-
Impala优化,并发性能问题,压测
场景方面
impala属于mpp架构计算引擎,它自身不存储数据,对内存的依赖很大,所有计算都在内存中的,因此优势和弊端也就清晰了。
-
优势是在cpu、磁盘io、网络io一样的情况下,内存计算很快。
-
劣势是资源有限,内存装不下就会oom,并发度不可能很高。
impala适应于低并发下秒级别分析场景,例如几秒、几十秒、十几秒。大数据量下的过滤、聚合、join都有不错的表现。
并发方面
有人会问,低并发低到什么程度,没有个数吗,5个?10个?20个? 我只能说无法回答。不同集群、不同资源、不同类型的sql都是并发量的决定因素。在资源固定的情况下,有两种方案来解决并发太高导致sql异常的问题:
-
应用监控内存使用情况,提交sql前,检查集群正在运行多少个sql,队列中有多少sql在等待,再explain下要提交sql需要的内存量。最终决定要不要提交sql,如果不提交等待一定时间后继续检测。
-
SQL运行失败后重试,这个方法比较暴力,会浪费些资源。
资源方面
因此impala和hadoop生态圈的其他应用共用资源是必然的。
做集群资源隔离有没有用呢?有用,但是作用有限。早期hadoop1.x版本,没有支持cpu和io的隔离,hadoop2.x对cpu的隔离有支持,最新版本不知道有没有支持io隔离,知道的同学可以@我。为何说有限呢,资源隔离的动态才行,hive一般用于离线,impala更可能用于线上业务,使用的时间点不尽相同,在不同时间点资源动态调整才能把资源利用最大化,做到这点难度不低。
优化要点:
1、SQL优化,使用之前调用执行计划, 执行计划
– 查询sql执行之前,先对该sql做一个分析,列出需要完成这一项查询的详细方案
– 命令:explain sql、profile7、使用profile输出底层信息计划,在做相应环境优化
在执行之前使用EXPLAIN来查看逻辑规划,分析执行
- [9-24-143-25:21000] > explain select ds,count(*) from t_ed_xxxx_newuser_read_feature_n group by ds order by ds;
- Connection lost, reconnecting...
- Query: explain select ds,count(*) from t_ed_xxxx_newuser_read_feature_n group by ds order by ds
- +----------------------------------------------------------------------------------------------+
- | Explain String |
- +----------------------------------------------------------------------------------------------+
- | Max Per-Host Resource Reservation: Memory=9.94MB |
- | Per-Host Resource Estimates: Memory=27.00MB |
- | PLAN-ROOT SINK |
- | 05:MERGING-EXCHANGE [UNPARTITIONED] |
- | | order by: ds ASC |
- | 02:SORT |
- | | order by: ds ASC |
- | 04:AGGREGATE [FINALIZE] |
- | | output: count:merge(*) |
- | | group by: ds |
- | 03:EXCHANGE [HASH(ds)] |
- | 01:AGGREGATE [STREAMING] |
- | | output: sum_init_zero(default.t_ed_xxxx_newuser_read_feature_n.parquet-stats: num_rows) |
- | | group by: ds |
- | 00:SCAN HDFS [default.t_ed_xxxx_newuser_read_feature_n] |
- | partitions=372/372 files=2562 size=15.15GB |
- +----------------------------------------------------------------------------------------------+
自底向上读取EXPLAIN的输出:
- 00阶段: 显示了底层的详细信息,如:扫描的表,表的分区数,文件数以及文件大小等信息,根据这些信息,你可以估算大概的耗时
- 01阶段: 聚合操作SUM并行地在不同的节点上执行
- 03阶段: 将01阶段的结果进行传输
- 04阶段: 将SUM结果进行合并
- 02阶段: 排序操作并行地在不同的节点中进行
- 05阶段: 排序结果合并,并且输出
EXPLAIN也会在PROFILE结果的头部输出。使用SUMMARY 报告进行性能调优
SUMMARY命令可以输出每一阶段的耗时,可以快速地了解查询的性能瓶颈,与PROFILE输出一样,它只能在查询之后才可用,并且显示实际的时间消耗。SUMMARY输出也会在PROFILE的头部输出的显示。- [9-24-143-25:21000] > select ds,count(*) from t_ed_xxxx_newuser_read_feature_n group by ds order by ds;
- [9-24-143-25:21000] > summary;
- +---------------------+--------+----------+----------+-------+------------+----------+---------------+--------------------------------------------+
- | Operator | #Hosts | Avg Time | Max Time | #Rows | Est. #Rows | Peak Mem | Est. Peak Mem | Detail |
- +---------------------+--------+----------+----------+-------+------------+----------+---------------+--------------------------------------------+
- | 05:MERGING-EXCHANGE | 1 | 3.20s | 3.20s | 372 | 372 | 0 B | 0 B | UNPARTITIONED |
- | 02:SORT | 51 | 517.22us | 2.54ms | 372 | 372 | 6.02 MB | 6.00 MB | |
- | 04:AGGREGATE | 51 | 1.75ms | 7.85ms | 372 | 372 | 2.12 MB | 10.00 MB | FINALIZE |
- | 03:EXCHANGE | 51 | 2.91s | 3.10s | 2.44K | 372 | 0 B | 0 B | HASH(ds) |
- | 01:AGGREGATE | 51 | 135.29ms | 474.62ms | 2.44K | 372 | 2.03 MB | 10.00 MB | STREAMING |
