-
(项目笔记)opencv人脸识别
Haar级联:
Haar特征:边缘特征,线性特征,中心环绕特征,对角线特征
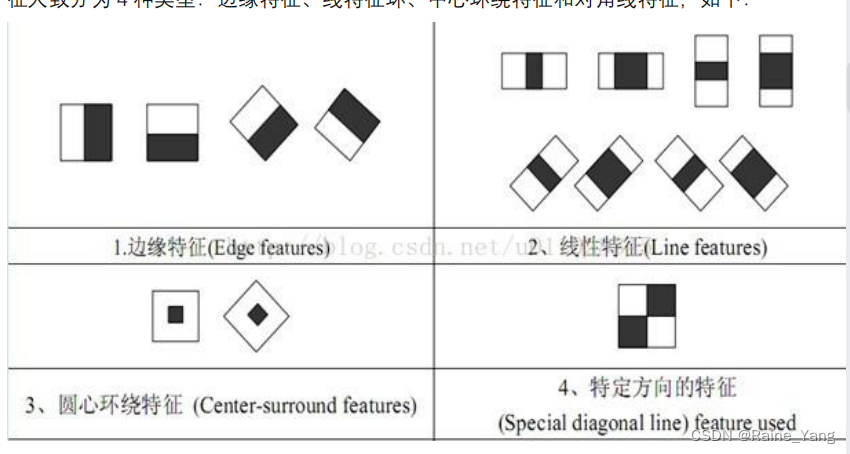
这些特征组合为特征模板,特征模板里有白色和黑色矩形,模板特征即为白色矩形像素和减去黑色矩形像素和。
Haar 特征的提取简单说就是通过不断改变模版的大小、位置和类型,白色矩形区域像素和‘减 去’黑色矩形区域像素和,以得到每种类型模版的大量子特征。
Haar特征提取需要大量重复计算各个像素,因此使用积分图可以很好减少计算量。积分图将图像以线性时间初始化(仅第二次遍历图像时),并可以通过矩形区域 四个角的值,提供像素的总和

在此例中,如要知道ABCD面积,只需要将左上角作为基准,计算以下四部分面积,最后图3 - 图1 - 图2 - 图4即为ABCD面积
Haar 级联是一个基于 Haar 特征的级联分类器,级联分类器把弱分类器转换为强分类器
人脸识别流程:
人脸检测,图像采集:
加载人脸检测器
图像预处理(灰度化,直方图均衡化)
detectMultiscal识别
rectangle函数绘制矩形框
在原图截取人脸图像人脸识别:
样本归一化
加载训练好的分类器
预测输入图像值
判断角色人脸数据采集程序
注:单纯安装opencv-python没有包含人脸识别所使用函数,因为人脸识别函数还属于opencv测试版内容,稳定性还无法保证,因此没有放在常规发行版。要安装opencv-contrib-python
pip install opencv-contrib-python -i https://mirrors.aliyun.com/pypi/simple/
import cv2 import numpy as np import os def generate_img(dirname): face_cascade = cv2.CascadeClassifier('D:\\opencv\\data\\haarcascades\\haarcascade_frontalface_default.xml') if (not os.path.isdir(dirname)): os.makedirs(dirname) cap = cv2.VideoCapture(0) count = 0 while True: ret,frame = cap.read() x,y = frame.shape[0:2] small_frame = cv2.resize(frame, (int(y/2), int(x/2))) result = small_frame.copy() gray = cv2.cvtColor(small_frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray,1.3,5) for (x, y, w, h) in faces: result = cv2.rectangle(result, (x, y), (x + w, y + h), (255, 0, 0), 2) f = cv2.resize(gray[y: y + h, x: x + w], (200, 200)) if count < 20: cv2.imwrite(dirname + '%s.pgm' % str(count), f) print(count) count += 1 cv2.imshow('face', result) if cv2.waitKey(30) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() if __name__ == '__main__': generate_img(".\\photos\\raine")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
说明:
1face_cascade = cv2.CascadeClassifier('D:\\opencv\\data\\haarcascades\\haarcascade_frontalface_default.xml')
引入opencv的人脸检测器。该程序参数路径为标记好的图片的xml文件,关于人脸图片的xml文件可以自己标记创建,也可以直接下载opencv官方库(https://github.com/opencv/opencv/tree/master/data/haarcascades)。这里引入其中一个xml文件路径(我用的是正脸照片文件)。注意windows里路径要使用 \ 而非 \ 。 因为 \ 为转义字符标注,使用 \ 为 \ 的转义字符。2
ret,frame = cap.read() x,y = frame.shape[0:2] small_frame = cv2.resize(frame, (int(y/2), int(x/2))) result = small_frame.copy() gray = cv2.cvtColor(small_frame, cv2.COLOR_BGR2GRAY)- 1
- 2
- 3
- 4
- 5
获取相机照片,缩放图片使长宽缩为一半,复制图片,转换图片为灰度图
3
