-
JVM面试常考的4个问题详解
1.JVM内存区域划分
1)程序计数器
内存中的最小区域,保存了下一条要执行的指令地址在哪。程序想要运行,JVM就得把字节码加载器来访到内存中,程序就会一条一条把指令从内存中取出来放到CPU上执行,因此需要记住当前执行到哪一条。操作系统是以线程为单位进行调度执行的,每个线程都得记录自己的执行位置,因此程序计数器每个线程都会有一个。
2)栈
存放局部变量和方法调用信息,方法调用的时候每次调用一个新的方法就都涉及到“入栈”操作、每次执行完了一个方法都涉及到“出站”操作。每个线程都有一个栈。
3)堆
一个进程只有一份,多个线程共用一个堆,因此也是内存中空间最大的区域。new出来的对象存放在堆中,对象的成员变量自然也是在堆中了。因此可以认为局部变量在栈上,成员变量和new的对象在堆上。
4)方法区
方法区中存放的是“类对象”(.java->.class二进制字节码文件),.class会被加载到内存中,也就被JVM构造成了类对象(加载的过程就称为“类加载”)。这里的类对象就是放到了方法区,类对象描述了这个类长什么样(泪的名字是啥,有啥成员,有哪些方法,每个成员叫啥名字是啥类型,每个方法叫啥名字是啥类型),除此之外静态成员成为了“类属性”,普通的成员是“实例属性”。
2.类加载
把.class文件加载到内存中构建成类对象
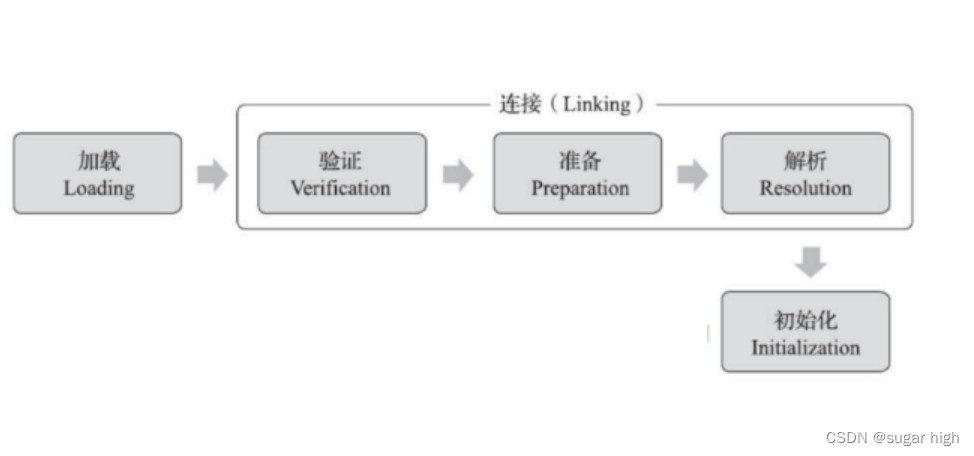
1)Loading环节
先找到对应的.class文件,然后打开并读取.class文件,同时初步生成一个类对象。
2)Linking环节
建立实体之间的联系
a.Verification
验证读到的内容是不是和规范中的格式完全匹配,如果发现这里读到的数据格式不符合规范,就会类加载失败并且抛出异常。
b.Preparation
给静态变量分配内存,并设置初始值。
c.Resolution
解析阶段是java虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常亮的过程。.class文件中常量是集中放置的,没一个常量都有一个编号,.class稳健的结构体初始化情况只是记录了编号,就需要根据编号找到对应的内容填充到类对象中。3)Intializing
真正地对类对象初始化,尤其针对静态成员。
经典面试题:

