-
进程地址空间
1. 程序地址空间
在我们以前学习C/C++时,我画过一些程序地址空间的图:
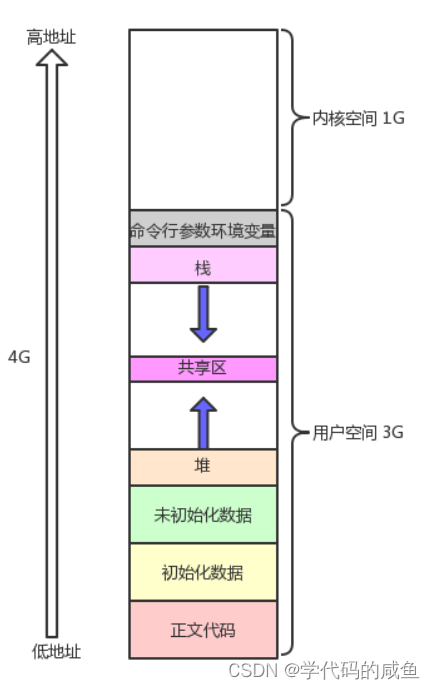
但是我们并不能正确的去理解。下面我们就需要弄清楚这个东西。
首先,我像问一下大家:程序地址空间是内存吗?
答案是:不是的。其实程序地址空间的叫法是不准确的,应该叫它进程地址空间。
既然我们说地址空间是这样发布的,那么我们就来验证一下。

我们在这里用一个代表把这个地址打印出来。共享区暂时没法验证,,后面再说。

从运行结果可以看出地址是逐渐升高的。

而这里我们可以看到堆栈之间有很大的镂空,里面是有共享区的。然后我们需要验证堆和栈的增长方向的问题。

我们多创建两个变量。

所以,堆区向地址增大方向增长,栈区向地址减少方向增长。如何理解static变量?

运行结果如下:

函数内定义的变量用static修饰,编译器会把该变量编译进全局数据区。下面我用代码来让大家感受一下地址空间的存在:
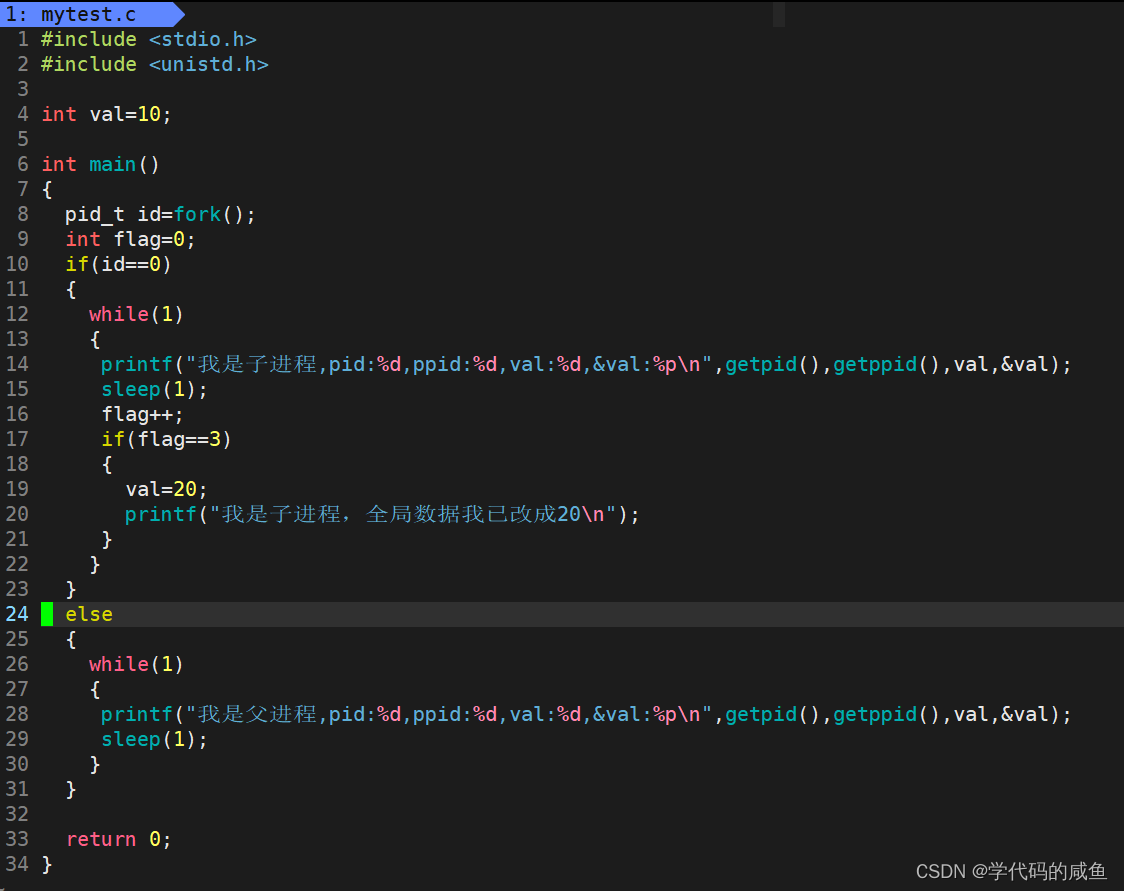
这个代码的意思是:前3秒子进程和父进程的值是一样,3秒过后子进程里把全局数据改成20。我们来看一下运行结果:

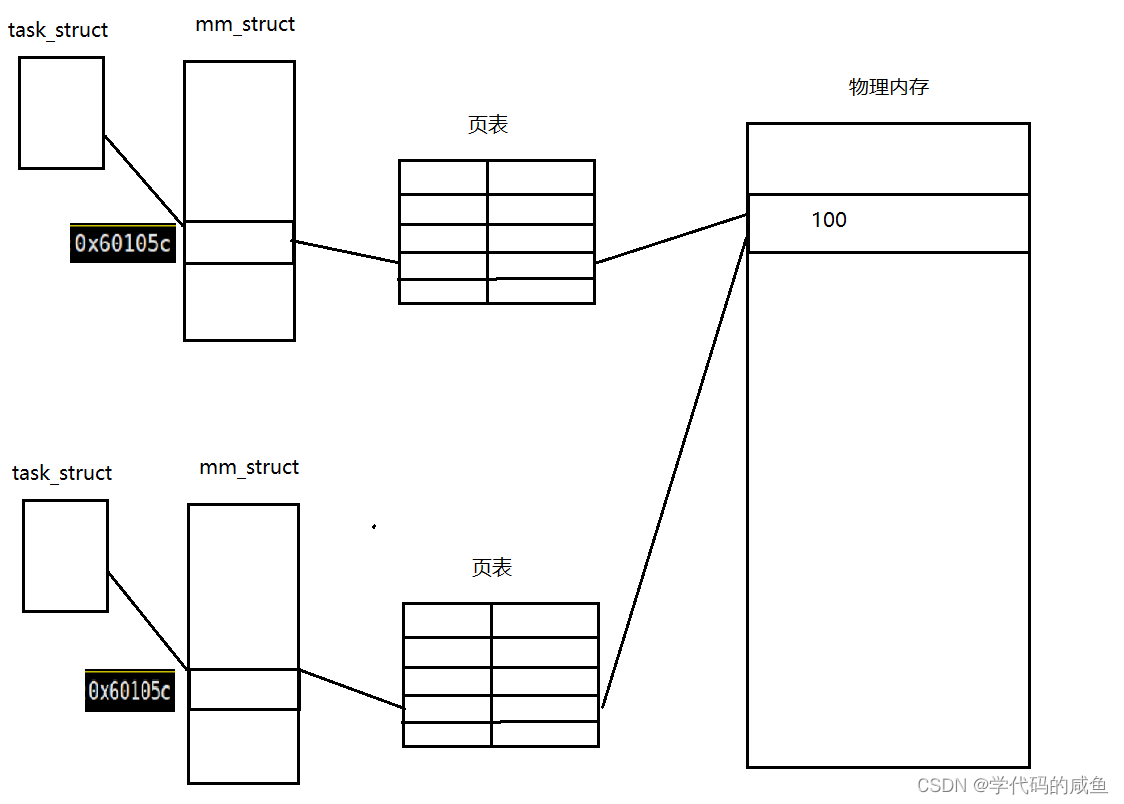
当父子进程没有人修改全局数据的时候,父子是共享该数据的。当修改全局变量后,父子进程读取同一个变量(地址一样),但父子进程读取的内容不一样。所以,我们在C/C++中使用的地址,绝对不是物理地址。因为如果是物理地址,不可能出现同一个内存中存在不同的值。那么是什么呢?答案是:虚拟地址。2. 进程地址空间
每一个进程在启动的时候,都会让操作系统给它创建一个地址空间,该地址空间就是进程地址空间。
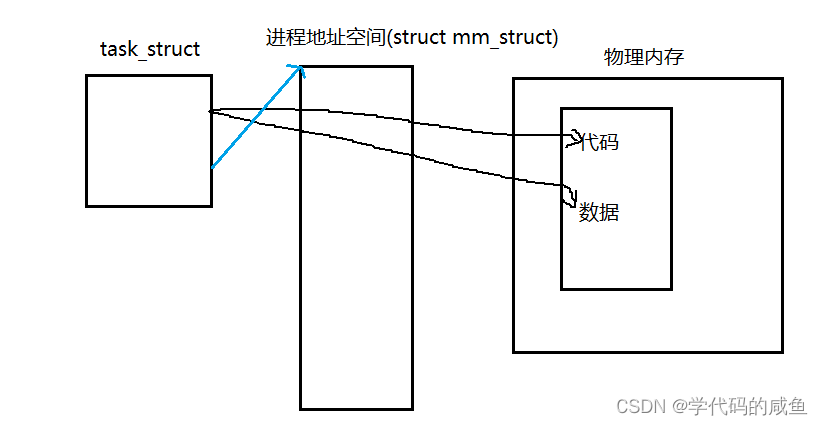
每一个进程都会有一个自己的进程地址空间。那么操作系统肯定需要管理这些进程地址空间,我们的管理观念就是先描述再组织。所以,进程地址空间,其实是内核里的一个数据结构(struct mm_struct)。什么是进程地址空间?
进程地址空间其实是操作系统给进程画的一个大饼,让每一个进程都认为自己是独占操作系统中的所有资源。2.1 程序是如何变成进程的

