-
DPDK中Ring的优先级反转问题
当同一个ring被多个生产者使用,而且一个生产者在非实时核,另一个生产者在实时核时,就有可能出现实时核等待非实时核enqueue结束的情况。
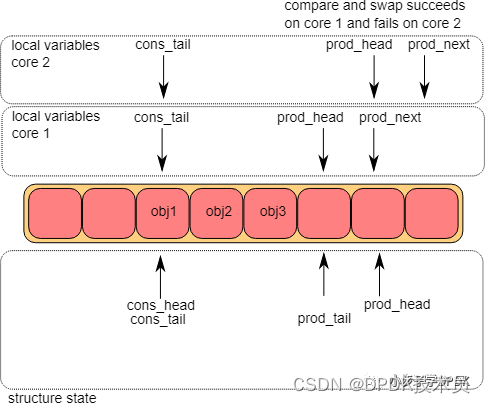
如DPDK的文档所述,每个core都会通过函数__rte_ring_update_tail()去更新ring->prod_tail,表示enqueue结束。一个core只有在ring->prod_tail和本地的prod_head相等时,才可以更新。上图中,只有core1能更新成功,core2需要等待core1更新结束。如果core1是非实时核,在更新ring->prod_tail前被切走了,等待时间就可能会比较长。
rte_ring_mp_enqueue_bulk
->rte_ring_mp_enqueue_bulk_elem
->__rte_ring_do_enqueue_elem
->__rte_ring_update_tail
https://elixir.bootlin.com/dpdk/v21.11/source/lib/ring/rte_ring_c11_pvt.h#L15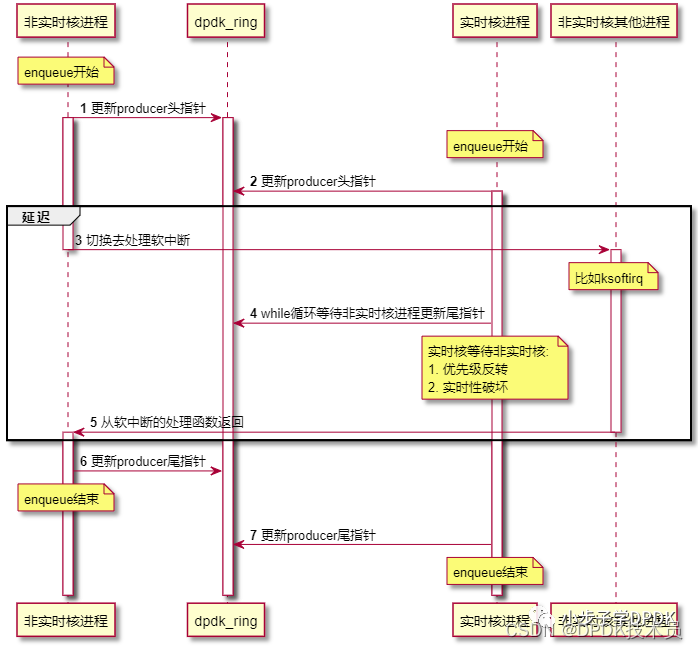
图中展示了非实时核被切走,而实时核在等待非实时核ring的prod_tail更新结束的情况。
解决方案
-
使用硬件来调度,有些芯片会自带调度或队列处理的模块。
-
非实时核和实时核间的通信,采用不同队列来实现。比如非实时核发到实时核用一个队列,实时核发到非实时核用另一个队列。实时核之间通信还是用原来的队列。新队列可以有几种实现方式:
a. 手写ring buffer,可以参考linux的ring buffer实现,比如https://lwn.net/Articles/340443/。改进:ring里最好存的是offset,而不是整个object,性能更好。注意linux的ring buffer或自己实现的ring,一般不是sync的,有可能出现这边push了,对端还不能pop的情况。比如发送端发信号量让接收方来取包,虽然信号量过去了,但是可能包还没有真正到队列。
b. C++ boost库的boost::lockfree::queue实现,boost库的ring是sync的,也就是push到ring返回后,对端一定可以pop。
c. 使用DPDK的memif的实现通信。
性能对比
硬件调度 > DPDK队列 > 手写ring buffer > boost ring buffer > DPDK memif。
如果队列只是被一个core使用,就不需要考虑是否加锁或者无所编程了,直接用C++默认的push和pop函数放到队列即可。原文链接:https://mp.weixin.qq.com/s/g4Dbw8X8bylUZfid8eluOA
学习更多dpdk视频
Dpdk/网络协议栈/ vpp /OvS/DDos/NFV/虚拟化/高性能专家 学习地址: https://ke.qq.com/course/5066203?flowToken=1043799
DPDK开发学习资料、教学视频和学习路线图分享有需要的可以自行添加学习交流q 君羊909332607 获取
-
-
相关阅读:
2023年 DevOps 七大趋势
项目实践《小说网站数据爬取》
IEEE论文Word转高清PDF
通过ExecutorService、Callable、Future实现有返回结果的多线程来处理有轮询业务
【实践篇】redis管道pipeline使用详解
vue3+vite使用monaco-editor编辑器
动态规划 拿小球简单版(爱思创)
apk和小程序渗透
RobotFrameWork自动化测试环境搭建
Tabby--一个终端连接工具
- 原文地址:https://blog.csdn.net/weixin_60043341/article/details/126623500