-
离线强化学习(Offline RL)系列7: (状态处理) OfflineRL中的状态空间的数据增强(7种增强方案)

Arxiv原文:S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning in Robotics
本文是由多伦多大学、斯坦福大学和Nvidia三家合作完成的工作,发表在5th Conference on Robot Learning (CoRL2021)会议上。
现有的OfflineRL存在(1)对训练数据集过度拟合;(2)在部署时表现出对环境的分布外(OOD)泛化能力差的问题,本篇论文作者研究了在 状态空间上执行数据增强 的有效性,并通过7种不同的增强方案在OfflineRL环境环境中进行了实验。结果不表明使用 S4RL(简单自我监督技术, Surprisingly Simple Self-Supervision in RL) 可以显着改进离线机器人学习环境中的效果。
当前的offline model-free强化学习算法包括学习 Q Q Q 函数,其中训练参数化神经网络以从数据中学习状态动作值。 这一系列算法高估了与所使用的离线数据集不同分布的数据的真实状态-动作值。 除了高估误差外,另一个误差来源是神经网络的函数逼近,通常用于参数化 Q Q Q 函数。 由于在训练期间状态-动作分布是静态的,因此神经网络可能会过度拟合数据,从而在部署到实际环境时进一步导致泛化能力差。 为了阻止神经网络中的过度拟合,可以利用数据增来解决。
流行的actor-critic算法中,例如Soft Actor Critic (SAC),在从离线数据集学习时往往表现不佳,因为它们由于高估偏差(overestimate)而无法推广到分布外 (OOD) 数据: Critic高估了以前从收集的数据中没有遇到的状态-动作对的值,会导致了一个脆弱策略(brittle policy)。
1. Representation Learning in RL
一系列的研究表明,使用表示学习对强化学习的特征提取帮助非常大。
表示学习(Representation Learning) 的目的是对复杂的原始数据化繁为简,把原始数据的无效的或者冗余的信息剔除,把有效信息进行提炼,形成特征(feature),这个2013年的时候Yoshua Bengio就写了一篇综述Representation Learning: A Review and New
