-
【Linux系统管理】05 常用命令 & 06 vim编辑器
1.1 命令的提示符
[root@localhost ~]#- 1
- []:这是提示符的分隔符号,没有特殊含义。
- root:显示的是当前的登录用户,现在使用的是root用户登录。
- @:分隔符号,没有特殊含义。
- localhost:当前系统的简写主机名(完整的主机名是localhost.localdomain)
- ~:代表用户当前所在的目录,此例中用户当前所在的目录是家目录
- #:命令提示符,超级用户是 #,普通用户是 $
1.2 命令的基本格式
[root@localhost ~]# 命令 [选项] [参数]- 1
ls 是最常见的目录操作命令,主要作用是显示目录下的内容。
- 命令名称:ls
- 英文原意:list
- 所在路径:/bin/ls
- 执行权限:所有用户
- 功能描述:显示目录下的内容
# ls [选项] [文件名或目录名] 选项: -a :显示所有文件(隐藏文件和非隐藏文件) # 隐藏文件是重要系统文件 --color=when:支持颜色输出,when 的值默认是always(总显示颜色),也可以是never(从不显示颜色)和auto (自动) -d :显示目录信息,而不是目录下的文件 -h :人性化显示,按照我们习惯的单位显示文件大小 -i :显示文件的i节点号 -l :长格式显示- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
举几个例子:
# ls -l total 72 -rw-------. 1 root root 1712 Jun 19 17:31 anaconda-ks.cfg -rw-r--r--. 1 root root 50968 Jun 19 17:31 install.log -rw-r--r--. 1 root root 11504 Jun 19 17:27 install.log.syslog # 权限 引用计数 所有者 所属组 文件大小 文件修改时间 文件名- 1
- 2
- 3
- 4
- 5
- 6
我们已经知道“-1“选项用于显示文件的详细信息,那么“-1”选项显示的这7列分别是什么含义?
- 第一列:权限。具体权限的含义将在4.5节中讲解。
- 第二列:引用计数。文件的引用计数代表该文件的硬链接个数,而目录的引用计数代表该目录有多少个一级子目录(ls -al,所有目录下都有.(当前目录) 和 …(上次目录) 的概念)。
- 第三列:所有者,也就是这个文件属于哪个用户。默认所有者是文件的建立用户。
- 第四列:所属组。默认所属组是文件建立用户的有效组,一般情况下就是建立用户的所在组。
- 第五列:大小。默认单位是字节(ls -lh,使用更加人性化的显示文件大小)。
- 第六列:文件修改时间。文件状态修改时间或文件数据修改时间都会更改这个时间,注意这个时间不是文件的创建时间。
- 第七列:文件名。
选项:是用于调整命令的功能的。
参数:是命令的操作对象,如果省略参数,是因为有默认参数
二、目录操作命令
2.1 ls 命令
见前一小节的内容
2.2 cd 命令
cd是切换所在目录的命令,这个命令的基本信息如下。
- 命令名称: cd。
- 英文原意: change directory。
- 所在路径: Shell内置命令。
- 执行权限:所有用户
功能描述:切换所在目录。
2.2.1 cd 命令的简化用法
特殊符号 作用 ~ 代表用户的家目录 - 代表上次所在目录 . 代表当前目录 … 代表上级目录 2.2.2 绝对路径和相对路径
绝对路径:以根目录为参照物,从根目录开始,一级一级进入目录
相对路径:以当前目录作为参照物,进行目录查找
2.3 pwd 命令
显示当前工作目录的绝对路径。
概要
pwd [-LP]
主要用途
- 显示当前工作目录。
选项
- -L (默认值)打印环境变量"$PWD"的值,可能为符号链接。
- -P 打印当前工作目录的物理位置。
返回值
- 返回状态为成功除非给出了非法选项或是当前目录无法读取。
注意
- 该命令是bash内建命令,相关的帮助信息请查看help命令。
2.4 mkdir 命令
mkdir 命令用来创建目录。该命令创建由dirname命名的目录。如果在目录名的前面没有加任何路径名,则在当前目录下创建由dirname指定的目录;如果给出了一个已经存在的路径,将会在该目录下创建一个指定的目录。在创建目录时,应保证新建的目录与它所在目录下的文件没有重名。
注意:在创建文件时,不要把所有的文件都存放在主目录中,可以创建子目录,通过它们来更有效地组织文件。最好采用前后一致的命名方式来区分文件和目录。例如,目录名可以以大写字母开头,这样,在目录列表中目录名就出现在前面。
在一个子目录中应包含类型相似或用途相近的文件。例如,应建立一个子目录,它包含所有的数据库文件,另有一个子目录应包含电子表格文件,还有一个子目录应包含文字处理文档,等等。目录也是文件,它们和普通文件一样遵循相同的命名规则,并且利用全路径可以唯一地指定一个目录。
其基本信息如下。
- 命令名称:mkdir
- 英文原意:make directories
- 所在路径:/bin/mkdir
- 执行权限:所有用户
- 功能描述:创建空目录
命令格式:
# mkdir [选项] 目录名 选项: -p:递归建立所需目录 -v:打印建立目录的过程 -Z:设置安全上下文,当使用SELinux时有效; -m<目标属性>或--mode<目标属性>:建立目录的同时设置目录的权限;- 1
- 2
- 3
- 4
- 5
- 6
任何的操作系统都无法在同一个目录下创建同名的文件和同名的目录。
范例:
~ mkdir -pv -m 700 /tmp/dir1/dir2 mkdir: created directory `/tmp/dir1' mkdir: created directory `/tmp/dir1/dir2' ~ tree -p /tmp/ /tmp/ ├── [drwxr-xr-x] dir1 │ └── [drwx------] dir2- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.5 rmdir 命令
既然有建立目录的命令,就一定会有删除目录的命令 rmdir,其基本信息如下。
- 命令名称: rmdir。
- 英文原意:remove empty directories。
- 所在路径:/bin/rmdir。
- 执行权限:所有用户。
- 功能描述:删除空目录。
命令格式
# rmdir [选项] 目录名 选项: -p:递归删除所需目录 -v:打印删除目录的过程- 1
- 2
- 3
- 4
rmdir命令的作用十分有限,因为只能删除空目录,所以一旦目录中有内容,就会报错。
这个命令比较“笨”,所以我们不太常用。后续我们不论删除的是文件还是目录,都会使用 rm 命令
可以使用 extundelete 命令恢复一定的数据,是通过恢复硬盘的 inode 节点或者文件指针的方式,来建立文件索引和文件数据内容的连接。
三、文件操作命令
3.1 touch 命令
创建空文件或修改文件时间,这个命令的基本信息如下。
- 命令名称:touch
- 英文原意:change file timestamps
- 所在路径:/bin/touch
- 执行权限:所有用户
- 功能描述:修改文件的时间戳。
范例:touch 命令
# touch t1.txt- 1
3.2 stat 命令
stat是查看文件详细信息的命令,而且可以看到文件的这三个时间,其基本信息如下。
- 命令名称:stat
- 英文原意:display file or file system status
- 所在路径:/usr/bin/stat
- 执行权限:所有用户
功能描述:显示文件或文件系统的详细信息
# stat anaconda-ks.cfg File(文件名): `anaconda-ks.cfg' Size(大小): 1712 Blocks(块): 8 IO Block(IO块): 4096 regular file(普通文件) Device(设备): fd00h/64768d Inode(I节点号): 1844702 Links(硬连接数): 1 Access(环境): (0600/-rw-------) Uid(用户ID): ( 0/ root) Gid(组ID): ( 0/ root) Access(最近访问时间): 2022-06-26 17:14:25.661877869 +0800 # 数据访问时间 Modify(最近更改时间): 2022-06-19 17:31:30.898999912 +0800 # 数据修改时间 Change(最近改动时间): 2022-06-19 17:31:40.700999913 +0800 # 状态修改时间 # 然而实际上,Change不光代表文件状态修改时间,也包括文件内容修改时间 Linux 没有记录创建时间- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.3 cat 命令
cat命令用来查看文件内容。这个命令的基本信息如下。
- 命令名称:cat。
- 英文原意:concatenate files and print on the standard output。
- 所在路径:/bin/cat。
- 执行权限:所有用户。
- 功能描述:合并文件并打印输出到标准输出
命令格式
# cat [选项] [文件名] 选项: -A :相当于-vET选项的整合﹐用于列出所有隐藏符号 -E :列出每行结尾的回车符$ -n :显示行号 -T :把Tab键用^I显示出来 -v :列出特殊字符 # 一般用于小文件的内容查看,大文件是尽量不要使用- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
范例:
cat -An /etc/fstab- 1
3.4 more 命令
more是分屏显示文件的命令,其基本信息如下。
- 命令名称:more。
- 英文原意:file perusal filter for crt viewin。
- 所在路径:/bin/more。
- 执行权限:所有用户。
- 功能描述:分屏显示文件内容。
more命令比较简单,一般不用什么选项,命令会打开一个交互界面,可以识别一些交互命令。常用的交互命令如下。
- 空格键:向下翻页。【Ctrl + F】
- b:向上翻页。【Ctrl + B】
- 回车键:向下滚动一行。
- /字符串:搜索指定的字符串。
- q:退出。
3.5 less 命令
less 命令和 more命令类似,只是more是分屏显示命令,而less是分行显示命令,其基本信息如下。
- 命令名称:less。
- 英文原意:opposite of more。
- 所在路径:/usr/bin/less
- 执行权限:所有用户。
- 功能描述:分行显示文件内容
3.6 head 命令
less命令和 more命令类似,只是more是分屏显示命令,而less是分行显示命令,其基本信息如下。
- 命令名称:less
- 英文原意:opposite of more。
- 所在路径:/usr/bin/less。
- 执行权限:所有用户。
- 功能描述:分行显示文件内容
3.7 tail 命令
既然有显示文件开头的命令,就会有显示文件结尾的命令。tail命令的基本信息如下。
- 命令名称:tail
- 英文原意:output the last part of files。
- 所在路径:/ust/bin/tail。
- 执行权限:所有用户。
- 功能描述:显示文件结尾的内容。
命令格式:
# tail [选项] [文件名] 选项: -v :总是打印提供文件名的头文件 -n 行数 :从文件结尾开始,显示指定的行数 -f :监听文件的新增内容- 1
- 2
- 3
- 4
- 5
3.8 ln 命令
我们来看看 ln 命令的基本信息
- 命令名称:ln。
- 英文原意:make links between file
- 所在路径:/bin/ln
- 执行权限:所有用户
- 功能描述:在文件之间建立链接
3.8.1 inode 表结构
每个文件的属性信息 meta data,比如:文件的大小,时间,类型,权限等等,称为文件的元数据(meta data)。这些元数据是存放在 node(index node)表中。node 表中有很多条记录组成,第一条记录对应的存放了一个文件的元数据信息。
第一个 node 表记录对应的保存了以下信息:
- inode number 节点号
- 文件类型
- UID
- GID
- 链接数(指向这个文件名路径名称个数)
- 该文件的大小和不同的时间戳
- 指向磁盘上文件的数据块指针
- 有关文件的其他数据



在硬盘的分区上,有一块空间用来存放文件和目录的元数据metadata,有一块空间用来存放真正的数据data
元数据的存放,每一个文件的元数据信息存放,被称为 inode 表。inode 表包含以下信息:
- inode number 节点号
- 文件类型
- UID
- GID
- 链接数(指向这个文件名路径名称个数)
- 该文件的大小和不同的时间戳
- 指向磁盘上文件的数据块指针
- 有关文件的其他数据
文件的元数据信息和真正的数据存放位置不同,所以就需要有数据指针(地址)来引导寻找真正数据的位置
指针可以分为:直接块指针、间接块指针、双重间接块指针、三重间接块指针
而每一个磁盘上存放数据的空间,会有一个分配单位:block 块(block 的大小通常是4K = 4096字节)
- 直接块指针:就是直接使用指针就找到了文件数据真实存放的位置;直接块指针一共有 12 个,12个指针就可以分别指向 12 个块 block;那么就是 12 * 4 = 48K 的数据。也就是说 直接块指针可以存放 48K 以内的数据内容。
- 间接块指针:当文件超过48K的数据大小,那么就会用到间接块指针;间接块指针是会指定到一个指针块 block 中,指针块也是 4K(4096 字节),指针块中一个小块就是占用空间为 4 个字节,那么指针块可以存放 1024 个指针。那么 1024 个指针指向的数据块存放为 4K,那么间接块指针可以存放 1024 * 4K = 4M。也就是说 间接块指针可以存放 4M 以内的数据内容。
- 双重间接块指针同理。跟套娃一样。那么双重间接块指针可以存放 1024 * 1024 * 4K = 4G。也就是说 双重间接块指针可以存放 4G 以内的数据内容。
- 三重间接块指针同理。也就是说 三重间接块指针可以存放 4T 以内的数据内容。
数据越大,指针就不是直接指向数据了,需要通过间接的手段实现。那么文件越大,找起来会慢。
Linux 操作系统中的文件系统在对底层元数据 metadata 和真实数据 data 的实现方式上各有不同之处。
在磁盘上,每个文件都会有一个与众不同的唯一标识,叫 inode number节点号;就像每个人都会唯一的身份证号一样。节点号是一个整数;就是文件的节点号来标识文件;节点号是每个分区独立分配的;
节点号也是宝贵的资源,每创建一个目录或者文件,都会消耗一个节点号
# 查看系统节点表空间利用率 $ df -Thi # 查看物理分区空间利用率 $ df -Th $ ls -il /data total 0 131 -rw-r--r--. 1 root root 0 May 5 22:15 f1.txt 132 -rw-r--r--. 1 root root 0 May 5 22:15 f2.txt 133 -rw-r--r--. 1 root root 0 May 5 22:15 f3.txt $ df -ih Filesystem Inodes IUsed IFree IUse% Mounted on devtmpfs 457K 402 457K 1% /dev tmpfs 464K 1 464K 1% /dev/shm tmpfs 464K 858 463K 1% /run tmpfs 464K 17 464K 1% /sys/fs/cgroup /dev/sda2 50M 121K 50M 1% / /dev/sda3 50M 9 50M 1% /data /dev/sda1 1.0M 309 1.0M 1% /boot tmpfs 464K 23 464K 1% /run/user/42 tmpfs 464K 11 464K 1% /run/user/0 # 不同的分区中分配的节点号可以相同。就像中国和印度可能会出现身份证号一样的情况,但是用来标识不同的人 # 同一个分区中分配的节点号可能会有重复,即同一个文件有多个名,比如硬链接。在磁盘上占用的空间是一份 $ ls -il /data | grep 131 131 -rw-r--r--. 1 root root 0 May 5 22:15 f1.txt $ ls -il /boot | grep 131 131 drwxr-xr-x. 3 root root 17 Jul 11 2021 efi- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
目录
目录是个特殊文件,文件内容保存了目录中文件的列表及 inode number
- 文件引用一个是 inode 号
- 人是通过文件名来引用一个文件
- 一个目录是目录下的文件名和文件 inode 号之间的映射
inode 表和目录