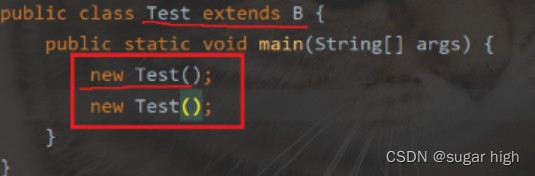

加载:程序是从main方法开始执行的,main是Test的方法,因此要执行main就需要先加载Test。Test继承自B要加载Test就要先加载B,B继承自A就要先加载A。因此先有前两行AB的静态代码块。
构造:要想构造Test,就得先构造B,要想构造B,就得先构造A。对于A来说构造过程(构造代码块->构造方法的执行)因此大的原则:
- 创建实例前必须进行类加载,类加载阶段会进行静态代码块的执行
- 静态代码块只是在类加载阶段执行一次
- 每次实例化,构造代码块先进行然后构造方法
- 分类执行在子类前
3.双亲委派模型
JVM中的类加载器如何根据类的全限定名(java.lang.String)找到.class文件的过程。
JVM里提供了专门的对象叫做“类加载器”负责进行类加载,当然找文件的过程也是类加载器来负责的,.class文件放置的位置可能有很多,因此JVM里面提供了多个类加载器,每个类加载器负责一个分区,默认的类加载器主要是3个:
- BootStrapClassLoader:负责加载标准库中的类(String,ArrayList,Random,Scanner…)
- ExtensionClassLoader:负责加载JDK扩展的类
- ApplicationClassLoader:负责加载当前项目目录的类
程序员还可以自定义加载器,来加载目录中的类,Tomcat就自定义了类加载器,用来专门加载webapps里面的.class。
双亲委派模型就描述了这个找目录过程。
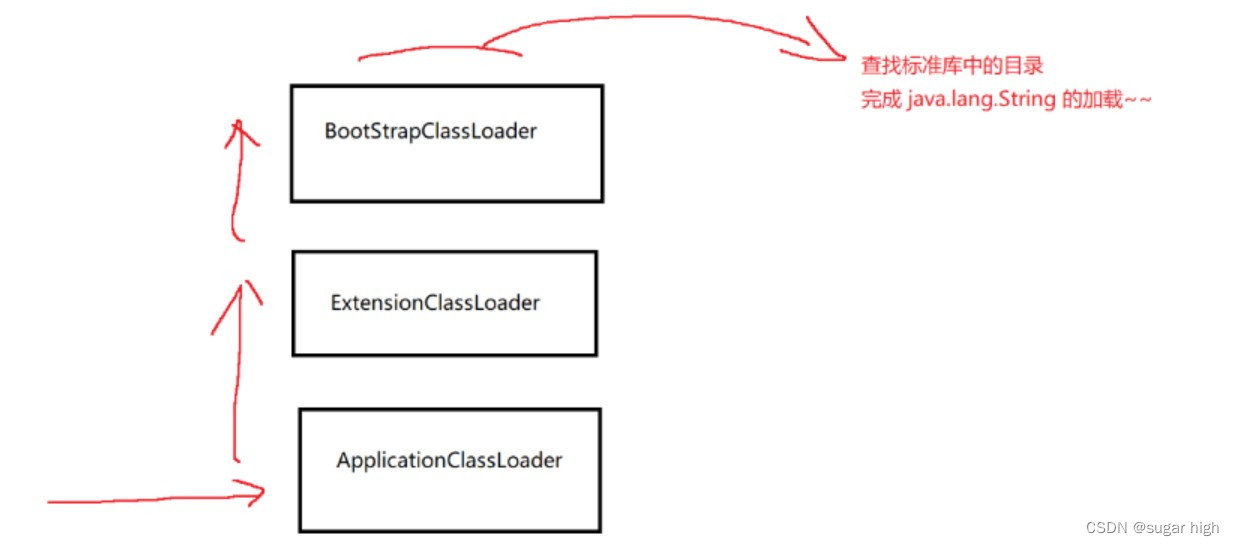
1)加载java.lang.String
程序启动先进入ACL类加载器
- ACL就会检查下,它的附加在其是否已经加载过了,如果没有就调用父“类加载器”ECL
- ECL也会检查下,它的父“加载器”是否已经加载过了,如果没有就调用父“类加载器”BSCL
- BSCL也会检查下,它的父“加载器”是否已经加载过了,没有父亲于是扫描自己负责的目录
- java.lang.String这个类在标准库能找到,直接由BSCL负责后续加载过程。
2)加载自己写的Test类