Perspectives, 它和特征工程的区别如下: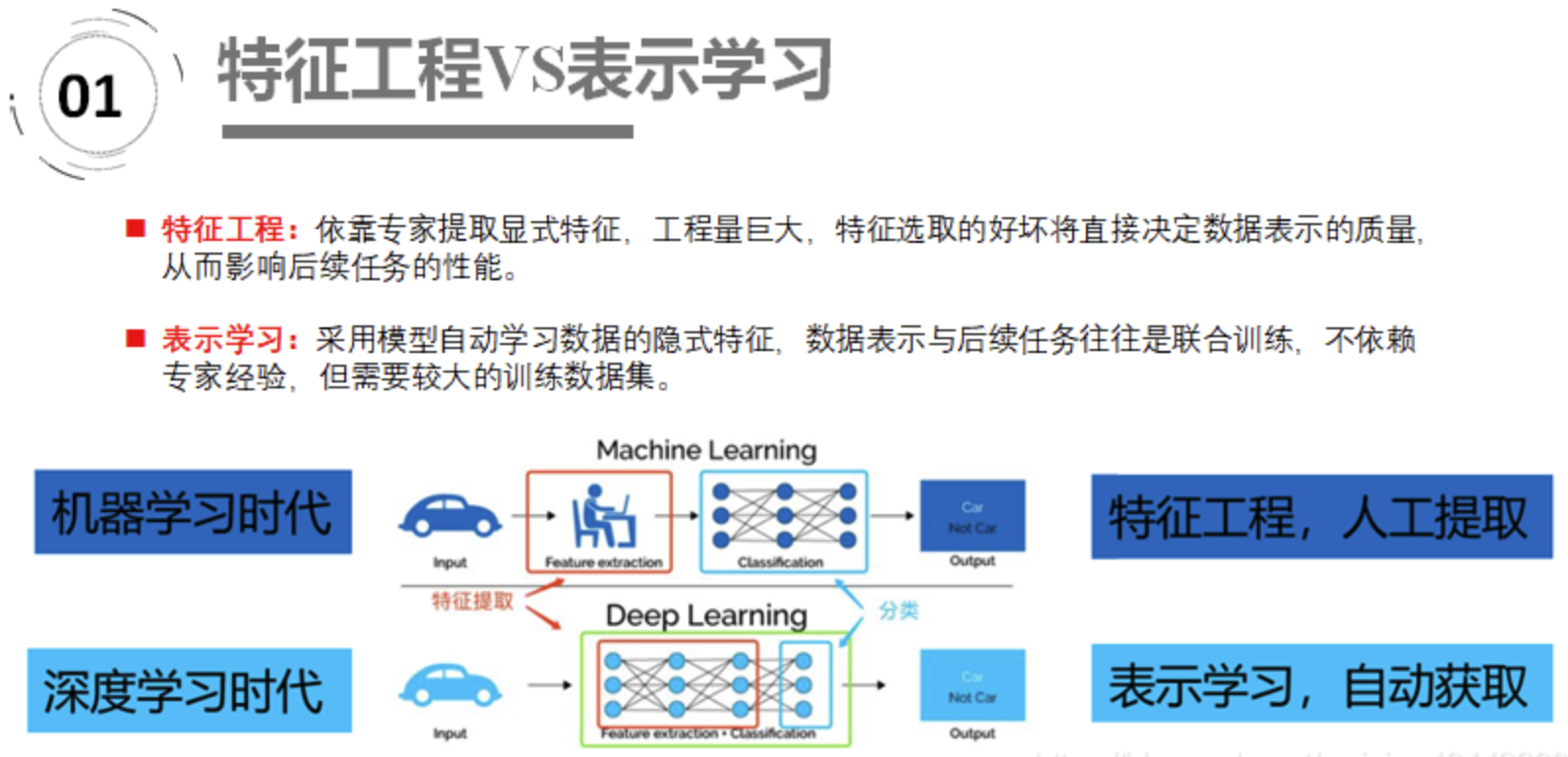
而将表示学习与RL结合起来,它的结构如下
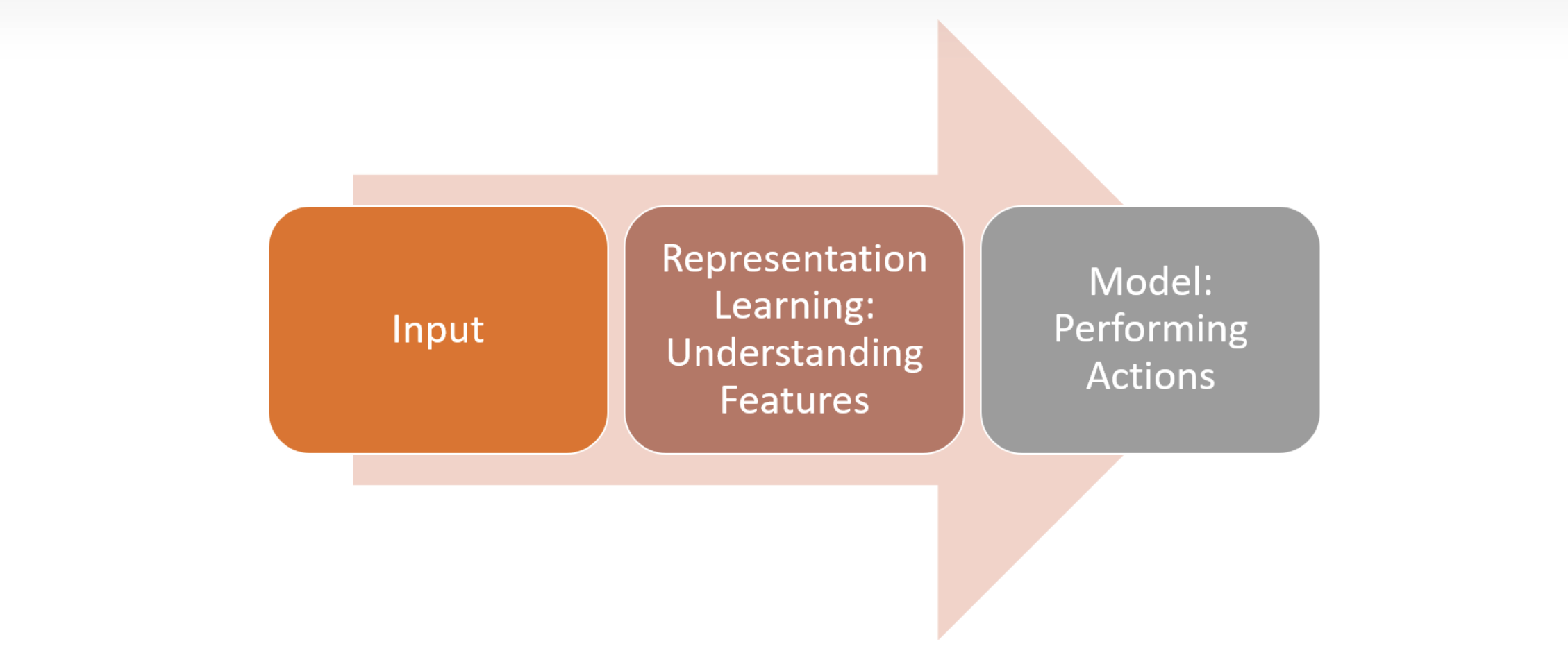
其中最重要的为中间这一部分,即理解特征(PS:强化学习中状态空间过大,特别是无用的特征对算法的收敛也会造成影响,导致算法的收敛、稳定性差)这一层。
本文中作者介绍的数据增强(Data Augementation)主要在状态的提取和策略生成这一层,从图中可以看到直接从Offline Dataset中进行提取数据,通过了 T 1 ( s t ) T_{1}(s_{t}) T1(st) 和 T 2 ( s t ) T_{2}(s_{t}) T2(st)两种方式。然后通过状态空间中的局部扰动具有相似的 Q Q Q 值进行估计,使用增强状态来计算 Q Q Q 值和目标值,以更好地逼近 Q Q Q 网络的函数。

它和传统的RL的区别可以用下图表示,作者特意说: 使用数据增强,能够平滑数据集 s t s_{t} st 中观察值周围的局部状态空间。, 所以核心点就是 *smoothening the state space

而作者这里在的DrQ算法(通过鼓励州周围的局部点具有相似的 Q 值,这有助于在训练期间结合数据增强和学习更好的价值函数。)基础上进行数据增强
DrQ(Data-regularized Q,)算法,是由纽约大学的Ilya Kostrikov提出的Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels, 主要讲述了”在输入数据的层面对强化学习算法作数据增广,就可以达到 CURL 使用 contrastive learning 进行学习的方法的性能。CURL在学习中使用 negative 样本的过程其实也用到了数据增广,只不过 DrQ 直接将这一过程放在了神经网络的数据层面,而非特征学习的层面。通过简单的数据增广可以在很大程度上提升性能。在 RL 中的数据增广基于一个假设,在输入 state 层面进行微弱变化之后的 state 和原有的 state 拥有类似的 value function 估计。“,数学表示为:
Q ( s , a ) = Q ( f ( s , ν ) , a ) for all s ∈ S , a ∈ A and ν ∈ T Q(s, a)=Q(f(s, \nu), a) \text { for all } s \in \mathcal{S}, a \in \mathcal{A} \text { and } \nu \in \mathcal{T} Q(s,a)=Q(f(s,ν),a) for all s∈S,a∈A and ν∈T
具体关于DrQ的内容可以看这篇把博客Image Augmentation Is All You Need, 下面我们继续本文。
2. Data augmentation transformation
我们将数据增强的转换过程定义为:
T ( s ~ t ∣ s t ) where s t ∼ D \mathcal{T}\left(\tilde{s}_{t} \mid s_{t}\right) \text { where } s_{t} \sim \mathcal{D} T(s~t∣st) where st∼D这里的 s ~ t \tilde{s}_{t} s~t 表示增强状态,而 T \mathcal{T} T 表示一个随机转换, 作者通过使用对比学习将同一状态的两个增强表示“拉”向彼此,同时将两个不同的状态表示“推”开。
在这里作者同样类似于DrQ算法: 对给定状态执行多次增强,并且我们简单地对状态的不同增强中的状态-动作值和目标值进行平均, 数学表示为:
min Q E s t , a t ∼ D [ r t + γ 1 i ∑ i Q ( T i ( s ~ t + 1 ∣ s t + 1 ) , a t + 1 ) − 1 i ∑ i Q ( T i ( s ~ t ∣ s t ) , a t ) ] \min _{Q} \underset{s_{t}, a_{t} \sim \mathcal{D}}{\mathbb{E}}\left[r_{t}+\gamma \frac{1}{i} \sum_{i} Q\left(\mathcal{T}_{i}\left(\tilde{s}_{t+1} \mid