- | 00:SCAN HDFS | 51 | 1.08s | 2.58s | 2.56K | 96.53M | 1.05 MB | 1.00 MB | default.t_ed_xxxx_newuser_read_feature_n |
- +---------------------+--------+----------+----------+-------+------------+----------+---------------+--------------------------------------------+
使用PROFILE进行性能分析
PROFILE语句将产生一个关于最近一次查询的底层报告的详细信息展示。与EXPLAIN不同,这些信息只在查询完成之后才会生成,它显示了每个节点上的物理详细信息如:读取的字节数,最大内存消耗等。
你可以根据这些信息来确定查询时I/O密集型,还是CPU密集型,网络是否导致瓶颈,是否某些节点性能差但是其它节点性能好等信息。2、选择合适的文件格式进行存储
为数据存储选择合适的文件格式(如:Parquet) ,通常对于大数据量来说,Parquet文件格式是最佳的
3、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表)
4、使用合适的分区技术,根据分区粒度测算
根据实际的数据量大小选择合适的分区粒度
合适的分区策略可以对数据进行物理拆分,在查询的时候就可以忽略掉无用数据,提高查询效率,通常建议分区数量在3万以下(太多的分区也会造成元数据管理的性能下降)
为分区key选择最小的整数类型
虽然使用string类型也可以作为分区key,因为分区key最后都是作为HDFS目录使用,但是使用最小的整数类型作为分区key可以降低内存消
5. 选择合适的Parquet块大小
默认情况下,Impala的
insert ... select语句创建的Parquet文件都是每个分区256M(在2.0之后改为1G了),通过Impala写入的Parquet文件只有一个块,因而只能被一个机器当作一个单元进行处理。如果在你的Parquet表中只有一个或者几个分区,或者一个查询只能访问一个分区,那么你的性能会非常慢,因为足够的数据来利用Impala并发分布式查询的优势5、使用compute stats进行表信息搜集
在追求性能或者大数据量查询的时候,要先获取所需要的表的统计指标(如:执行
compute stats)6、网络io的优化:减少传输到client端的数据量
– a.避免把整个数据发送到客户端
– b.尽可能的做条件过滤
– c.使用limit字句
– d.输出文件时,避免使用美化输出我们可以通过如下方式来降低到客户端的数据量:
- 聚合(如
count、sum、max等) - 过滤(如
WHERE) LIMIT- 结果集禁止使用美化格式进行展示(在通过impala-shell展示结果时,添加这些可选参数:
-B、 --output_delimiter)
8、如果是刷新表的新增元数据要使用refresh 表名 来刷新,不要使用impala-shell -r 或 invalidate metadata
9、如果执行SQL的结果内容较多的话可以使用 impala-shell -B 将一些不必要的样式输出去掉
控制Impala资源使用情况
有时,将原始查询性能与可伸缩性进行平衡需要限制单个查询或查询组使用的资源(如内存或CPU)的数量。 Impala可以使用多种机制来帮助在大量并发使用期间消除负载,从而加快整个查询时间,并跨群集中的Impala查询,MapReduce作业和其他类型的工作负载共享资源:
-
Impala许可控制功能使用快速的分布式机制来阻止超过并发查询数或使用的内存量限制的查询。查询排队,并在其他查询完成且资源可用时执行。您可以控制并发限制,并为不同的用户组指定不同的限制,以根据不同用户类的优先级划分群集资源。此功能是Impala 1.3中的新功能。有关详细信息,请参阅第682页的“准入控制和查询队列”。
-
您可以通过为impalad守护程序指定-mem_limit选项来限制Impala在查询执行期间保留的内存量。有关详细信息,请参阅第33页的修改Impala启动选项。这个限制仅适用于查询直接使用的内存; Impala在启动时保留额外的内存,例如用于保存缓存的元数据。
-
对于生产部署,请使用群集管理工具实施资源隔离。
Impala中最大连接数的设置
impala中最大连接数
最近工作中有用到impala,有用到impala进行对数据库的操作,由于查询是页面在查询,所以有可能会有n个人在同时查询,那也就是数有可能同事有很多个客户端在请求impala连接,当请求数量达到64个的时候就卡住了,通过测试发现,impala默认的请求数(也就是连接数)限制在64个,当请求到64个impala连接之后,如果连接一直保持不释放,那么就不能再请求第65个连接,这就不满足一些需求了,下面来看下怎么来修改这个最大连接数的设置。修改impala的最大连接数
通过调查以及网上的搜索,发现可以通过设置参数:–fe_service_threads=n来达到目的,打开impala的配置文件impala,在IMPALA_SERVER_ARGS的值中添加–fe_service_threads=n即可,其中n为修改后的最大连接数,然后重启impalad即可生效。由Impala-3316导致的并发查询缓慢问题 - 码农教程
1.创建测试表
- create database if not exists iot_test;
- use iot_test;
- create table if not exists hive_table_text (
- ordercoldaily BIGINT,
- smsusedflow BIGINT,
- gprsusedflow BIGINT,
- statsdate TIMESTAMP,
- custid STRING,
- groupbelong STRING,
- provinceid STRING,
- apn STRING )
- PARTITIONED BY ( subdir STRING )
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "," ;
2.准备测试数据
gendata.sh脚本内容如下:
- [root@cdh4 scripts]# cat gendata.sh
- function rand(){
- min=$1
- max=$(($2-$min+1))
- num=$(($RANDOM+1000000000))
- echo $(($num%$max+$min))
- }
- let i=1
- while [ $i -le 3 ];
- do
- let n=1
- while [ $n -le $1 ];
- do
- let month=$n%12+1
- if [ $month -eq 2 ];then
- let day=$n%28+1
- else
- let day=$n%30+1
- fi
- let hour=$n%24
- rnd=$(rand 10000 10100)
- echo "$i$n,$i$n,$i$n,2017-$month-$day $hour:20:00,${rnd},$n,$n,$n" >> data$i.txt
- let n=n+1
- done
- let i=i+1
- done
执行./gendata.sh 300000命令,生成3个测试文件,每个文件包含30万条样例数据。