在内核中,每一个进程都有一个task_struct,在task_struct里有一个指向虚拟地址的指针,而虚拟地址需要通过页表映射到物理地址。

那么怎么通过页表映射呢?
其实虚拟地址划分了许多区域:

而这些区域在mm_struct里通过start和end来规定每个区域的大小。

每个区域都有自己的开始地址和结束地址。而这些地址就作为页表左侧的虚拟地址,页表右侧作为物理地址,然后进行映射。下面,问大家两个问题:
1.程序被编译出来,没有被加载的时候,程序内部有地址吗?
答案是:有的。像我们之前说的链接。就是把我的程序和库里的代码产生关联。就是把库里函数的地址填到我们代码的地方。2.程序被编译出来,没有被加载的时候,程序内部有区域吗?
答案是:有的。
现在,在磁盘里有一个可执行程序它的代码区在它的地址里的0x1F处。我们想把这个可执行程序加载到物理内存代码区的0x100处。那么可执行程序在物理内存的地址就是0x11F。
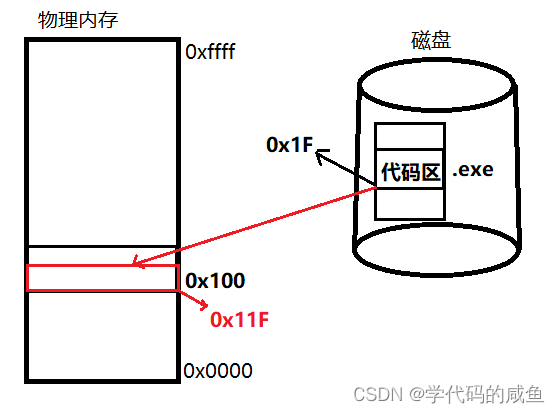
这叫全新的地址叫做相对地址,也叫做虚拟地址。然后进程地址空间通过页表来映射物理内存。

