-
线性代数学习笔记7-1:特征值、特征向量、迹、特征基
特征向量:经历特定线性变换后,只受到伸缩影响的特殊向量
首先注意前提:特征值和特征向量,仅针对方阵讨论,因为非方阵不可能满足定义式 A v ⃗ = λ v ⃗ \mathbf A \vec v=\lambda \vec v Av=λv的维度要求
特征向量(Eigenvectors) v ⃗ \vec v v:线性变换后,仍保持在其原张成空间内的向量(方向不变或反向)
特征值(Eigenvalue) λ \lambda λ:衡量特征向量在线性变换中被拉伸/压缩的比例因子
它们之间的关系记作: A v ⃗ = λ v ⃗ \mathbf A \vec v=\lambda \vec v Av=λv- 特别注意,特征值
λ
=
0
\lambda=0
λ=0的特征向量,意味着它是
A
v
⃗
=
0
\mathbf A \vec v=0
Av=0的解,则特征向量
v
⃗
\vec v
v位于
A
\mathbf A
A的零空间中;
另外,假如 A \mathbf A A不可逆/奇异/不满秩,则零空间不只有零向量,即特征值 λ = 0 \lambda=0 λ=0的特征向量有无数个( A \mathbf A A对应降维的线性变换,有大量非零向量被压缩为零向量)
考虑一个变换,其i轴被拉伸,其j轴向i轴倾斜,我们可以写出对应的变换矩阵

考虑一个向量 v ⃗ = [ 2 , 1 ] T \vec v=[2,1]^T v=[2,1]T
在变换前,它的张成空间span为其所在的直线;
在变换后,由于整个空间的“压缩”,这个向量离开了它原先的张成空间

另一方面,也的确存在一些特殊的向量,在变换后留在其原来张成的空间内
线性变换对这些向量的作用,仅是压缩/拉伸,就好像是一个标量的作用一样
- x轴上的所有向量留在原span内,容易理解
- 隐蔽的是,处于变换后的新坐标系的基向量张成的对角线上的任意向量,例如(-1, 1),同样留在其span内
举例理解特征向量
Eg1. 对于所有列向量线性无关的矩阵 A \mathbf A A,他代表了一个平面,而投影矩阵 P = A ( A T A ) − 1 A T \mathbf P=\mathbf A(\mathbf A^T\mathbf A )^{-1}\mathbf A^T P=A(ATA)−1AT能够将平面外的向量投影到平面上,例如将向量 b \boldsymbol b b投影到平面上得到的 p = P b = A ( A T A ) − 1 A T b \boldsymbol p=\mathbf P\boldsymbol b=\mathbf A(\mathbf A^T\mathbf A )^{-1}\mathbf A^T\boldsymbol b p=Pb=A(ATA)−1ATb
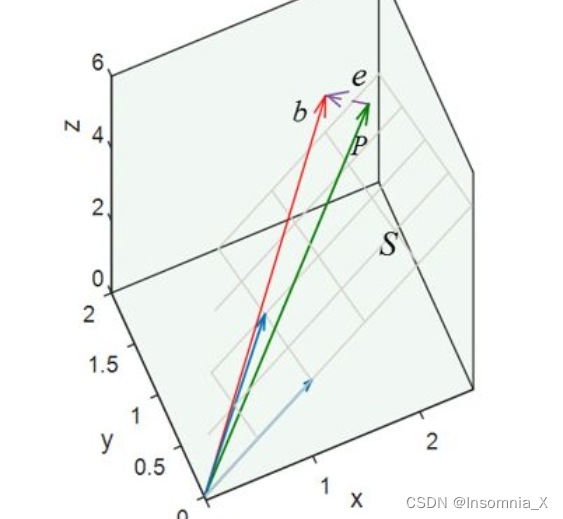
现在,求投影矩阵 P \mathbf P P的所有特征值和特征向量- 矩阵 A \mathbf A A对应的平面(列空间)上所有向量都是特征值 λ = 1 \lambda=1 λ=1特征向量: A v ⃗ = v ⃗ \mathbf A \vec v=\vec v Av=v
- 垂直于平面的所有向量(零空间,与列空间互相正交),都是特征值 λ = 0 \lambda=0 λ=0特征向量: A v ⃗ = 0 \mathbf A \vec v=0 Av=0
- 注意,这里由于投影矩阵是对称矩阵,故行空间=列空间,又因为零空间与行空间间互为正交补,所以这里零空间与列空间间互为正交补,故: P \mathbf P P的特征向量互相垂直,所有特征向量张成了整个空间
Eg2. 置换矩阵 A = [ 0 1 1 0 ] A=\left[0110\right] A=[0110],其作用是将向量的两行位置互换,求其所有特征值和特征向量
- 就是要寻找互换两坐标后,仍在同一直线上的向量
- 向量
[
1
1
]
\left[\right] [11]是特征值 λ = 1 \lambda=1 λ=1特征向量: A v ⃗ = v ⃗ \mathbf A \vec v=\vec v Av=v
1 1 - 向量
[
1
−
1
]
