-
Visual Studio 2019 + LibTorch + CUDA11.6 环境配置
-
准备cuda11.6.2 + cudnn8.2.4
本人尝试过,如果此cuda版本配更高版本的cudnn会出问题,比如针对cuda11.6的cudnn,所以我这里下载了针对11.4的cudnn来配合cuda11.6.2。其实cuda版本也有向下兼容的能力。 -
进入pytorch官网 https://pytorch.org/get-started/locally/

由于如图的torch版本太高,1.12.1的,本人尝试了这个源码在visual studio 集成,会出现奇奇怪怪的无法找到函数实现的问题,所以这里使用1.10.2版的libtorch源码,注意,这里,下载的cuda11.3的源码,我的环境是cuda11.6。可能这个版本适合更高版本的visualt studio,我猜。
https://download.pytorch.org/libtorch/cu113/libtorch-win-shared-with-deps-1.10.2%2Bcu113.zip- 1
.
3. 使用visual studio创建C++程序控制台项目
右键项目属性->VC++目录->包含目录,添加如下两个libtorch源码下的包含目录
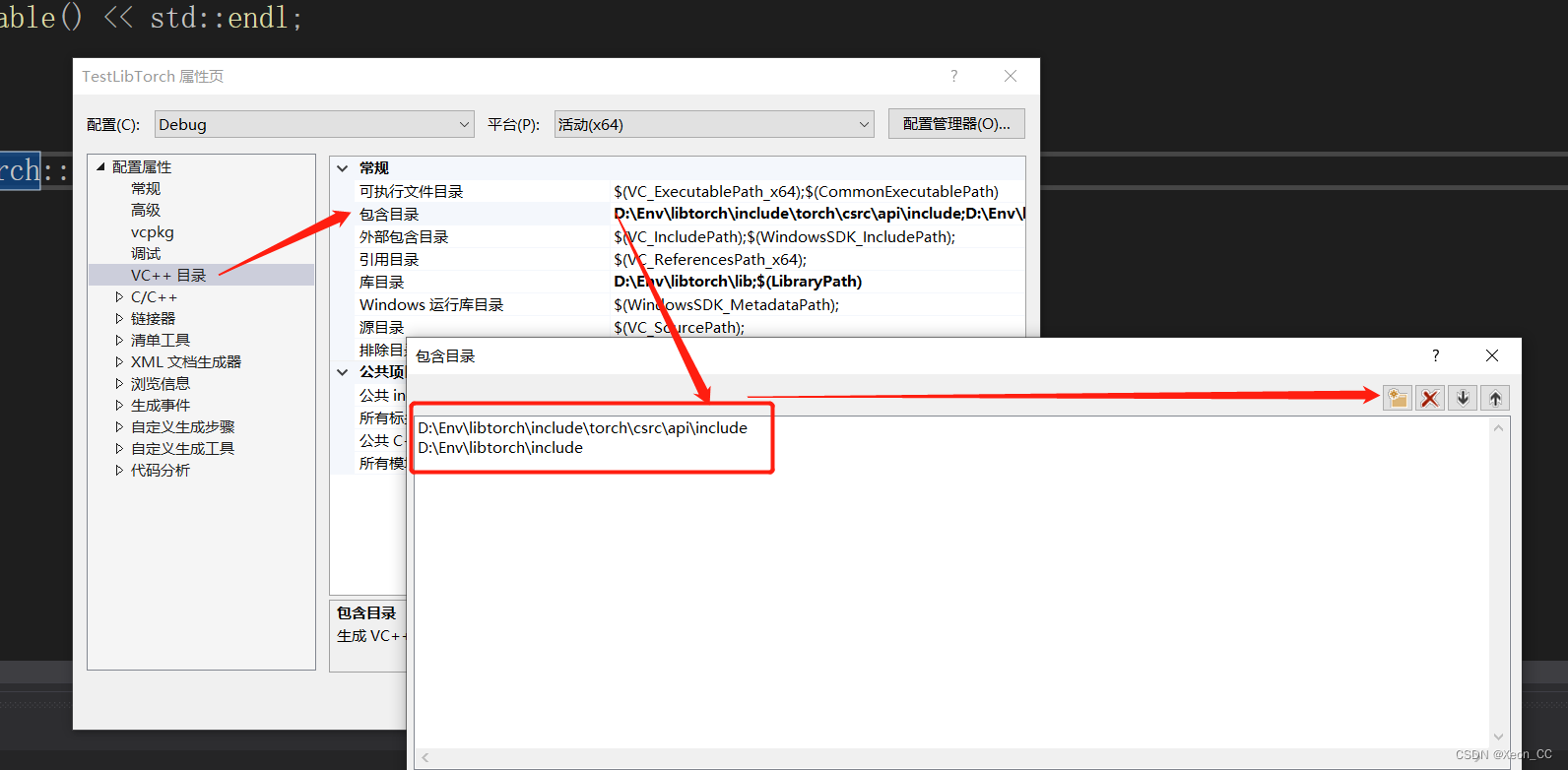
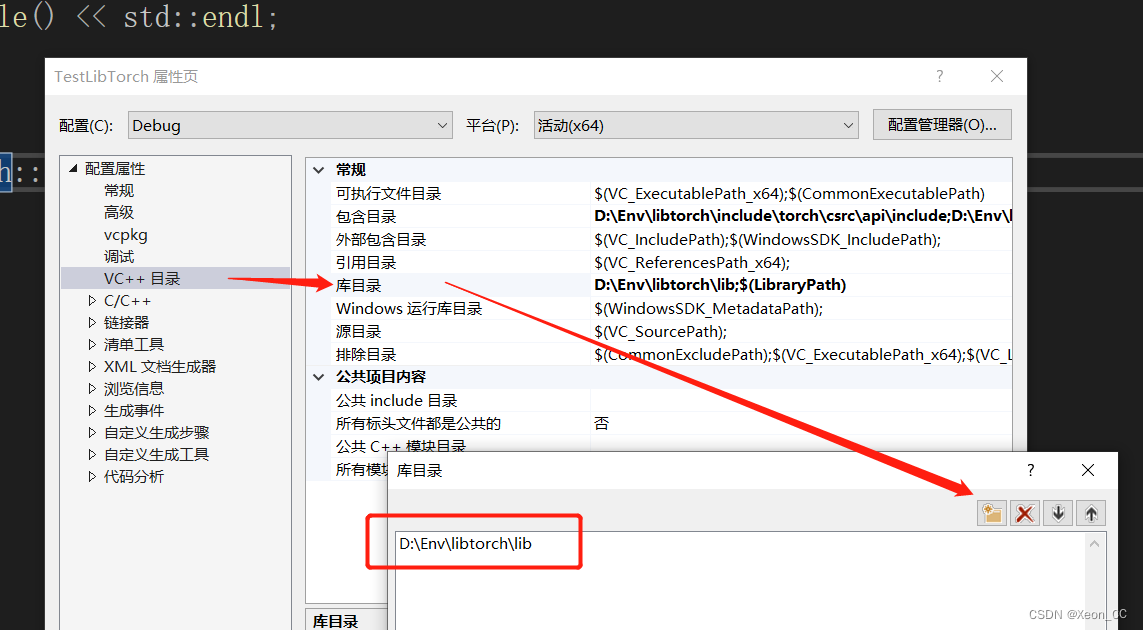
加入库目录:
将C++标准改为C++17

在链接器->输入->附加依赖项,添加 D:\Env\libtorch\lib 目录下的所有lib文件asmjit.lib c10.lib c10_cuda.lib caffe2_detectron_ops_gpu.lib caffe2_module_test_dynamic.lib caffe2_nvrtc.lib Caffe2_perfkernels_avx.lib Caffe2_perfkernels_avx2.lib Caffe2_perfkernels_avx512.lib clog.lib