-
1.7 Elasticsearch分词与内置分词器
什么是分词?
把文本转换为一个个的单词,分词称之为analysis,es默认只对英文语句做分词,中文不支持,每个中文都会被拆分为独立的个体。
- 英文分词:My name is Peter Parker,I am a Super Hero. I don't like the Criminals.
- 中文分词:我的名字是皮特帕克,我是一个超级英雄。我不喜欢犯罪。
全局分析
POST /_analyze
{
"analyzer": "standard",
"text": "text文本"
}演示:
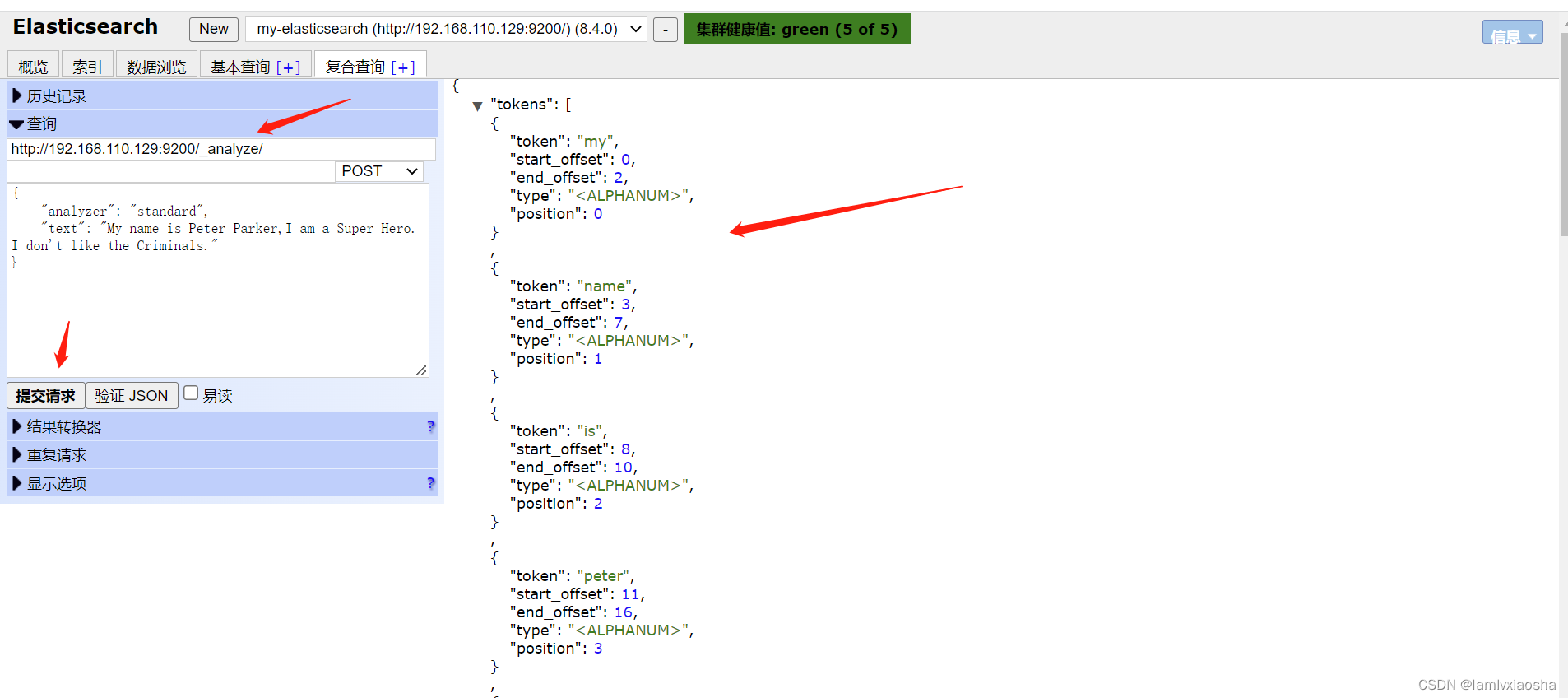
结果:
{
"tokens":[
{
"token":"my",
"start_offset":0,
"end_offset":2,
"type":"",
"position":0
},
{
"token":"name",
"start_offset":3,
"end_offset":7,
"type":"",
"position":1
},
{
"token":"is",
"start_offset":8,
"end_offset":10,
"type":"",
"position":2
},
{
"token":"peter",
"start_offset":11,
"end_offset":16,
"type":"",
"position":3
},
{
"token":"parker",
"start_offset":17,
"end_offset":23,
"type":"",
"position":4
},
{
"token":"i",
"start_offset":24,
"end_offset":25,
"type":"",
"position":5
},
{
"token":"am",
"start_offset":26,
"end_offset":28,
"type":"",
"position":6
},
{
"token":"a",
"start_offset":29,
"end_offset":30,
"type":"",
"position":7
},
{
"token":"super",
"start_offset":31,
"end_offset":36,
"type":"",
"position":8
},
{
"token":"hero",
"start_offset":37,
"end_offset":41,
"type":"",
"position":9
},
{
"token":"i",
"start_offset":43,
"end_offset":44,
"type":"",