目录是特殊的文件。
目录的元数据跟文件的元数据大致相同,只是在指针指向中,目录的指针指向的数据。目录的数据部分是目录下所有文件的列表(列表存放的是文件名+节点号)
cp 和 inode
cp 命令:
- 分配一个空闲的 inode 号,在 inode 表中生成新的条目
- 在目录中创建一个目录项,将名称与 inode 编号关联
- 拷贝数据生成新的文件
rm 和 inode
rm 命令:
- 链接数递减,从而释放的 inode 号可以被重用
- 把数据块放在空闲列表中
- 删除目录项
- 数据实际上不会马上被删除,但是另一个文件使用数据块时将被覆盖
mv 和 inode
-
如果 mv 命令的目标和源在系统的文件系统,作为 mv 命令:
-
- 用新的文件名来创建对应新的目录项
- 删除旧目录条目对应的旧的文件名
- 不影响 inode 表(除了时间戳)或磁盘上的数据位置:没有数据被移动;
-
如果目标和源在不同的文件系统,mv 相当于 cp 和 rm
$ touch file{1..n}.txt -bash: /usr/bin/touch: Argument list too long # 正确的写法 echo file{1..n}.txt | xargs touch # 删除大量的空文件 echo file{1..n}.txt | xargs rm- 1
- 2
- 3
- 4
- 5
- 6
- 7
节点编号用光的情况:只有分区中有大量的无用的小文件占用
解决方法:
- 删除分区中无用的小文件
- 修改inode的数量(注意该方法会丢失磁盘数据,建议操作前备份数据)
3.8.2 ln 命令的基本格式如下:

# 查看根目录的Inode号,所有操作系统的根目录Inode都是2 # 1 在内核加载的时候就已经被占用了 ~ ls -ild / 2 dr-xr-xr-x. 25 root root 4096 Jun 26 23:20 / # ln [选项] 源文件 目标文件 选项: -s :建立软链接文件。如果不加"-s"选项,则建立硬链接文件 -f :强制。如果目标文件已经存在,则删除目标文件后再建立链接文件- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果创建硬链接:
~ touch cangls ~ ln /root/cangls /tmp/ # 建立硬链接文件,目标文件没有写文件名,会和原名一致 # 也就是 /root/cangls 和 /tmp/cangls 是硬链接文件 # 硬链接方式创建的文件不管是修改源文件还是硬链接文件都是会实时同步内容修改- 1
- 2
- 3
- 4
- 5
如果创建软链接:
~ touch bols ~ ln -sv /root/bols /tmp/ `/tmp/bols' -> `/root/bols' # 建立软链接文件- 1
- 2
- 3
- 4
3.8.3 硬链接和软链接的特征
硬链接特征:
- 源文件和硬链接文件拥有相同的Inode和 Block
- 修改任意一个文件,另一个都改变
- 删除任意一个文件,另一个都能使用
- 硬链接标记不清,很难确认硬链接文件位置,不建议使用
- 硬链接不能链接目录
- 硬链接不能跨分区
软链接特征:

- 软链接可以类似可以 Windows 下的快捷方式
- 软链接标记清晰,可以确认源文件的位置
- 软链接和源文件拥有不同的 Inode和 Block,软链接保存的源文件的Inode,所以不管源文件多大,软链接的大小保持不变
- 两个文件修改任意一个,另一个都改变
- 删除软链接,源文件不受影响;删除源文件,软链接不能使用
- 软链接没有实际数据,只保存源文件的Inode,不论源文件多大,软链接大小不变(保存的大小是指向源文件路径大小)
- 软链接的权限是最大权限 lrwxrwxrwx.(软链接的权限没有实际意义),但是由于没有实际数据,最终访问时需要参考源文件权限
- 软链接可以链接目录
- 软链接可以跨分区
- 软链接特征明显,推荐建议使用软链接
~ ls -il /etc/rc.local /etc/rc.d/rc.local 1710704 -rwxr-xr-x. 1 root root 220 Jun 20 2018 /etc/rc.d/rc.local 1710715 lrwxrwxrwx. 1 root root 13 Jun 19 17:18 /etc/rc.local -> rc.d/rc.local # 软链接可以使用绝对路径或者相对路径 # 软链接的相对路径是相对于软链接文件的目录编写的 ~ ln -sv /root/install.log /tmp/install.log ~ ln -sv ../root/anaconda-ks.cfg /tmp/anaconda-ks.cfg ~ ls -l /tmp/ total 8 # 使用相对路径 lrwxrwxrwx. 1 root root 23 Aug 1 19:23 anaconda-ks.cfg -> ../root/anaconda-ks.cfg # 使用绝对路径 lrwxrwxrwx. 1 root root 17 Aug 1 19:23 install.log -> /root/install.log- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
四、目录和文件都能操作的命令
4.1 rm 命令
rm是强大的删除命令,不仅可以删除文件,也可以删除目录。这个命令的基本信息如下。
- 命令名称:rm
- 英文原意:remove files or directories
- 所在路径:/bin/rm
- 执行权限:所有用户
- 功能描述:删除文件或目录。
命令格式
# rm [选项] [文件名或者目录] 选项: -f :强制删除(force) -i :交互删除,在删除之前会询问用户 -r :递归删除,可以删除目录(recursive)- 1
- 2
- 3
- 4
- 5
4.2 cp 命令
cp是用于复制的命令,其基本信息如下:
- 命令名称:cp
- 英文原意:copy files and directories
- 所在路径:/bin/cp
- 执行权限:所有用户
- 功能描述:复制文件和目录。
命令格式
# rm [选项] 源文件 目标文件 选项: -a :相当于-dpr选项的集合,这几个选项我们――介绍 -d :如果源文件为软链接(对硬链接无效),则复制出的目标文件也为软链接 -i :询问,如果目标文件已经存在.则会询问是否覆盖 -p :复制后目标文件保留源文件的属性(包括所有者、所属组、权限和时间) -r :递归复制,用于复制目录 -v :显示复制的过程- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.3 mv 命令
mv是用来剪切或者文件重命名的命令,其基本信息如下。
- 命令名称:mv
- 英文原意:move files
- 所在路径:/bin/mv
- 执行权限:所有用户
- 功能描述:移动文件或改名
命令格式:
# mv [选项] 源文件 目标文件 选项: -f :强制覆盖,如果目标文件已经存在,则不询问,直接强制覆盖 -i :交互移动,如果目标文件已经存在,则询问用户是否覆盖(默认选项) -v :显示详细信息- 1
- 2
- 3
- 4
- 5
移动 和 复制的区别是:复制时源文件还在,移动则是源文件消失了,相当于是 Windows 中的剪切。
五、基本权限管理
5.1 权限的介绍
权限位的含义
前面讲解 ls 命令时,我们已经知道长格式显示的第一列就是文件的权限,例如:
[root@localhost ~]# ls -l install.log -rw-r--r--. 1 root root 50968 Jun 19 17:31 install.log -rw-r--r--.(是受 SELinux 保护的,安全上下文) # 查看ls帮助文档 # Linux 除了使用 man 获取帮助,也可以使用 info 获取帮助 # info 比 man 帮助更加详细 [root@localhost ~]# info ls 选择 What information is listed::- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