\left[\right] [1−1]是特征值 λ = − 1 \lambda=-1 λ=−1特征向量: A v ⃗ = − v ⃗ \mathbf A \vec v=-\vec v Av=−v
1 − 1 - 这些特征向量张成了整个空间
- 因为是对称矩阵,其特征向量互相垂直
给出矩阵(某种变换),求解其特征向量
进一步的,要求解某个变换矩阵对应的特征向量 v ⃗ \vec v v
就是求下面方程的解(其中 v ⃗ \vec v v是待求解的量,并且需要非零解): ( A − λ I ) v ⃗ = 0 \mathbf{( A-\lambda I)} \vec v=0 (A−λI)v=0- 根据求解齐次线性方程组的知识,该方程必有一个解是零向量,然而这个解无意义,我们需要的是非零解
上式有非零解 ⇒ \Rightarrow ⇒,仅当 d e t ( A − λ I ) = 0 det \mathbf{( A-\lambda I)}=0 det(A−λI)=0,即矩阵 ( A − λ I ) ( A-\lambda I) (A−λI)不可逆/奇异,或线性变换使得空间被压缩降维 - 对于 d e t ( A − λ I ) det \mathbf{( A-\lambda I)} det(A−λI),这是一个关于未知量 λ \lambda λ的多项式 f ( λ ) f(\lambda) f(λ),称为特性多项式
- 综上,这个问题,最终变为:寻找合适的
λ
\lambda
λ值,使得
d
e
t
(
A
−
λ
I
)
=
0
det \mathbf{( A-\lambda I)}=0
det(A−λI)=0成立,然后再带入特定的
λ
\lambda
λ值,求解
(
A
−
λ
I
)
x
=
0
\mathbf{( A-\lambda I)}\boldsymbol x=0
(A−λI)x=0得到特征向量
x
\boldsymbol x
x(利用消元法,求主元列和自由列…)
这里由于 d e t ( A − λ I ) = 0 det \mathbf{( A-\lambda I)}=0 det(A−λI)=0,可以看出,对于每个特征值 λ \lambda λ,矩阵 ( A − λ I ) \mathbf{( A-\lambda I)} (A−λI)必为不可逆矩阵/奇异矩阵,从而方程有无数个非零解/存在(非零的、有效的)特征向量
也就是说,任何特征值,都对应一个特征子空间(而不仅仅是一个特征向量)
注意:一般与特征向量对应的特征值都是实数
而特征值为虚数的情况,对应于变换中出现了某种旋转(例如对于旋转90°矩阵求特征值为 i \boldsymbol i i,联系复平面内乘以 i \boldsymbol i i的效果)特征值和特征向量有什么用?
- 考虑三维空间中的三维向量,用一个3x3矩阵对其做“旋转”的线性变换,如果能找到这个变换中的特征值为1的特征向量(在变换过程中,始终留在其张成空间内的向量),那么就找到了旋转轴!(进一步可以将旋转视为绕轴一定角度的旋转,这比矩阵描述更直观)
- 并且,之前将矩阵的列向量看作基向量去向的做法,非常依赖于当前所用的坐标系(在其他的坐标系下,同一矩阵表示的变换完全不同),而特性向量则避开了对特定坐标系的依赖,只关注变换的特性本身
特征值的性质
- 任意 n × n n\times n n×n矩阵,一定有 n n n个特征值,但其中可能有重复的特征值
- 特征值的物理意义:物体都有一个自身的内禀结构,特征向量显示了物体内结构的方向,特征值则是在这个主方向上物体对外场的响应参数,也称伸缩系数,实际上它反应了在其所对应的特征向量方向上,内结构与外场之间的相互关系。
- 特征值可以作为降维的判据:降维的线性变换,矩阵不可逆/行列式为0
⇒
\Rightarrow
⇒至少存在一个特征值为零(对应的特征向量就是方程Ax=0解/A的零空间中的所有向量)
数学上理解,奇异矩阵的齐次方程有无穷个非零解;几何上理解,奇异矩阵对应了降维的线性变换,从而有许多向量被变为零向量(也就是特征值为零的特征向量)
应用:在图像压缩过程中,极小的特征值会被赋值为0,从而节省存储空间,降维后的图像基本轮廓依旧清晰,图像细节有所牺牲
- 迹trace=
λ
1
+
λ
2
+
.