cpuinfo.lib dnnl.lib fbgemm.lib fbjni.lib kineto.lib libprotobuf-lite.lib libprotobuf.lib libprotoc.lib mkldnn.lib pthreadpool.lib pytorch_jni.lib torch.lib torch_cpu.lib torch_cuda.lib torch_cuda_cpp.lib torch_cuda_cu.lib XNNPACK.lib- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
以上都是最重要的准备,接下来准备一些细节上的修复
在C/C++ ->预处理器 -> 预处理定义 ,添加 NOMINMAX

在链接器 -> 命令行 -> 其他选项,加上:
/INCLUDE:?searchsorted_cuda@native@at@@YA?AVTensor@2@AEBV32@0_N1@Z /INCLUDE:?warp_size@cuda@at@@YAHXZ- 1
- 2
加上以上的命令行,使得你的CUDA和cudnn可正常工作。
在Visual Studio 2019下,如果你使用最新版的libtorch,可能会出现报错:“一个无法解析的外部命令at::native::searchsorted_cuda”,如果你点进searchsorted_cuda函数,你会发现,只有声明没有实现,就会出现这个报错,那么它的实现其实在lib库文件里面,新版本的libtorch可能并没有这个函数的实现,所以报错了,所以我们才使用略早一些版本的libtorch。最后,还要将D:\Env\libtorch\lib库目录下的dll文件给加进来

以上都是debug模式的配置,
如果你当前设置为Release模式,那么将D:\Env\libtorch\lib 目录下的所有dll文件复制到生成Release模式下生成exe文件的同级目录下。然后执行,其他的配置一律相同。我们将此hello world程序运行在NVIDIA的显卡上