第一列的权限位如果不计算最后的“.”(这个点的含义我们在后面解释),则共有10位,这10位权限位的含义如图所示。

(1)第1位代表文件类型。Linux不像 Windows使用扩展名表示文件类型,而是使用权限位的第1位表示文件类型。虽然 Linux文件的种类不像Windows 中那么多,但是分类也不少,详细情况可以使用“info ls”命令查看。在这里只讲一些常见的文件类型。
-
“-”:普通文件。
-
“b”“块设备文件。这是一种特殊设备文件,存储设备都是这种文件,如分区文件 /dev/sda1 就是这种文件。
-
“c”:字符设备文件。这也是特殊设备文件,输入设备一般都是这种文件,如鼠标、键盘等。
-
“d”:目录文件。Linux 中一切皆文件,所以目录也是文件的一种。
-
“l”:软链接文件。
-
“p”:管道符文件。这是一种非常少见的特殊设备文件。
-
“s”:套接字文件。这也是一种特殊设备文件,一些服务支持Socket访问,就会产生这样的文件。套接字文件会根据机器的配置生成相应的套接字文件。不同的版本应用的套接字文件是不同的。
(2)第2-4位代表文件所有者的权限。
- -r :代表read,是读取权限。
- -w :代表write,是写权限。
- -x :代表execute,是执行权限。
(3)第5-7位代表文件所属组的权限(所属组内的用户)
- -r :代表read,是读取权限。
- -w :代表write,是写权限。
- -x :代表execute,是执行权限。
(4)第8-10位代表文件其他人的权限
- -r :代表read,是读取权限。
- -w :代表write,是写权限。
- -x :代表execute,是执行权限。
5.2 基本权限命令
首先来看修改权限的命令chmod,其基本信息如下。
- 命令名称:chmod。
- 英文原意:change file mode bits
- 所在路径:/bin/chmod。
- 执行权限:所有用户。
- 功能描述:修改文件的权限模式。
5.2.1 命令格式
# chmod [选项] 权限模式 文件名 选项: -R :递归设置权限,也就是给子目录中的所有文件设定权限- 1
- 2
- 3
5.2.2 权限模式
chmod命令的权限模式的格式是“[ugoa][ [+=][perms] ]”,也就是“[用户身份][ [赋予方式][权限] ]'的格式,我们来解释一下。
-
用户身份
-
- - u:代表所有者(user) 。
-
- - g:代表所属组(group)。
- - o:代表其他人(other)。
- - a:代表全部身份(all)。
-
赋予方式:
-
-
- :加入权限
-
- :减去权限
- = :设置权限
-
-
权限:
-
- - r :读取权限(read)
- - w :写权限(write)
- - x :执行权限(execute)
5.2.3 数字权限
数字权限的赋予方式是最南单的,但是不抓之前的字母权限好记、直观。我们来看看这些数字权限的含义。
- 4:代表"r"权限
- 2:代表"w"权限
- 1:代表"x"权限
5.2.4 常用权限
数字权限的赋予方式更加简单,但是需要用户对这几个数字更加熟悉。其实常用权限也并不多,只有如下几个。
- 644:这是文件的基本权限,代表所有者拥有读、写权限,而所属组和其他人拥有只读权限。
- 755:这是文件的执行权限和目录的基本权限,代表所有者拥有读、写和执行权限,而所属组和其他人拥有读和执行权限。
- 777:这是最大权限。在实际的生产服务器中,要尽力避免给文件或目录赋予这样的权限,这会造成一定的安全隐患。
5.3 基本权限的作用
5.3.1 权限含义的解释
首先,读、写、执行权限对文件和目录的作用是不同的。
(1)权限对文件的作用:
- 读®:对文件有读(r)权限,代表可以读取文件中的数据。如果把权限对应到命令上,那么一旦对文件有读(r)权限,就可以对文件执行cat、more、less、head、tail 等文件查看命令。
- 写(w):对文件有写(w)权限,代表可以修改文件中的数据。如果把权限对应到命令上,那么一旦对文件有写(w)权限,就可以对文件执行vim、echo等修改文件数据的命令。注意:对文件有写权限,是不能删除文件本身的,只能修改文件中的数据。如果要想删除文件,则需要对文件的上级目录拥有写(w)权限【因为上级目录的 Block 存放的是文件的 Inode 节点及其文件名】。
- 执行(x):对文件有执行(x)权限,代表文件拥有了执行权限,可以运行。在Linux中,只要文件有执行(x)权限,这个文件就是执行文件了。只是这个文件到底能不能正确执行,不仅需要执行(x) 权限,还要看文件中的代码是不是正确的语言代码。对文件来说,执行(x)权限是最高权限。
(2)权限对目录的作用:
- 读®:对目录有读(r)权限,代表可以查看目录下的内容,也就是可以查看目录下有哪些子文件和子目录。如果把权限对应到命令上,那么一旦对目录拥有了读(r)权限,就可以在目录下执行 ls 命令,查看目录下的内容了。
- 写(w):对目录有写(r)权限,代表可以修改目录下的数据,也就是可以在目录中新建、删除、复制、剪切子文件或子目录。如果把权限对应到命令上,那么一旦对目录拥有了写(w)权限,就可以在目录下执行 touch、rm、cp、mv命令。对目录来说,写(w)权限是最高权限。
- 执行(x):目录是不能运行的,那么对目录拥有执行(x)权限,代表可以进入目录。如果把权限对应到命令上,那么一旦对目录拥有了执行(x)权限,就可以对目录执行cd命令,进入目录。
执行权限对于文件是最大权限,但是对于目录来说则是最小权限。
目录的可用权限
目录的可拥权限其实只有以下几个。
- 0:任何权限都不赋予。
- 5:基本的目录浏览和进入权限。
- 7:完全权限。
# 使用普通用户进行相应的测试 ~ su - user1 [user1@localhost ~]$ mkdir 123 [user1@localhost ~]$ touch 123/abc.txt [user1@localhost ~]$ ls -lR ~ /home/user1: total 4 drwxrwxr-x. 2 user1 user1 4096 Aug 2 00:45 123 /home/user1/123: total 0 -rw-rw-r--. 1 user1 user1 0 Aug 2 00:45 abc.txt # 将测试的目录和文件在所有者权限设置为0,那么目录就是075,文件就是064 [user1@localhost ~]$chmod 064 123/abc.txt [user1@localhost ~]$chmod 075 123/ ### 开始进行测试目录1 ### [user1@localhost ~]$ ls -l 123/ ls: cannot open directory 123/: Permission denied [user1@localhost ~]$ cd 123/ -bash: cd: 123/: Permission denied # 将测试的目录放开读取权限 [user1@localhost ~]$ chmod 475 123/ [user1@localhost ~]$ ls -l 123/ ls: cannot access 123/abc.txt: Permission denied total 0 -????????? ? ? ? ? ? abc.txt [user1@localhost ~]$ cd 123/ -bash: cd: 123/: Permission denied # 将测试的目录放开执行权限 [user1@localhost ~]$ chmod 575 123/ [user1@localhost ~]$ ls -l 123/ total 0 ----rw-r--. 1 user1 user1 0 Aug 2 00:45 abc.txt [user1@localhost ~]$ cd 123/ [user1@localhost 123]$ ls -l total 0 ----rw-r--. 1 user1 user1 0 Aug 2 00:45 abc.txt ### 开始测试文件 ### [user1@localhost 123]$ cat abc.txt cat: abc.txt: Permission denied [user1@localhost 123]$ echo "abc" > abc.txt -bash: abc.txt: Permission denied [user1@localhost 123]$ rm -rf abc.txt rm: cannot remove ``abc.txt': Permission denied' # 将文件放开读取权限 [user1@localhost 123]$ chmod 464 abc.txt [user1@localhost 123]$ cat abc.txt # 将文件放开编写权限 [user1@localhost 123]$ chmod 664 abc.txt [user1@localhost 123]$ echo "abc" > abc.txt [user1@localhost 123]$ cat abc.txt abc # 删除该文件 [user1@localhost 123]$ rm -rf abc.txt rm: cannot remove ``abc.txt'': Permission denied ### 开始进行测试目录2 ### [user1@localhost 123]$ cd .. # 将测试的目录放开编写权限 [user1@localhost ~]$ chmod 775 123/ # 成功删除目录内文件 [user1@localhost ~]$ rm -rf 123/abc.txt [user1@localhost ~]$ ls -l 123/abc.txt ls: cannot access 123/abc.txt: No such file or directory- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
5.4 所有者和所属组命令
5.4.1 chown 命令
chown是修改文件和目录的所有者和所属组的命令,其基本信息如下。
- 命令名称:chown
- 英文原意:change file owner and group
- 所在路径:/bin/chown
- 执行权限:所有用户
- 功能描述:修改文件和目录的所有者和所属组
1)命令格式
# chown [选项] 所有者:所属组 文件或者目录 选项: -R :递归设置权限,也就是给子目录中的所有文件设置权限 # 新安装的系统,里面拥有大量的系统用户,登录的用户只有root,和初始化系统时创建的用户- 1
- 2
- 3
- 4
- 5
普通用户不能修改文件的所有者,哪怕自己是这个文件的所有者也不行。只有超级用户才能修改文件或者目录的所有者
普通用户可以修改所有者是自己的文件的权限。
~ useradd user1 ~ echo "123456" | passwd --stdin user1 ~ chown user1 abc.txt ~ ls -l abc.txt -rwxr-xr-x. 1 user1 root 0 Aug 1 23:27 abc.txt ~ chgrp user1 abc.txt ~ ls -l abc.txt -rwxr-xr-x. 1 user1 user1 0 Aug 1 23:27 abc.txt # 在linux系统中创建的用户默认会创建同名的用户组。而在Windows中创建的用户是加入到 User 组中 # chown <用户>[:|.]<用户组> [文件或者目录] ~ chown root:root abc.txt ~ ls -l abc.txt -rwxr-xr-x. 1 root root 0 Aug 1 23:27 abc.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
普通用户可以修改所有者为自己的文件的权限。
普通用户不能修改文件的所有者(哪怕文件是属于这个普通用户的),只有超级用户才能修改所有者和所属组。
5.5 umask 默认权限
5.5.1 查看系统的 umask 权限
[root@localhost ~]#umask 0022 # 用八进制数值显示 umask 权限 [root@localhost ~]#umask -S u=rwx,g=rx,o=rx # 用字母表示文件和目录的初始权限- 1
- 2
- 3
- 4
- 5
- 6
5.5.2 umask 权限的计算方法
我们需要先了解一下新建文件和目录的默认最大权限。
- 对文件来讲,新建文件的默认最大权限是666,没有执行(x)权限。这是因为执行权限对文件来讲比较危险,不能在新建文件的时候默认赋予,而必须通过用户手工赋予。
- 对目录来讲,新建目录的默认最大权限是777。这是因为对目录而言,执行(x)权限仅仅代表进入目录,所以即使建立新文件时直接默认赋予,也没有什么危险。
按照官方的标准算法,umask 默认权限需要使用二进制进行逻辑与和逻辑非联合运算才可以得到正确的新建文件和目录的默认权限。这种方法既不好计算,也不好理解,并不推荐。
我们在这里还是按照权限字母来讲解umask权限的计算方法。我们就按照默认的umask值是022来分别计算一下新建文件和目录的默认权限吧。
- 文件的默认权限最大只能是666,而umask的值是022–>“-rw-rw-rw-” 减去"-----w–w-“等于”-rw-r–r–"
- 目录的默认权限最大可以是777,而umask的值是022–>"drwxrwxrwx"减去"d----w–w-“等于"drwx-r-xr-x”
注意:umask 默认权限的计算绝不是数字直接相减。
例如umask是033呢?
- 文件的默认权限最大只能是666,而umask的值是033
- “-rw-rw-rw-“减去”-----wx-wx"等于”-rw-r–r–”
# 环境变量配置文件 ~ vim /etc/profile if [ $UID -gt 199 ] && [ "`/usr/bin/id -gn`" = "`/usr/bin/id -un`" ]; then umask 002 else umask 022 fi- 1
- 2
- 3
- 4
- 5
- 6
- 7
六、帮助命令
6.1 man 命令
man是最常见的帮助命令,也是Linux最主要的帮助命令,其基本信息如下。
- 命令名称:man
- 英文原意:format and display the on-line manual pages
- 所在路径:/usr/bin/man
- 执行权限:所有用户
- 功能描述:显示联机帮助手册
6.1.1 命令格式
# man [选项] 命令 选项: -f :查看命令拥有哪个级别的帮助 -k :查看和命令相关的所有帮助- 1
- 2
- 3
- 4
6.1.2 man 命令的快捷键
快捷键 作用 上箭头 向上移动一行 下箭头 向下移动一行 PgUp 向上翻一页 PgDn 向下翻一页 g 移动到第一页 G 移动到最后一页 q 退出 /字符串 从当前页向下搜索字符串 ?字符串 从当前页向上搜索字符串 n 当搜索字符串时,可以使用n键找到下一个字符串 N 当搜索字符串时,使用N键反向查询字符串。也就是说,如果使用“!字符串”方式搜索,则N键表示向上搜索字符串;如果使用“?字符串”方式搜索,则N键表示向下搜索字符串 ~ man ls- 1
6.1.3 man 命令的帮助级别
级别 作用 1 普通用户可以执行的轻统命令和可执行文件的帮助(绝大部分的命令只有1级别帮助,1级别和5级别的命令和相关的配置文件是少数) 2 内核可以调用的函数和工具的帮助 3 C语言函数的帮助 4 设备和特殊文件的帮助 5 配置文件的帮助 6 游戏的帮助(个人版的Linux中是有游戏的) 7 杂项的帮助 8 超级用户可以执行的系统命令的帮助 9 内核的帮助 man -f 命令 或者 whatis 命令(需要使用数据库 makewhatis)
#查看命令拥有哪个级别的帮助
man -k 命令 或者 apropos 命令
#查看和命令相关的所有帮助
# 更新man帮助的数据库 mandb # man 的使用 man -f passwd & [whatis passwd] man -k passwd & [apropos passwd] # 查看内置命令 man cd- 1
- 2
- 3
- 4
- 5
- 6
- 7

6.2 info 命令
info 命令的帮助信息是一套完整的资料,每个单独命令的帮助信息只是这套完整资料中的某一个小章节。
快捷键 作用 上箭头 向上移动一行 下箭头 向下移动一行 PgUp 向上翻一页 PgDn 向下翻一页 Tab 在有 “*” 符号的节点间进行切换 回车 进入有 “*” 符号的子页面,查看详细帮助信息 u 进入上一层信息(回车是进入下一层信息) n 进入下一小节信息 p 进入上一小节信息 ? 查看帮助信息 q 退出 info 信息 6.3 help 命令
help只能获取Shell内置命令的帮助
help命令的基本信息如下:
- 命令名称:help
- 英文原意:help
- 所在路径:Shell内置命令。
- 执行权限:所有用户。
- 功能描述:显示Shell内置命令的帮助。可以使用type命令来区分内置命令与外部命令
Shell 是 Linux的命令解释器。
# 内置命令 [root@localhost ~]# type type type is a shell builtin [root@localhost ~]# help type ...... # 外部命令 [root@localhost ~]# type mkdir mkdir is hashed (/bin/mkdir) [root@localhost ~]# help mkdir bash: help: no help topics match `mkdir'. Try `help help' or `man -k mkdir' or `info mkdir'.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6.4 --help 选项
绝大多数命令都可以使用“–help”选项来查看帮助,这也是一种获取帮助的方法。例如:
[root@localhost~]#ls --help- 1
这种方法非常简单,输出的帮助信息基本上是man命令的信息简要版。
对于这4种常见的获取帮助的方法,大家可以按照自己的习惯任意使用。
七 搜索命令
7.1 whereis 命令
whereis是搜索系统命令的命令(像绕口令一样),也就是说,whereis命令不能搜索普通文件,而只能搜索系统命令。whereis命令的基本信息如下。
- 命令名称:whereis
- 英文原意:locate the binary, source,and manual page files for a command
- 所在路径:/usr/bin/whereis
- 执行权限:所有用户
- 功能描述:查找二进制命令、源文件和帮助文档的命令
7.2 which 命令
which也是搜索系统命令的命令。和 whereis命令的区别在于:
- whereis 命令可以在查找到二进制命令的同时,查找到帮助文档的位置;
- 而 which 命令在查找到二进制命令的同时,如果这个命令有别名,则还可以找到别名命令。
~ which ls alias ls='ls --color=auto' /usr/bin/ls # 查看系统所有的命令别名 ~ alias alias cdnet='cd /etc/sysconfig/network-scripts/' alias cdyum='cd /etc/yum.repos.d/' alias cp='cp -i' alias disepel='sed -ri /enabled/s/enabled=1/enabled=0/ /etc/yum.repos.d/base.repo' alias egrep='egrep --color=auto' alias epel='sed -ri /enabled/s/enabled=0/enabled=1/ /etc/yum.repos.d/base.repo' alias fgrep='fgrep --color=auto' alias i.='ls -d .* --color=auto' alias l.='ls -d .* --color=auto' alias lh='ls -lh --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto' alias more='more -d' alias mv='mv -i' alias nm='systemctl restart NetworkManager' alias p='poweroff' alias restart='systemctl restart ' alias restartnet='systemctl restart network' alias rm='rm -i' alias scandisk='echo "- - -" > /sys/class/scsi_host/host0/scan;\ echo "- - -" > /sys/class/scsi_host/host1/scan;\ echo "- - -" > /sys/class/scsi_host/host2/scan' alias vie0='vim /etc/sysconfig/network-scripts/ifcfg-eth0' alias vie1='vim /etc/sysconfig/network-scripts/ifcfg-eth1' alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde' alias xzfgrep='xzfgrep --color=auto' alias xzgrep=' xzgrep --color=auto' alias yr='yum remove' alias yy='yum -y install' alias zegrep='zegrep --color=auto' alias zfgrep='zfgrep --color=auto' alias zgrep='zgrep --color=auto'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
which 命令的基本信息如下。
- 命令名称:which
- 英文原意:shows the full path of (shell) commands
- 所在路径:/usr/bin/which
- 执行权限:所有用户
- 功能描述:列出命令的所在路径。
7.3 locate 命令
7.3.1 基本用法
locate命令才是可以按照文件名搜索普通文件的命令。
优点:按照数据库搜索,搜索速度快,消耗资源小。数据库位置/var/lib/mlocate/mlocate.db(需要使用特别的命令查看该文件)
缺点:只能按照文件名来搜索文件,而不能执行更复杂的搜索,比如按照权限、大小、修改时间等搜索文件。
locate 命令的基本信息如下。
- 命令名称:locate
- 英文原意:find files by name
- 所在路径:/usr/bin/locate
- 执行权限:所有用户
- 功能描述:按照文件名搜索文件。
7.3.2 配置文件
~ vim /etc/updatedb.conf # 开启搜索限制,也就是让这个配置文件生效 PRUNE_BIND_MOUNTS = "......" # 在 locate 执行搜索时,禁止搜索这些文件系统类型 PRUNEFS = "......" # 在 locate 执行搜索时,禁止搜索带有这些扩展名的文件 PRUNENAMES = "......" # 在 locate 执行搜索时,禁止搜索这些系统目录 PRUNEPATHS = "......"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