s_{t+1}\right), a_{t+1}\right)-\frac{1}{i} \sum_{i} Q\left(\mathcal{T}_{i}\left(\tilde{s}_{t} \mid s_{t}\right), a_{t}\right)\right] Qminst,at∼DE[rt+γi1i∑Q(Ti(s~t+1∣st+1),at+1)−i1i∑Q(Ti(s~t∣st),at)]

接下来我们继续看看是如何数据增强的,作者这里提出了7种不同的数据增强方法。

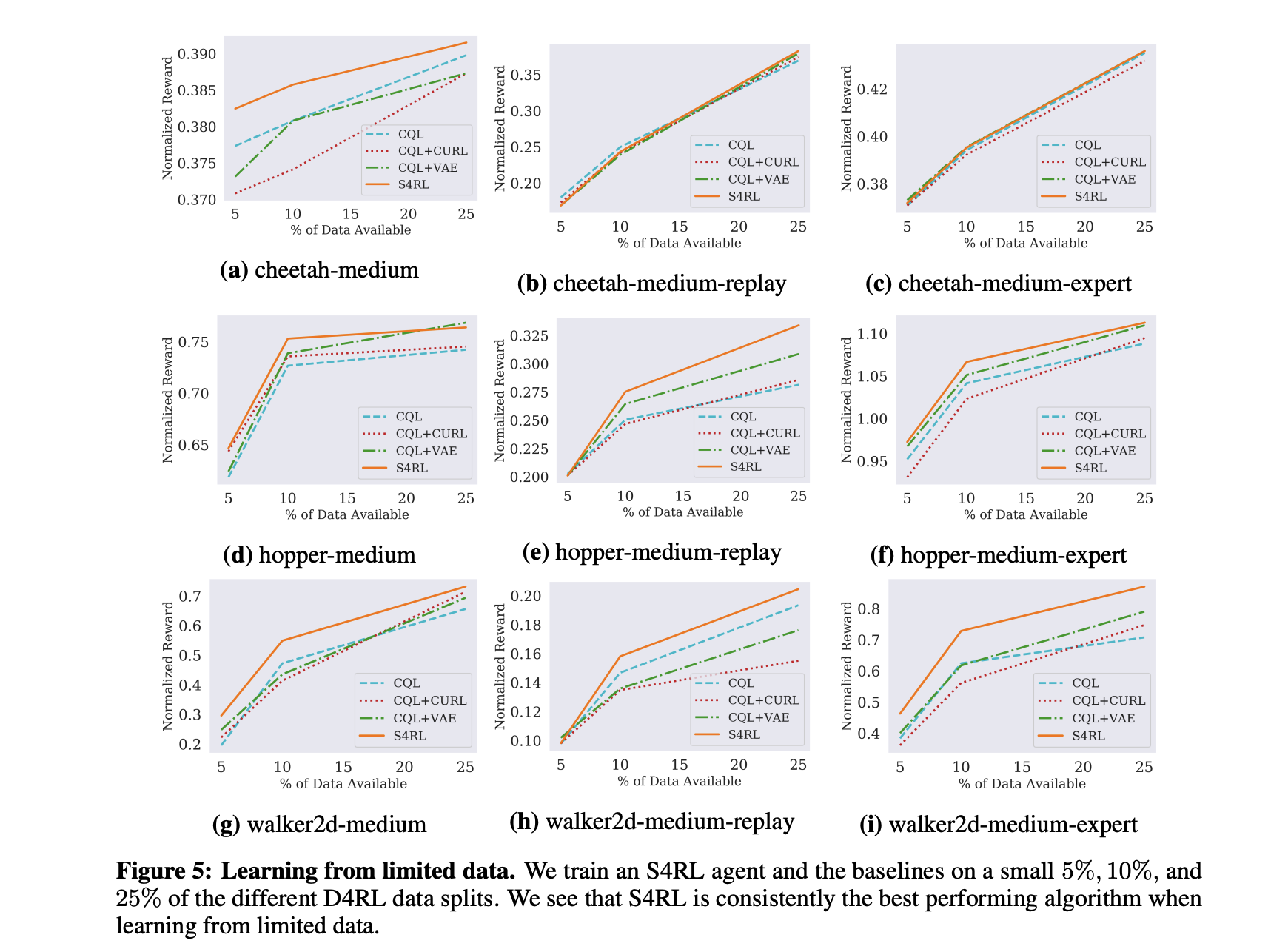
作者通过Offline RL 中两种常见的CQL 离线强化学习(Offline RL)系列3: (算法篇) CQL 算法详解与实现和 BRAC 离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BRAC算法原理详解与实现(经验篇)算法进行了对比实验,结果如下:


参考文献:
[1]. Samarth Sinha, Ajay Mandlekar, Animesh Garg: “S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning”, 2021; arXiv:2103.06326.
[2]. Ilya Kostrikov, Denis Yarats, Rob Fergus: “Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels”, 2020; arXiv:2004.13649.
OfflineRL推荐阅读
离线强化学习(Offline RL)系列6: (采样效率) OfflineRL中的样本选择策略
离线强化学习(Offline RL)系列5: (模型参数) 离线强化学习中的超参数选择
离线强化学习(Offline RL)系列4:(数据集) 经验样本复杂度对模型收敛的影响分析
离线强化学习(Offline RL)系列4:(数据集)Offline数据集特征及对离线强化学习算法的影响
离线强化学习(Offline RL)系列3: (算法篇) AWAC算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) AWR(Advantage-Weighted Regression)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) Onestep 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) IQL(Implicit Q-learning)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) CQL 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) TD3+BC 算法详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇) REM(Random Ensemble Mixture)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BRAC算法原理详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BEAR算法原理详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BCQ算法详解与实现
离线强化学习(Offline RL)系列2: (环境篇)D4RL数据集简介、安装及错误解决
离线强化学习(Offline RL)系列1:离线强化学习原理入门 -
相关阅读:
数说故事《汽车行业全场景数字化解决方案》之产品管理解决方案
JDK API
《LeetCode力扣练习》代码随想录——二叉树(找树左下角的值---Java)
推箱子游戏设计与实现(Java+swing+JAWT)
数字调制与星座图
企业数字化转型建设过程中需要哪些能力?
【高等数学基础进阶】二重积分
【牛客面试必刷TOP101】Day9.BM37 二叉搜索树的最近公共祖先和BM42 用两个栈实现队列
雪花是否一样问题
C#底层库--随机数生成类
- 原文地址:https://blog.csdn.net/gsww404/article/details/126556524