#include#include #include int main() { std::cout << "检查CDUA是否可用:" << torch::cuda::is_available() << std::endl; std::cout << "检查cudnn是否可用:" << torch::cuda::cudnn_is_available() << std::endl; std::clock_t s, e; s = clock(); torch::Tensor cuda_output; for (int i=0;i<1;i++) { cuda_output = torch::randn({ 5, 4 }, torch::device(torch::kCUDA)); } std::cout << cuda_output << std::endl; e = clock(); std::cout << "use time: " << (e - s) << " ms" << std::endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
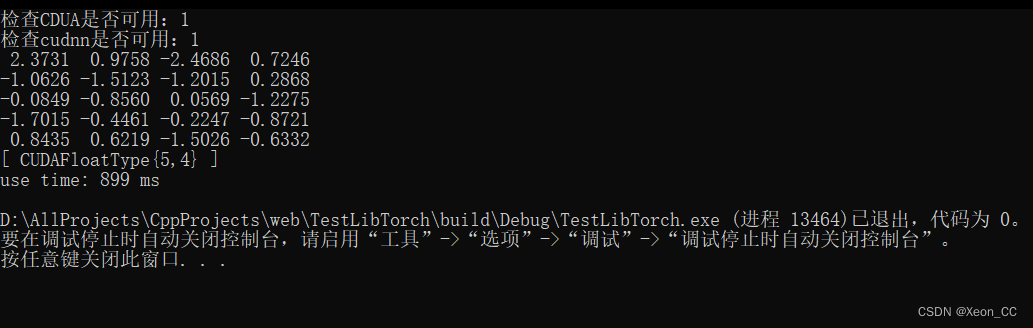
这是我们的运行结果:
我们可以看到CUDAFloatType{5, 4} 这证明确实在显存分配内存空间,随机生成一个5x4的矩阵。
-
-
相关阅读:
枚举与反射
Python绘图报错解决:The factorplot function has been renamed to catplot.
三万字盘点Spring/Boot的那些常用扩展点
2023数学建模国赛C题赛后总结
渐进式 shiro - shiro + jwt+salt (二)
文件共享方法
UEFI基础——测试用例Hello Word
MySQL实现每日备份
面试题:为什么HashMap 使用的时候指定容量?
【DC综合】DC工具 report_timing 命令的一些选项
- 原文地址:https://blog.csdn.net/Xeon_CC/article/details/126571246
