-
06-nginx缓存集成
一、Nginx缓存
1. 缓存的概念
缓存就是数据交换的
缓冲区(称作:Cache),当用户要获取数据的时候,会先从缓存中去查询获取数据,如果缓存中有就会直接返回给用户,如果缓存中没有,则会发请求从服务器重新查询数据,将数据返回给用户的同时将数据放入缓存,下次用户就会直接从缓存中获取数据。

缓存其实在很多场景中都有用到,比如场景 作用 操作系统磁盘缓存 减少磁盘机械操作 数据库缓存 减少文件系统的IO操作 应用程序缓存 减少对数据库的查询 Web服务器缓存 减少对应用服务器请求次数 浏览器缓存 减少与后台的交互次数 缓存的优点
- 减少数据传输,节省网络流量,加快响应速度,提升用户体验;
- 减轻服务器压力;
- 提供服务端的高可用性;
缓存的缺点
- 数据的不一致:缓存来不及更新
- 增加成本:需要单独的服务器

本节讲解的是Nginx作为web服务器,Nginx作为Web缓存服务器,它介于客户端和应用服务器之间,当用户通过浏览器访问一个URL时,web缓存服务器会去应用服务器获取要展示给用户的内容,将内容缓存到自己的服务器上,当下一次请求到来时,如果访问的是同一个URL,web缓存服务器就会直接将之前缓存的内容返回给客户端,而不是向应用服务器再次发送请求。web缓存降低了应用服务器、数据库的负载,减少了网络延迟,提高了用户访问的响应速度,增强了用户的体验。
2. Nginx的web缓存服务
Nginx是从0.7.48版开始提供缓存功能。Nginx是基于
Proxy Store来实现的,其原理是把URL及相关组合当做Key,在使用MD5算法对Key进行哈希,得到硬盘上对应的哈希目录路径,从而将缓存内容保存在该目录中。它可以支持任意URL连接,同时也支持404/301/302这样的非200状态码。Nginx既支持对指定URL或者状态码设置过期时间,也支持使用purge命令来手动清除指定URL的缓存。

3. Nginx的缓存设置的相关指令
Nginx的web缓存服务主要是使用ngx_http_proxy_module模块相关指令集来完成,接下来我们把常用的指令来进行介绍下。
1 proxy_cache_path
该指令用于设置缓存文件的存放路径
语法 proxy_cache_path path [levels=number]
keys_zone=zone_name:zone_size [inactive=time][max_size=size];默认值 — 位置 http -
path缓存路径地址,如:/usr/local/proxy_cache- 1
-
levels指定该缓存空间对应的目录,最多可以设置3层,每层取值为1|2如:levels=1:2 缓存空间有两层目录,第一层是1个字母,第二层是2个字母 举例说明: lssznnlmyznnlss 通过MD5加密以后的值为 320e33649c48591a levels=1:2 最终的存储路径为/usr/local/proxy_cache/a/91 levels=2:1:2 最终的存储路径为/usr/local/proxy_cache/1a/9/85 levels=2:2:2 最终的存储路径为??/usr/local/proxy_cache/1a/59/48- 1
- 2
- 3
- 4
- 5
- 6

-
keys_zone用来为这个缓存区设置名称和指定大小,如:keys_zone=lss:200m 缓存区的名称是lss 大小为200m- 1
-
inactive指定缓存的数据多长时间没有被访问将删除,如:inactive=1d 缓存数据在1天内没有被访问就会被删除- 1
-
max_size设置最大缓存空间,如果缓存空间存满,默认会覆盖缓存时间最长的资源,如:max_size=20g- 1
-
配置实例
proxy_cache_path /usr/local/proxy_cache keys_zone=lss:200m levels=1:2:1 inactive=1d max_size=20g- 1
2 proxy_cache
该指令用来开启或关闭代理缓存,如果是开启则指定使用哪个缓存区来进行缓存。
语法 proxy_cache zone_name|off; 默认值 proxy_cache off; 位置 http、server、location zone_name:指定使用缓存区的名称
3 proxy_cache_key
该指令用来设置web缓存的key值,Nginx会根据key值MD5哈希存缓存。
语法 proxy_cache_key key; 默认值 proxy_cache_key $scheme$proxy_host$request_uri; 位置 http、server、location 4 proxy_cache_valid
该指令用来对不同返回状态码的URL设置不同的缓存时间
语法 proxy_cache_valid [code …] time; 默认值 — 位置 http、server、location 如:
proxy_cache_valid 200 302 10m; proxy_cache_valid 404 1m; // 若匹配到,就不会再往后匹配了。 为200和302的响应URL设置10分钟缓存,为404的响应URL设置1分钟缓存 proxy_cache_valid any 1m; 对所有响应状态码的URL都设置1分钟缓存- 1
- 2
- 3
- 4
- 5
5 proxy_cache_min_uses
该指令用来设置资源被访问多少次后被缓存
语法 proxy_cache_min_uses number; 默认值 proxy_cache_min_uses 1; 位置 http、server、location 6 proxy_cache_methods
该指令用户设置缓存哪些HTTP方法
语法 proxy_cache_methods GET|HEAD|POST; 默认值 proxy_cache_methods GET HEAD; 位置 http、server、location 默认缓存HTTP的GET和HEAD方法,不缓存POST方法。
4. Nginx的缓存设置案例
需求分析