范例:locate 命令的使用
# CentOS 系统使用 yum install -y mlocate # 更新 locate 数据库 updatedb # 使用 passwd 内容 locate passwd # CentOS 7默认禁止搜索目录 # /afs /media /mnt /net /sfs /tmp /udev # /var/cache/ccache /var/lib/yum/yumdb /var/spool/cups /var/spool/squid /var/tmp /var/lib/ceph- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.4 find 命令
find命令的基本信息如下:
- 命令名称:find
- 英文原意:search for files in a directory hierarchy
- 所在路径:/bin/find
- 执行权限:所有用户
- 功能描述:在目录中搜索文件
7.4.1 按照文件名搜索
# find 搜索路径 [选项] 搜索内容 选项: -name :按照文件名搜索 -iname:按照文件名搜索,不区分文件大小写 -inum :按照 inode 号搜索- 1
- 2
- 3
- 4
- 5
范例:
# 在实际生产环境中,尽量避免搜索整个 / 根目录 ~ find / -name "abc.txt" /root/abc.txt ~ find / -iname "abc.txt" /root/ABC.txt /root/abc.txt ~ ls -i abc.txt 1836779 abc.txt ~ ln abc.txt /tmp/abc_h.txt ~ find / -inum "1836779" -ls 1836779 0 -rwxr-xr-x 2 root root 0 Aug 1 23:27 /tmp/abc_h.txt 1836779 0 -rwxr-xr-x 2 root root 0 Aug 1 23:27 /root/abc.txt # find 命令运行的时候产生的一些临时文件 find: `/proc/33087/task/33087/fd/5': No such file or directory find: `/proc/33087/task/33087/fdinfo/5': No such file or directory find: `/proc/33087/fd/5': No such file or directory find: `/proc/33087/fdinfo/5': No such file or directory- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
7.4.2 按照文件大小搜索
# find 搜索路径 [选项] 搜索内容 选项: -size [+|-]大小:按照指定大小搜索文件 # 这里的"+"的意思是搜索比指定大小还要大的文件,"-"的意思是搜索比指定大小还要小的文件- 1
- 2
- 3
- 4
find 命令的单位
# man find -size n[cwbkMG] File uses n units of space. The following suffixes can be used: ‘b’ for 512-byte blocks (this is the default if no suffix is used) # 这里默认单位,如果单位为b或者不写单位,则按照512 Byte搜索 ‘c’ for bytes # 搜索单位是c,按照字节搜索 ‘w’ for two-byte words # 搜索单位是w,按照双字节(中文)搜索 ‘k’ for Kilobytes (units of 1024 bytes) # 按照 KB 单位搜索,必须是小写的k ‘M’ for Megabytes (units of 1048576 bytes) # 按照 MB 单位搜索,必须是大写的M ‘G’ for Gigabytes (units of 1073741824 bytes) # 按照 GB 单位搜索,必须是大写的G The size does not count indirect blocks, but it does count blocks in sparse files that are not actually allocated. Bear in mind that the ‘%k’ and ‘%b’ format specifiers of -printf handle sparse files differ- ently. The ‘b’ suffix always denotes 512-byte blocks and never 1 Kilo- byte blocks, which is different to the behaviour of -ls.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
范例:
~ find . -size 50k -ls 1835010 56 -rw-r--r-- 1 root root 50968 Jun 19 17:31 ./install.log ~ find . -size -10k -ls # 搜索比 20Mi 小的文件 ~ find . -size -20M -ls # 搜索比 25字节 小的文件 ~ find . -size -25c -ls 1844697 4 -rw-r--r-- 1 root root 18 May 20 2009 ./.bash_logout 1842265 4 -rw-r--r-- 1 root root 20 Aug 2 04:44 ./abc # 搜索正好 20字节 的文件 ~ find . -size 20c -ls 1844726 4 -rw-r--r-- 1 root root 20 Aug 2 04:52 ./abc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
7.4.3 按照修改时间搜索
Linux 中的文件有访问时间(atime)、数据修改时间(mtime)、状态修改时间(ctime)这三个时间,我们也可以按照时间来搜索文件。
# find 搜索路径 [选项] 搜索内容 选项: -atime [+|-]时间 :按照文件访问时间搜索 -mtime [+|-]时间 :按照文件数据修改时间搜索 -ctime [+|-]时间 :按照文件状态修改时间搜索- 1
- 2
- 3
- 4
- 5
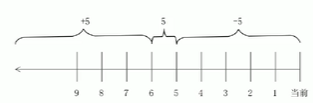
这三个时间的区别我们在stat命令中已经解释过了,这里用mtime数据修改时间来举例,重点说说“[±]”时间的含义。(并不会有未来时间)
- -5 :代表5天内修改的文件。
- 5 :代表前5~6天那一天修改的文件。
- +5 :代表6天前修改的文件。
我们画一个时[间轴,来解释一下。如图所示
范例:
# 搜索3天之内的修改时间 ~ find / -mtime -3 # 搜索3-4天之间的修改时间 ~ find / -mtime 3 # 搜索4天之前的修改时间 ~ find / -mtime +3- 1
- 2
- 3
- 4
- 5
- 6
7.4.4 按照权限搜索
find 用于权限的搜索几率不大。需要使用之后方可查找相关的帮助即可。
命令格式:
# find 搜索路径 [选项] 搜索内容 选项: -perm 权限模式 :查找文件权限刚好等于"权限模式"的文件 -perm -权限模式 :查找文件权限全部包含"权限模式"的文件 -perm +权限模式 :查找文件权限包含"权限模式"的任意一个权限的文件- 1
- 2
- 3
- 4
- 5
范例:
find . -perm 644 -ls ~ mkdir test ; cd test ~ touch hjk ; touch uio ~ chmod 600 uio # +权限模式:在所有者,所属组,其他人的权限有一个匹配,就匹配 ~ find . -perm +444 -ls 1844723 4 drwxr-xr-x 2 root root 4096 Aug 2 05:07 . 1844724 0 -rw-r--r-- 1 root root 0 Aug 2 05:07 ./hjk 1844727 0 -rw------- 1 root root 0 Aug 2 05:07 ./uio # -权限模式:在所有者,所属组,其他人的权限都要能够满足匹配,就匹配。有一个权限不匹配就不匹配 ~ find . -perm -444 -ls 1844723 4 drwxr-xr-x 2 root root 4096 Aug 2 05:07 . 1844724 0 -rw-r--r-- 1 root root 0 Aug 2 05:07 ./hjk- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
7.4.5 按照所有者和所属组搜索
# find 搜索路径 [选项] 搜索内容 选项: -uid 用户ID :按照用户ID查找所有者是指定ID的文件 -gid 组ID :按照用户组ID查找所属组是指定ID的文件 -user 用户名 :按照用户名查找所有者是指定用户的文件 -group 组名 :按照组名查找所属组是指定用户组的文件 -nouser :查找没有所有者的文件- 1
- 2
- 3
- 4
- 5
- 6
- 7
按照所有者和所属组搜索时,“-nouser”选项比较常用,主要用于查找垃圾文件。
只有一种情况例外,那就是外来文件。比如光盘和U盘中的文件如果是由Windows复制的,在Linux中查看就是没有所有者的文件;再比如手工源码包安装的文件,也有可能没有所有者。
~ find . -user root -ls 1844723 4 drwxr-xr-x 2 root root 4096 Aug 2 05:07 . 1844724 0 -rw-r--r-- 1 root root 0 Aug 2 05:07 ./hjk 1844727 0 -rw------- 1 root root 0 Aug 2 05:07 ./uio ~ find / -nouser -ls- 1
- 2
- 3
- 4
- 5
- 6
7.4.6 按照文件类型搜索
# find 搜索路径 [选项] 搜索内容 选项: -type d :查找目录 -type f :查找普通文件 -type l :查找软链接文件- 1
- 2
- 3
- 4
- 5
范例:
find . -type d -ls find . -type f -ls find . -type l -ls- 1
- 2
- 3
7.4.7 逻辑运算符
# find 搜索路径 [选项] 搜索内容 选项: -a :and 逻辑与 -o :or 逻辑或 -not :not 逻辑非- 1
- 2
- 3
- 4
- 5
逻辑与:
- 1 与 1 结果是 1
- 1 与 0 结果是 0
- 0 与 1 结果是 0
- 0 与 0 结果是 0
逻辑或:
- 1 或 1 结果是 1
- 1 或 0 结果是 1
- 0 或 1 结果是 1
- 0 或 0 结果是 0
1)-a:and 逻辑与
find 命令也支持逻辑运算符选项,其中-a代表逻辑与运算,也就是 -a 的两个条件都成立,find搜索的结果才成立。举个例子:
find . size +2k -a type f # 在当前目录下搜索大于2KB,并且文件类型是普通文件的文件- 1
- 2
范例:
# 搜索当前目录下大于1KB,并且文件类型是普通文件的文件 find . -size +1k -a -type f -ls- 1
- 2
2)-o:or 逻辑或
-o选项代表逻辑或运算,也就是-o的两个条件只要其中一个成立,find命令就可以找到结果。例如:
find . -name cangls -o -name bols # 在当前目录下搜索文件名要么是cangls 的文件,要么是bols 的文件- 1
- 2
范例:
# 搜索大于1KB的所有类型,或者文件类型是普通文件 find . -size +1k -o -type f -ls- 1
- 2
3)-not:not 逻辑非
-not是逻辑非,也就是取反的意思。举个例如:
find . -not -name cangls # 在当前目录下搜索文件名不是 cangls 的文件- 1
- 2
范例:
find . ! -name abc -ls 等同于 find . -not -name abc -ls- 1
- 2
- 3
7.4.8 其他选项
1)-exec选项
这里我们主要讲解两个选项“-exec”和“-ok”,这两个选项的基本作用非常相似。我们先来看看“-exec”选项的格式。
find 搜索路径 [选项] 搜索内容 -exec 命令2 {} \; # 使用 -exec 就必须要有 命令 {} \;- 1
- 2
其次,这个选项的作用其实是把 find命令的结果交给由“-exec”调用的命令2来处理。“{}”就代表find命令的查找结果。
范例:
find . -not -name abc -exec ls -l {} \; find . -size +1k -a -type f -exec ls -lh {} \; # exec 只能识别标准命令,无法识别命令别名 # 下列命令不会提示,直接删除 find /var/log -mtime +10 -exec rm -f {} \;- 1
- 2
- 3
- 4
- 5
2)-ok 选项
“-ok”选项和“-exec”选项的作用基本一致,区别在于:“-exec”的命令﹖会直接处理,而不询问;“-ok”的命令2在处理前会先询问用户是否这样处理,在得到确认命令后,才会执行。
find /var/log -mtime +10 -ok rm -f {} \;- 1
7.5 grep 命令:补充命令
grep 的作用是在文件中提取和匹配符合条件的字符串行。命令格式如下:
grep [选项] "搜索内容" 文件名 选项: -i :忽略大小写 -n :输出行号 -v :反向查找 --color=auto :搜索出的关键字用颜色显示 # 写出三层以上的循环,除了做算法,是不是考虑代码有问题- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
find也是搜索命令,那么find命令和grep命令有什么区别呢?
1)find 命令
find命令用于在系统中搜索符合条件的文件名,如果需要模糊查询,则使用通配符进行匹配。搜索时文件名是完全匹配的(find命令可以通过-regex选项,把匹配规则转为正则表达式规则,但是不建议如此)。
范例:
# 查找当前目录下的 abc 开头的文件 find . -name "abc*" -a -type f -exec ls -l {} \; # 查找当前目录下的 a和c 中间未知的文件 find . -name "a?c" -a -type f -exec ls -l {} \; # 查找当前目录下的 a和c 中间是b或者c的文件 find . -name "a[bc]c" -a -type f -exec ls -l {} \; # 查找当前目录下的 a和c 中间不是 b 的文件 find . -name "a[^b]c" -a -type f -exec ls -l {} \;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2)grep 命令
grep命令用于在文件中搜索符合条件的字符串,如果需要模糊查询,则使用正则表达式进行匹配。搜索时字符串是包含匹配的。
范例:
# 查找文件中的含有 123 的行 grep "123" abc # 查找文件中含有 a 的行 grep "a.*" abc # 查找文件中 a 开头的行 grep "^a.*" abc # 查找文件中还含有 aa 的行 grep "aa.\?" abc grep -E "aa.?" abc # grep "3aa.\?b" abc # 查找文件中数字结尾的行 grep "[0-9]$" abc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3)通配符与正则表达式的区别
通配符:用于匹配文件名,完全匹配
通配符 所用 ? 匹配一个任意字符,不能匹配空字符 * 匹配0个或者任意多个任意字符,也就是可以匹配任何内容 [] 匹配中括号中任意一个字符,例如,[abc]代表一定匹配一个字符,或者是a,或者是b,或者是c [-] 匹配中括号中任意一个字符,-代表一个范围,例如,[a-z]代表一个小写字母,[A-Z]代表一个大写字母 [^] 逻辑非,表示匹配不是中括号内的一个字符,例如,[^0-9]代表匹配一个不是数字的字符 正则表达式:用于匹配字符串,包含匹配
正则符 所用 . 代表任意的一个字符 ? 匹配前一个字符重复 0 次,或者 1 次 * 匹配前一个字符重复 0 次,或者任意多次 [] 匹配中括号中任意一个字符,例如,[abc]代表一定匹配一个字符,或者是a,或者是b,或者是c [-] 匹配中括号中任意一个字符,-代表一个范围,例如,[a-z]代表一个小写字母,[A-Z]代表一个大写字母 [^] 逻辑非,表示匹配不是中括号内的一个字符,例如,[^0-9]代表匹配一个不是数字的字符 ^ 匹配行首 $ 匹配行尾 说明:
.* 代表匹配任意内容
^$ 代表匹配的空行
7.6 管道符:补充命令
命令格式:命令1 | 命令2
命令1 的正确输出作为 命令2的操作对象。管道符其实是 文本流
1)例子1:
举个例子,我们经常需要使用“ls -l”命令查看文件的长格式,不过在有些目录中文件众多,比如:/etc/ 目录,使用“II”命令显示的内容就会非常多,只能看到最后的内容,而不能看到前面输出的内容。这时我们马上想到 more 命令可以分屏显示文件内容,可是怎么让 more命令分屏显示命令的输出呢?我想到了一种笨办法:
# 方式1:使用输出重定向 ~ ls -al /etc/ > /root/etc.txt # 用输出重定向,把 ll 命令的输出保存到 /root/etc.txt 文件中 ~ more /root/etc.txt # 既然 etc.txt 是文件,当然可以用 more 命令分屏显示了 ......- 1
- 2
- 3
- 4
- 5
- 6
- 7
可是这样操作实在不方便,这时就可以利用管道符了。命令如下:
# 方式2:使用管道符 ls -l /etc/ | more- 1
- 2
2)例子:
我想在命令/etc/的结果中搜索yum的文件名,应该使用find命令?还是grep命令?
ls -al /etc/ | grep yum- 1
3)例子:
netstat 命令(CentOS 7中,需要安装net-snmp.x86_64,net-tools.x86_64两个包才有此命令。7.5系统中已经自动安装)格式如下:
[ root@localhost ~]# netstat [选项] 选项: -a :列出所有网络状态﹐包括socket程序 -c 秒数 :指定每隔几秒刷新一次网络状态 -n :使用IP地址和端口号显示,不使用域名与服务名 -p :显示PID和程序名 -t :显示使用TCP协议端口的连接状况 -u :显示使用UDP协议端口的连接状况 -l :仅显示监听状态的连接 -r :显示路由表- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
范例:
netstat -auntlp | grep "ESTABLISHED" | wc -l # 如果想知道具体的网络连接数量,就可以再使用 wc 命令统计行数- 1
- 2
IP 地址可以确认服务器的位置,服务器上的服务如何确认,就需要端口来确认。