2.上传测试数据
运行upLoad.sh脚本,将测试数据上传至HDFS的/tmp/hive目录下
- [root@cdh4 scripts]# cat upLoadData.sh
- #!/bin/sh
- num=3
- path='/tmp/hive'
- #create directory
- sudo -u hdfs hdfs dfs -mkdir -p $path
- sudo -u hdfs hdfs dfs -chmod 777 $path
- #upload file
- let i=1
- while [ $i -le $num ];
- do
- hdfs dfs -put data${i}.txt $path
- let i=i+1
- done
- #list file
- hdfs dfs -ls $path
3.验证数据是否正确

可以看到,三个文件共包含90万条数据,与原始文件数据总数一致
4.加载数据进入测试表
执行./hivesql_exec.sh loadData.sql命令,加载数据
- [root@cdh4 scripts]# cat loadData.sql
- use iot_test;
- LOAD DATA INPATH '/tmp/hive/data1.txt' INTO TABLE hive_table_test partition (subdir="10");
- LOAD DATA INPATH '/tmp/hive/data2.txt' INTO TABLE hive_table_test partition (subdir="20");
- LOAD DATA INPATH '/tmp/hive/data3.txt' INTO TABLE hive_table_test partition (subdir="30");
3.由Hive生成包含timestamp的parquet表
1.使用Hive创建Parquet表
生成Parquet表语句如下,其中“statsdate”字段为TIMESTAMP类型:
- [root@cdh4 scripts]# cat genParquet.sql
- use iot_test;
- create table hive_table_parquet (
- ordercoldaily BIGINT,
- smsusedflow BIGINT,
- gprsusedflow BIGINT,
- statsdate TIMESTAMP,
- custid STRING,
- groupbelong STRING,
- provinceid STRING,
- apn STRING )
- PARTITIONED BY ( subdir STRING )
- STORED AS PARQUET;
- set hive.exec.dynamic.partition=true;
- set hive.exec.dynamic.partition.mode=nonstrict;
- insert overwrite table hive_table_parquet partition (subdir)
- select * from hive_table_test
4.准备并发测试脚本
1.并发测试脚本如下,Impala负载均衡地址为:cdh4.macro.com:25003
- [root@cdh4 scripts]# cat impala-test.sh
- #!/bin/sh
- #Concurrency test
- let i=1
- while [ $i -le $1 ];
- do
- impala-shell -B -i cdh4.macro.com:25003 -u hive -f $2 -o log/${i}.out &
- let i=i+1
- done
- wait
2.测试SQL语句如下
- SELECT
- nvl(A.TOTALGPRSUSEDFLOW,0) as TOTALGPRSUSEDFLOW, nvl(A.TOTALSMSUSEDFLOW,0) as TOTALSMSUSEDFLOW, B.USEDDATE AS USEDDATE
- FROM ( SELECT SUM(GPRSUSEDFLOW) AS TOTALGPRSUSEDFLOW, SUM(SMSUSEDFLOW) AS TOTALSMSUSEDFLOW, cast(STATSDATE as timestamp) AS USEDDATE
- FROM hive_table_parquet SIMFLOW
- WHERE SIMFLOW.subdir = '10' AND SIMFLOW.CUSTID = '10099'
- AND cast(SIMFLOW.STATSDATE as timestamp) >= to_date(date_sub(current_timestamp(),7))
- AND cast(SIMFLOW.STATSDATE as timestamp) < to_date(current_timestamp())
- GROUP BY STATSDATE ) A
- RIGHT JOIN (
- SELECT to_date(date_sub(current_timestamp(),7)) AS USEDDATE UNION ALL
- SELECT to_date(date_sub(current_timestamp(),1)) AS USEDDATE UNION ALL
- SELECT to_date(date_sub(current_timestamp(),2)) AS USEDDATE UNION ALL
- SELECT to_date(date_sub(current_timestamp(),3)) AS USEDDATE UNION ALL
- SELECT to_date(date_sub(current_timestamp(),4)) AS USEDDATE UNION ALL
- SELECT to_date(date_sub(current_timestamp(),5)) AS USEDDATE UNION ALL
- SELECT to_date(date_sub(current_timestamp(),6)) AS USEDDATE
- ) B on to_date(A.USEDDATE) = to_date(B.USEDDATE) ORDER BY B.USEDDATE
5.Impala并发测试
使用相同的测试SQL,在不同并发测试场景下做并发测试,为了避免单次测试结果的偶然性,针对3种并发测试场景分别作了三次测试。
1.测试1个并发查询:1 秒返回查询结果
第一次测试:1.09秒返回查询结果