步骤实现
1.环境准备
应用服务器的环境准备
(1)在192.168.38.133服务器上的Tomcat的webapps下面添加一个js目录,并在js目录中添加一个jquery.js文件
(2)启动Tomcat
(3)访问测试http://192.168.38.133:8080/js/jquery.js- 1

2.Nginx的环境准备
(1) 完成Nginx反向代理配置。在192.168.38.131上面http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; upstream tomcatbackend { server 192.168.38.133:8080; } server { listen 8080; server_name localhost; location / { proxy_pass http://tomcatbackend/js/; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21


(2) 完成Nginx缓存配置
http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; proxy_cache_path /usr/local/proxy_cache levels=2:1 keys_zone=lss:200m inactive=1d max_size=20g; upstream tomcatbackend { server 192.168.38.133:8080; } server { listen 8080; server_name localhost; location / { proxy_cache lss; proxy_cache_key lzz; # 缓存的key proxy_cache_valid 200 5d; proxy_cache_valid 404 30s; #匹配到 下面的any就没生效 proxy_cache_valid any 1m; #匹配不到 走这个 # $upstream_cache_status 值为MIS没用缓存 HIT使用缓存 add_header nginx-cache "$upstream_cache_status"; proxy_pass http://tomcatbackend/js/; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
如何查看是否使用了缓存
【方式一】:在响应头添加$upstream_cache_status

第一次访问可以并没有走缓存

第二次以后,就会走缓存

【方式二】
proxy_cache_path中设置的缓存路径
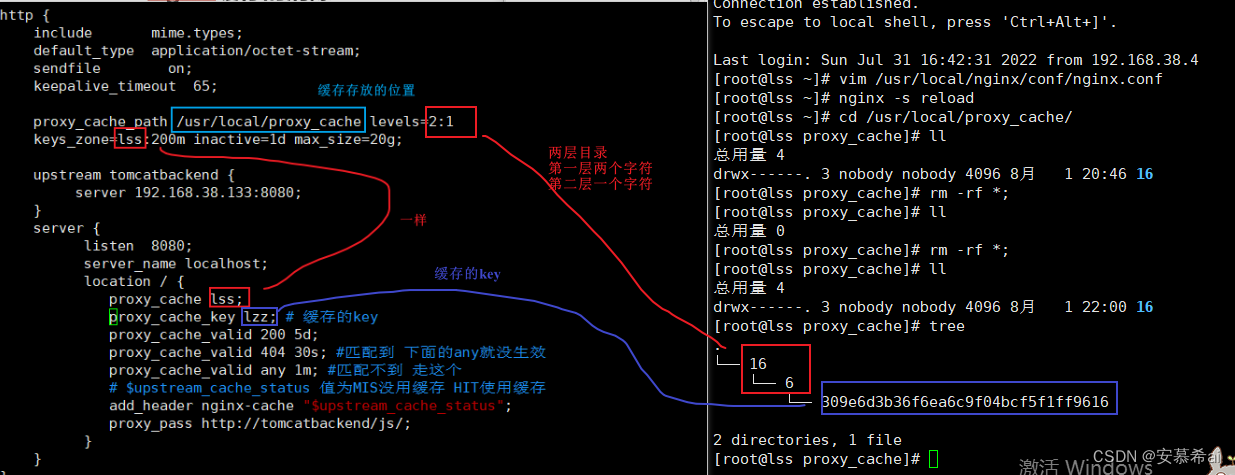
在浏览器访问一个不存在的文件如:http://192.168.38.131:8080/jquery.jsp,会发现报404的问题,然后在访问存在的文件:http://192.168.38.131:8080/jquery.js30s内还是报404。第一步删除proxy_cache_path配置的路径/usr/local/proxy_cache下的所有缓存。

原因是在proxy_cache_key中配置的是静态的缓存key:lzz,方法该location下的所有资源缓存的key都是lzz,所以访问http://192.168.38.131:8080/jquery.jsp时,会将404页面缓存起来,缓存的时间是30s,在30s之内,发起请求一直响应的都是缓存中的404页面。30s之后缓存失效,再次访问http://192.168.38.131:8080/jquery.js即可访问的到。下图是30s之后访问的页面:

上面有一个问题就是,访问所有的资源共用一个缓存key,这样就会造成如:我该目录下有两个资源路径:http://192.168.38.131:8080/jquery.js和 http://192.168.38.131:8080/lss.html,第一次访问的是哪个路径,就会被缓存起来,由于该location块中的缓存key是同一个,所以访问任何路径,返回的资源都是第一次访问的路径对应的资源。解决这个问题的方式是:为每一个资源路径都生成一个唯一的缓存key。

所以我们使用默认值,即可给每个资源路径生成一个缓存key,这样就不会再有问题了。
首先清除缓存
作如下配置,可配可不配,因为默认就是的。

通过浏览器查看效果

4. Nginx的缓存清除
方式一:删除对应的缓存目录
就是上面使用过的。示例:
rm -rf /usr/local/proxy_cache/......- 1
方式二:使用第三方扩展模块ngx_cache_purge
-
下载ngx_cache_purge模块对应的资源包,并上传到服务器上且对资源进行解压缩。

-
修改文件夹名称,方便后期配置

-
查询Nginx的配置参数
nginx -V-with-stream --with-http_gzip_static_module --with-http_ssl_module --add-module=/opt/module/fair- 1
-
进入Nginx的安装目录,使用./configure进行参数配置

-
使用make进行编译
make- 1
-
将nginx安装目录的nginx二级制可执行文件备份
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginxold- 1
-
将编译后的objs中的nginx拷贝到nginx的sbin目录下
cp objs/nginx /usr/local/nginx/sbin- 1
-
使用make进行升级
make upgrade- 1
添加完模块之后使用
nginx -s reload重新加载若不生效,则重启一下nginx。
测试能否清除
nginx.conf的配置文件如下:

执行
http://192.168.38.131:8080/purge/lzz后面是缓存空间的key,可以看到能够正确的清除缓存。

上面使用的缓存key是固定写死的lzz。
将缓存key改成默认的,也即请求的URL,如下

可以看到响应头中的
nginx-cache:HIT,说明命中,走的缓存。

按照固定的缓存key的方式执行
http://192.168.38.131:8080/purge/jquery.js,查看能否清空缓存,访问结果如下:直接报了404

原因是因为路径不一致造成的。nginx配置文件做如下配置:

在浏览器查看访问的路径:http://192.168.38.131:8080/jquery.js与清除缓存的路径http://192.168.38.131:8080/purge/jquery.js两者在日志中的打印结果

5. Nginx设置资源不缓存
前面咱们已经完成了Nginx作为web缓存服务器的使用。但是我们得思考一个问题就是不是所有的数据都适合进行缓存。比如说对于一些经常发生变化的数据。如果进行缓存的话,就很容易出现用户访问到的数据不是服务器真实的数据。所以对于这些资源我们在缓存的过程中就需要进行过滤,不进行缓存。
Nginx也提供了这块的功能设置,需要使用到如下两个指令1. proxy_no_cache
该指令是用来定义不将数据进行缓存的条件。
语法 proxy_no_cache string …; 默认值 — 位置 http、server、location 配置实例 proxy_no_cache $cookie_nocache $arg_nocache $arg_comment;- 1
2. proxy_cache_bypass
该指令是用来设置不从缓存中获取数据的条件。
语法 proxy_cache_bypass string …; 默认值 — 位置 http、server、location 配置实例
proxy_cache_bypass $cookie_nocache $arg_nocache $arg_comment;- 1
上述两个指令都有一个指定的条件,这个条件可以是多个,并且多个条件中
至少有一个不为空且不等于"0",则条件满足成立。上面给的配置实例是从官方网站获取的,里面使用到了三个变量,分别是$cookie_nocache、$arg_nocache、 $arg_comment。$cookie_nocache、$arg_nocache、$arg_comment
这三个参数分别代表的含义是:$cookie_nocache 指的是当前请求的cookie中键的名称为nocache对应的值。 $arg_nocache和$arg_comment 指的是当前请求的参数中属性名为nocache和comment对应的属性值。- 1
- 2
- 3
- 4
- nginx配置文件如下

- 没有添加
cookie、nocache、comment值时打印的日志如下:

- 配置了cookie中
nocache的值如下:

- 浏览器访问结果如下:

4. 案例实现
nginx做如下配置:

- 清除
/usr/local/proxy_cache下的已有缓存,然后访问http://192.168.38.131:8080/purge/jquery.js?nocache=520查看/usr/local/proxy_cache中是否有内容且查看响应头中的nginx_cache=MISS,如果/usr/local/proxy_cache没有缓存且nginx_cache的值是MISS说明没有缓存,则设置成功。

- 修改上面的案例
可以看到访问http://192.168.38.131:8080/jquery.js是不会进行缓存,而访问http://192.168.38.131:8080/lss.html时会进行缓存。

proxy_no_cache与proxy_cache_bypass的区别:
前者根本不缓存,而后者进行了缓存,却不会使用缓存,每次都是请求的服务器。
二、Nginx与Tomcat部署
前面课程已经将Nginx的大部分内容进行了讲解,我们都知道了Nginx在高并发场景和处理静态资源是非常高性能的,但是在实际项目中除了静态资源还有就是后台业务代码模块,一般后台业务都会被部署在Tomcat,weblogic或者是websphere等web服务器上。那么如何使用Nginx接收用户的请求并把请求转发到后台web服务器?