当CPU读取代码和数据时,一定是虚拟地址,因为物理内存在读取前就已经是虚拟地址了。然后我们去找虚拟地址的时候,经过页表的转换,一定能找到物理地址。现在我们再解释一下一开始的代码:
当没有修改全局变量的时候,父进程和子进程是共享的:
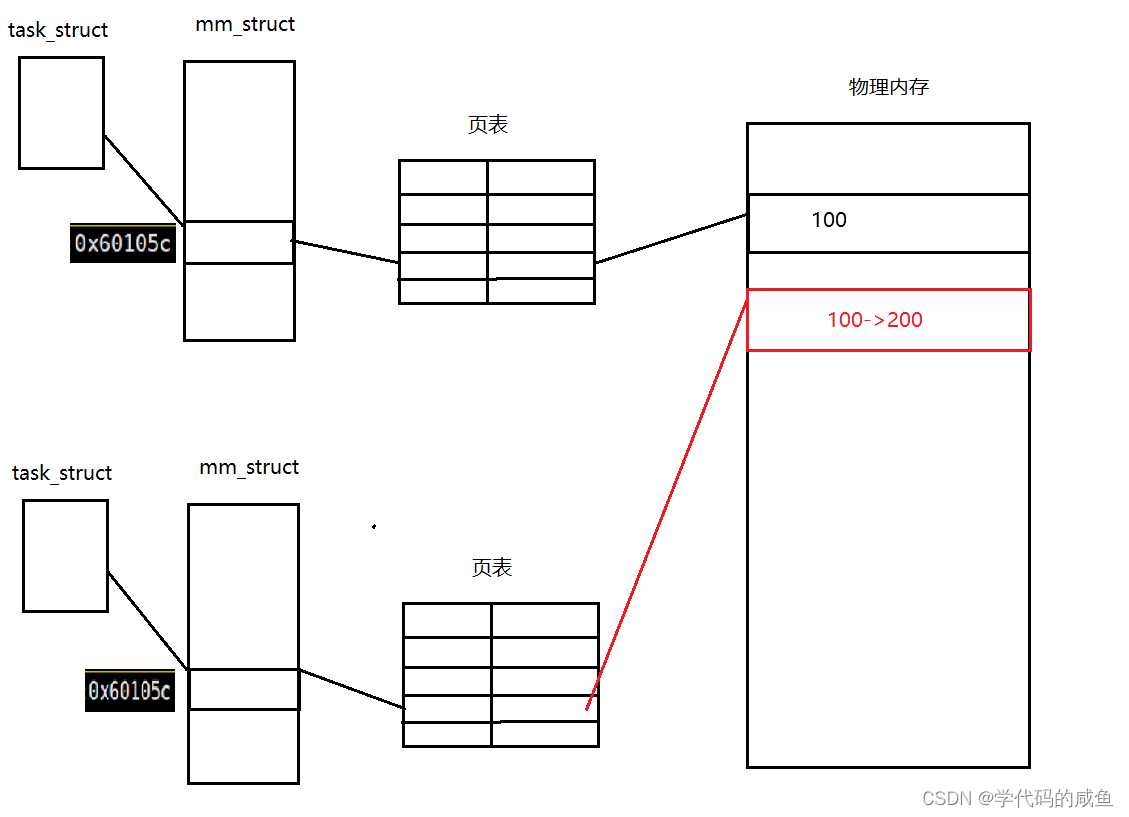
当子进程修改全局数据时,就会重新复制一段内存,然后把100改成200。这个也叫做写时拷贝。
我们只是改变了右边页表的内容,左边页表的内容没有修改。
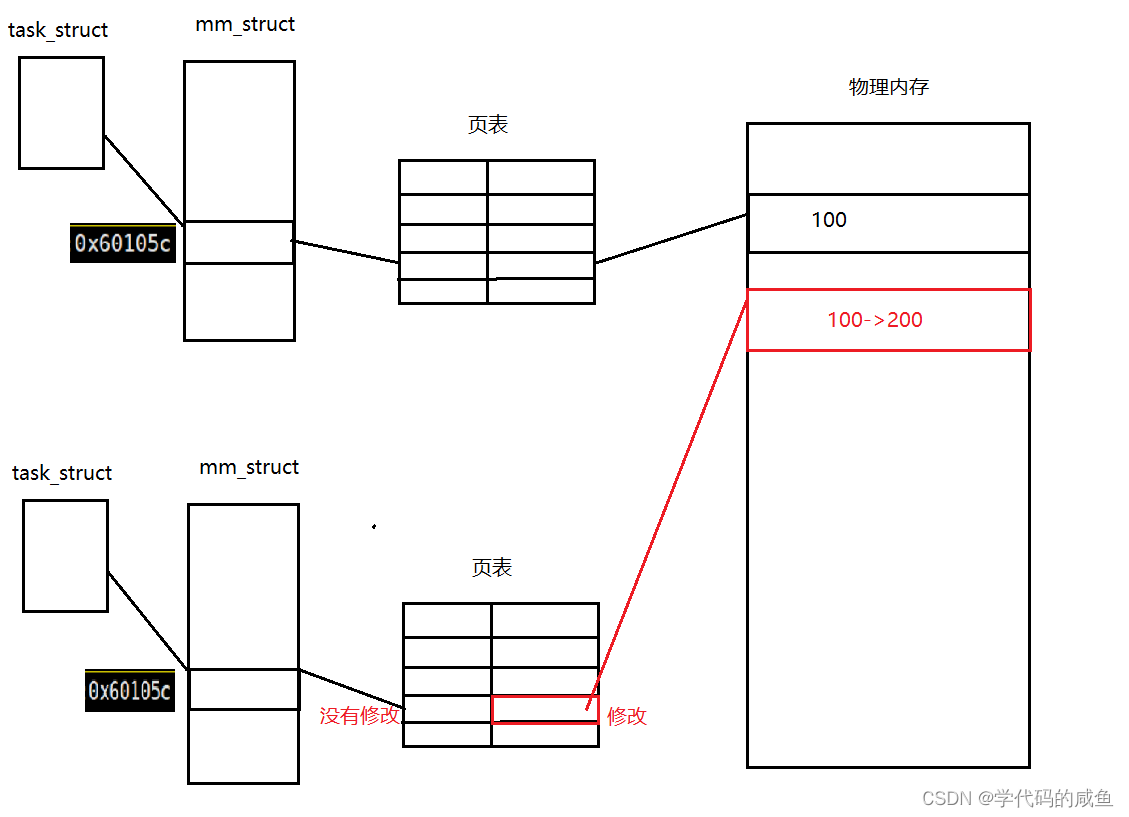
所以,我们从运行结果看出,它们的虚拟地址一样,但是打印出来的值不一样。fork有两个返回值,同一个变量,为什么会有不同的值?
pid_t id是属于父进程栈空间中定义的变量,fork内部,return会执行两次,return的本质就是通过寄存器将返回值写入到接受返回值的变量中。
当id=fork()的时候,谁先返回,谁就要发生写时拷贝。所以,同一个变量,会有不同的内容值。本质是虚拟地址是一样的,但物理地址不一样。为什么要有虚拟地址空间?
因为直接让进程访问物理内存是不安全的。如果有一个野指针,没有虚拟地址空间,此时野指针就可能直接修改物理内存的数据。

