-
集合&Set集合详解
集合
- 集合与数组区别
- 集合长度可变,数组长度固定
- 数组中可以存储基本数据类型也可存储对象,集合只能存储对象
- 在元素个数不确定时,使用集合进行数据的增删改查
Java中的集合代表—>collection是所有集合的父类
Collection集合体系
Collection接口,其子接口有List、Set接口
Set集合
Set接口实现类:HashSet ( LinkedHashSet<> )、TreeSet
HashSet:添加元素无序、不重复、无索引
LinkedHashSet<> :有序
TreeSet:按照大小默认升序排序
List集合
List接口实现类:ArrayList、LinekdList
ArrayList、LinkedList:有序、可重复、有索引
Collection常用方法
添加元素
(1)add(E obj):添加元素对象到当前集合中
ArrayList<String> list = new ArrayList<>(); list.add("张三"); list.add("桂电"); list.add("大一"); list.add("123456");- 1
- 2
- 3
- 4
- 5
(2)addAll(Collection other):添加other集合中的所有元素对象到当前集合中
ArrayList<Object> objects = new ArrayList<>(Arrays.asList(str)); objects.addAll(list);- 1
- 2
删除元素
(1) boolean remove(Object obj) :从当前集合中删除第一个找到的与obj对象equals返回true的元素。
(2)boolean removeAll(Collection coll):从当前集合中删除所有与coll集合中相同的元素。
判断
(1)boolean isEmpty():判断当前集合是否为空集合。
(2)boolean contains(Object obj):判断当前集合中是否存在一个与obj对象equals返回true的元素。
(3)boolean containsAll(Collection c):判断c集合中的元素是否在当前集合中都存在。即c集合是否是当前集合的“子集”。
获取元素个数
(1)int size():获取当前集合中实际存储的元素个数
System.out.println(objects.size());- 1
集合转为数组
(1)Object[] toArray():返回包含当前集合中所有元素的数组
Object[] objects1 = objects.toArray();- 1
拓展:数组转为集合
(1)Arrays.asList(object[ ] obj)
ArrayList<Object> objects = new ArrayList<>(Arrays.asList(str));11- 1
add与addAll区别
public static void main(String[] args) { Collection coll = new ArrayList(); coll.add(1); coll.add(2); coll.add(3); System.out.println("coll集合元素个数="+coll.size());//--->3 Collection coll2 = new ArrayList(); coll2.add(4); coll2.add(5); coll2.add(6); //coll2.addAll(coll); --->6 coll2.add(coll);//--->4 System.out.println("coll2集合元素个数="+coll2.size()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
迭代器Iterator
迭代器使用
Iterator接口依赖于Collection集合存在
Iterator常用方法:
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
下面利用迭代器遍历集合
public static void main(String[] args) { ArrayList<Object> list = new ArrayList<>(); list.add(23.3); list.add("wao"); list.add(false); Iterator<Object> iterator = list.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
tips::在进行集合元素取出时,如果集合中已经没有元素了,还继续使用迭代器的next方法,将会发生java.util.NoSuchElementException没有集合元素的错误。
迭代器的快速失败机制
如果在Iterator、ListIterator迭代器创建后的任意时间从结构上修改了集合(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险
public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); list.add(4); Iterator<Integer> iterator = list.iterator(); while(iterator.hasNext()){ Integer temp = iterator.next(); if(temp % 2 == 0){ iterator.remove(); //删除数据时只能采用迭代器自身的remove方法 } } for (Integer integer : list) { System.out.println(integer+" "); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Set集合