步骤分析:1.准备在192.168.38.133上安装Tomcat环境,并在Tomcat上部署一个web项目 2.准备在192.168.38.131Nginx环境,使用Nginx接收请求,并把请求分发到Tomat上- 1
- 2
-
在本地
idea中打一个war包,其中注意打包两点1。- 指定达成war包

- 这里指定打车的
war包的名称。

- 如果是
springboot项目,则排除内嵌的tomcat。然后引入javax.servlet-api的依赖。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <!-- 移除嵌入式tomcat插件 --> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-tomcat</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <scope>provided</scope> </dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

4. 启动类继承SpringBootServletInitializer。

- 指定达成war包
-
执行顺序执行如下操作,即可在target目录下找到打的
war包
-
将打好的
war包上传到192.168.38.133上面的Tomcat的webapps目录下

-
在tomcat下的bin目录下执行
./startup.sh启动Tomcat。

-
通过浏览器访问
http://192.168.38.133:8080/lss-znn/login,是否部署成功。

-
通过
192.168.38.131上面的nginx做代理来访问上述的资源(上面的资源部署在192.168.38.133上面的Tomcat中)

(1)使用Nginx的反向代理,将请求转给Tomcat进行处理。upstream webservice{ server 192.168.38.133:8080; } server { listen 80; server_name localhost; location /lss-znn{ proxy_pass http://webservice; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

(2)通过浏览器访问192.168.38.131:/lss-znn/login就会将请求代理到192.168.38.133上面的Tomcat。

(3)输入账号lss密码123即可登录成功。
学习到这,可能大家会有一个困惑,明明直接通过tomcat就能访问,为什么还需要多加一个nginx,这样不是反而是系统的复杂度变高了么?
那接下来我们从两个方便给大家分析下这个问题,
第一个使用Nginx实现动静分离
第二个使用Nginx搭建Tomcat的集群
1、nginx实现动静分离
1.1 什么是动静分离
动:后台应用程序的业务处理(如上面的登录接口)
静:网站的静态资源(html,javaScript,css,images等文件)
分离:将两者进行分开部署访问,提供用户进行访问。举例说明就是以后所有和静态资源相关的内容都交给Nginx来部署访问,非静态内容则交个类似于Tomcat的服务器来部署访问。1.2 为什么要动静分离
前面我们介绍过Nginx在处理静态资源的时候,效率是非常高的,而且Nginx的并发访问量也是名列前茅,而Tomcat则相对比较弱一些,所以把静态资源交个Nginx后,可以减轻Tomcat服务器的访问压力并提高静态资源的访问速度。动静分离以后,降低了动态资源和静态资源的耦合度。如动态资源宕机了也不影响静态资源的展示。
1.3 如何实现动静分离
实现动静分离的方式很多,比如静态资源可以部署到CDN、Nginx等服务器上,动态资源可以部署到Tomcat,weblogic或者websphere上。本次课程只要使用Nginx+Tomcat来实现动静分离。
需求分析

-
将
lss-znn.war项目中的静态资源都删除掉,重新打包成一个war包 -
将重写打好的包部署到Tomcat
-
在nginx所在服务器创建如下目录,并将对应的静态资源放入指定的位置。


假如某个时间点,由于某个原因导致Tomcat后的服务器宕机了,我们再次访问Nginx,还会得到如上效果,用户还是能看到页面,只是不能再进行登录了,这就是前后端耦合度降低的效果,并且整个请求只和后的服务器交互了一次,js和images都直接从Nginx返回,提供了效率,降低了后的服务器的压力。
三、Nginx实现Tomcat集群搭建
在使用Nginx和Tomcat部署项目的时候,我们使用的是一台Nginx服务器和一台Tomcat服务器。那么问题来了,如果Tomcat的真的宕机了,整个系统就会不完整,所以如何解决上述问题,一台服务器容易宕机,那就多搭建几台Tomcat服务器,这样的话就提升了后的服务器的可用性。这也就是我们常说的集群,搭建Tomcat的集群需要用到了Nginx的反向代理和负载均衡的知识,具体如何来实现?我们先来分析下原理