.
.
+
λ
n
\lambda_1+\lambda_2+...+\lambda_n
λ1+λ2+...+λn=矩阵对角线上的元素之和
这个性质可以用于求解未知的特征值 - 行列式=
λ
1
λ
2
.
.
.
λ
n
\lambda_1\lambda_2...\lambda_n
λ1λ2...λn
对于特征多项式因式分解,可以直观看出每一项对应一个根,从而对于二阶方阵,其特征多项式就是 λ 2 − t r a c e ( A ) λ + d e t ( A ) = 0 \lambda^2-trace(\mathbf A)\lambda+det(\mathbf A)=0 λ2−trace(A)λ+det(A)=0 - 对称矩阵的特征向量正交,因为对称矩阵对角化后,得到正交矩阵
A
=
Q
Λ
Q
−
1
=
Q
Λ
Q
T
\boldsymbol{A}=\boldsymbol{Q} \boldsymbol{\Lambda} \boldsymbol{Q}^{-1}=\boldsymbol{Q} \boldsymbol{\Lambda} \boldsymbol{Q}^{T}
A=QΛQ−1=QΛQT
证明:设对称矩阵 A \mathbf A A满足 A x 1 = λ 1 x 1 \mathbf Ax_1=\lambda_1x_1 Ax1=λ1x1、 A x 2 = λ 2 x 2 \mathbf Ax_2=\lambda_2x_2 Ax2=λ2x2
第一个式子同乘 x 2 T x_2^T x2T则有 x 2 T A x 1 = λ 1 x 2 T x 1 x_2^T\mathbf Ax_1=\lambda_1x_2^Tx_1 x2TAx1=λ1x2Tx1,又由第二个式子得到 x 2 T A x 1 = ( A T x 2 ) T x 1 = ( A x 2 ) T x 1 = λ 2 x 2 T x 1 x_2^T\mathbf Ax_1=(\mathbf A^T x_2)^Tx_1=(\mathbf A x_2)^Tx_1=\lambda_2 x_2^T x_1 x2TAx1=(ATx2)Tx1=(Ax2)Tx1=λ2x2Tx1,
从而有 ( λ 1 − λ 2 ) x 2 T x 1 = 0 (\lambda_1-\lambda_2) x_2^T x_1=0 (λ1−λ2)x2Tx1=0,又 λ 1 ≠ λ 2 \lambda_1\neq\lambda_2 λ1=λ2,故 x 2 T x 1 = 0 x_2^T x_1=0 x2Tx1=0,两特征向量正交 - 三角矩阵的特征值就是矩阵对角线上的元素
原因:三角阵的特征多项式 d e t ( A − λ I ) = 0 det(\mathbf A-\lambda \mathbf I)=0 det(A−λI)=0,该行列式为上三角的,因此行列式就等于对角元上元素的乘积,从而 A \mathbf A A的对角线元素就是特征多项式的根
例如对于三角阵 A = [ 3 1 0 3 ] \boldsymbol{A}=\left[3103\right] A=[3013],可以解得 λ 1 = λ 2 = 3 \lambda_1=\lambda_2=3 λ1=λ2=3,两者对应同一个特征向量 x 1 = [ 1 0 ] \mathbf{x}_{1}=\left[10\right] x1=[10];
- 特征值有重根,特征向量可能线性相关,此时意味着矩阵
A
\mathbf A
A是一个退化矩阵(特征向量短缺,对应降维的线性变换)
出现重复的特征值,我们认为这是一种“最坏”的情况 -
A
\mathbf A
A特征值为
λ
\lambda
λ,则
A
+
k
I
\mathbf A+k\mathbf I
A+kI的特征值为
λ
+
k
\lambda+k
λ+k
证明:原来的特征值满足 d e t ( A − λ I ) = 0 det(\mathbf A-\lambda\mathbf I)=0 det(A−λI)=0,那么 d e t [ ( A + k I ) − λ ′ I ] = 0 det[(\mathbf A+k\mathbf I)-\lambda'\mathbf I]=0 det[(A+kI)−λ′I]=0的解为 λ ′ = λ + k \lambda'=\lambda+k λ′=λ+k
注意,这条性质仅对于 A + k I \mathbf A+k\mathbf I A+kI生效,一般 A + B \mathbf A+\mathbf B A+B的特征值并不是各自特征值之和 -
A
\mathbf A
A和
A
T
\mathbf A^T
AT的特征值相同