"position":10
},
{
"token":"don't",
"start_offset":45,
"end_offset":50,
"type":"",
"position":11
},
{
"token":"like",
"start_offset":51,
"end_offset":55,
"type":"",
"position":12
},
{
"token":"the",
"start_offset":56,
"end_offset":59,
"type":"",
"position":13
},
{
"token":"criminals",
"start_offset":60,
"end_offset":69,
"type":"",
"position":14
}
]
}使用现有的索引分析
POST /my_doc/_analyze
{
"analyzer": "standard",
"field": "name",
"text": "text文本"
}演示:
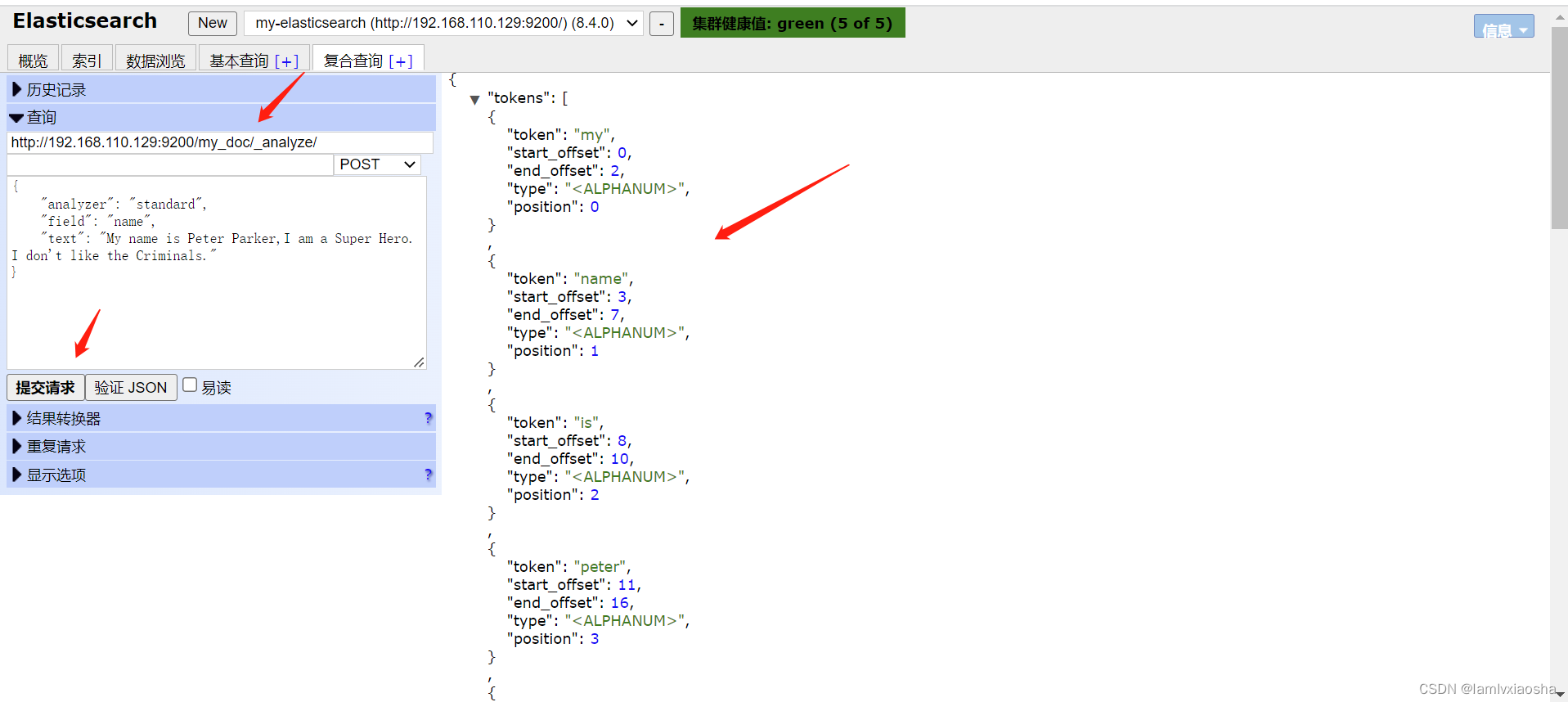
结果:
{
"tokens":[
{
"token":"my",
"start_offset":0,
"end_offset":2,
"type":"",
"position":0
},
{
"token":"name",
"start_offset":3,
"end_offset":7,
"type":"",
"position":1
},
{
"token":"is",
"start_offset":8,
"end_offset":10,
"type":"",
"position":2
},
{
"token":"peter",
"start_offset":11,
"end_offset":16,
"type":"",
"position":3
},
{
"token":"parker",
"start_offset":17,
"end_offset":23,
"type":"",
"position":4
},
{
"token":"i",
"start_offset":24,
"end_offset":25,
"type":"",
"position":5
},
{
"token":"am",
"start_offset":26,
"end_offset":28,
"type":"",
"position":6
},
{
"token":"a",
"start_offset":29,
"end_offset":30,
"type":"",
"position":7
},
{
"token":"super",
"start_offset":31,