-
编写如下类,该接口的作用,主要是用来获得所在Tomcat的端口号。将其打成一个
war包,放在192.168.38.131上面的第一台服务器上。@Controller public class DemoController { @GetMapping("/getAddress") @ResponseBody public String getAddress(){ MBeanServer beanServer = ManagementFactory.getPlatformMBeanServer(); try { QueryExp protocol = Query.match(Query.attr("protocol"), Query.value("HTTP/1.1")); ObjectName name = new ObjectName("*:type=Connector,*"); Set<ObjectName> objectNames = beanServer.queryNames(name, protocol); for (ObjectName objectName : objectNames) { String catalina = objectName.getDomain(); if ("Catalina".equals(catalina)) { return "所在Tomcat的端口号为" +objectName.getKeyProperty("port"); } } } catch (MalformedObjectNameException e) { e.printStackTrace(); } return null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
-
在
/opt/static/web下面放一个index.html内容如下:


其中上面ajax请求中的ip是nginx所在机器的ip,然后代理到192.168.38.133上面,上面不能直接写成192.1683.8.133的ip会出现跨域现象。或者不写ip端口了直接写成demo/getAddress也可以。 -
nginx做如下配置

-
通过浏览器访问,查看是否配置成功。

-
在
192.168.38.133上面在创建两台服务器,步骤如下: -
找到原来的Tomcat安装包改名为
tomcat1,然后拷贝两份,分别为tomcat2和Tomcat3。

-
由于三个Tomcat的端口都是一样的,所以我们需要更改端口。(生产环境下,三台Tomcat肯定分别位于三台不同的服务器,由于学习没有那么多服务器,所以就更改端口了)
-
vim tomcat2/conf/server.xml更改下面两个位置。tomcat3做相同的配置即可,这里不再给出。

-
tomcat3的更改如下:

-
分别启动tomcat2和tomcat3
-
更改nginx配置如下:

-
浏览器访问效果:

好了,完成了上述环境的部署,我们已经解决了Tomcat的高可用性,一台服务器宕机,还有其他两条对外提供服务,同时也可以实现后台服务器的不间断更新。但是新问题出现了,上述环境中,如果是Nginx宕机了呢,那么整套系统都将服务对外提供服务了,这个如何解决?
四、Nginx高可用解决方案
针对于上面提到的问题,我们来分析下要想解决上述问题,需要面临哪些问题?

需要两台以上的Nginx服务器对外提供服务,这样的话就可以解决其中一台宕机了,另外一台还能对外提供服务,但是如果是两台Nginx服务器的话,会有两个IP地址,用户该访问哪台服务器,用户怎么知道哪台是好的,哪台是宕机了的?
1、Keepalived
使用Keepalived来解决,Keepalived 软件由 C 编写的,最初是专为 LVS 负载均衡软件设计的,Keepalived 软件主要是通过 VRRP 协议实现高可用功能。

VRRP(Virtual Route Redundancy Protocol)协议,翻译过来为虚拟路由冗余协议。VRRP协议将两台或多台路由器设备虚拟成一个设备,对外提供虚拟路由器IP,而在路由器组内部,如果实际拥有这个对外IP的路由器如果工作正常的话就是MASTER,MASTER实现针对虚拟路由器IP的各种网络功能。其他设备不拥有该虚拟IP,状态为BACKUP,除了接收MASTER的VRRP状态通告信息以外,不执行对外的网络功能。
当主机失效时,BACKUP将接管原先MASTER的网络功能。从上面的介绍信息获取到的内容就是VRRP是一种协议,那这个协议是用来干什么的?
1. 选择协议VRRP可以把一个虚拟路由器的责任动态分配到局域网上的 VRRP 路由器中的一台。其中的虚拟路由即Virtual路由,是VRRP路由群组创建的一个不真实存在的路由,这个虚拟路由也是有对应的IP地址。而且VRRP路由1和VRRP路由2之间会有竞争选择,通过选择会产生一个Master路由和一个Backup路由。
2. 路由容错协议Master路由和Backup路由之间会有一个心跳检测,Master会定时告知Backup自己的状态,如果在指定的时间内,Backup没有接收到这个通知内容,Backup就会替代Master成为新的Master。Master路由有一个特权就是虚拟路由和后端服务器都是通过Master进行数据传递交互的,而备份节点则会直接丢弃这些请求和数据,不做处理,只是去监听Master的状态。用了keepalived后,解决方案如下:

环境准备
VIP IP 主机名 主/从 192.168.38.131 keepalived1 Master 192.168.38.110 192.168.38.133 keepalived2 Backup keepalived的安装
在192.168.38.131和192.168.38.133上面分别安装keepalived。其中192.168.38.133上有一台nginx。192.168.38.133上面有一台nginx、三台tomcat。并启动nginx和tomcat。步骤1:从官方网站下载keepalived,官网地址https://keepalived.org/ 步骤2:将下载的资源上传到服务器 keepalived-2.2.7.tar.gz 步骤3:创建keepalived目录,方便管理资源 mkdir keepalived 步骤4:将压缩文件进行解压缩,解压缩到指定的目录 tar -zxf keepalived-2.2.7.tar.gz -C keepalived/ 步骤5:对keepalived进行配置,编译和安装 cd keepalived/keepalived-2.2.7 ./configure --sysconf=/etc --prefix=/usr/local make && make install- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
安装完成后,有两个文件需要我们认识下,一个是
/etc/keepalived/keepalived.conf(keepalived的系统配置文件,我们主要操作的就是该文件),一个是/usr/local/sbin目录下的keepalived,是系统配置脚本,用来启动和关闭keepalivedKeepalived配置文件介绍
打开keepalived.conf配置文件。若在
/etc/keepalived/下不存在keepalived.conf配置文件,会发现/etc/keepalived目录下存在一个叫做keepalived.conf.sample的文件,复制一份,并重命名为keepalived.conf即可。cp /etc/keepalived/keepalived.conf.sample keepalived.conf- 1

这里面会分三部,第一部分是global全局配置、第二部分是vrrp相关配置、第三部分是LVS相关配置。
本次课程主要是使用keepalived实现高可用部署,没有用到LVS,所以我们重点关注的是前两部分global全局部分: global_defs { #通知邮件,当keepalived发送切换时需要发email给具体的邮箱地址 notification_email { tom@itcast.cn jerry@itcast.cn } #设置发件人的邮箱信息 notification_email_from zhaomin@itcast.cn #指定smpt服务地址 smtp_server 192.168.200.1 #指定smpt服务连接超时时间 smtp_connect_timeout 30 #运行keepalived服务器的一个标识,可以用作发送邮件的主题信息 router_id LVS_DEVEL #默认是不跳过检查。检查收到的VRRP通告中的所有地址可能会比较耗时,设置此命令的意思是,如果通告与接收的上一个通告来自相同的master路由器,则不执行检查(跳过检查) vrrp_skip_check_adv_addr #严格遵守VRRP协议。 vrrp_strict #在一个接口发送的两个免费ARP之间的延迟。可以精确到毫秒级。默认是0 vrrp_garp_interval 0 #在一个网卡上每组na消息之间的延迟时间,默认为0 vrrp_gna_interval 0 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
VRRP部分,该部分可以包含以下四个子模块 1. vrrp_script 2. vrrp_sync_group 3. garp_group 4. vrrp_instance 我们会用到第一个和第四个, #设置keepalived实例的相关信息,VI_1为VRRP实例名称 vrrp_instance VI_1 { state MASTER #有两个值可选MASTER主 BACKUP备 interface ens33 #vrrp实例绑定的接口,用于发送VRRP包[当前服务器使用的网卡名称] virtual_router_id 51#指定VRRP实例ID,范围是0-255 priority 100 #指定优先级,优先级高的将成为MASTER, 并不是state后面配的是master他就是master advert_int 1 #指定发送VRRP通告的间隔,单位是秒 authentication { #vrrp之间通信的认证信息 auth_type PASS #指定认证方式。PASS简单密码认证(推荐) auth_pass 1111 #指定认证使用的密码,最多8位 } virtual_ipaddress { #虚拟IP地址设置虚拟IP地址,供用户访问使用,可设置多个,一行一个 192.168.38.110 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
192.168.38.131 master配置内容如下:

global_defs { notification_email { 1270295098@qq.com } notification_email_from 1270295098@qq.com smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id keepalived1 vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.38.110 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
192.168.38.1313 backup配置内容如下:

global_defs { notification_email { 1270295098@qq.com } notification_email_from 1270295098@qq.com smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id keepalived2 vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.38.110 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
访问测试
-
启动keepalived之前,咱们先使用命令
ip a,查看192.168.38.131和192.168.38.133这两台服务器的IP情况。【master】

【backup】

-
分别启动两台服务器的keepalived
cd /usr/local/sbin- 1
【192.168.38.131】master启动之后,可以看到虚拟的ip
192.168.38.110

【192.168.38.133】backup的keepalived启动之后,看不到虚拟的ip
192.168.38.110

-
关闭
192.168.38.131(master)上面的keepalived,再次通过ip a查看,发现虚拟ip192.168.38.110跑到了192.168.38.133(backup)上面了。

