0]] return res- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 支持单列分组与多列分组
- 支持带有标量广播的
my_groupby(df)[col].transform(my_func)功能 pandas的transform不能跨列计算,请支持此功能,即仍返回Series但col参数为多列- 无需考虑性能与异常处理,只需实现上述功能,在给出测试样例的同时与
pandas中的transform对比结果是否一致
-
相关阅读:
docker详解(尚硅谷阳哥)
vue3自定义指令批量注册
说说对Fiber架构的理解?解决了什么问题?
docker
Vue基础之组件通信provide、inject
C#取两个集合的交集、并集和差集
C++ lambda表达式
Mbot ros编译环境安装
盛会落幕,精彩延续 | 云扩科技入选《2022中国AI商业落地市场研究报告》
JIRA 如何在项目之间移动 Issue
- 原文地址:https://blog.csdn.net/m0_52024881/article/details/126601851