程序启动先进入ACL类加载器
- ACL就会检查下,它的附加在其是否已经加载过了,如果没有就调用父“类加载器”ECL
- ECL也会检查下,它的父“加载器”是否已经加载过了,如果没有就调用父“类加载器”BSCL
- BSCL也会检查下,它的父“加载器”是否已经加载过了,没有父亲于是扫描自己负责的目录,没有扫描到回到子加载器继续扫描
- ECL也会扫描下自己负责的目录,也没扫描到回到子加载器继续扫描
- ACL也会扫描下自己负责的目录,能找到Test类,于是进行后续加载。
设计原因:一旦程序员自己写的类和标准库中的类,全限定类名重复了也能够顺利加载到标准库中的类。自定义的类加载器可以遵守,也可以不遵守双亲委派,tomcat加载webapp得类就不遵守。
4.JVM的垃圾回收机制(GC)
1)垃圾回收的概念
垃圾回收是有运行时环境通过复杂的策略,判定内存是否可以回收并进行回收的动作。垃圾回收本质上是靠运行时环境额外做了很多工作,来完成自动释放内存的操作。
劣势:
1.消耗额外开销
2.可能会影响程序的流畅运行(垃圾回收经常会引入STW问题)垃圾回收的内容?内存
内存又分为以下几种:- 程序计数器:固定大小,不涉及释放,也不需要GC
- 栈:函数执行完毕,对应的栈帧也就自动释放了,也不需要GC
- 堆:最需要GC的,代码中的量的内存都是在堆上的
- 方法区:类对象,类加载来的,进行“类加载”就需要释放内存,卸载操作其实是一个非常低频的操作

途中需要进行回收的是不再使用单时尚未回收的内存。对于一部分仍然使用,一部分不在的对象,整体来说是不是放的,等到这个对象彻底完全不使用才真正释放。
2)回收的过程:
找垃圾/判定垃圾
a.基于引用计数(Python采取的方案)

针对每个对象都会额外引入一小块内存,保存这个对象有多少个引用指向它,这个内存不再使用就释放了(引用计数为0)
缺点:
- 空间利用率低,每个new的对象都得搭配个计数器(计数器假设4个字节),如果对象本身很大(几百个字节),多出来的4个字节就可以忽略。但是如果对象本身很小(自己才4个字节),多出4个字节相当于空间被浪费了一倍。
- 会有循环引用的问题
例子:
class Test{ Test t =null; } Test t1 = new Test(); Test t2 = new Test(); t1.t = t2; t2.t = t1; t1 = null; t2 = null;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

此时t1,t2,以及两个对象的状态如上图所示,两个对象的引用计数不为0,所以无法释放。但是由于引用长在彼此身上,外界的代码无法访问到这两个对象。此时此刻这两个对象就被孤立了,既不能使用又不能释放,这就出现了内存泄露的问题。
b.基于可达性分析(java采取的方案)
通过额外的线程,定期的针对整个内存空间的对象进行扫描,由一些起始位置(称为GCRoots),会类似于深度优先遍历一样,把可以访问到的对象都标记一遍(带有标记的对象就是可达的对象),没被标记的对象就是不可达对象(垃圾)。
GCRoots:
- 栈上的局部变量
- 常量池中的引用指向的对象
- 方法区中静态成员指向
优点:空间利用率低,解决了循环引用的问题
缺点:系统开销大,遍历一次可能比较慢释放垃圾
a.标记清除