7.7 命令的别名:补充命令
命令的别名,就是命令的小名,主要是用于照顾管理员使用习惯的。尽量不要占用 系统原始命令。
命令格式: ~ alias # 查询命令的别名(临时生效) ~ alias 别名="原命令" # 设定命令的别名 # 例如: alias ser="service network restart" # 用 ser 别名,替换 service network restart 命令- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
用命令定义的别名,是临时生效的,要想永久生效,需要写入环境变量配置文件~/.bashrc,/etc/profile 全局变量配置文件。
alias cdnet='cd /etc/sysconfig/network-scripts/' alias cdyum='cd /etc/yum.repos.d/' alias cp='cp -i' alias disepel='sed -ri /enabled/s/enabled=1/enabled=0/ /etc/yum.repos.d/base.repo' alias egrep='egrep --color=auto' alias epel='sed -ri /enabled/s/enabled=0/enabled=1/ /etc/yum.repos.d/base.repo' alias fgrep='fgrep --color=auto' alias i.='ls -d .* --color=auto' alias l.='ls -d .* --color=auto' alias lh='ls -lh --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto' alias more='more -d' alias mv='mv -i' alias nm='systemctl restart NetworkManager' alias p='poweroff' alias restart='systemctl restart ' alias restartnet='systemctl restart network' alias rm='rm -i' alias scandisk='echo "- - -" > /sys/class/scsi_host/host0/scan;\ echo "- - -" > /sys/class/scsi_host/host1/scan;\ echo "- - -" > /sys/class/scsi_host/host2/scan' alias vie0='vim /etc/sysconfig/network-scripts/ifcfg-eth0' alias vie1='vim /etc/sysconfig/network-scripts/ifcfg-eth1' alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde' alias xzfgrep='xzfgrep --color=auto' alias xzgrep=' xzgrep --color=auto' alias yr='yum remove' alias yy='yum -y install' alias zegrep='zegrep --color=auto' alias zfgrep='zfgrep --color=auto' alias zgrep='zgrep --color=auto' alias grep='grep --color=auto'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
7.8 常用的快捷键:补充命令
快捷键 命令 Tab键 命令或者文件补全 Ctrl + A 把光标移动到命令行开头。如果我们输入的命令过长,想要把光标移动到命令行开头时使用。 Ctrl + E 把光标移动到命令行结尾。 Ctrl + C 强制终止当前的命令。 Ctrl + L 清屏,相当于clear命令。 Ctrl + U 删除或剪切光标之前的命令。我输入了一行很长的命令,不用使用退格键一个一个字符的删除,使用这个快捷键会更加方便 Ctrl + Y 粘贴ctrl+U剪切的内容。 Ctrl + D 删除命令的后一个字符 八 压缩和解压缩命令
在Linux 中可以识别的常见压缩格式有十几种,比如".zip"、“.gz”、“.bz2”、“.tar”、“.tar.gz”、".tar.bz2"等。
8.1 ".zip"格式
“.zip”是Windows 中最常用的压缩格式,Linux也可以正确识别“.zip”格式,这可以方便地和Windows系统通用压缩文件。
8.1.1 ".zip"格式的压缩命令
压缩命令就是zip,其基本信息如下。
- 命令名称:zip。
- 英文原意:package and compress (archive) files。
- 所在路径:/usr/bin/zip。
- 执行权限:所有用户。
- 功能描述:压缩文件或目录。
命令格式如下:
zip [选项] 压缩报名 源文件或者源目录 # 选项: -r :压缩目录 # 例如: ~ zip boot.zip -r /boot/- 1
- 2
- 3
- 4
- 5
8.1.2 ".zip"格式的解压缩命令
".zip”格式的解压缩命令是unzip,其基本信息如下
- 命令名称: unzip。
- 英文原意: list, test and extract compressed files in a ZIP archive。
- 所在路径:/usr/bin/unzip。
- 执行权限:所有用户。
- 功能描述:列表、测试和提取压缩文件中的文件。
命令格式如下:
unzip [选项] 压缩包名 # 选项: -d :指定解压缩的位置 # 例如: ~ unzip -d /tmp/ boot.zip- 1
- 2
- 3
- 4
- 5
8.2 “.gz” 格式
gzip 是不会打包。
8.2.1 ".gz"格式的压缩命令
“.gz”格式是Linux中最常用的压缩格式,使用gzip命令进行压缩,其基本信息如下。
- 命令名称:gzip。
- 英文原意:compress or expand files。
- 所在路径:/bin/gzip。
- 执行权限:所有用户。
- 功能描述:压缩文件或目录。会将源文件删除,并且生成相应的压缩包。并且默认不保留源文件。
这个命令的格式如下:
gzip [选项] 源文件 # 选项 -c :将压缩数据输出到标准输出中,可以用于保留源文件 -d :解压缩 -r :压缩目录 # 例如: ~ gzip -c install.log > install_log.gz # 使用 -c 选项,但是不让压缩数据输出到屏幕上,而是重定向到压缩文件中 # 这样可以再压缩文件的同时不删除源文件- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
8.2.2 ".gz"格式的解压缩命令
如果要解压缩“.gz”格式,那么使用“gzip -d 压缩包”和“gunzip 压缩包”命令都可以。我们先看看gunzip 命令的基本信息。
- 命令名称:gunzip。
- 英文原意:compress or expand files。
- 所在路径:/bin/gunzip。
- 执行权限:所有用户。
- 功能描述:解压缩文件或目录。
# 例如: gunzip install_log.gz gzip -d install_log.gz- 1
- 2
- 3
两个命令都可以解压缩".gz"格式
8.3 ".bz2"格式
bz2 不能压缩目录
8.3.1 “.bz2” 格式的压缩命令
“.bz2”格式是Linux 的另一种压缩格式,从理论上来讲,“.bz2”格式的算法更先进、压缩比更好;而“.gz”格式相对来讲压缩的时间更快。
“.bz2”格式的压缩命令是bzip2,我们来看看这个命令的基本信息。
- 命令名称:bzip2。
- 英文原意:a block-sorting file compressor。
- 所在路径:/ust/bin/bzip2。
- 执行权限:所有用户。
- 功能描述:.bz2格式的压缩命令。
来看看 bzip2命令的格式。
bzip2 [选项] 源文件 选项: -d :解压缩 -v :显示压缩的详细信息 -k :压缩时,保留源文件- 1
- 2
- 3
- 4
- 5
例如:
# 压缩成 bz2 格式 ~ bzip2 install.log # 保留源文件压缩 ~ bzip2 -k install.log- 1
- 2
- 3
- 4
8.3.2 ".bz2"格式的解压缩命令
“.bz2”格式可以使用“bzip2 -d压缩包”命令来进行解压缩,也可以使用“bunzip2压缩包”命令来进行解压缩。先看看bunzip2命令的基本信息。
- 命令名称:bunzip2。
- 英文原意:a block-sorting file compressor。
- 所在路径:/usr/bin/bunzip2。
- 执行权限:所有用户。
- 功能描述:.bz2格式的解压缩命令。
bunzip2 install.log.bz2 bzip2 -d install.log.bz2 # 两个命令都可以解压缩- 1
- 2
- 3
8.4 ".tar"格式
打包不会压缩
8.4.1 ".tar"格式的打包命令
".tar”格式的打包和解打包都使用tar命令,区别只是选项不同。我们先看看tar命令的基本信息
- 命令名称:tar。
- 英文原意:tar。
- 所在路径:/bin/tar。
- 执行权限:所有用户。
- 功能描述:打包与解打包命令。
命令的基本格式如下:
[root@localhost]# tar [选项] [-f压缩包名] 源文件或目录 选项: -c :打包 -f :指定压缩包的文件名。压缩包的扩展名是用来给管理员识别格式的,所以一定要正确指定扩展名 -v :显示打包文件过程- 1
- 2
- 3
- 4
- 5
范例:
# 打包,不会压缩 ~ tar -cvf install.log.tar install.log # 查看tar包的内容 ~ tar -tf install.log.tar install.log- 1
- 2
- 3
- 4
- 5
8.4.2 "tar"格式的解打包命令
“".tar”格式的解打包也需要使用tar命令,但是选项不太一样。命令格式如下:
~ tar [选项] 压缩包 # 选项 -x :解打包 -f :指定压缩包的文件名 -v :显示接打包的文件过程 -t :测试,就是不解打包,只是查看包中有哪些文件 -C(大) 目录:指定解打包的位置 # 例如 ~ tar -xvf install.log.tar- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
8.4.3 “.tar.gz” 和 “.tar.bz2” 格式
使用 tar 命令直接打包压缩,命令格式如下:
~ tar [选项] 压缩包 源文件或者目录 # 或者: -z :压缩和解压缩".tar.gz"格式 -j :压缩和解压缩".tar.bz2"格式 -J :压缩和解压缩".tar.xz"格式- 1
- 2
- 3
- 4
- 5
例如:.tar.gz 格式
# 把 /tmp/ 目录直接打包压缩成 ".tar.gz" 格式 ~ tar -zcvf tmp.tar.gz /tmp/ # 解压缩与解打包 ".tar.gz" 格式 ~ tar -zxvf tmp.tar.gz- 1
- 2
- 3
- 4
例如:.tar.bz2 格式
# 把 /tmp/ 目录直接打包压缩成 ".tar.bz2" 格式 ~ tar -jcvf tmp.tar.bz2 /tmp/ # 解压缩与解打包 ".tar.bz2" 格式 ~ tar -jxvf tmp.tar.bz2- 1
- 2
- 3
- 4
例如:.tar.xz 格式
# 把 /tmp/ 目录直接打包压缩成 ".tar.xz" 格式 ~ tar -jcvf tmp.tar.xz /tmp/ # 解压缩与解打包 ".tar.xz" 格式 ~ tar -jxvf tmp.tar.xz- 1
- 2
- 3
- 4
再举几个例子
# 建立测试目录和测试文件 mkdir test touch test/{abc,bcd,cde} # 压缩 tar -zcvf test.tar.gz test/ # 只查看,不解压 tar -tvf test.tar.gz # 解压缩到指定位置 tar -zxvf test.tar.gz -C /tmp # 只解压压缩包中的特定文件,到指定位置 tar -zxvf test.tar.gz -C /tmp test/cde- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
九 关机和重启
9.1 sync 数据同步
sync命令的基本信息如下。
- 命令名称:sync。
- 英文原意:flush file system buffers。
- 所在路径:/bin/sync。
- 执行权限:所有用户。
- 功能描述:刷新文件系统缓冲区。
9.2 shutdown 命令
shutdown命令的基本信息如下。
- 命令名称:shutdown。
- 英文原意:bring the system down。
- 所在路径:/sbin/shutdown。
- 执行权限:超级用户。
- 功能描述:关机和重启。
命令的基本格式如下:
~ shutdown [选项] 时间 [警告信息] # 选项: -c :取消已经执行的 shutdown 命令 -h :关机 -r :重启- 1
- 2
- 3
- 4
- 5
范例:
~ shutdown -r 5:30 & # 放入后台进程运行 ~ shutdown -c- 1
- 2
- 3
9.3 reboot 命令
在现在的系统中,reboot命令也是安全的,而且不需要加入过多的选项。服务器的重启尽量不要使用。
reboot- 1
9.4 halt 和 poweroff 命令
这两个都是关机命令,直接执行即可。这两个命令不会完整关闭和保存系统的服务,不建议使用。
halt # 关机 poweroff # 关机- 1
- 2
- 3
- 4
9.5 init 命令
init 是修改Linux运行级别的命令,也可以用于关机和重启。这个命令并不安全,不建议使用。
# 关机,也就是调用系统的 0 级别 ~ init 0 # 重启,也就是调用系统的 6 级别 ~ init 6- 1
- 2
- 3
- 4
十 常用网络命令
10.1 配置 IP 地址
10.1.1 配置 IP 地址
IP地址是计算机在互联网中唯一的地址编码。每台计算机如果需要接入网络和其他计算机进行数据通信,就必须配置唯一的公网IP地址。
配置IP地址有两种方法:
\1) setup工具(Redhat / CentOS 系列专有)