第二次测试:0.76秒返回查询结果

第三次测试:0.78秒返回查询结果

可以看到,1个并发查询,能在秒级内返回结果
2.测试10个并发查询:所有并发查询均在6.8秒内完成
第一次测试:所有并发查询均在6.4秒内完成

第二次测试:所有并发查询均在6.8秒内完成

第三次测试:所有并发查询均在6.8秒内完成

可以发现,在10个并发查询的场景下,Impala查询性能已经有明显的下降了。
3.测试30个并发查询:花费时间最长的为12.24秒。
第一次测试:前6个查询均在5秒内完成,但是随着并发数的增大,查询返回结果的时间越长,花费时间最长的为11.81秒。


第二次测试:前4个查询均在5秒内完成,30个并发查询中,花费时间最长的为12.24秒。

 第三次测试:前5个查询均在5秒内完成,30个并发查询中,花费时间最长的为12.20秒。
第三次测试:前5个查询均在5秒内完成,30个并发查询中,花费时间最长的为12.20秒。

结论:
从并发测试结果来看,在30个并发查询的测试场景下,Impala查询性能急剧下降,即随着并发查询数量的增多,Impala查询性能越差。
如果Parquet表是由Hive/Spark产生的,包含TIMESTAMP字段类型,并且Impala高级配置包含--convert_legacy_hive_parquet_utc_timestamps=true启用选项,那么使用Impala做并发查询时,随着并发的增加,查询性能会慢慢下降,并发越高,性能下降越厉害。根据我们在上一章的测试效果,可以看出,1个用户单独查询能秒级返回查询结果,10个用户并发查询需要3秒左右返回查询结果,30个用户并发查询需要耗时15秒左右。
该性能问题是由IMPALA-3316(https://issues.apache.org/jira/browse/IMPALA-3316)导致的,Impala在读取Hive或者Spark生成的Parquet表时,如果表包含TIMESTAMP字段类型,并且Impala高级配置包含--convert_legacy_hive_parquet_utc_timestamps=true启用选项。Impala会调用Linux本地的时间转换函数(localtime_r)将Timestamp数据转换成系统的当地时间,而缺省情况下,Impala并不做任何转换,且将Timestamp时间都作为UTC时间处理。但是localtime_r函数内部实现会加上进程全局锁,因此当有大量并发的Parquet读取时会影响性能。而并发越高,全局锁的问题就越严重,从而导致性能下降就越厉害。
4.解决方案建议
在Impala的该bug修复前,我们建议通过以下三种方式来规避这个问题:
1.如果不要求 Impala 返回本地时间, 可以去掉
--convert_legacy_hive_parquet_utc_timestamps=true启动选项
2.将相关的 Parquet表用 Impala 生成
3.Hive/Spark 产生 Parquet 表时使用STRING类型代表时间, 并且时间格式采用 yyyy-MM-dd HH:mm:ss.SSS 或者 yyyy-MM-dd HH:mm:ss,这种方式下,使用 Impala 的date/time函数时, Impala 会自动将其转换成TIMESTAMP类型
Impala并发性能问题排查案例_道友,且慢的博客-CSDN博客_impala并发量
1. 问题介绍
在进行impala性能测试的过程中,从测试结果发现impala的并发性能非常差。
1.1 环境信息
测试的环境配置如下:
服务器内存:250G ;
CPU : 2个CPU,每cpu 6个物理核,逻辑核数24 ;
带宽:万兆网口
节点个数:3
数据:TPC-DS生成的100G数据集,把数据导入parquet格式的hive表中。1.2 查询SQL
- select ss_quantity, ss_list_price, ss_coupon_amt, ss_sales_price, ss_wholesale_cost, ss_ext_list_price
- from store_sales
- where ss_sold_date_sk > 20 and (ss_item_sk between 10 and 5000)
- and ((ss_cdemo_sk between 100 and 3000 or ss_store_sk between 10 and 3000))
- and (ss_addr_sk > 100 or ss_promo_sk < 3000)
- limit 100
1.3 测试结果
并发测试结果如下:
并发度: 4、6 、8 、10 、15 、20
平均耗时(ms):2305 、3435 、4694 、5868 、8803 、11679
从测试结果看,查询的平均耗时随着测试的并发度增加呈现线性的上升,4并发下平均耗时仅需2秒的查询在20并发下竟然需要11秒。这样的性能并不符合预期。
2. 问题分析
为了查明高并发场景下简单的过滤查询耗时变慢的原因。我们列出如下排查方向。
1、 监控服务器资源,观察是否资源不足导致的
2、 如果资源充足,分析查询的profile信息,分析任务执行的各个阶段耗时,找出耗时明显较长的阶段,进一步深入分析。2.1 服务器资源查看
通过先知平台,监控测试运行时的资源情况。
CPU:随着并发度增加CPU使用率较为稳定,平均使用率约24%。
内存:起始内存约为50GB,随着并发数的增加,内存占用较为稳定,占用约为400M。

