-
计算机视觉项目实战-目标检测与识别
😊😊😊欢迎来到本博客😊😊😊
本次博客内容将继续讲解关于OpenCV的相关知识
🎉作者简介:⭐️⭐️⭐️目前计算机研究生在读。主要研究方向是人工智能和群智能算法方向。目前熟悉深度学习(keras、pytorch、yolov5),python网页爬虫、机器学习、计算机视觉(OpenCV)、群智能算法。然后正在学习深度学习的相关内容。以后可能会涉及到网络安全相关领域,毕竟这是每一个学习计算机的梦想嘛!
📝目前更新:🌟🌟🌟目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、目前正在更新计算机视觉-OpenCV的相关内容。
💛💛💛本文摘要💛💛💛本文我们将继续讲解AI领域项目-目标识别的相关操作。

🌟写在前面
本此博客我们简单的介绍一下目标检测与识别,我们从头开始介绍,从最简单的然后逐渐的走进项目。首先我们介绍使用深度学习和CV去做一个简单的目标识别项目。
🌟目标识别的重要应用场景
目标识别技术已广泛应用于国民经济、空间技术和国防等领域。
利用雷达和计算机对遥远目标进行辨认。现代雷达(包括热雷达和激光雷达)不但是对遥远目标进行探测和定位的工具,而且能够测量与目标形体和表面物理特性有关的参数,进而对目标分类和识别。雷达目标识别技术开始于50年代末期,美国人用单脉冲雷达跟踪并记录了苏联发射的第二颗人造地球卫星的回波,通过对回波信号的分析,确认卫星上装有角反射器。现代防空雷达已具有辨认少数典型飞机机型的能力。反弹道导弹防御雷达(见目标截获和识别雷达)能从洲际导弹的碎块和少量诱饵中识别出真弹头。在空间探测中,对月球和金星表面的地形测绘和电磁物理特性参数测量,以及判定卫星发射后太阳电池翼是否打开等,都能应用目标识别技术。
在地球遥感方面,微波遥感仪器可以测定潮汐、海冰厚度和海面风速;可以对农作物分类辨识,并作长势检查和产量估计;还可以勘探矿藏和石油等地球资源。
目标识别还可利用再入大气层后的大团过滤技术。当目标群进入大气层时,在大气阻力的作用下,目标群中的真假目标由于轻重和阻力的不同而分开,轻目标、外形不规则的目标开始减速,落在真弹头的后面,从而可以区别目标。目标分类与目标识别的含义稍有不同。目标分类是将被测目标与已知目标的训练样本一一比较,回答同或异(真或假)。而目标识别还要求指出目标特性的具体数值,如形体、表面粗糙度和介电常数等。因此识别比分类包含更多的目标特征信息。🌟任务目标
主要做一个目标识别任务。比如说下面几个图片,我能够利用最后的程序来识别他们分别是什么物体。


这里面不仅仅包含棕熊和火箭,还可以做很多很多的任务识别。我们来看一下。

这里面做的是一个1000分类的任务。其中包括一些水果,比如香蕉,或者是一些球类,比如说篮球、假发等等。🌟项目解析
首先我们导入了utils_paths模块以及三方工具包。
import utils_paths import numpy as np import cv2- 1
- 2
- 3
那么我们来看一下utils_paths模块做了什么。
import os image_types = (".jpg", ".jpeg", ".png", ".bmp", ".tif", ".tiff") def list_images(basePath, contains=None): # 返回有效的文件集 return list_files(basePath, validExts=image_types, contains=contains) def list_files(basePath, validExts=None, contains=None): # 循环遍历目录结构 os.walk(path)是一个目录的迭代器。root就是本身的地址,dirs就是该文件夹下的子文件夹目录,filenames是path路径下文件 for (rootDir, dirNames, filenames) in os.walk(basePath): # 循环遍历当前目录的中文名 for filename in filenames: # 如果包含字符串不是none,并且文件名不包含提供的字符串,则忽略该文件 if contains is not None and filename.find(contains) == -1: continue # 确定当前文件的文件扩展名 ext = filename[filename.rfind("."):].lower() # 检查该文件是否为图像,是否应该进行处理 if validExts is None or ext.endswith(validExts): # 构造到图像的路径并生成它 imagePath = os.path.join(rootDir, filename) yield imagePath- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
首先这个模块定义了照片的类型,都可以是什么格式的其中包括jpg、png等等。
os.walk(path)是一个目录的迭代器。其中返回三个参数。- root就是本身的地址。
- dirs就是该文件夹下的子文件夹目录。
- filenames是path路径下文件。
我们这个模块的目标就是要拿到照片的路径。并且yield回主程序当中。yield表示一个一个返回,返回一个然后处理,然后在返回去一个,直到结束。然后这里面判断了一下照片的拓展名,然后进行了判断看文件的拓展名和我们设置的那几个一致不一致。如果一致,就可以进行路径提取了~
rows = open("synset_words.txt").read().strip().split("\n") classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]- 1
- 2
我们先要对标签文件进行处理!那么这里
strip()表示消除空格。split("\n")这里就是以空格为分隔符。也就是说我们要一行一行的处理。我们截取一部分来看一下。

遍历每一行,然后从第二个元素开始找,并且以,为分隔符来看分类标签都是什么。这里就把分类标签弄好了。
这里我们用到了深度学习当中的caffe,导入的是所需要的配置文件。net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt", "bvlc_googlenet.caffemodel")- 1
- 2
cv2.dnn.readNetFromCaffe用于读取已经训练好的caffe模型。我们截取配置文件的其中一部分来看一下。