\2) vi /etc/sysconfig/network-scripts/ifcfg-eth0
手工修改配置文件
10.1.2 重启网络服务
service network restart # 重启网络服务 # 重启网络服务失败: # IP地址冲突 # MAC地址冲突 # NetworkManager 服务关闭- 1
- 2
- 3
- 4
- 5
- 6
- 7
10.1.3 虚拟机需要桥接到有线网卡,并重启网络服务
10.1.4 复制镜像有可能需要重置 UUID(唯一识别符)
~ vi /etc/sysconfig/network-scripts/ifcfg-eth0 # 删除Mac地址行 ~ rm -rf /etc/udev/rules.d/70-persistent-net.rules # 删除Mac地址和UUID绑定文件 ~ reboot # 重启Linux- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
10.2 ifconfig 命令
- 命令名称:ifconfig
- 英文原意:configure a network interface。
- 所在路径:/sbin/ifconfig。
- 执行权限:超级用户。
- 功能描述:配置网络接口
ifconfig 命令最主要的作用就是查看 IP 地址的信息,直接输入ifconfig 命令即可
~ ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 # 标准 最大传输单元 inet 10.0.0.30 netmask 255.255.255.0 broadcast 10.0.0.255 # IP地址 子网掩码 广播地址 inet6 fe80::20c:29ff:fe94:7b4c prefixlen 64 scopeid 0x20<link> # IPv6地址(目前没有生效) ether 00:0c:29:94:7b:4c txqueuelen 1000 (Ethernet) # MAC地址 RX packets 55890 bytes 73119558 (69.7 MiB) RX errors 0 dropped 0 overruns 0 frame 0 # 接收的数据包情况 TX packets 17982 bytes 1758172 (1.6 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # 发送的数据包情况 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 # 本地回环网卡,用于测试本地网卡是否正常 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 507 bytes 81959 (80.0 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 507 bytes 81959 (80.0 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
10.3 ping 命令
ping 是常用的网络命令,主要通过ICMP协议进行网络探测,测试网络中主机的通信情况。ping命令的基本信息如下。
- 命令名称:ping。
- 英文原意:send ICMP ECHO_REQUEST to network hosts。
- 所在路径:/bin/ping。
- 执行权限:所有用户。
- 功能描述:向网络主机发送ICMP请求。
命令的基本格式如下:
ping [选项] IP # 选项: -b :后面加入广播地址,用于对整个网段进行探测 -c 次数:用于指定 ping 的次数 -s 字节:指定探测包的大小 # 例如 ~ ping -c 2 www.baidu.com PING www.baidu.com (183.232.231.174) 56(84) bytes of data. 64 bytes from 183.232.231.174 (183.232.231.174): icmp_seq=1 ttl=128 time=13.3 ms 64 bytes from 183.232.231.174 (183.232.231.174): icmp_seq=2 ttl=128 time=19.6 ms --- www.baidu.com ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 5058ms rtt min/avg/max/mdev = 13.305/16.452/19.600/3.150 ms- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
例子:探测网段中的可用主机
在ping命令中,可以使用“-b”选项,后面加入广播地址,探测整个网段。我们可以使用这个选项知道整个网络中有多少主机是可以和我们通信的,而不用一个一个P地址地进行探测。例如:
~ ping -b -c 3 10.0.0.255 WARNING: pinging broadcast address PING 10.0.0.255 (10.0.0.255) 56(84) bytes of data. 64 bytes from 10.0.0.10: icmp_seq=1 ttl=128 time=0.152 ms 64 bytes from 10.0.0.20: icmp_seq=1 ttl=128 time=0.319 ms 64 bytes from 10.0.0.30: icmp_seq=1 ttl=128 time=0.400 ms ...省略部分内容...- 1
- 2
- 3
- 4
- 5
- 6
- 7
#探测 10.0.0.0/24 网段中有多少可以通信的主机
10.4 netstat 命令
netstat是网络状态查看命令,既可以查看到本机开启的端口,也可以查看有哪些客户端连接。
在CentOS 7.x 中 netstat 命令默认没有安装,如果需要使用,需要安装net-snmp和net-tools 软件包。
netstat命令的基本信息如下。
- 命令名称:netstat。
- 英文原意:Print network connections,routing tables,interface statistics,masquerade connections,and multicast memberships 。
- 所在路径:/bin/netstat。
- 执行权限:所有用户。
- 功能描述:输出网络连接、路由表、接口统计、伪装连接和组播成员。
命令格式如下:
~ netstat [选项] # 选项: -a :列出所有网络状态,包括socket程序 -c 秒数 :指定每隔几秒刷新―次网络状态 -n :使用IF地址和端口号显示,不使用域名与服务名 -p :显示PID 和程序名 -t :显示使用TCP协议端口的连接状况 -u :显示使用UDP协议端口的连接状况 -l :仅显示监听状态的连接 -r :显示路由表- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
例子1:查看本机开启的端口
这是本机最常用的方式,使用选项“-tuln”。因为使用了“-l”选项,所以只能看到监听状态的连接,而不能看到已经建立连接状态的连接。例如:
~ netstat -tuln Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN tcp6 0 0 :::111 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN tcp6 0 0 ::1:25 :::* LISTEN udp 0 0 0.0.0.0:940 0.0.0.0:* udp 0 0 0.0.0.0:111 0.0.0.0:* udp6 0 0 :::940 :::* udp6 0 0 :::111 :::* # 协议 接收队列 发送队列 本机的IP地址及端口号 远程主机的IP地址及端口号 状态- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这个命令的输出较多。
- Proto:网络连接的协议,一般就是TCP协议或者UDP协议。
- Recv-Q:表示接收到的数据,已经在本地的缓冲中,但是还没有被进程取走。
- Send-Q:表示从本机发送,对方还没有收到的数据,依然在本地的缓冲中,一般是不具备ACK标志的数据包。
Recv-Q 和 Send-Q 排队的数据包,当队列的数值越大,说明该端口比较繁忙。
-
Local Address:本机的P地址和端口号。
-
Foreign Address:远程主机的P地址和端口号。
-
State:状态。常见的状态主要有以下几种。
-
- LISTEN:监听状态,只有TCP协议需要监听,而UDP协议不需要监听。
- ESTABLISHED:已经建立连接的状态。如果使用“-1”选项,则看不到已经建立连接的状态。
- SYN_SENT:SYN发起包,就是主动发起连接的数据包。
- SYN_RECV:接收到主动连接的数据包。
- FIN_WAIT1:正在中断的连接。
- FIN_WAIT2:已经中断的连接,但是正在等待对方主机进行确认。
- TIME_WAIT:连接已经中断,但是套接字依然在网络中等待结束。
在这些状态中,我们最常用的就是LISTEN和ESTABLISHED状态,一种代表正在监听,另一种代表已经建立连接。
例子2:查看本机有哪些程序开启的端口
如果使用“-p”选项,则可以查看到是哪个程序占用了端口,并且可以知道这个程序的 PID。例如:
~ netstat -tulnp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 768/rpcbind tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 974/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1370/master tcp6 0 0 :::111 :::* LISTEN 768/rpcbind tcp6 0 0 :::22 :::* LISTEN 974/sshd tcp6 0 0 ::1:25 :::* LISTEN 1370/master udp 0 0 0.0.0.0:940 0.0.0.0:* 768/rpcbind udp 0 0 0.0.0.0:111 0.0.0.0:* 768/rpcbind udp6 0 0 :::940 :::* 768/rpcbind udp6 0 0 :::111 :::* 768/rpcbind # 比之前的命令多了一个"-p"选项,结果多了"PID/程序名",可以知道是哪个程序占用了端口- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
例子3:查看所有连接
使用选项“-an”可以查看所有连接,包括监听状态的连接(LISTEN)、已经建立连接状态的连接(ESTABLISHED) 、Socket程序连接等。因为连接较多,所以输出的内容有很多。例如:
netstat -an Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN tcp 0 36 10.0.0.30:22 10.0.0.1:11072 ESTABLISHED tcp 0 0 10.0.0.30:22 10.0.0.1:2704 ESTABLISHED tcp 0 0 10.0.0.30:22 10.0.0.1:2709 ESTABLISHED tcp6 0 0 :::111 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN tcp6 0 0 ::1:25 :::* LISTEN # ...省略部分内容... Active UNIX domain sockets (servers and established) Proto RefCnt Flags Type State I-Node Path unix 3 [ ] DGRAM 11532 /run/systemd/notify # ...省略部分内容...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
从“Active UNIX domain sockets”开始,之后的内容就是Socket程序产生的连接,之前的内容都是网络服务产生的连接。我们可以在“-an”选项的输出中看到各种网络连接状态,而之前的“-tuln”选项则只能看到监听状态。
例子3:查看本机的路由表信息
~ netstat -rn ~ route -n ~ ip route- 1
- 2
- 3
10.5 write 命令
Linux 登录终端:
本地字符终端:tty 1-6 (使用快捷键:Alt + F1 - F6)
本地图形终端:tty 7 (Ctrl+Alt+F7 按住3秒,需要安装启动图形界面)
远程终端: pts/0-255
write命令的基本信息如下。
- 命令名称:write。
- 英文原意:send a message to another user。
- 所在路径:/usr/bin/write。
- 执行权限:所有用户。
- 功能描述:向其他用户发送信息。
# 查看当前系统的所有用户的终端 ~ w | # 或者使用 who 命令查看 10:37:22 up 1:48, 4 users, load average: 0.00, 0.01, 0.05 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root pts/0 10.0.0.1 Thu17 16:41m 0.00s 0.00s -bash root pts/1 10.0.0.1 Thu17 16:35m 0.01s 0.01s -bash root pts/2 10.0.0.1 09:14 2.00s 0.04s 0.00s w root pts/3 10.0.0.1 09:14 58.00s 0.05s 0.05s -bash # 查看当前系统的用户的终端类型 ~ tty /dev/pts/2 # 发送指定的信息到远程终端 ~ write root pts/1 hello I will be in 5 minutes to restart, please save your data # 向在 pts/1(远程终端1)登录的 user1 用户发送信息,使用 "Ctrl+D"快捷键保存发送的数据- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 发送方

