-
大数据--hadoop生态12--高频知识点总结
目录
一:一个基本的Hadoop集群中的节点主要有
- NameNode:负责协调集群中的数据存储
- DataNode:存储被拆分的数据块
- JobTracker:协调数据计算任务
- TaskTracker:负责执行由JobTracker指派的任务
- SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
二.分布式文件系统节点分类:
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,
这些节点分为 两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),
另一类叫**“从节点”(Slave Node)或者也被称为“数据节点”(DataNode).**
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间 (Namespace),
保存了两个核心的数据结构,即FsImage和EditLog FsImage用于维护文件系统树
以及文件树中所有的文件和文件夹的元数据 操作日志文件EditLog中记录了
所有针对文件的创建、删除、重命名等操作 名称节点记录了每个文件中各个块所在的数据节点的位置信息。
三.Hbase索引
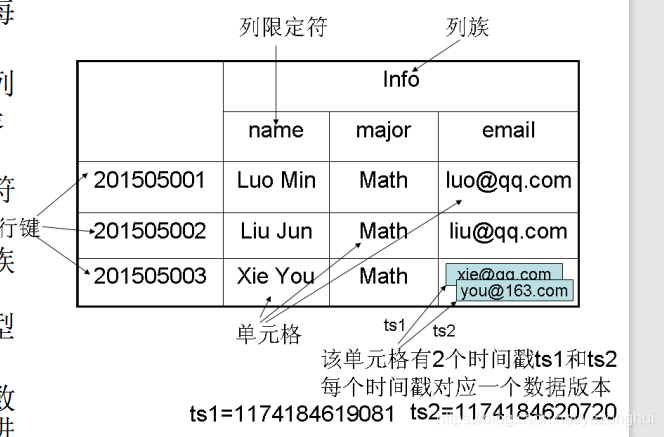
HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、 列族、列限定符和时间戳
每个值是一个未经解释的字符串,没有数据类型
用户在表中存储数据,每一行都有一个可排序的行键和任意多的列
表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多 个列,同一个列族里面的数据存储在一起
列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义 列的数量以及类型,
所有列均以字符串形式存储,用户需要自行进行 数据类型转换
HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个 新的版本,
旧有的版本仍然保留(这是和HDFS只允许追加不允许修 改的特性相关的)
四.HBase的实现包括三个主要的功能组件:
(1)库函数:链接到每个客户端 – (2)一个Master主服务器 – (3)许多个Region服务器
主服务器Master负责管理和维护HBase表的分区信息,维护Region服 务器列表,分配Region,负载均衡
Region服务器负责存储和维护分配给自己的Region,处理来自客户 端的读写请求
客户端并不是直接从Master主服务器上读取数据,而是在获得Region 的存储位置信息后,直接从Region服务器上读取数据
客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息 ,大多数客户端甚至从来不和Master通信,这种设计方式使得Master 负载很小
五:HDFS常用命令
hdfs dfs -ls / 查看hdfs根目录
put命令:
hdfs dfs -put file1.txt /user/hive/warehouse (首先在Linux系统上进入file1.txt所对应的目录下面,然后执行该命令)
get命令
hdfs dfs -put /user/hive/warehouse/test.db (此时hdfs上面的文件会导出到当前目录下面)
六:hive创建表然后导入数据
create table if not exist haokan_ads_test02 ( user_id int, user_type int, day1 date, play_rate double, resource string ) row format delimited fields terminated by ' ' lines terminated by ' ';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
导入数据
load data local inpath '/home/atguigu/bin/haokan_ads_test02.txt' into table haokan_ads_test02;- 1
- 2
覆盖原数据就使用overwrite
七:hive如何解决数据倾斜