"end_offset":36,
"type":"",
"position":8
},
{
"token":"hero",
"start_offset":37,
"end_offset":41,
"type":"",
"position":9
},
{
"token":"i",
"start_offset":43,
"end_offset":44,
"type":"",
"position":10
},
{
"token":"don't",
"start_offset":45,
"end_offset":50,
"type":"",
"position":11
},
{
"token":"like",
"start_offset":51,
"end_offset":55,
"type":"",
"position":12
},
{
"token":"the",
"start_offset":56,
"end_offset":59,
"type":"",
"position":13
},
{
"token":"criminals",
"start_offset":60,
"end_offset":69,
"type":"",
"position":14
}
]
}es内置分词器
- standard:默认分词,单词会被拆分,大写会被转换为小写。
- simple:按照非字母分词。大写会转为小写。
- whitespace :按照空格分词。忽略大小写。
- stop: 去除无意义单词。比如the/a/an/is...
- keyword:不做分词。把整个文本作为一个单独的关键词
{
"analyzer": "standard",
"text": "My name is Peter Parker,I am a Super Hero. I don't like the Criminals."
} -
相关阅读:
【华为机试真题 JAVA】最大嵌套括号深度-100
概率论与数据统计学习:随机变量(一)——知识总结与C语言案例实现
【3D建模全流程教学】在 ZBrush、Maya 和 Marvelous Designer 中制作一位逼真的女孩
深入理解函数式编程(上)
灵性·挖掘 2:自我迭代之路
【一起学数据结构与算法】0基础学习集合Map和Set(包含面试题)
PowerBI-窗口函数-INDEX
【HarmonyOS】鸿蒙系统中应用权限等级介绍、定义、申请授权讲解
北京旅游HTML学生网页设计作品 dreamweaver作业静态HTML网页设计模板 北京旅游景点网页作业制作 HTML+CSS+JS
英特尔 SGX 技术概述
- 原文地址:https://blog.csdn.net/Xx13624558575/article/details/126639642