磁盘和网络IO也消耗很少。从以上监控结果可以得出结论,系统的cpu、内存、磁盘IO、网络IO都非常充足,因此排除资源不足的因素。
2.2 Profile 分析
打开impalad的web页面,选择queries导航栏,打开queries页面,这个页面上有impala上正在执行和执行完成的查询信息。

在页面下方的 Last 25 Completed Queries 中可以看到最近的25条执行完成的查询。找出你要分析的查询,选择Detail
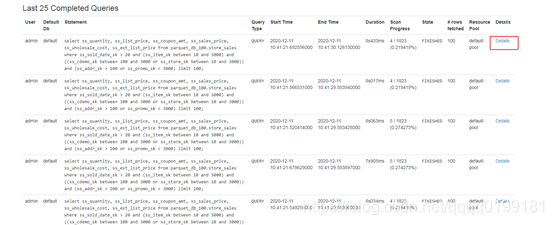
打开Detail页面后,选择profile选项,就可以看到查询各个阶段耗时的分析了

在本案例中,截取的profile关键信息如下:

有上图可以看出,sql的执行时间为19s016ms,其中Single node Plan created 的耗时就需要18s05ms。
由此可见,生成单节点计划步骤是查询性能降低的罪魁祸首,并且查询的并发度越高,生成单节点计划消耗的时间越长。那么为什么会出现这种现象呢?导致这种现象的根本原因又是什么呢?
2.3 Arthas分析
从impala的源码中可以找到,生成单节点计划的代码如下:

可见impala的执行计划生成的代码位于fe部分,由java代码实现。既然是java实现的,就可以使用诊断神器Arthas去做进一步分析。
在arthas安装目录下启动arthas
java -jar arthas-boot.jar
选择impala进程attach
首先查看线程的情况,执行thread命令

可以发现此时impala进程中有许多线程处于阻塞状态。
使用thread 1331 查看其中一个阻塞线程的调用栈,打印如下信息:- "Thread-649" Id=1331 BLOCKED on org.apache.hadoop.conf.Configuration@3a2996ef owned by "Thread-616" Id=1270
- at app//org.apache.hadoop.conf.Configuration.getOverlay(Configuration.java:1424)
- - blocked on org.apache.hadoop.conf.Configuration@3a2996ef
- at app//org.apache.hadoop.conf.Configuration.handleDeprecation(Configuration.java:706)
- at app//org.apache.hadoop.conf.Configuration.get(Configuration.java:1183)
- at app//org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1774)
- at app//org.apache.hadoop.hdfs.client.impl.DfsClientConf.<init>(DfsClientConf.java:248)
- at app//org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:301)
- at app//org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:285)
- at app//org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:168)
- at app//org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:3237)
- at app//org.apache.hadoop.fs.FileSystem.get(FileSystem.java:475)
- at app//org.apache.hadoop.fs.Path.getFileSystem(Path.java:361)
- at app//org.apache.impala.planner.HdfsScanNode.computeScanRangeLocations(HdfsScanNode.java:893)
- at app//org.apache.impala.planner.HdfsScanNode.init(HdfsScanNode.java:413)
- at app//org.apache.impala.planner.SingleNodePlanner.createHdfsScanPlan(SingleNodePlanner.java:1335)
- at app//org.apache.impala.planner.SingleNodePlanner.createScanNode(SingleNodePlanner.java:1395)
- at app//org.apache.impala.planner.SingleNodePlanner.createTableRefNode(SingleNodePlanner.java:1582)
- at app//org.apache.impala.planner.SingleNodePlanner.createTableRefsPlan(SingleNodePlanner.java:826)
- at app//org.apache.impala.planner.SingleNodePlanner.createSelectPlan(SingleNodePlanner.java:662)
- at app//org.apache.impala.planner.SingleNodePlanner.createQueryPlan(SingleNodePlanner.java:261)
- at app//org.apache.impala.planner.SingleNodePlanner.createSingleNodePlan(SingleNodePlanner.java:151)
- at app//org.apache.impala.planner.Planner.createPlan(Planner.java:117)
- at app//org.apache.impala.service.Frontend.createExecRequest(Frontend.java:1169)
- at app//org.apache.impala.service.Frontend.getPlannedExecRequest(Frontend.java:1495)
- at app//org.apache.impala.service.Frontend.doCreateExecRequest(Frontend.java:1359)
- at app//org.apache.impala.service.Frontend.getTExecRequest(Frontend.java:1250)
- at app//org.apache.impala.service.Frontend.createExecRequest(Frontend.java:1220)
- at app//org.apache.impala.service.JniFrontend.createExecRequest(JniFrontend.java:154)
从标红行可以判断,线程阻塞的位置就是发生在生成单节点计划处,即SingleNodePlanner.createScanNode。而最终阻塞的位置是Configuration.getOverlay。这是调用了hadoop jar包的方法,该方法的代码如下:

这是个同步方法,也就是代表多线程的情况下会存在资源竞争,这就导致了线程阻塞的问题。
3. 问题解决
那么为什么会有多线程调用这个方法呢?
从上面的调用栈可以看出,创建单节点计划的过程中会创建FileSystem,创建FileSystem的方法如下:

以上代码显示如果fs.hdfs.impl.disable.cache 为 true,每次impala查询就会调用createFileSystem(uri, conf)去初始化hdfs客户端,最终调用getOverlay方法,这就导致了多并发场景下线程的阻塞。如果fs.hdfs.impl.disable.cache 为 false,就可以获取缓存,这样就避免了阻塞的问题。因此只要将hdfs-site.xml中的fs.hdfs.impl.disable.cache配置项改为false,就可以解决问题。
fs.hdfs.impl.disable.cache参数之前工作中遇到过,默认值为false,表示使用cache,因此首先怀疑又是cache的问题,FileSystem.get(URI.create(path), conf),第一次获取的是master集群,第二次使用了cache
fs.hdfs.impl.disable.cache参数本身不建议修改,否则有可能会带来其他问题
4. 效果验证
修改fs.hdfs.impl.disable.cache配置为false后,在并发查询场景下,用arthas监控没有发现线程阻塞的问题。且原来100并发平均耗时20s, 现在平均耗时4s,查询的并发性能大幅度提升。
hive由fs.hdfs.impl.disable.cache参数引起的重写分区数据的异常_脚踏宝马的博客-CSDN博客_fs.hdfs.impl.disable.cache
hive由fs.hdfs.impl.disable.cache参数引起的重写分区数据的异常
问题描述:
已有 (外部/内部) 表test,新建分区时指定数据位置,如下
alter table test add partition(day='20140101')
location '20140101';这样会默认在表warehouse路径下生成/{warehouse}/test/20140101/这种格式目录
同时使用命令 desc formatted test partition(day='20140101')可以查看到相应的location为
hdfs://..:../{warehouse}/test/20140101/然后使用insert overwrite向分区插入数据
insert overwrite table test partition (day='20140101')
select xx from xx....;正常情况下一切正常,但是当设置属性 fs.hdfs.impl.disable.cache为 true时,会出现以下情况
desc formatted test partition(day='20140101')时发现location变成了以下格式
hdfs://..:../{warehouse}/test/day=20140101/
同时会在hdfs上 生成一个新的目录/{warehouse}/test/day=20140101/,而此 分区之前的location路径会被删掉,即 /{warehouse}/test/20140101/这个路径被删除
Impala Join策略与执行计划生成
作为铺垫,本文首先对Broadcast Join和Partitioned Join进行简要介绍。
Broadcast Join
顾名思义,Broadcast Join就是广播的方式进行Join。以下图为例,假设Join操作为SELECT A JOIN B ON A.id=B.id,Broadcast Join就是将B表(rhs)数据广播到所有扫描了A表的节点中,每一个扫描A表数据的impalad都会用自己持有的部分数据与接收到的完整的B表进行Join,随后将结果聚合得到完整的Join结果(如下图所示)。

这种Join方式适合于体积较大的表与体积较小的表进行关联,如下图这种情况,一个100多G的表与几十KB的表进行Join(绿框内显示BROADCAST即为广播Join),对小表进行广播的网络传输代价几乎可忽略不计,在内存中的哈希计算开销也很小,但如果是采用Partitioned Join,则会增加许多网络中的通信传输代价,下面对其进行简要介绍。