标记就是可达性分析的过程,清楚就是直接释放内存。此时如果直接释放虽然内存是还给系统了,但是释放的内存是离散的会带来“内存碎片”问题。
b.复制算法

复制算法是为了解决内存碎片的问题,用一半丢一半直接把不是垃圾的拷贝到另一半,把原来整个空间整体都释放掉。此时内存碎片的问题就迎刃而解了。
缺点:内存空间利用率低,如果要保留的对象多,释放的对象少,复制开销就很大。
c.标记整理
针对复制算法做出的改进
原理类似于顺序表删除中间元素,有一个搬运操作。这个方案空间利用率是高了,但是仍然没有解决复制/搬运元素开销大的问题
d.综合使用(JVM)
实际的JVM中的实现会把多种方案结合起来使用,即“分代回收”,针对对象进行分类。根据对象“年龄”分类,一个对象熬过一轮GC的扫描就称为“长了一岁”,针对不同年龄采取不同方案。
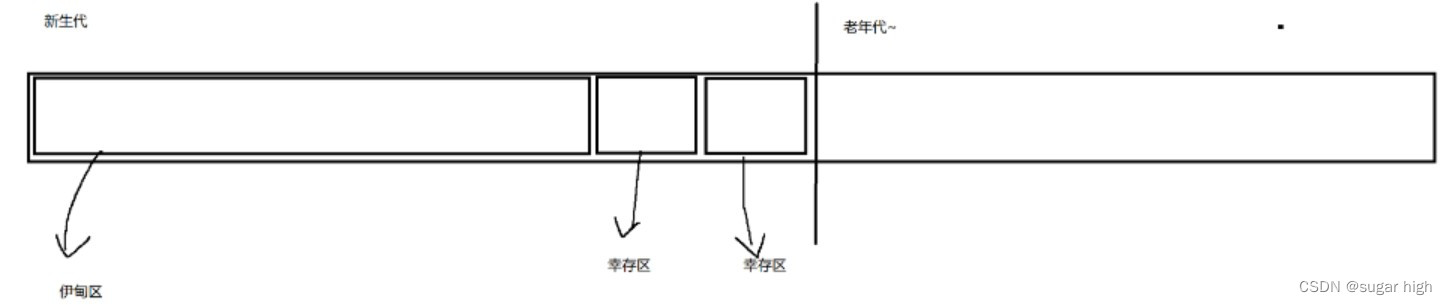
- 刚创建出来的对象就放在伊甸园
- 如果伊甸园的对象熬过一轮GC扫描,就会被拷贝到幸存区(应用复制算法)
- 在后续的几轮GC中,幸存区的对象就在两个幸存区之间来回拷贝(复制算法),每一轮都会淘汰掉一波幸存者
- 在后续若干轮后进入老年代,老年代的特点:对象年龄大,而且经验可得对象年龄越大,存活的可能性也就越大,因此老年代的GC扫描频率大大低于新生代。老年代使用标记整理方式进行回收。
3)垃圾收集器
比较老的垃圾收集器
- Serial收集器,Serial Old收集器,串行收集即在进行垃圾扫描和释放的时候业务要停止工作,这种方式扫描的慢释放的也慢,也产生严重的STW。
- ParNew收集器(新生代),Parallel Old收集器(老年代),并发手机引入多线程。
新的收集器
1)CMS收集器- 初始标记速度很快,会引起短暂的STW(只是找到GCRoots)
- 并发标记,虽然速度慢但是可以和业务线程并发执行,不会产生STW
- 重新标记在b业务代码可能会影响并发标记的结果,对b结果的微调,虽然会引起STW但只是微调速度快 回收内存也是和业务线程并发
2)G1收集器(唯一一款全区域的垃圾回收器,Java11de JVM)
把整个内存分成了很小的区域Region,给这些Region进行了不同的标记,有的Region方新生代对象,有的对象放老年代对象。然后在扫描的时候一次扫若干Region(不追求一轮GC就扫描完分多次扫),相比CMS对于业务代码影响更小。G1在当下可以优化到让STW停顿时间小于1ms。
-
相关阅读:
Book2Notion:将豆瓣图书信息同步到Notion的Chrome插件
RAR压缩包如何加密,忘记密码如何找回?
涨姿势了,殊途同归的图片交互动效制作!
Python:实现deutsch jozsa算法(附完整源码)
java的stream让我灵光一现
C++ 中的单例模式singleton
openresty 内置变量
应急响应靶机训练-Linux2
GAME (HDU)(博弈论)
报错处理:Error: Redis server is running but Redis CLI cannot connect
- 原文地址:https://blog.csdn.net/weixin_46429649/article/details/126658820