faces = face_cascade.detectMultiScale(gray,1.3,5)
调用face_cascade对象识别人脸,参数:
1 image表示的是要检测的输入图像
2 objects表示检测到的人脸目标序列
3 scaleFactor表示每次图像尺寸减小的比例
4 minNeighbors表示每一个目标至少要被检测到3次才算是真的目标(因为周围的像素和不同的窗口大小都可以检测到人脸)
5 minSize为目标的最小尺寸
6 minSize为目标的最大尺寸4
for (x, y, w, h) in faces: result = cv2.rectangle(result, (x, y), (x + w, y + h), (255, 0, 0), 2) f = cv2.resize(gray[y: y + h, x: x + w], (200, 200))- 1
- 2
- 3
用矩形框框出人脸。创建图像 f 为截取的人脸部分图片
5
if count < 20: cv2.imwrite(dirname + '%s.pgm' % str(count), f) print(count) count += 1- 1
- 2
- 3
- 4
保存图片,count加一,count为20时停止保存
效果如下:
人脸识别
opencv有三种人脸识别方法:
1 Fisherfaces:PCA 衍生版本,更高级,速度更快
2 Eigenfaces:通过 PCA 处理,计算训练集相对于数据库发散程度,越小则数据库与检测 到人脸差别越小
3 Local Binary Pattern Histogram(LBPH):将人脸分成小单元,与模型对应单元比对,每 个比对区域产生一个直方图人脸数据模型训练及识别
import os import sys import cv2 import numpy as np # search for face photos in the files def read_images(path, sz = None): index = 0 images, indexes = [], [] names = [] # find path for samples for root, dirs, files in os.walk(path): # transverse the path for subdirs in dirs: # get files in the childrens in path subject_path = os.path.join(root, subdirs) for filename in os.listdir(subject_path): # get each photos try: if (filename == ".directory"): continue # find the path for each photo filepath = os.path.join(subject_path, filename) im = cv2.imread(os.path.join(subject_path, filename), cv2.IMREAD_GRAYSCALE) # read face samples # negative samples if (im is None): print("image" + filepath + "is None") # positive samples if (sz is not None): im = cv2.resize(im, sz) images.append(np.asarray(im, dtype = np.uint8)) indexes.append(index) except: print("unexpected error") raise # throw an exception index = index + 1 names.append(subdirs) return [names, images, indexes] # detect and classify face images def face_rec(read_dir): # get face samples [names, x, y] = read_images(read_dir, sz = (200, 200)) y = np.asarray(y, dtype=np.int32) model = cv2.face_EigenFaceRecognizer.create() # create face classifier model model.train(np.asarray(x), np.asarray(y)) # train model # create face detector model face_cascade = cv2.CascadeClassifier('C:/Users/linli/Desktop/faceDetect/haarcascade_frontalface_default.xml') cap = cv2.VideoCapture(0) while True: # get gray image ret, frame = cap.read() x, y = frame.shape[0:2] small_frame = cv2.resize(frame, (int(y / 2), int(x / 2))) result = small_frame.copy() gray = cv2.cvtColor(small_frame, cv2.COLOR_BGR2GRAY) # find face in the video frame faces = face_cascade.detectMultiScale(gray, 1.3, 5) for (x, y, w, h) in faces: # mark the face with a rectangle result = cv2.rectangle(result, (x, y), (x + w, y + h), (255, 0, 0), 2) roi = gray[x:x + w, y:y + h] centerX = int(x + w / 2) centerY = int(y + h / 2) result = cv2.circle(result, (centerX, centerY), 5, (0, 0, 255), -1) try: roi = cv2.resize(roi, (200,200), interpolation=cv2.INTER_LINEAR) [p_label, p_confidence] = model.predict(roi) # predict the face identity print(p_confidence) # showthe prediction in text cv2.putText(result, names[p_label], (x, y - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, 255, 2) except: continue cv2.imshow("recognize_face", result) if cv2.waitKey(30) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() if __name__ == "__main__": face_rec("./photos")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
1 Python里os获取路径基本函数
os.path.join(String*):接受多个字符串为参数,将字符串连接为文件路径,如果出现以 / 开头的参数,路径从最后一个以 / 开头参数开始
os.listdir(path):参数为一个路径,返回该路径下所有文件和文件夹名称
os.walk(path):遍历选定路径文件夹,返回root,dirs,files。其中root为当前文件夹path的绝对路径,dirs为当前文件夹子文件夹,files为当前文件夹下文件2 def read_images(path, sz = None):
该函数搜索文件夹里已有的人脸样本,得到一个路径(names)+图像(images)+序号(indexes)二维列表3
model = cv2.face_EigenFaceRecognizer.create() # create face classifier model model.train(np.asarray(x), np.asarray(y)) # train model- 1
- 2
创建人脸分类对象并利用之前获得的人脸图片训练模型
4
faces = face_cascade.detectMultiScale(gray, 1.3, 5)- 1
调用人脸识别模型,在视频画面中寻找人脸图像
5
roi = cv2.resize(roi, (200,200), interpolation=cv2.INTER_LINEAR)- 1
Eigenfaces算法要求识别目标图像和样本图像大小一致,这里统一设为200*200
6
centerX = int(x + w / 2) centerY = int(y + h / 2) result = cv2.circle(result, (centerX, centerY), 5, (0, 0, 255), -1)- 1
- 2
- 3
找到人脸中心并绘制圆
注:circle函数参数:图像,圆心,半径,颜色,线宽(负数代表填充)
圆心必须为int型7
[p_label, p_confidence] = model.predict(roi)- 1
获取预测结构,包括标签名称和置信区间
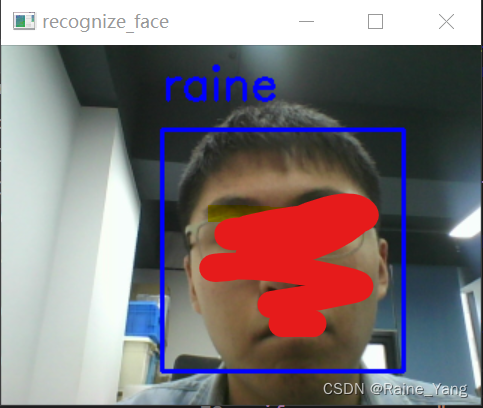
效果如下:
-
相关阅读:
程序媛的mac修炼手册-- 2024如何彻底卸载Python
Nginx反向代理与负载均衡
[C语言]对一段连续内存,多个结构体赋值的一种手段
彻底理解进程
HBR推荐|迎战未来必知的10大管理创新趋势
redis学习-发布订阅
实现游戏后处理6大常用模糊算法
如何使用BERT生成单词嵌入?
90. 子集 II
【Python】环境管理Pipenv
- 原文地址:https://blog.csdn.net/Raine_Yang/article/details/126196873