通过上述的测试,我们会发现,虚拟IP(VIP)会在MASTER节点上,当MASTER节点上的keepalived出问题以后,因为BACKUP无法收到MASTER发出的VRRP状态信息,就会直接升为MASTER。VIP也会"漂移"到新的MASTER。 -
再次打开
192.168.38.131(master)上面的keepalived,再次通过ip a查看,发现虚拟ip192.168.38.100又回到了192.168.38.131(master)上了。此时192.168.38.133(backup)上面的keepalived并没有关闭。而是192.168.38.131(master)上面的keepalived.conf配置文件中的priority(100)比192.168.38.133(backup)的priority(90)高,所以优先级高的当做master。并不是keepalived.conf中的state配置为master`就是master

我们把192.168.38.131服务器的keepalived再次启动下,由于它的优先级高于服务器192.168.38.133,所以它会再次成为MASTER,VIP也会"漂移"过去

-
再次回到192.168.38.133上面,可以看到已经没有虚拟ip192.168.38.110

-
192.168.38.131上面的nginx配置如下,又因为虚拟ip192.168.38.110在192.168.38.131主机上面,所以当我们通过虚拟ip访问192.168.38.110:80时,其实就是在访问192.168.38.131真实ip上的80端口,由nginx的配置可以看出,会将请求分发到192.168.38.133上面的tomcat上。
静态资源访问的是/opt/static/web下的index.html其内容如下:

浏览器访问
192.168.38.110发现访问的192.168.38.131上面的nginx。虽然项目的getAddress跨域了,但是可以发现访问的是192.168.38.131

将192.168.38.131上面的keepalived关机,根据前面的结论,虚拟ip就会飘到192.168.38.133上面。可以看到访问到的内容是192.168.38.133上面的nginx。

效果实现了以后, 我们会发现要想让vip进行切换,就必须要把服务器上的keepalived进行关闭,而什么时候关闭keepalived呢?应该是在keepalived所在服务器的nginx出现问题后,把keepalived关闭掉,就可以让VIP执行另外一台服务器,但是现在这所有的操作都是通过手动来完成的,我们如何能让系统自动判断当前服务器的nginx是否正确启动,如果没有,要能让VIP自动进行"漂移",这个问题该如何解决?2、keepalived之vrrp_script
keepalived只能做到对网络故障和keepalived本身的监控,即当出现网络故障或者keepalived本身出现问题时,进行切换。但是这些还不够,我们还需要监控keepalived所在服务器上的其他业务,比如Nginx,如果Nginx出现异常了,仅仅keepalived保持正常,是无法完成系统的正常工作的,因此需要根据业务进程的运行状态决定是否需要进行主备切换,这个时候,我们可以通过编写脚本对业务进程进行检测监控。
实现步骤-
在keepalived配置文件中添加对应的配置项
vrrp_script 脚本名称 { script "脚本位置" interval 3 #执行时间间隔 weight -20 #动态调整vrrp_instance的优先级 }- 1
- 2
- 3
- 4
- 5
- 6
-
编写脚本ck_nginx.sh
#!/bin/bash num=`ps -C nginx --no-header | wc -l` # 查询到的nginx进程数目给num if [ $num -eq 0 ];then # 如果num的值与0-相等 /usr/local/nginx/sbin/nginx # 启动nginx sleep 2 # 睡两秒 if [ `ps -C nginx --no-header | wc -l` -eq 0 ]; then killall keepalived # 如果nginx的进程数还为0 关闭keepalived fi fi- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Linux ps命令用于显示当前进程 (process) 的状态。
-C(command) :指定命令的所有进程
–no-header 排除标题其中
ps -C nginx结果如下:

ps -C nginx --no-header结果如下:

ps -C nginx --no-header | wc -l结果如下:

-
创建脚本内容如下,和上面介绍的不同

-
keepalived.conf配置文件的修改如下

上面的脚本和keepalived配置文件的修改都是在192.168.38.131(master)上改的 -
启动192.168.38.131(master)看到虚拟主机在其上。

-
关闭192.168.38.131(master)上的nginx,模拟nginx软件宕机,查看虚拟ip就会在192.168.38.133(backup)上。因为keepalived会每隔2s执行脚本内容,脚本内容的if判满足nginx的数目为0,所以进入if块,关闭keepalived。虚拟ip就会漂移到backup这台机器了。


7.重启192.168.38.131上的nginx和keepalived,就会发现虚拟ip又回到了192.168.28.131上面,因为它的优先级(在keepalived.conf中配置)比192.168.38.133中配置的优先级高,所以虚拟ip会在192.168.38.131上面。

问题思考:
通常如果master服务死掉后backup会变成master,但是当master服务又好了的时候 master此时会抢占VIP,这样就会发生两次切换对业务繁忙的网站来说是不好的。所以我们要在配置文件加入 nopreempt 非抢占,但是这个参数只能用于state 为backup,故我们在用HA的时候最好master 和backup的state都设置成backup 让其通过priority来竞争。
五、Nginx制作下载站点
首先我们先要清楚什么是下载站点?
我们先来看一个网站http://nginx.org/download/这个我们刚开始学习Nginx的时候给大家看过这样的网站,该网站主要就是用来提供用户来下载相关资源的网站,就叫做下载网站。

