-
[C进阶] 数据在内存中的存储——整形篇
前言

学习一门语言就像是了解一个陌生人,首先我们要做的是从外貌和举止来宏观上考察一个人的特点,然后逐渐的对其进行深入了解,最终变得知根知底,畅所欲言。本章我们对数据存储的探讨其实就是在对C语言进行深入了解,因为只有知根知底才能畅所欲言!本章重点:
- 区分并能够灵活转换整数的三种表示方式:原码、反码、补码
- 理解整数在储存时的大小端模式。
- 学会区分和界定有符号数与无符号数的取值范围。
一、类型的基本归类
在C语言中我们将类型大体分为5类,即整形、浮点型、构造类型、指针类型、空类型。
(1)整形家族:
类型 关键字 分类 字符类型 char signed char
unsigned char短整型 short signed short
unsigned short整形 int signed int
unsigned int长整型 long signed long
unsigned long更长的整形 long long signed long long
unsigned lonf long补充:除 char类型外。当short、int、long、long单独使用时系统默认为signed类型。char类型单独使用是否表示signed char与编译器有关。例如VS下char=signed char
问题1:为什么
char类型归属整形家族?char类型在内存中存储数据时,本质上存储的是数据的
ASCII码值,而ASCII码值又作为整数存在,所以也将char类型归属为整形家族。问题2:为什么一种类型存在
unsigned和signed?1、unsigned表示无符号、signed表示有符号。二者的区别在于能不能表示负数,有符号可以表示负整数,无符号则不行,只能表示非负整数。
2、另外,表示的数值范围不同。从二进位制的角度上说,有符号int就是以最高位为符号位(计算机二进位制是没有正负号的,只有0和1,因此最高位为0表示正整数或0,最高位为1表示负整数),使用补码的形式储存负数,而无符号int不用考虑符号的问题,它的二进位制最高位仍是有效数位而不是符号位。(2)浮点型家族:
类型 关键字 单精度浮点型 float 双精度浮点型 double (3)构造类型:(自定义类型)
类型 关键字 数组类型 类型+数组名+[大小] 结构体类型 struct 枚举类型 enum 联合类型 union (4)指针类型:
类型 关键字 整形指针 int *pi 字符指针 char *pi 浮点型指针 float *pi 空指针 void *pi … … 注意: void*pv用于临时存放其他类型的地址,但是由于void没有具体类型,所以不能对其进行
pv++,*pv等相关指针操作(5)空类型:
类型 关键字 空类型 void void通常应用于函数的返回类型、函数的参数、指针类型二、类型存在的意义
- 不同的类型通常在内存中开辟不同的空间,丰富的类型增加了我们的选择性,同时在一定程度上避免了空间的浪费。
- 不同的类型决定我们看待内存空间的视角。比如int类型数据表示内存空间存放的是整数,float表示存放的是小数……
三、整形的存储
我们之前讲过一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。那接下来我们谈谈数据在所开辟内存中到底是如何存储的?
🍑3.1 原码、反码、补码
计算机中整数是以2进制数字存储的,整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有
符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而对于数值位正数的原、反、补码都相同;负整数的三种表示方法各不相同。原码: 直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码: 将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码: 反码+1就得到补码。其实不必将其想的太过于复杂,也就是说,
正整数的原反补码相同,计算和存储时不需要转换。而负整数原反补码,各不相同,需要对其进行相关转换后才能进行计算。📝例如:
1.int a=20的原、反、补
2.int b=-10的原、反、补

🍑3.2 整形在内存中的存储
现在我们已经知道了计算机中整数的3种二进制表示方法,那么整数在内存中究竟是以那种形式存储的呢?为了能够直观的观察到整数在内存中的存储形式,我们以
-10为例,通过内存窗口观察可得到:
内存中-10的16进制表示形式为:ff ff ff f6转化为2进制为:11111111111111111111111111110110显然这不正是-10的补码吗?结论: 对于整形来说,数据存放内存中其实存放的是补码。
为什么整形在内存中存放的是补码?
1.在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理;
2.同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。📝例如:计算int c= 1-1
1.在此过程中将其分别转换为补码后,符号位与数值位可以统一进行加法运算从而得到正确结果