而有虚拟地址空间,如果访问野指针,页表里没有建立映射关系,就不会访问到物理内存。页表映射转换失败,就会把进程杀掉。
第一个原因:保护内存。
第二个原因:让进程管理和内存管理通过地址空间,进行功能模块的解耦。
什么意思呢?就是如果我们想在堆上开辟一块空间。它会先在虚拟地址空间开辟出来,然后等CPU调度到此开辟空间的代码才会通过页表的映射去物理地址上开辟。为什么会这样?原因是:如果我们在虚拟地址堆上开辟了一段空间,直接在物理地址上开辟。但此时我们没有到用此空间的地方,那么就会白白占用空间资源。如果没有虚拟地址,那么当CPU调度时,执行到malloc代码时,就会跑到物理内存上开辟这叫做没有解耦。
第三个原因:让进程或者程序可以以一种统一的视角看待内存,方便以统一的方式来编译和加载所有可执行程序,简化进程本身的设计与实现。 -
相关阅读:
轻量级网络整理及其在Yolov5上的实现
低代码:数字化转型趋势下的快速开发方式
dotnet6 docker 部署
Nginx配置整合:基本概念、命令、反向代理、负载均衡、动静分离、高可用
get_trade_detail_data函数使用
IOS 证书更新
JVM之Class文件分析详解
DHTMLX Gantt 8.0.5 Crack -甘特图
Spring中的Environment外部化配置管理详解
与迭代次数有关的一种差值结构
- 原文地址:https://blog.csdn.net/qq_52154068/article/details/126534838