Partitioned Join
区别于Broadcast Join,Partitioned Join更适合两个较大的表进行关联(两个小表无所谓哪种Join一般都不会很慢)。其原理图如下图所示,仍假设SELECT A JOIN B ON A.id=B.id,当两进行Partitioned Join时,对AB两表的Join key进行分区,具有相同key的数据分布到相同的impalad,此时各impalad内的数据相当于被打散的AB两表(shuffle),再在所有impalad内进行小数据块的Hash Join,完成后进行结果聚合(如下图所示)。

下图为一个使用Partitioned Join的例子,相比Broadcast Join,Partitioned Join多了一个EXCHANGE,这是由于Partitioned Join不是单独将一个表发送到网络中,而是两个表要把shuffle后的数据全部发送出去。从图中也可看出,两个表的体积相对接近,因此Impala采用了分区JOIN的方式。

极端情况下,假如错误地对大表进行了Broadcast,将会对网络造成极大的负担,而且相关查询会非常慢,耗时过久的慢查询也会影响队列内其他查询的正常执行。
Broadcast vs Partitioned如何选择
对于一个大数据查询引擎,任何一步操作均需要最大化考虑性能的影响,否则在数据量极大的条件下可能出现不可预估的后果,Impala有一套CBO(Cost-based Optimizer,基于代价的优化)机制用来指导执行计划的生成,不仅在JOIN策略的选择上,在整个执行计划的生成上都有CBO的影子。本文接下来先介绍执行计划中对JOIN策略的取舍。
CBO对于JOIN策略的影响
对于JOIN策略的判断,Impala有基于代价的一系列计算,通过分别计算两种JOIN的网络传输代价和内存代价的和来判断最优的策略。
广播Join的cost计算
Impala中广播JOIN的代价计算可总结为以下公式:cost_broadcast = 2 × size_rhs × instNum_lhs
其中,size_rhs为根据右表基数和每行数据序列化后的预估大小计算得到,意为右表在网络中传输的数据大小;instNum_lhs为左表所在impalad的个数,由MT_DOP(多线程处理参数,线程个数)和扫描左表的impalad的个数确定,意为所有参与左表扫描的impalad总个数;两者相乘为一次网络传输中右表需要传输的数据量;内存代价与网络代价相同,也为size_rhs与impalad个数的乘积,因此乘2就是总代价。在几种情况下,广播代价将无法正确计算,置为-1:1)右表统计信息缺失
计算代价前,Impala会直接获取右表的基数进行判断,由于右表可能为子查询得到的中间结果或数据表:假如为直接扫描到的数据表,那么直接获取表的基数,再判断是否为-1。假如为子查询,无论子查询中SQL写了哪种JOIN,只要有一张表的统计信息缺失,那么Impala均会把子查询的结果基数置为-1,广播代价也会直接置为-1。左表的统计信息缺失不影响广播代价的计算,如果当前也是子查询,结果的基数将为-1。(基数:Impala用来判断表或数据大小的重要指标,一般是从数据总行数和所有列的数据类型计算得到并存入metastore,使用时从metastore库中获取,Impala会随着数据插入/删除进行动态调整,统计信息缺失的表基数为-1)2)左表的SCAN节点数获取失败
在1)的条件满足的情况下,假如没有正确获取到size_rhs,broadcast的代价也会置为-1。分区Join的cost计算
计算分区JOIN代价的计算公式可总结如下:cost_partition = NetworkCost_lhs + NetworkCost_rhs + size_rhs
NetworkCost = Cardinality × AvgSerializedRowSize
其中NetWorkCost_lhs和NetWorkCost_rhs分别为lhs和rhs的网络代价,rhs_size仍为rhs的大小,即内存代价,网络代价由基数和平均序列化后的行大小相乘(根据统计信息预估)。在计算代价前,需要先进行一些判断:
1)两边表或子执行计划的结果统计信息未缺失,然后判断2);
2)根据分区和Join key判断是否需要经过网络传输数据,如果为否,则网络代价为0;
随后进行代价计算,如果2)的判断均使lhs和rhs的网络代价为0,那么总代价则直接为内存代价;反之,lhs和rhs的网络代价均为表大小的估计值,通过基数与平均表序列化后每行数据大小相乘得到。最终两者相加为总代价。
由于Impala一般在两个大小相对接近大表Join时选择Partitioned Join,因此直接取一个表的大小作为内存代价。结合两种代价的计算公式可看出,同样的两个表进行Join,当impalad数量不多时,Broadcast Join和Partitioned Join的代价可能会较为接近,但在参与处理的impalad数量较多时,进行Broadcast Join的代价可能就会超过Partitioned Join,因此对于两者的选择不应一成不变,还需要根据实际情况判断。策略选择