set接口是Collection的子接口,不提供额外的方法,但在使用规范比Collection更加严格
- 不允许包含重复的元素
- 遍历可以通过Foreach和Iterator
- set接口常用实现类有:HashSet、TreeSet、LinkedHashSet
set集合无序存储的原因
set集合的底层实现实际上时采用哈希表存储元素
JDK1.8之前:哈希表 = 数组 + 链表 + ( 哈希算法 )
JDK1.8之后:哈希表 = 数组 + 链表 + 红黑树 + ( 哈希算法 )
哈希算法简述
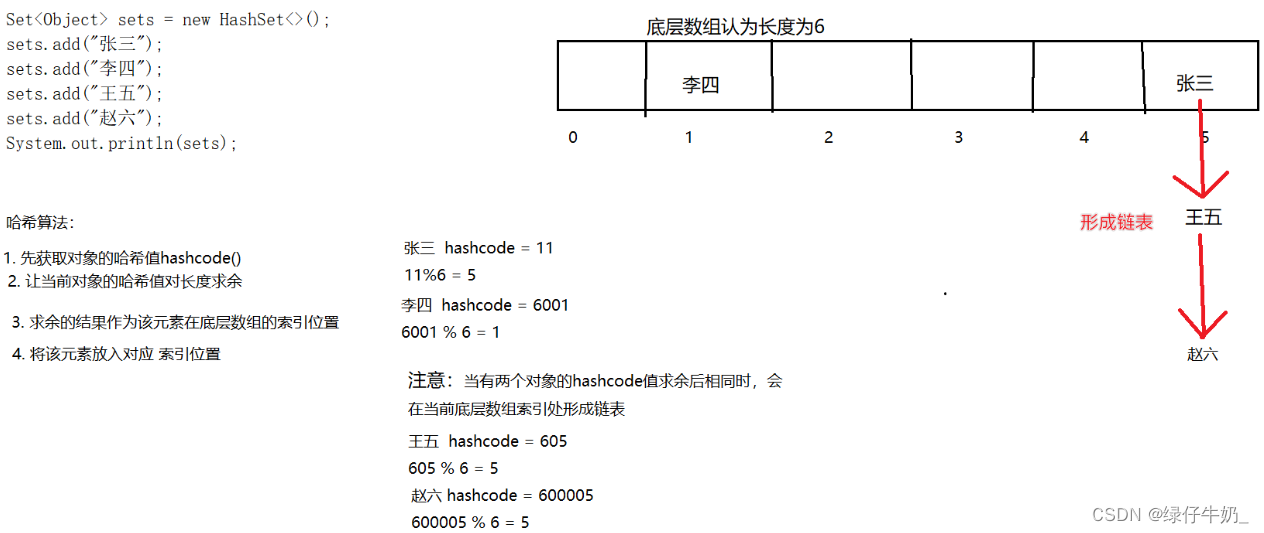
- 现在假设认为哈希表的底层数组长度为6
Set<Object> sets = new HashSet<>(); sets.add("张三"); sets.add("李四"); sets.add("王五"); sets.add("赵六"); System.out.println(sets);- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们已经知道哈希表的的底层是数组+链表
数组体现:
- 首先利用hashcode得到对象的哈希值
- 将其哈希值对底层数组长度求余得到该对象对应的底层数组的存储索引位置
- 将元素放入底层数组
链表体现:
当在底层数组中的某一位置已经有了元素占据,则再次需要有元素放入该位置时,将会在该位置形成链表
原理:
HashSet用法及概述
java.util.HashSet的底层实现实际是java.util.HashMap,而HashMap的底层是一个哈希表。HashSet集合判断两个元素相等的标准:
两个对象通过hashcode()方法比较相等,并且两个对象的equals()方法的返回值也相等。故存储到HashSet的元素需要重写hashcode()和equals()方法
HashSet集合的对象存储方式:每个hascode的值,分配一个槽(slot),同一个槽的对象,以链表方式存储
class Test{ private int count; public Test() {} public Test(int count) {this.count = count;} public int getCount() {return count;} public void setCount(int count) {this.count = count;} @Override public String toString() {return "Test{" + "count=" + count + '}';} @Override public int hashCode() {return this.count;} @Override public boolean equals(Object obj) { if (obj == null){ return false; } if (this == obj){ //this指参与比较的当前对象,即谁调用了equals方法 this就是谁 return true; } if (obj instanceof Test){ //强制转换 Test newTest = (Test) obj; if (this.count == newTest.count){ return true; } } return false; } } public class MainTest { public static void main(String[] args) { HashSet<Test> hashset = new HashSet<>(); /*Test t1 = new Test(); Test t2 = t1; Test t3 = t2; Test t4 = t3; hashset.add(t1); hashset.add(t2); hashset.add(t3); hashset.add(t4);*/ hashset.add(new Test(3)); hashset.add(new Test(1)); hashset.add(new Test(2)); hashset.add(new Test(3)); for (Test test : hashset) { System.out.println(test); } /** * Test{count=1} * Test{count=2} * Test{count=3} */ HashSet<String> strSet = new HashSet<>(); strSet.add("woc"); strSet.add("wok"); strSet.add("wok"); for (String s : strSet) { System.out.println(s); } /** * wok * woc */ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
equals和hashCode方法详解
- Hashset是set接口的实现类之一,故而继承了set接口的特点
- 向hashset存入元素,调用hashcode方法得到该对象的哈希值,该哈希值决定了该元素在hashset中的存储位置
- 如果两个元素的equals返回值相同,但是hashcode返回值不同,hashset依然可以添加成功,但是存在不同位置
- 如果两个对象的哈希值相同会继续比较equals内容是否相同,如果相同则确认重复
- 故:判断两个元素是否相等,需要判断两个元素的equals和hashcode的返回值是否全部相等
equals方法是做什么的?
