-
阅读笔记——MetaAge: Meta-Learning Personalized Age Estimators
概述
我们在之前介绍过一篇由旷世和新加坡国立联合提出的用于年龄估计的论文 C3AE,模型只有0.3MB,具备较大的实用价值。但是人脸年龄受种族、肤色、地区等因素的影响,不同的人在同一年龄有不同的外观表现,对所有人脸使用同一套参数进行年龄估计可能会造成估计偏差。MetaAge 提出年龄估计还应当考虑每个人的个人身份属性信息来获得一个更精准的年龄估计。在此基础上使用了元学习的概念进行了包装。
方法
文章的开头便写道:Different people age in different ways,对不同的人学习一个个性化的年龄估计器是一个有希望的方向。但是存在的问题是没有足够的数据集来支撑这样的任务:这需要人物身份标签以及每个人足够的长年龄段内的样本。
当前的年龄估计方法可以分为两大类:全局的年龄估计方法和个性化的年龄估计方法。全局的年龄估计方法对所有人都使用同样的年龄估计模型;个性化的年龄估计方法对不同人有个性化的年龄估计模型。但是通常个性化的年龄估计方法对数据有更高的需求:需要数据具有身份属性标签、以及每个人在不同年龄阶段有足够的图像。对于个性化的年龄估计方法来说,还没有能满足上面两个要求的大型数据集。因此文章提出,使用现有的人脸识别模型对人脸进行特征编码,免去对人脸年龄数据集的特殊要求。
全局年龄估计器
首先文章仍然使用一个全局年龄估计器(参考 Deep Expectation of Real and Apparent Age from a Single Image Without Facial Landmarks),这个估计器基于 VGG-16网络,基于这个全局年龄估计器也可以直接获取到年龄估计:首先输入图像经过一个 CNN 网络,得到一个 D D D 维特征,使用一个全连层 D × K D×K D×K,得到一个 K K K 维特征向量(这里 K = 101 K=101 K=101,表示 101 个年龄分段);然后基于这个 101 维度特征进行加权求和得到最终的估计年龄,如下式所示:

个性化年龄估计器
文章首先将这个个性化年龄估计器使用元学习进行了一下包装。
元学习通常需要有大量的训练任务,来学习如何适应到新的任务。在一部分任务上训练元学习器,另一部分任务上测试元学习器的精度。每个任务都对应一批数据。文章认为个性化的年龄估计器刚好满足元学习的这些需求:一个年龄数据集中存在大量的人物样本,每个人物样本对应少量的不同年龄段的人脸数据,可以在一部分人物上训练元学习器,在另一部分人物数据上测试元学习器的性能。而现有的年龄数据集中没有人物 ID 信息,因此使用人脸识别模型提取特征向量构成 ID(人脸识别网络出来的身份特征包含了丰富的身份属性相关信息,例如年龄、性别、人脸形状等)。
最终的网络结构如下图所示。可以看到文章使用一个全局年龄估计特征 g ( x , θ ) g(x, \theta) g(x,θ),对一个大小为 K × D K×D K×D 的个性化年龄特征进行点积得到最终年龄输出。相比 Deep Expectation of Real and Apparent Age from a Single Image Without Facial Landmarks 中训练一个额外的全连层来得到 K K K 维的特征向量,这样的方式无疑更有优势。
 可以用下式对上图的个性化年龄估计网络进行公式化描述:
可以用下式对上图的个性化年龄估计网络进行公式化描述:
对于一张输入图像:- 首先使用 MTCNN 进行人脸检测并进行人脸对齐,然后将对齐后的人脸 resize 以及crop到 224 × 224 224×224 224×224大小;
- 然后处理后的图像被送入g() 和 h() 用来提取年龄特征和身份特征。g() 使用VGG-16网络,其在 IMDB-WIKI 上进行了预训练,使用倒数第二层的 4096 维度特征作为年龄特征。对于h(),使用了 Resnet-50 版本的VGGFace2 网络,得到2048维度的特征;
- 而r(),则是一个两层的全连层,它的输入是 h() 的输出(身份信息)、 w i c w^c_i wic(一个额外的特征向量) 以及年龄 i i i 的 one-hot 编码(实验中发现把发现将这样一个年龄作为特征输入提升了网络性能)。因此r()的总输入维度是 6245 = 4096 + 2048 + 101 6245=4096+2048+101 6245=4096+2048+101,最后输出4096维度的特征。
损失函数
损失函数方面使用交叉熵损失和合页损失,如下式所示。其中 y y y 是 GT 年龄。

在合页损失方面,对于每张图像的 GT 年龄,都希望接近这个年龄的输出相比远离这个年龄的输出有更大的预测概率。哈哈这个损失用得还有点意思。


总损失是两者的加权和:

其中 λ = 0.2 , δ = 2 \lambda=0.2,\delta=2 λ=0.2,δ=2。并且训练期间用于人脸特征提取的网络不进行参数更新。实验结果
评估标准
文章使用 MAE(mean absolute error) 和 CS(cumulative score) 作为评估标准。两者的计算公式如下式所示:
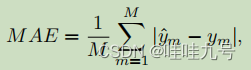

其中 M ( θ ) M(\theta) M(θ) 表示估计年龄误差在 θ \theta θ 范围内的图像张数。除此之外还用到了 ϵ − e r r o r \epsilon-error ϵ−error 指标:

其中 σ m \sigma_m σm 表示第 m m m 个测试样本的标注标准差。小讨论
文献提出了 MetaAge,在全局特征基础上结合了人物个性化特征获得更精准的年龄估计。但是存在一些更简单的方法,例如可以直接 concat 全局年龄估计特征和一个身份特征,然后使用全连层获取年龄估计。文章也进行了对比实验,可以看到虽然识别精度没有 MetaAge 高,但是仍然不错了。

其中 Baseline 就是一个全局年龄估计器。指标对比
在 MORPH Ⅱ 数据集上的对比如下图所示。可以看到 MetaAge 精度最高:

-
相关阅读:
Linux学习之MySQL建表
Spring Boot技术知识点:如何解读@Validated注解
保研复习-计算机组成原理
SAP gui 登录条目不让修改
ShardingSphere数据分片
MyBatis-Plus
ActiveMQ、RabbitMQ、RocketMQ、Kafka四种消息中间件分析介绍
来围观|大佬们都是如何处理风控特征变量池的
Mysql
CentOS安装mysql8
- 原文地址:https://blog.csdn.net/bengyanluo1542/article/details/126562609