如何制作一个下载站点:
nginx使用的是模块ngx_http_autoindex_module来实现的,该模块处理以斜杠(“/”)结尾的请求,并生成目录列表。nginx编译的时候会自动加载该模块,但是该模块默认是关闭的,我们需要使用下来指令来完成对应的配置
1. autoindex
启用或禁用目录列表输出
语法 autoindex on|off; 默认值 autoindex off; 位置 http、server、location 2. autoindex_exact_size
对应HTLM格式,指定是否在目录列表展示文件的详细大小
默认为on,显示出文件的确切大小,单位是bytes。
改为off后,显示出文件的大概大小,单位是kB或者MB或者GB语法 autoindex_exact_size on|off; 默认值 autoindex_exact_size on; 位置 http、server、location 3. autoindex_format
设置目录列表的格式
语法 autoindex_format html|xml|json|jsonp; 默认值 autoindex_format html; 位置 http、server、location 注意:该指令在1.7.9及以后版本中出现
4. autoindex_localtime
对应HTML格式,是否在目录列表上显示时间。
默认为off,显示的文件时间为GMT时间。
改为on后,显示的文件时间为文件的服务器时间语法 autoindex_localtime on | off; 默认值 autoindex_localtime off; 位置 http、server、location 5. 示例
- 在
192.168.38.133上面的/opt/download文件加下有redis、nginx、tomcat三个文件。

- nginx做如下配置:

- autoindex_exact_size:
- autoindex_format:设置目录列表的格式为xml

- autoindex_localtime:对应HTML格式,是否在目录列表上显示时间。

六、Nginx的用户认证模块
对应系统资源的访问,我们往往需要限制谁能访问,谁不能访问。这块就是我们通常所说的认证部分,认证需要做的就是根据用户输入的用户名和密码来判定用户是否为合法用户,如果是则放行访问,如果不是则拒绝访问。
Nginx对应用户认证这块是通过
ngx_http_auth_basic_module模块来实现的,它允许通过使用"HTTP基本身份验证"协议验证用户名和密码来限制对资源的访问。默认情况下nginx是已经安装了该模块,如果不需要则使用--without-http_auth_basic_module。该模块的指令比较简单,
1.auth_basic
使用“ HTTP基本认证”协议启用用户名和密码的验证
语法 auth_basic string|off; 默认值 auth_basic off; 位置 http,server,location,limit_except 开启后,服务端会返回401,指定的字符串会返回到客户端,给用户以提示信息,但是不同的浏览器对内容的展示不一致。
string:两个功能。功能一:启用该模块。功能二:把字符串发送给前端,给用户一个提示的信息。2.auth_basic_user_file
指定用户名和密码所在文件
语法 auth_basic_user_file file; 默认值 — 位置 http,server,location,limit_except 指定文件路径,该文件中的用户名和密码的设置,密码需要进行加密。

-
Google浏览器访问

-
我们并没有设置用户名和密码?如何添加用户名和密码呢?可以采用自动生成
-
我们需要使用
htpasswd工具生成。执行命令yum install -y httpd-tools

-
有如下命令
htpasswd -c /usr/local/nginx/conf/htpasswd username //创建一个新文件记录用户名和密码 htpasswd -b /usr/local/nginx/conf/htpasswd username password //在指定文件新增一个用户名和密码 htpasswd -D /usr/local/nginx/conf/htpasswd username //从指定文件删除一个用户信息 htpasswd -v /usr/local/nginx/conf/htpasswd username //验证用户名和密码是否正确- 1
- 2
- 3
- 4

且密码是加密的,我们查看htpasswd文件中的内容:


-
通过浏览器输入用户和密码再次访问


上述方式虽然能实现用户名和密码的验证,但是大家也看到了,所有的用户名和密码信息都记录在文件里面,如果用户量过大的话,这种方式就显得有点麻烦了,这时候我们就得通过后台业务代码来进行用户权限的校验了。
-
相关阅读:
『动态规划』矩阵连乘
windows和linux下安装memcached
CCF计算机资格认证模拟题202303-2垦田计划
应急响应:应急响应流程,常见应急事件及处置思路
改变光标形状的多种方式
【Android】MQTT
邯郸百亿斤粮食生产 国稻种芯·中国水稻节:河北大市粮食经
R语言ggplot2可视化:使用ggpubr包的ggbarplot函数可视化柱状图、使用order参数自定义柱状图中水平的顺序
[21天学习挑战赛——内核笔记](九)——sysfs相关API
Redis系列19:LRU内存淘汰算法分析
- 原文地址:https://blog.csdn.net/qq_43788522/article/details/126088621