- 被接收端的界面信息

10.6 wall 命令
write 命令用于给指定用户发送信息,而 wall命令用于给所有登录用户发送信息,包括你自己。执行时,在 wall命令后加入需要发送的信息即可,例如:
wall "I will be in 5 minutes to restart, please save your data"- 1

10.7 mail 命令
mail 是Linux的邮件客户端命令,可以利用这个命令给其他用户发送邮件。mail命令的基本信息如下。
- 命令名称:mail。
- 英文原意:send and receive Internet mail。
- 所在路径:/bin/mail。
- 执行权限:所有用户。
- 功能描述:发送和接收电子邮件。
例子1:发送邮件
如果我们想要给其他用户发送邮件,则可以执行如下命令:
[root@localhost ~] # mail user1 Subject: hello <-邮件标题 Nice to meet you ! <-邮件具体内容 . <-使用"."来结束邮件输入 # 发送邮件给user1用户- 1
- 2
- 3
- 4
- 5
- user1 用户查看邮件

例子2:发送文件内容
如果我们想把某个文件的内容发送给指定用户,则可以执行如下命令:
~ mail -s "test mail" root < /root/anaconda-ks.cfg # 选项: -s :指定邮件标题 # 把 /root/anaconda-ks.cfg 文件的内容发送给 root 用户- 1
- 2
- 3
- 4
我们在写脚本时,有时需要脚本自动发送一些信息给指定用户,把要发送的信息预先写到文件中,是一个非常不错的选择。
例子3:查看已经接收的邮件
我们可以直接在命令行中执行 mail 命令,进入 mail 的交互命令中,可以在这里查看已经接收到的邮件。例如:
~ mail Heirloom Mail version 12.4 7/29/08. Type ? for help. "/var/spool/mail/user1": 1 message 1 new >N 1 root Wed Aug 3 00:58 18/647 "hello" # 未阅读 编号 发件人 时间 标题 & <- 等待用户输入命令- 1
- 2
- 3
- 4
- 5
- 6
可以看到已经接收到的邮件列表,“N”代表未读邮件,如果是已经阅读过的邮件,则前面是不会有这个“N”的;之后的数字是邮件的编号,我们主要通过这个编号来进行邮件的操作。如果我们想要查看第一封邮件,则只需输入邮件的编号“1”就可以了。
在交互命令中执行“?”,可以查看这个交互界面支持的命令。例如:
& ? <- 输入命令 mail commands type <message list> type messages next goto and type next message from <message list> give head lines of messages headers print out active message headers delete <message list> delete messages undelete <message list> undelete messages save <message list> folder append messages to folder and mark as saved copy <message list> folder append messages to folder without marking them write <message list> file append message texts to file, save attachments preserve <message list> keep incoming messages in mailbox even if saved Reply <message list> reply to message senders reply <message list> reply to message senders and all recipients mail addresses mail to specific recipients file folder change to another folder quit quit and apply changes to folder xit quit and discard changes made to folder ! shell escape cd <directory> chdir to directory or home if none given list list names of all available commands A <message list> consists of integers, ranges of same, or other criteria separated by spaces. If omitted, mail uses the last message typed.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
这些交互命令是可以简化输入的,比如“headers”命令,就可以直接输入“h”,这是列出邮件标题列表的命令。我们解释一下常用的交互命令。
- headers:列出邮件标题列表,直接输入“h”命令即可。
- delete:删除指定邮件。比如想要删除第二封邮件,可以输入“d 2”。
- save:保存邮件。可以把指定邮件保存成文件,如“s 2 /tmp/test.mail”。
- quit:退出,并把已经操作过的邮件进行保存。比如移除已删除邮件、保存已阅读邮件等。
- exit:退出,但是不保存任何操作。
十一 系统痕迹命令
系统中有一些重要的痕迹日志文件,如/var/log/wtmp、/var/run/utmp、/var/log/btmp 、/var/log/lastlog 等日志文件,如果你用 vim 打开这些文件,你会发现这些文件是二进制乱码。这是由于这些日志中保存的是系统的重要登录痕迹,包括某个用户何时登录了系统,何时退出了系统,错误登录等重要的系统信息。这些信息要是可以通过vim打开,就能编辑,这样痕迹信息就不准确,所以这些重要的痕迹日志,只能通过对应的命令来进行查看。
11.1 w 命令
w命令是显示系统中正在登陆的用户信息的命令,这个命令查看的痕迹日志是/var/run/utmp。这个命令的基本信息如下:
- 命令名称:w
- 英文原意:Show who is logged on and what they are doing.
~ w 01:16:43 up 1 day, 8:04, 2 users, load average: 0.00, 0.00, 0.00 # 系统时间 持续开机时间 登录用户 系统在1分钟,5分钟,15分钟前的平均负载 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root pts/0 10.0.0.1 23:30 7:45 0.11s 0.11s -bash root pts/1 10.0.0.1 00:58 0.00s 0.19s 0.16s w- 1
- 2
- 3
- 4
- 5
- 6
第一行信息,内容如下:
内容 说明 12:26:46 系统当前时间 up 1 day,13:32 系统的运行时间,本机已经运行1天13小时32分钟 2 users 当前登录了两个用户 load average: 0.00,0.00,0.00 系统在之前1分钟、5分钟、15分钟的平均负载。如果CPU是单核的,则这个数值超过 1 就是高负载;如果CPU是四核的,则这个数值超过4就是高负载(这个平均负载完全是依据个人经验来进行判断的,一般认为不应该超过服务器CPU的核数) CPU / 内存的占用率原则:指的是 70/90,CPU 不能超过占有70%,内存不能超过占用 90%。
第二行信息,内容如下:
内容 说明 USER 当前登陆的用户 TTY 登陆的终端:(1)tty1-6:本地字符终端(alt+F1-6切换)(2)tty7:本地图形终端(ctrl+alt+F7切换,必须安装启动图形界面)(3)pts/0-255:远程终端 FROM 登陆的IP地址,如果是本地终端,则是空 LOGIN@ 登陆时间 IDLE 用户闲置时间 JCPU 所有的进程占用的CPU时间 PCPU 当前进程占用的CPU时间 WHAT 用户正在进行的操作 10.2 who 命令
who 命令和w命令类似,用于查看正在登陆的用户,但是显示的内容更加简单,也是查看/var/run/utmp日志。
~ who root pts/0 2022-08-02 23:30 (10.0.0.1) root pts/1 2022-08-03 00:58 (10.0.0.1) # 用户名 登录终端 登录时间(来源IP)- 1
- 2
- 3
- 4
10.3 last 命令
last命令是查看系统所有登陆过的用户信息的,包括正在登陆的用户和之前登陆的用户。这个命令查看的是 /var/log/wtmp 痕迹日志文件。
~ last root pts/1 10.0.0.1 Wed Aug 3 00:58 still logged in root pts/0 10.0.0.1 Tue Aug 2 23:30 still logged in root pts/0 10.0.0.1 Tue Aug 2 13:28 - 22:53 (09:25) root pts/1 10.0.0.1 Tue Aug 2 03:32 - 15:30 (11:58) reboot system boot 2.6.32-754.el6.x Mon Jun 20 09:17 - 09:32 (00:15) # 系统重启信息记录 root pts/0 10.0.0.1 Fri Jun 24 15:18 - 16:47 (01:28) # 用户名 终端号 来源IP地址 登录时间 - 退出时间- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
10.4 lastlog 命令
lastlog 命令是查看系统中所有用户最后一次的登陆时间的命令,他查看的日志是 /var/log/lastlog 文件。
~ lastlog Username Port From Latest root pts/1 10.0.0.1 Wed Aug 3 00:58:04 +0800 2022 bin **Never logged in** daemon **Never logged in** adm **Never logged in** lp **Never logged in** sync **Never logged in** ...省略部分内容... # 用户名 终端 来源IP 登录时间- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
10.5 lastb 命令
lastb命令是查看错误登陆的信息的,查看的是/var/log/btmp痕迹日志:
[root@localhost ~]# lastb (unknown ttyl Mon Nov 12 23:58 - 23:58(00:00) root tty1 Mon Nov 12 23:58 - 23:58(00:00) # 错误登陆用户 终端 尝试登陆的时间 # 查看错误登录用户,例如输入用户密码错误等信息- 1
- 2
- 3
- 4
- 5
十二 挂载命令
12.1 mount 命令基本格式
linux所有存储设备都必须挂载使用,包括硬盘。SWAP 空间是不需要挂载点的,内核直接访问。
挂载:将设备文件名和已经建立的空目录进行对接的过程就是挂载。如果是非空的目录进行挂载,那么原有目录的数据内容将会被隐藏。原理是将目录的挂载点抽出来,作为一个分区使用。
- 命令名称:mount
- 命令所在路径:/bin/mount
- 执行权限:所有用户
在Linux 系统中Disk 硬盘是可以开机自动挂载(官方推荐),而在U盘等移动设备则是不推荐进行开机自动挂载的操作。
RHEL 5之前的版本修改 /etc/fstab 是十分的脆弱,只要修改错误一个标点符号,就会导致开机启动失败。
RHEL 6以后的版本修改 /etc/fstab 功能已经增强,例如文件系统 ext4 修改为 ex4,开机启动也不会导致启动失败。功能有所增强。mount -a 即使没有报错也会仔细检查 /etc/fstab 的文件内容。
说了这么多,命令的具体格式如下:
~ mount -l # 查询系统中已经挂载的设备,-l 会显示卷边名称 ~ mount -a # 依据配置文件 /etc/fstab 的内容,自动挂载 ~ mount [-t 文件系统] [-L 卷标名] [-o 特殊选项] \ 设备文件名 挂载点 # \ 代表这一行没有写完,换行 # 选项 -t 文件系统 :加入文件系统类型来指定挂载的类型,可以ext3、ext4、iso9660等文件系统。具体可以参考表 -L 卷标名 :挂载指定卷标的分区,而不是安装设备文件名挂载 -o 特殊选项 :可以指定挂载的额外选项,比如读写权限、同步异步等,如果不指定则默认值生效。具体的特殊选项,见表:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
参数 说明 atime/noatime 更新访问时间/不更新访问时间。访问分区文件时,是否更新文件的访问时间,默认为更新 async/sync 异步/同步,默认为异步 auto/noauto 自动/手动,mount - a命令执行时,是否会自动安装/etc/fstab文件内容挂载,默认为自动 defaults 定义默认值,相当于rw,suid, dev, exec, auto, nouser, async这七个选项 exec/noexec 执行/不执行,设定是否允许在文件系统中执行可执行文件,默认是exec允许。noexec 的属性若添加到相关的分区中,会使得该分区的所有的可执行文件无法执行,若添加到启动分区会导致系统启动失败,导致崩溃。 remount 重新挂载已经挂载的文件系统,一般用于指定修改特殊权限 rw/ro 读写/只读,文件系统挂载时,是否具有读写权限,默认是rw suid/nosuid 具有/不具有SUID权限,设定文件系统是否具有SUID和SGID的权限,默认是具有SUID user/nouser 允许/不允许普通用户挂载,设定文件系统是否允许普通用户挂载,默认是不允许,只有root可以挂载分区 usrquota 写入代表文件系统支持用户磁盘配额,默认不支持 grpquota 写入代表文件系统支持组磁盘配额,默认不支持 举例:
# 例子1: ~ mount # 查看系统中已经挂载的文件系统,注意有虚拟文件系统 /dev/mapper/vg_centos6server-lv_root on / type ext4 (rw) proc on /proc type proc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0") /dev/sda1 on /boot type ext4 (rw) /dev/mapper/vg_centos6server-lv_home on /home type ext4 (rw) /dev/sr0 on /mnt/cdrom type iso9660 (ro) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) # 命令结果是代表:/dev/sda1 分区挂载到 / 目录,文件协调 ext4,权限是读写模式 # 例子2:修改特殊权限 ~ mount | grep boot # 我们查看到 /boot 分区已经被挂载,而且采用的 defaults 选项,那么我们重新挂载分区,并采用 noexec # 权限禁止执行文件执行,看看会出现什么情况(注意不要用 / 分区做试验,#不然系统命令也不能执行了) /dev/sda1 on /boot type ext4 (rw) ~ mount -o remount,noexec /boot # 重新挂载 /boot 分区,并使用 noexec 权限 ~ mount | grep boot /dev/sda1 on /boot type ext4 (rw,noexec) ~ cd /boot # 写个shell脚本 ~ vim /boot/hello.sh #!/bin/bash echo "hello!!!" ~ chmod 755 /boot/hello.sh ~ ./hello.sh -bash: ./hello.sh: Permission denied # 虽然赋予了 hello.sh 执行权限,但是仍然无法执行 ~ mount -o remount,exec /boot # 记得改回来,要不会影响系统的启动的,可以使用绝对路径或者相对路径运行脚本 ~ ./hello.sh hello!!!- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
如果我们做了试验修改了特殊选项,一定要记住,而且确定需要修改,否则非常容易出现系统问题,而且还找不到哪里出现了问题。
# 挂载分区 ~ mkdir /mnt/disk1 # 建立挂载点目录 ~ mount /dev/sdb1 /mnt/disk1 # 挂载分区- 1
- 2
- 3
- 4
- 5
12.2 光盘挂载
系统在根目录下创建了三个空目录用于移动设备的挂载:
/media:用于挂载光盘
/mnt:用于挂载U盘或者移动硬盘
/misc:挂载网络存储盘
光盘挂载的前提依然是指定光盘的设备文件名,不同版本的Linux,设备文件名并不相同:
- CentOS 5.x 以前的系统,光盘设备文件名是 /dev/hdc。容易出现光盘设备文件名和硬盘设备文件名冲突。
- CentOS 6.x 以后的系统,光盘设备文件名是 /dev/sr0。
不论哪个系统都有软连接/dev/cdrom,与可以作为光盘的设备文件名4 4
~ ls -l /dev/cdrom /dev/sr0 lrwxrwxrwx. 1 root root 3 Jun 26 23:20 /dev/cdrom -> sr0 brw-rw----+ 1 root cdrom 11, 0 Jun 26 23:20 /dev/sr0 ~ mkdir -pv /mnt/cdrom ~ mount -t iso9660 /dev/cdrom /mnt/cdrom # 挂载光盘,推荐使用 /dev/sr0 进行挂载,如果Linux系统没有完全启动,加入修复模式或者安全模式,那么软链接/dev/cdrom 将会失效。 # 所以尽量使用源文件进行挂载。 ~ df -Th | grep /dev/sr0 /dev/sr0 iso9660 3.8G 3.8G 0 100% /mnt/cdrom- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
用完之后记得卸载:
umount /dev/sr0 umount /mnt/cdrom # 因为设备文件名和挂载点已经连接在一起,卸载哪一个都可以 # 若在光盘还没有卸载的情况下,使用 VMware Workstation 软件将光盘文件进行替换,那么就会出现光盘故障的情况。 # 直到出现由VMware Workstation 软件自身的 vmtools 工具在挂载目录中。 # 解决方法:将VMware Workstation 的光驱移除后重新添加- 1
- 2
- 3
- 4
- 5
- 6
注意:卸载的时候需要退出光盘目录,才能正常卸载。
12.3 挂载U盘
若U盘的传输协议是 USB 3.0 ,则可能需要在VMware 中设置–>USB 控制器–>连接–>USB兼容性 -->USB3.0,防止虚拟机不识别的情况。

Windows 安装 VMware 后,会生成多个服务,尽量使其产生的服务正常稳定的运行,否则会导致后期出现BUG问题。
U盘会和硬盘共用设备文件名,所以U盘的设备文件名不是固定的,需要手工查询,查询命令:
~ fdisk -l # 查询已识别硬盘- 1
- 2