不对equals方法进行重写时,默认调用object的equals方法。而equals方法实际上是对两个对象的的地址进行判断,判断两个对象地址是否相同
什么是hashcode?
hashcode也叫做哈希值,每一个对象都会有一个哈希值。但要注意区分哈希值并不代表该对象的存储地址,哈希值的组成是由该对象的value字符串决定,与地址无关。
从抽象角度来讲,哈希值是一个名词。每个对象会有自己的存储地址,而这个“存储地址”也是一个名词,可以看成是这个对象的一个特性,而哈希值也是如此,调用hashCode()方法即可得到对象的哈希值。在集合的应用中,hashcode也代表了该对象在此集合的存储位置
为什么要重写equals和hashCode方法?
– 两个对象比较时如果equals返回true,则hashCode方法返回值必须相同
如果不重写hashCode方法则两个对象的hashCode方法返回的依然是两个对象的地址值,此结果必然不同。也就出现了equals相等但是hashCode方法返回值不同的情况
重写equals就必须重写hashCode方法
hashcode方法重写规则
- 同一个对象多次调用hashcode方法时的返回值应该始终保持一致
- 当两个元素的equals的返回值为true时,则 两个对象调用hashcode方法也应该返回 相同的值
class A{ //重写hashcode方法始终返回 1 @Override public int hashCode() { return 1; } } class B{ //重写equals方法始终返回true @Override public boolean equals(Object obj) { return true; } } class C{ //重写equals和hashcode方法始终返回1和true @Override public int hashCode() { return 1; } @Override public boolean equals(Object obj) { return true; } } public class HashSetUse { public static void main(String[] args) { HashSet<Object> hashset = new HashSet<>(); hashset.add(new A()); hashset.add(new A()); hashset.add(new B()); hashset.add(new B()); hashset.add(new C()); //new c无法添加:equals和hashcoe方法返回值始终相等 System.out.println(hashset); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 如果需要set集合认为只要两个对象的内容相同就判定为重复,则必须重写equals和hashcode方法
class Car{ private String name; private double price; public Car(String name,double price) { this.name = name; this.price = price; } //重写equals和hashcode方法 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Car car = (Car) o; return Double.compare(car.price, price) == 0 && Objects.equals(name, car.name); } @Override public int hashCode() { return Objects.hash(name, price); } //重写方法后set集合将会认为两个对象的内容若一致,就会判定为重复 @Override public String toString() {return "Car{" + "name='" + name + '\'' + ", price=" + price + '}';} } public class HashSetUse02 { public static void main(String[] args) { Set<Car> sets = new HashSet<>(); //两个对象,内容相同 Car car1 = new Car("Benz",47.9); Car car2 = new Car("Benz",47.9); sets.add(car1); sets.add(car2); System.out.println(sets); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
LinkedHashSet
- LinkedHashSet是HashSet的子类
public class LinkedHashSet<E> extends HashSet<E>- 1
- 2
- 3
- 有序、不重复、无索引
- 此时的有序指的是向集合中添加元素的顺序,并不是排序
public static void main(String[] args) { LinkedHashSet<String> lhset = new LinkedHashSet<>(); //LinkedHashSet的有序是指--->按照添加顺序输出 lhset.add("卡梅隆"); lhset.add("勒布朗"); lhset.add("詹姆斯"); lhset.add("安东尼"); lhset.add("凯文"); System.out.println(lhset); //运行--> [卡梅隆, 勒布朗, 詹姆斯, 安东尼, 凯文] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
LinkedHashSet能够有序存储的原因?