2.原码——>补码与补码——>原码的计算路径是一样的

📖综上两点,我们可以体会到计算机设计的巧妙。设计师们用补码将原本复杂的问题极度简化,其构思之精妙实在惊为天人。
🍑3.3 大小端介绍及判断
细心地你有没有发现当我们观察内存中存放的补码时,存放的顺序有点不对劲。这是为什么呢?
在计算机中,数值是以字节为单位进行储存,当一个数值超过了1个字节,要存储在内存中就需要考虑存储的顺序。这里我们就引出了数据存储的大小端:🌳(1) 什么是大端小端?
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址 中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地 址中。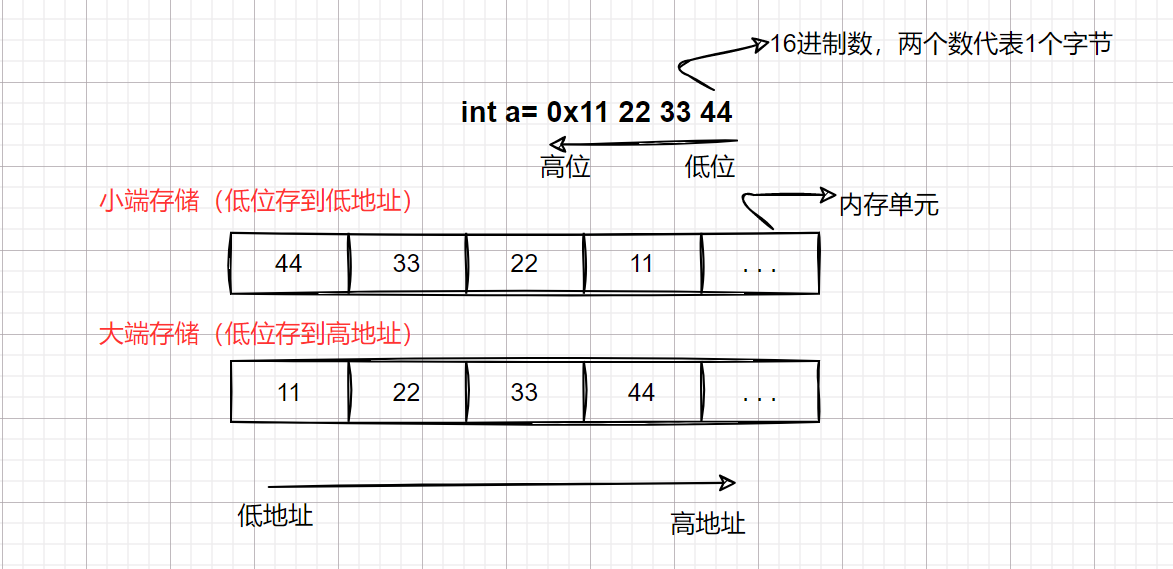
🌳(2) 为什么有大端和小端?
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元 都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short 型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因 此就导致了大端存储模式和小端存储模式。
我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。🌳(3) 设计一个小程序,判断当前机器的字节序
✍️思路:创建一个大于1字节的变量,用char*指针访问他们第一个字节的数值,因为char*指针访问顺序为从低地址到高地址,如果访问得到的数值是变量的低位,则机器为小端存储,反之为大端存储。
📑代码展示:
//返回1表示小端 //返回0表示大端 #includeint check_sys() { int a = 1; return *(char*)&a; } int main() { if(check_sys() == 1) printf("小端\n"); else printf("大端\n"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
🤔思考题:
unsigned int a= 0x1234; unsigned char b=*(unsigned char *)&a;- 1
- 2
在32位大端模式处理器上变量b等于多少?答案是0x00,为什么呢?这道题留给大家思考!
🍑3.4 有符号数和无符号数的取值范围如何定?
📝以
signed short和unsigned short类型为例:
推而广之:类型 空间大小 signed char -128~127 unsigned char 0~255 signed short -32768~32767 unsigned short 0~65535 signed int -2147483648~2147483648 unsigned int 0~4294967295 . . . . . . 📝牛刀小试:
下面代码在VS下输出的结果是?
int main() { char a[1000] = {0}; int i=0; for(i=0; i<1000; i++) { a[i] = -1-i; } printf("%d",strlen(a)); return 0; } //答案:255- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
🤔分析:用库函数strlen()求字符串长度,遇到‘\0’即ASCII码值为0时停止,返回0之前的字符长度。

总结
最后就浅浅总结一下吧!
本章主要讲解了基本的数据类型,着重介绍了整形家族及整形在内存中的储存。本章重点:
- 区分并能够灵活转换整数的三种表示方式:原码、反码、补码
- 理解整数在储存时的大小端模式。
- 学会区分和界定有符号数与无符号数的取值范围。
铁汁们,我们下期再见!😊😊😊

-
相关阅读:
力扣第 306 场周赛复盘
【 java 面向对象】Object 类结构的剖析
find、findindex、indexof的区别
论如何直接用EF Core实现创建更新时间、用户审计,自动化乐观并发、软删除和树形查询(中)
解决弹性布局父元素设置高自动换行,子元素均分高度问题(align-content: flex-start)
nginx中的惊群效应
软考网络工程师 第五章 第一节 移动通信与5G
凯撒密码加解密过程与破解原理
Flink系列之Flink基础使用与核心概念
二线程序员的出路
- 原文地址:https://blog.csdn.net/LEE180501/article/details/126253845
