-
B+树索引(11)之索引挑选(上)
B+树索引(11)之索引挑选(上)
前言
之前的文章从索引的基本结构聊到索引存储又聊到索引的适用场景,我们已经对索引有了一个大致的认识,索引相关文章参考
这次我们聊聊怎么去选择索引,一个正确的索引可以花最小的代价换取最大的性能!
索引的挑选原则
只为搜索排序分组相关列创建索引
也就是说只为出现在where条件中的列(包含连接语句中的列),order by排序中的列,group by分组中的列建立索引,其余的不考虑建立索引,即使出现在查询列表(select查询列)中,如下SQL
select birthday,country,phone_number from person_info where name = 'Aaron';- 1
我们可以给name字段建立索引,但除此外birthday、country、phone_number这些字段都不用加索引,因为我们需要明白的是索引的目的是加快检索速度,快速定位,如果起不到定位的字段通常不需要创建索引。
每个数据页的大小通常是16kb,如果除了给name加索引外还给birthday、phone_number加索引,这样会导致数据页存储记录的数量减少,那么B+树需要维护的叶子节点就会增多,查找效率也会降低,如下

如果仅仅给name列建立索引,那么每个叶子节点的记录只保存name值和主键id值,自然占用空间小,查找效率相对就高。
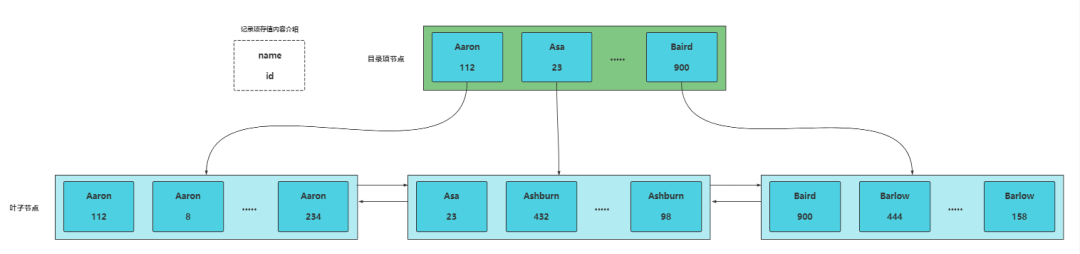
另外这里可能有人会考虑回表的性能消耗,因为仅仅只给name列建立索引那么birthday、country、phone_number这三列需要回表从聚簇索引上获取,会带来一定的性能消耗,其实这里就需要从业务层面考虑。
如果条件**name = ‘Aaron’**得到的记录只有少数的几项那么即使回表对于整个SQL的查询性能影响不大。
如果条件**name = ‘Aaron’**得到了大量的记录,那么回表将是巨大的性能消耗,还不如不用索引(全表扫描)或者采用索引覆盖解决。
索引列区分度要高
区分度一般用基数来表示,什么是基数呢?一个列数值不重复的个数。
例如存在列a的数据为2、5、6,8,6,2,5,5,6,8该列实际存在10条数据,而列a的基数为4(相当于给列a进行去重)。
也就是说如果索引列为主键或者用UNIQUE(唯一性约束)那么该列的基数就应该等于该列的行数,基数越大索引效果越好,基数越小索引检索效果越差(当基数太小优化器可能会放弃使用索引,采用全表扫描)。
在日常业务中最常见的就是性别,性别本来的值就是固定的男、女、其它这三种,性别的基数最大就是3,这种区分度极低的我们需避免使用索引。
索引列长度尽可能的小
例如一个索引列是整数类型的值,那么我们需要注意数据类型的定义方式,整数在Mysql中分为如下几种
类型 表示大小 占用字节数 TINYINT -2^7 ~ 2^7-1 1个字节 SMALLINT -2^15 ~ 2^15-1 2个字节 MEDIUMINT -2^23 ~ 2^23-1 3个字节 INT(INTEGER) -2^31 ~ 2^31-1 4个字节 BIGINT -2^63 ~ 2^63-1 8个字节 当我们在创建表时需要根据业务选择,当能用SMALLINT表示时就不要用MEDIUMINT,能用MEDIUMINT表示时就不要用INT,原因是,数据类型越小,索引所占用的空间就会更小,一个数据页存放的数据就会越多,从而就能减少磁盘IO带来的性能消耗,加载到内存中的记录数就越多,对于查询来讲效率就越高。
这个规则更加适用于主键索引,为什么呢?因为主键索引的列值不仅仅需要保存在聚簇索引中,还需要保存在二级索引的记录中,主键值越小那么越节省空间,磁盘IO越高效。
-
相关阅读:
Linux :远程访问的 16 个最佳工具(一)
【博主已解决】【npm】npm publish 发布包报错 代码:ERR400
vue中的生命周期有什么,怎么用
一个有关sizeof的题目
一篇文章熟练掌握Git
劣币驱良币的 pacing 之殇
Kafka MQ 如何处理请求
聚合电商API接口平台:让数据成为生产力!
003传统图机器学习、图特征工程
花费三个月整理的MySQL系列文档 诚意之作 看完不亏
- 原文地址:https://blog.csdn.net/zzf1233/article/details/126563802