已经知道LinkedHashSet是继承了HashSet的子类,在HashSet的基础上,为每个添加进该集合的元素增加了一条链来维护顺序
以上述代码为例:
首先添加字符串“ 卡梅隆 ”,再从此处引出链指向下一个“ 勒布朗 ”依次类推
图解所示:
TreeSet集合
TreeSet概述
- 继承Set接口,具有Set集合的特点同样不能存储相同对象
- 不同的是TreeSet集合可以确保集合处于排序状态
- 排序是TreeSet最大特点
- 自然排序
- 定制排序
自然排序
- 自然排序是TreeSet集合的默认排序规则
- 实现自然排序:
- 此类必须实现Comparable接口并重写compareTo()方法
- compareTo方法:obj1==obj2返回0,obj1>obj2返回整数,obj1
class B implements Comparable<B>{ private int count; public B(){} public B(int count){this.count = count;} public void setCount(int count){ this.count = count; } public int getCount(){ return this.count; } public String toString(){ return "B [count=" + count + "]"; } //重写Comparable接口的compareTo方法 @Override public int compareTo(B o) { //return o.getCount() > this.getCount() ? -1: (o.getCount() == this.getCount() ? 0:1); return Integer.compare(this.getCount(), o.getCount()); } } public class TreeSetUse { public static void main(String[] args) { Set<B> sets = new TreeSet<>(); sets.add(new B(60)); sets.add(new B(31)); sets.add(new B(27)); sets.add(new B(18)); sets.add(new B(59)); for (B set : sets) { System.out.print(set+" "); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
TreeSet自然排序:
- 默认按照升序排序
- 字符串也可以参与排序,比较时将会对首字母的Unicode码进行比较,如果首字母相同则继续向后
- 引用数据类型无法利用TreeSet默认规则排序,强行注入会报错
拓展Comparable接口实现类
我们以Integer为例:
//以下为Integer底层源码 //在Integer类中实现了Comparable接口 public final class Integer extends Number implements Comparable<Integer> //Integer类重写compareTo()方法 public int compareTo(Integer anotherInteger) { return compare(this.value, anotherInteger.value); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以发现,Integer等基本数据类型的包装类都实现了Comparable接口,故而也可以对于这些引用数据类型的数组进行排序,如下String数组为例
public static void main(String[] args) { String[] strings = new String[]{"B","E","C","A","D"}; Arrays.sort(strings); for (String string : strings) { System.out.print(string+" "); } //通过查询底层源码发现String类实现了Comparable接口,对于String数组的数据进行强制排序 //并且其他的基本数据类型包装类均实现了Comparable接口 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
定制排序
- 引用数据类型利用TreeSet默认排序会报错,故而需要我们自定义排序规则
- 定制方式一:直接为对象的的类实现比较器Comparable接口,重写比较方法
- 定制方式二:直接为集合设置比较器comparator对象,重写比较方法
public class Student implements Comparable<Student>{ private String name; private int age; private double score; @Override public int compareTo(Student o) { //重写比较方法,按照年龄升序排序 /*if(o1>o2){ return 1; }else if(o1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
-
相关阅读:
【uni-app系列】uni-app之App打包
基于HTML美食餐饮文化项目的设计与实现 HTML+CSS上海美食介绍网页(8页) 大学生美食文化网站制作 简单餐饮文化网页设计成品
应用程序主题生成很简单!界面控件DevExtreme有现成的主题生成器
基于SpringBoot的校园点餐系统
数据结构——带头双向循环链表
spring cloud gateway整合security实现统一权鉴
Tomcat IP白名单/黑名单配置
集合划分,将集合S划分成k个子集合,每个子集合互不相交且不为空集,所有子集合加在一起是S
lua基础之package
使用Visual Studio调试 .NET源代码
- 原文地址:https://blog.csdn.net/yuqu1028/article/details/126620067