我们可以看到就是做了卷积,池化等操作。同深度学习中的卷积神经网络的做法较为相似,只不过这个caffe网络做的较深。光网络结构这个就有2000行左右。我们在这里进行了导入。
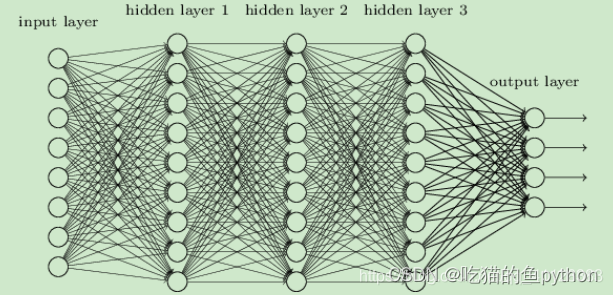
DNN神经网络的组成:- 输入层:神经网络的第一层,原始的样本数据
- 隐藏层:除了输入层,输出层,中间的都是隐藏层
- 输出层:神经网络的最后一层,最终的计算结果
神经网络的特点:
- 每个连接都有个权值
- 同一层神经元之间没有连接
- 最后的输出结果对应的层也称之为全连接层
imagePaths = sorted(list(utils_paths.list_images("images/")))- 1
然后从
utils_paths模块中拿到图片路径!image = cv2.imread(imagePaths[0]) resized = cv2.resize(image, (224, 224)) # image scalefactor size mean swapRB blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123)) print("First Blob: {}".format(blob.shape))- 1
- 2
- 3
- 4
- 5
这里读入了照片,然后做了一次resize操作,resize成(224,224)的图片。然后我们使用了
cv2.dnn.blobFromImage这个函数,我们在这里介绍一下。

cv2.dnn.blobFromImage就是得到预测结果。我们来细致的讲一下这里:
在深度学习和图像分类领域,预处理任务通常包括了三类。- 减均值操作。
- 按照比例缩放。
- 通道交换。

Opencv提供两个函数用来促进图像预处理,用于深度学习分类。
减去均值帮助我们对抗输入图像的亮度变化,所以我们将减去均值作为作为一个技术用来帮助我们的卷积神经网络,通常三个通道,R均值,G均值,B均值。然后我们也有一个比例因子,需要加上一个标准化。
需要注意的一点就是:不是所有的深度学习架构执行减去均值和缩放。blob=cv2.dnn.blobFromImage(image,scalefactor=1.0,size,mean,swapRB=True,crop=False,ddepth=CV_32F)- 1
net.setInput(blob) preds = net.forward()- 1
- 2
然后我们做了一次前向传播。就可以得到结果了。
idx = np.argsort(preds[0])[::-1][0] text = "Label: {}, {:.2f}%".format(classes[idx], preds[0][idx] * 100) cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) cv2.imshow("Image", image) cv2.waitKey(0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后我们取分值最大的,然后再图片上添加上标题。就ok了!然后展示出来。
for p in imagePaths[1:]: image = cv2.imread(p) image = cv2.resize(image, (224, 224)) images.append(image) # blobFromImages函数,注意有s blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))#均值 print("Second Blob: {}".format(blob.shape)) # 获取预测结果 net.setInput(blob) preds = net.forward() for (i, p) in enumerate(imagePaths[1:]): image = cv2.imread(p) idx = np.argsort(preds[i])[::-1][0] text = "Label: {}, {:.2f}%".format(classes[idx], preds[i][idx] * 100) cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) cv2.imshow("Image", image) cv2.waitKey(0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
同样对于后面的图片路径也做出一个相同的操作。然后我们试了一下结果。




这里面做出来的一些展示。左上角都已经进行了识别出来了!🌟完整代码
# 导入工具包 import utils_paths import numpy as np import cv2 # 标签文件处理 rows = open("synset_words.txt").read().strip().split("\n") classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows] # Caffe所需配置文件 net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt", "bvlc_googlenet.caffemodel") # 图像路径 imagePaths = sorted(list(utils_paths.list_images("images/"))) # 图像数据预处理 image = cv2.imread(imagePaths[0]) resized = cv2.resize(image, (224, 224)) # image scalefactor size mean swapRB blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123)) print("First Blob: {}".format(blob.shape)) # 得到预测结果 net.setInput(blob) preds = net.forward() # 排序,取分类可能性最大的 idx = np.argsort(preds[0])[::-1][0] text = "Label: {}, {:.2f}%".format(classes[idx], preds[0][idx] * 100) cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) # 显示 cv2.imshow("Image", image) cv2.waitKey(0) # Batch数据制作 images = [] # 方法一样,数据是一个batch for p in imagePaths[1:]: image = cv2.imread(p) image = cv2.resize(image, (224, 224)) images.append(image) # blobFromImages函数,注意有s blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))#均值 print("Second Blob: {}".format(blob.shape)) # 获取预测结果 net.setInput(blob) preds = net.forward() for (i, p) in enumerate(imagePaths[1:]): image = cv2.imread(p) idx = np.argsort(preds[i])[::-1][0] text = "Label: {}, {:.2f}%".format(classes[idx], preds[i][idx] * 100) cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) cv2.imshow("Image", image) cv2.waitKey(0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63

🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!
-
相关阅读:
java计算机毕业设计ssm易物小店交换系统-二手咸鱼交易系统
阳光能源,创造永远:光模块的未来”:随着大数据、区块链、云计算和5G的发展,光模块成为满足不断增长的数据流量需求的关键技术
卷积神经网络简介
Spring事务几种失效原因
1339 - Ancient Cipher (UVA)
SpringBoot+MinIO8.0开箱即用的启动器
RABBITMQ的本地测试证书生成脚本
Spring 是怎么解决循环依赖问题的呢?
计算机考研|一个408统考的王炸复习顺序
js控制手机蓝牙
- 原文地址:https://blog.csdn.net/m0_37623374/article/details/125953256