在计算得到广播Join和分区Join的代价后,就可以通过对比来选择更优的策略,但这里有一些特别的处理:
1)当Join类型为右外连接/右半连接/右反连接/全外连接时,直接选择分区Join;
2)当Join类型为NULL AWARE LEFT ANTI JOIN(无感知的左反连接)时,直接选择广播Join;
3)发现有Hint时,采用Hint中的Join方式;
4)当广播Join与分区Join的代价相同或两者任意一个为-1时,采用默认配置的Join方式,可在配置文件或通过set修改;
随后则通过广播和分区JOIN的代价进行判断,当分区JOIN的代价更小时,采用分区JOIN;反之若广播JOIN的代价更小,且同时满足:
1)mem_limit无限制或rhs的大小小于mem_limit,mem_limit可在配置文件或通过set修改;
2)broadcast_bytes_limit参数无限制或rhs大小小于broadcast_bytes_limit(该参数可在配置文件或通过set修改,用来防止Broadcast Join过程中传输过大的数据到网络中,默认约为34GB);
则选择广播JOIN。
注意,广播和分区JOIN的JOIN key均必须为等值Join,否则将进行NESTED LOOP JOIN。JOIN key的顺序
Impala的FE端在生成单节点执行计划时,对每个操作(如SQL中的各种运算符、AND/OR、[NOT] IN等等)均内置了每种操作的代价数值(如下图所示),无论是子查询得到的中间结果还是数据表,均可通过特定的算法计算出目前的代价,再通过排序来优化执行顺序。JOIN两边的不仅仅是表,也可能是子查询的中间结果,因此需要对所有基本操作进行代价的计算。需要注意的是,如果检测到目前只有1个impalad,那么将直接执行单节点执行计划,不会生成分布式执行计划。
每种操作的代价计算通过内置的值和筛选率(selectivity)进行计算,筛选率可理解为经过这个操作之后,筛选数据/原数据的值,实际数值通过统计信息来计算得到。默认的筛选率为0.1,如果表的统计信息缺失,那么将进行修正:selectivity = exp{ln0.1 / num}
其中num为缺失统计信息的表个数。计算代价时,遍历目前查询的所有操作,每次遍历选出当前cost最小的操作添加到结果list中,然后进行筛选率的修正,如此直到所有操作遍历完成,其中cost计算可描述为:cost_total = cost_currentOp + cost_otherOp × selectivity_fixed
selectivity_fixed = selectivity^(1/n)
其中cost_total为当前操作的代价,cost_currentOp为操作自有的代价,cost_otherOp为其他所有操作的代价,selectivity_fixed为当前的筛选率,n为当前遍历的次数。Join key作为SQL中的一部分,也会参与排序优化,但为使得优化的效果最好,需要参与扫描的表具有统计信息,否则可能出现性能更坏的情况。
综合2和3的流程,可将JOIN方式的选择总结如下:
总结Impala通过基于代价的优化,来动态判断当前SQL的Join策略应如何在广播和分区Join中选择,以及各种子句的排序优化。当参与Join的两个表一大一小时,一般将考虑广播Join;两个大表Join时,则使用分区Join。广播Join的开销取决于右表的大小和节点数,分区Join的开销取决于两表的大小。当统计信息缺失时,如果误将大表进行了Join,将对集群的计算性能和网络环境造成严重影响。综合来看,表的统计信息对执行计划的优劣有着重要的影响,因此在执行SQL前,应尽可能先计算所有被查询表的统计信息,且应先通过EXPLAIN查看执行计划是否为最优。
Impala 如何确定 Join 策略
如何确定 Join 策略
与主流的数据库和数仓查询引擎一样,Impala 也是基于代价模型进行执行计划优化(CBO)。只有获取足够的统计信息,才能支撑 Impala 选取较优的执行计划。本节分析 Join 的计算方式,以解文章开始提出的问题。对于这两种 join 类型,总成本计算为通过网络发送的数据量,加上插入到哈希表中的数据量。
1. 计算两种 join 成本:
能计算的前提是有统计信息,否则都是 -1.broadcast:将右侧 Fragment 输出发送到左侧的每个节点,并在节点构建哈希表。
计算:(右侧Fragment 数据大小 + 哈希表大小)* 左侧实例数
————————————————
-
-
相关阅读:
SIPp使用经验
彻底搞懂MySQL主从复制工作原理:2个日志 | 3种存储格式 |3个线程|4种工作模式
ffplay.c源码阅读之暂停、重播、快进、快退实现细节
Spring Boot整合Postgres实现轻量级全文搜索
(LeetCode C++)盛最多水的容器
[附源码]计算机毕业设计JAVA大学生互助系统
Excel - VBA的隔行拷贝功能
Python 设计模式之单例模式
文件的物理结构(连续分配,链接分配,索引分配)
【学习】一致性哈希与哈希环
- 原文地址:https://blog.csdn.net/qq_22473611/article/details/126559697