然后就是挂载了,挂载命令如下:
mkdir -pv /mnt/usb mount -t vfat /dev/sdb1 /mnt/usb # 挂载U盘,因为是 Windows 分区,所以是 vfat 文件系统格式- 1
- 2
- 3
如果U盘中有中文,会发现中文是乱码。Linux 要想正常显示中文,需要两个条件:
- 安装了中文编码和中文字体
- 操作终端需要支持中文显示(纯字符终端,是不支持中文编码的)
# 查看本地终端字符集是否满足中文 ~ echo $LANG en_CN.UTF-8- 1
- 2
- 3
而我们当前系统是安装了中文编码和字体,而 Xshell远程终端是Windows下的程序,当然是支持中文显示的。那之所以挂载U盘还出现乱码,是需要在挂载的时候,手工指定中文编码,例如:
# vfat 代表的是 fat32 的文件系统 # fat32 文件系统不支持单个文件最大 4GB 的限制 mount -t vfat -o iocharset=utf8 /dev/sdb1 /mnt/usb # 挂载U盘,指定中文编码格式为 UTF-8- 1
- 2
- 3
- 4
如果需要卸载,可以执行以下命令:
umount /mnt/usb- 1
范例:NTFS 挂载 Linux 系统
### Linux 系统默认是不识别 NTFS 的文件系统 ### Mac 系统是可以识别 NTFS 的文件系统,但是为只读的权限,不能进行写入操作 # 安装插件(需要配置 EPEL 源进行安装) yum install -y ntfs-3g # 或者从服务器下载 wget http://tuxera.com/opensource/ntfs-3g_ntfsprogs-2013.1.13.tgz tar -xvf ntfs-3g_ntfsprogs-2013.1.13.tgz cd ntfs-3g_ntfsprogs-2013.1.13 ./configure make && make install # 挂载 mount -t ntfs-3g /dev/sdb1 /mnt/usb- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14


12.4 挂载 NTFS
12.4.1 Linux 的驱动加载顺序
- 驱动直接放入系统内核之中。这种驱动主要是系统启动加载必须的驱动,数量较少。驱动若变多,则会使得系统的内核变大,启动和加载的速度变慢。
- 驱动以模块的形式放入硬盘。大多数驱动都已这种方式保存,保存位置在/lib/modules/3.10.0-862.el7.x86 64/kernel/中。
~ ls -l /lib/modules/3.10.0-1160.el7.x86_64/kernel/ total 16 drwxr-xr-x. 3 root root 17 Nov 22 2021 arch drwxr-xr-x. 3 root root 4096 Nov 22 2021 crypto drwxr-xr-x. 72 root root 4096 Nov 22 2021 drivers drwxr-xr-x. 26 root root 4096 Nov 22 2021 fs drwxr-xr-x. 3 root root 19 Nov 22 2021 kernel drwxr-xr-x. 4 root root 249 Nov 22 2021 lib drwxr-xr-x. 2 root root 35 Nov 22 2021 mm drwxr-xr-x. 34 root root 4096 Nov 22 2021 net drwxr-xr-x. 12 root root 173 Nov 22 2021 sound drwxr-xr-x. 3 root root 17 Nov 22 2021 virt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 驱动可以被Linux 识别,但是系统认为这种驱动一般不常用,默认不加载。如果需要加载这种驱动,需要重新编译内核,而NTFS文件系统的驱动就属于这种情况。
- 硬件不能被Linux内核识别,需要手工安装驱动。当然前提是厂商提供了该硬件针对Linux的驱动,否则就需要自己开发驱动了。(需要嵌入式工程师对 Linux 内核进行再次重新编译安装)
12.4.2 使用 NTFS-3G 安装 NTFS 文件系统模块
下载 NTFS-3G 插件
我们从网站 http://www.tuxera.com/community/ntfs-3g-download/ 下载 NTFS-3G插件到Linux服务器上的。
wget http://tuxera.com/opensource/ntfs-3g_ntfsprogs-2013.1.13.tgz # 解压 tar -xvf ntfs-3g_ntfsprogs-2013.1.13.tgz # 进入到解压目录 cd ntfs-3g_ntfsprogs-2013.1.13 # 编译器准备,没有指定安装目录,安装到默认位置 ./configure # 编译,编译安装 make && make install- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
安装就完成了,已经可以挂载和使用 Windows 的NTFS分区了。不过需要注意挂载分区时的文件系统不是ntfs,而是ntfs-3g。挂载命令如下:
mount -t ntfs-3g 分区设备文件名 挂载点 # 例如:ntfs-3g 就是对应于 NTFS 的文件系统 mount -t ntfs-3g /dev/sdb1 /mnt/usb- 1
- 2
- 3
- 4
十三章 vim 编辑器
13.1 vi 编辑器简介
vim是一个全屏幕纯文本编辑器(不需要鼠标接入,键盘就可以完全所有的操作),是 vi 编辑器(不支持颜色,不支持字体)的增强版,我们主要讲解的是 vim 编辑器。可以利用别名让输入vi命令的时候,实际上执行vim编辑器,例如:
~ alias vi='vim' # 定义别名- 1
- 2
这样定义的别名是临时生效,如果需要永久生效,请放入环境变量配置文件(~/.bashrc)
13.2 vim 的基本使用
13.2.1 vim 的工作模式
vim 工作在三种模式之下:

命令模式:是主要使用快捷键的模式,是我们后面学习的重点,命令模式想要进入输入模式,可以使用以下的方式:
插入命令
命令 作用 a 在光标所在字符后插入 A 在光标所在行尾插入 i 在光标所在字符前插入 I 在光标所在行行首插入 o 在光标下插入新行 O 在光标上插入新行 输入模式:主要用于文本编辑,和记事本类似,输入数据就好。
末行模式(编辑模式):
:w 保存不退出
- :w 新文件名 把文件另存为新文件
:q 不保存退出
:wq 保存退出
:x 当文件没有修改时,是直接退出即可,当文件有修改,则保存并退出。
:! 强制
- :q! 强制不保存退出,用于修改文件之后,不保存数据退出。(当文件修改错误的时候,所有用户都可以使用)
- :wq! 强制保存退出,当文件的所有者或者root用户,对文件没有写权限的时候,强制写入数据使用。(只有 root 用户或者文件的所有者才能使用)
13.2 命令模式操作
13.2.1 移动光标
1)上下左右移动光标
上、下、左、右方向键 移动光标 H、j、k、l 移动光标(左,下,上,右)- 1
- 2
2)把光标移动到文件头或者尾
gg 移动到文件头 G 移动到文件尾(shift+g)- 1
- 2
3)移动到行首或者行尾
^ 移动到行首 $ 移动到行尾- 1
- 2
4)移动到指定行
:n 移动到第几行- 1
这里 n 是数字,准备移动到第几行,就用哪个数字。
13.2.2 删除或剪切
1)删除字母
x 删除单个字母 nx 删除 n 个字母- 1
- 2
n是数字,如果打算从光标位置删除连续的10个字母,可以使用“10x”即可。删除字母并不符合使用习惯,我们更习惯在编辑模式中,用“Backspace”键删除字母。
2)删除整行或者剪切
dd 删除单行 ndd 删除多行 :n1,n2d 删除指定范围的行- 1
- 2
- 3
删除整行或多行,这是比较常用的删除方法。这里的dd 快捷键既是删除,也是剪切。删除内容放入了剪切板,如果不粘贴就是删除,如果粘贴就是剪切。粘贴方法如下:
p 粘贴到光标后 P(大写) 粘贴到光标前- 1
- 2
3)从光标所在行删除到文件尾
是否可以删除整篇文档,vim没有删除整篇文档的快捷键,但是可以这样:
dG 从光标所在行删除到文件尾- 1
“d”是删除行,“G”是文件尾,连起来就是从光标所在行删除到文件尾。如果把光标放在文件首,那么“dG”就变成了删除整篇文档了。
13.2.3 复制
yy 复制单行 nyy 复制多行- 1
- 2
复制之后的粘贴,依然可以使用p键或P(大)键。
13.2.4 撤销
u 撤销 ctrl + r 反撤销- 1
- 2
“u”键能一直撤销到文件打开时的状态,类似Windows 下“ctrl+z”键的作用。
“Ctrl+r”能一直反撤销到最后一次操作状态,类似windows 下“ctrl+y”键的作用。
13.2.5 替换
r 替换光标所在处的字符 R 从光标所在处开始替换字符,按ESC结束(进入到替换模式)- 1
- 2
“r”键替换单一字符,不用进入输入模式,实际使用时,比进入输入模式删除后再修改,要方便。
13.2.6 vim 配置文件
这次末行模式参数设置,多数需要在vim中才能生效。
设置参数 含义 :set nu:set nonu 显示与取消行号。 :syntax on:syntax off 是否依据语法显示相关的颜色帮助。在 Vim中修改相关的配置文件或Shell脚本文件时(如前面示例的脚本/etc/init.d/sshd),默认会显示相应的颜色,用来帮助排错。如果觉得颜色产生了干扰,则可以取消此设置 :set hlsearch:set nohlsearch 设置是否将查找的字符串高亮显示。默认是set hlsearch高亮显示。搜索一个不存在的字符串就可以类似的取消高亮。 :set ruler:set noruler 设置是否显示右下角的状态栏。默认是set ruler显示 :set showmode:set noshowmode 设置是否在左下角显示如“–INSERT–”之类的状态栏。默认是set showmode显示 :set list:set nolist 设置是否显示隐藏字符(Tab键用“^I”表示,回车符用“$”表示)。默认是nolist显示。如果使用set list 显示隐藏字符,类似“cat -A 文件名” vim支持更多的设置参数,可以通过“ :set all ”进行查看。
大家会发现,这些设置参数都只是临时生效,一旦关闭文件再打开,又需要重新输入。如果想要永久生效,需要手工建立vim的配置文件“~/.vimrc”,把你需要的参数写入配置文件就永久生效了。
补充:Windows 下回车符在 Linux 中是用“^M ”符号显示,而不是“ ”符号显示,而不是“ ”符号显示,而不是“”符。这样会导致 Windows 下编辑的程序脚本,无法在 Linux 中执行。这时可以通过命令“dos2unix”,把 Windows 格式转为 Linux 格式,当然反过来“unix2dos”命令就是把 Linux 格式转为 Windows 格式。这两个命令默认没有安装,需要手工安装才能使用。
13.2.7 查找
/查找内容 从光标所在行向下查找 ?查找内容 从光标所在行向上搜索 n 下一个 N 上一个- 1
- 2
- 3
- 4
13.2.8 替换
:1,10s/old/new/g 替换1到10行的所有old为new :%s/old/new/g 替换整个文件的old为new- 1
- 2
替换字符串,我举几个例子:在shell中“#”开头是注释,那我是否可以注释文件的前10行呢?手工一个一个注释很麻烦,那么批量替换吧:
:1,10s/^/#/g 注释1 到 10行 :1,10s/^#//g 取消注释- 1
- 2
而在C语言,PHP 语言等大多数语言中,是使用“//”开头作为注释的,我们当然可以用 vim 来写这些程序语言脚本,那么批量加入“//”注释吧:
:1,10s/^/\/\//g 1到10行,行首加入// :1,10s/^\/\///g 取消1到10行行首的//- 1
- 2
13.3 vim 使用技巧
13.3.1 在 vim 中导入其他文件内容或者命令结果
13.3.1.1 导入其他文件的内容
:r文件名 # 把文件内容导入光标位置- 1
- 2
可以把其他文件的内容导入到光标所在位置
13.3.1.2 在 vim 中执行系统命令
:!命令 # 在 vim 中执行系统命令- 1
- 2
这里只是在vim中执行系统命令,但并不把系统命令的结果写入到文件中。主要用于在文件编辑中,查看系统信息,如时间。
13.3.1.3 导入命令结果
:r!命令 # 在vim中执行系统命令,并把命令结果导入光标所在行- 1
- 2
在 vim 中执行系统命令,并把命令结果导入光标所在行。
13.3.2 设定快捷键
:map 快捷键 快捷键执行的命令 自定义快捷键- 1
- 2
vim 允许自定义快捷键,常用的自定义快捷键如下:
:map ^P I#按“ctrl+p”时,在行首加入注释 :map ^B ^x 按“ctrl+b”时,删除行首第一个字母(删除注释)- 1
- 2
注意:P快捷键不能手工输入,需要执行ctrl+V+P来定义,或ctrl+V,然后ctrl+P。B快捷键也是一样。
13.3.3 字符替换
:ab 源字符 替换为字符 # 字符替换 # 需要将 set nopaste 打印模式关闭- 1
- 2
- 3
在vim编辑中,有时候需要频繁输入某一个长字符串(比如邮箱),这时使用字符串替换,能增加输入效率,例如:
:ab mymail shenchao@163.com # 当碰到"mymail"时,转变为邮箱- 1
- 2
注意:“/源字符”不应设置的太短,否则有可能影响输入。
13.3.4 多文件打开
在 vim 中可以同时打开两个文件,只要执行如下命令:
vim -o abc.txt bcd.txt vim -O abc.txt bcd.txt # -o :小写O会上下分屏打开两个文件 # -O :大写O会左右分屏打开两个文件- 1
- 2
- 3
- 4
这样可以同时打开两个文件,方便操作。如果是“-o”上下打开两个文件,可以通过先按“Ctrl+w”,再按“上下箭头”的方式在两个文件之间切换。
如果是“-O”左右打开两个文件,可以通过先按“Ctrl+w”,再按“左右箭头”的方式在两个文件之间切换。
“Ctrl + w”切换到不同的文件进行编辑。
-
相关阅读:
Web APIs
【站内题解】十六道csdn每日一练Python题解
云安全-云原生基于容器漏洞的逃逸自动化手法(CDK check)
STM32实现六轴姿态测量陀螺仪模块JY61P(标准库与HAL库实现)
计算机毕业设计Java京津冀地区产学研项目管理信息系统2021(源码+系统+mysql数据库+lw文档)
UG\NX二次开发 仿射变换(未缩放向量与缩放向量相加) UF_VEC2_affine_comb
Linux常用命令
docker部署gitlab内存占用过大的解决
【前端1】标签(input),css(选择器),js(Bom,Dom)
mysql主从复制
- 原文地址:https://blog.csdn.net/weixin_40274679/article/details/126573896