八:详细讲解MapReduce的map和reduce过程,谈谈对shuffle的理解
1)map和reduce过程
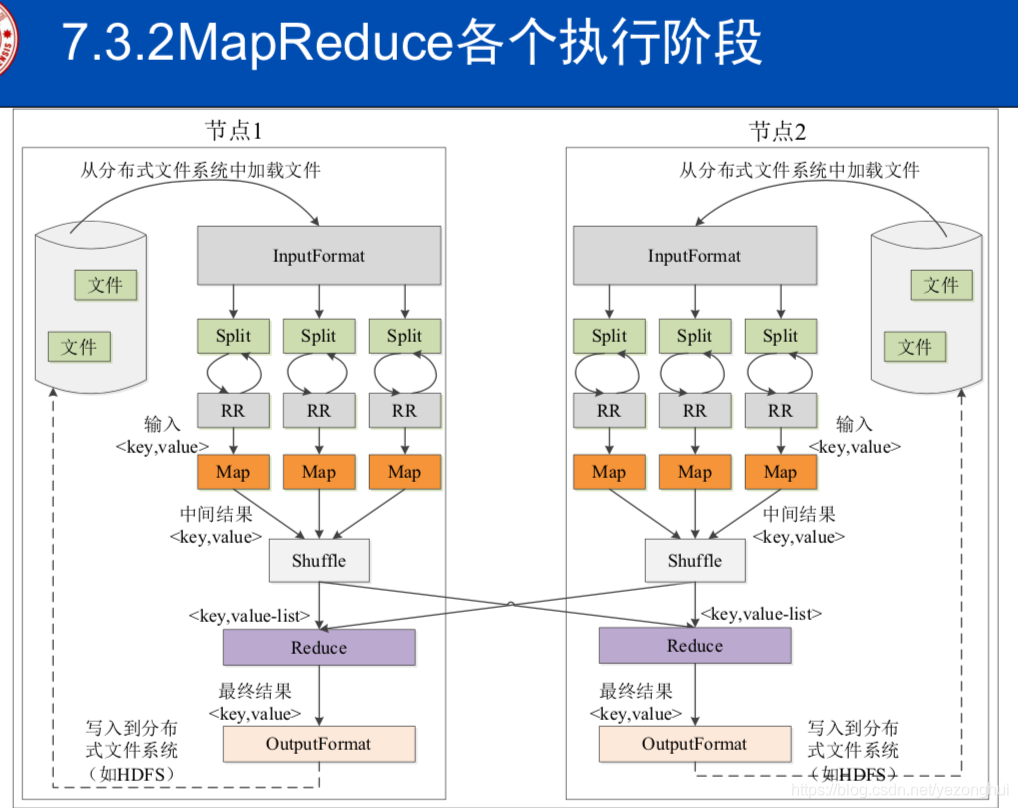
2)shuffle整体过程

3)map端的shuffle过程
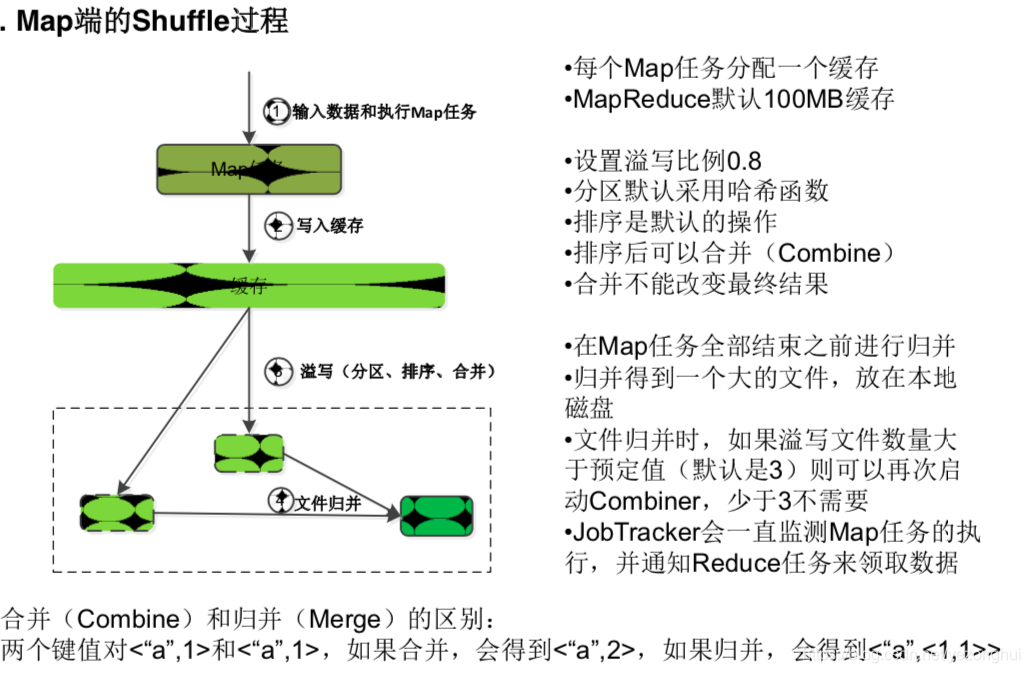
4)reduce端的shuffle过程

九:Java编程实现wordcount过程
1)wordcount过程

2)Java实现代码
十:hive实现wordcount过程
1
-
相关阅读:
SpringBoot2.7+使用swagger3
【AGC035E】Develop(图论,DP)
代码随想录算法训练营第五十九天| LeetCode 647 回文子串、LeetCode 516 最长回文子序列、动态规划总结
[附源码]计算机毕业设计JAVAjsp高校学生资助信息系统
leetcode (力扣) 201. 数字范围按位与 (位运算)
Ubuntu16.04安装Docker图文教程
什么是职业规划?如何进行职业规划?
【面试题】说说JS中的this指向问题
【仿牛客网笔记】 Redis,一站式高性能存储方案——点赞
你一定可以读懂的Linux中的变量、数组、和算数运算与测试看这篇就足够了
- 原文地址:https://blog.csdn.net/web18334137065/article/details/126565609