原因:由于矩阵的转置后行列式不变,则 d e t ( A − λ I ) = 0 ⟺ d e t ( A T − λ I ) = 0 det(\mathbf A-\lambda\mathbf I)=0\iff det(\mathbf A^T-\lambda\mathbf I)=0 det(A−λI)=0⟺det(AT−λI)=0,故 A \mathbf A A和 A T \mathbf A^T AT的特征值相同,但是其对应的特征向量不同,因为 A \mathbf A A和 A T \mathbf A^T AT的特征向量在 ( A − λ I ) (\mathbf A-\lambda\mathbf I) (A−λI)的零空间和左零空间中,即特征向量分别为方程 ( A − λ I ) x = 0 (\mathbf A-\lambda\mathbf I)\boldsymbol x=0 (A−λI)x=0的非零解和 ( A − λ I ) T x = 0 (\mathbf A-\lambda\mathbf I)^T\boldsymbol x=0 (A−λI)Tx=0的非零解 - 若
A
\mathbf A
A特征值为
λ
\lambda
λ,则
A
2
\mathbf A^2
A2特征值为
λ
2
\lambda^2
λ2
证明:对任意矩阵,有 A = M J M − 1 \boldsymbol{A} =\boldsymbol{M} \boldsymbol{J} \boldsymbol{M}^{-1} A=MJM−1,其中 J \boldsymbol{J} J为约尔当型,则 A 2 = M J 2 M − 1 \boldsymbol{A}^2 =\boldsymbol{M} \boldsymbol{J} ^2\boldsymbol{M}^{-1} A2=MJ2M−1,可证
几何理解:两次线性变换,效果叠加,则特征向量缩放两次,特征值变为 λ 2 \lambda^2 λ2
特征值的虚实性
分三种情况:
- 对称矩阵:实数的特征值,有一组正交的特征向量
例如对于 A = [ 3 1 1 3 ] \boldsymbol{A}=\left[3113\right] A=[3113],特征值和特征向量 λ 1 = 4 , x 1 = [ 1 1 ] \lambda_{1}=4, \mathbf{x}_{1}=\left[11\right] λ1=4,x1=[11], λ 2 = 2 , x 2 = [ − 1 1 ] \lambda_{2}=2, \mathbf{x}_{2}=\left[−11\right] λ2=2,x2=[−11]
注意,这里与前面的 A 0 = [ 0 1 1 0 ] \boldsymbol A_0=\left[0110\right] A0=[0110]对比,其 λ 1 = 1 , x 1 = [ 1 1 ] \lambda_{1}=1, \mathbf{x}_{1}=\left[11\right] λ1=1,x1=[11], λ 2 = − 1 , x 2 = [ − 1 1 ] \lambda_{2}=-1, \mathbf{x}_{2}=\left[−11\right] λ2=−1,x2=[−11],可见由于 A = A 0 + 3 I \boldsymbol A=\boldsymbol A_0+3\boldsymbol I A=A0+3I,对应的特征值也加3,特征向量不变,但这个结论不是普遍成立,即两个矩阵的和的特征值不是两特征值直接相加,因为特征向量很可能并不相同因- 反对称矩阵/斜对称矩阵(anti-symmetric matrices/skew-symmetric matrices,即 A T = − A \mathbf A^T=-\mathbf A AT=−A):纯虚数的特征值,有一组正交的特征向量
例如对于正交矩阵 Q = [ 0 − 1 1 0 ] = [ cos 9 0 ∘ − sin 9 0 ∘ sin 9 0 ∘ cos 9 0 ∘ ] \boldsymbol{Q}=\left[0−110\right]= \left[cos90∘−sin90∘sin90∘cos90∘\right] Q=[01−10]=[cos90∘sin90∘−sin90∘cos90∘],该矩阵对应了90°的旋转变换,应该不存在只受伸缩的特征向量(没有实数特征值),可以解得 λ 1 = i 和 λ 2 = − i \lambda_{1}=i \text { 和 } \lambda_{2}=-i λ1=i 和 λ2=−i
- 介于两者之间的矩阵:有实数特征值,也有复数的特征值
特征值若为复数,则一定共轭成对出现,即两个共轭复数必然同时为特征值
实数特征值对应特征向量的伸缩,虚数特征值对应特征向量的旋转
特征向量的性质
- 当满足
A
T
A
=
A
A
T
\boldsymbol{A}^{T} \boldsymbol{A}=\boldsymbol{A} \boldsymbol{A}^{T}
ATA=AAT,则矩阵
A
\boldsymbol{A}
A必然具有正交的特征向量
典型的例子就是对称矩阵(包括正交矩阵)和反对称矩阵
迹
- 迹trace= λ 1 + λ 2 + . . . + λ n \lambda_1+\lambda_2+...+\lambda_n λ1+λ2+...+λn=矩阵对角线上的元素之和
迹实际上是一种是相似不变量(它仅由线性变换决定,但具体可以表现为多个相似矩阵),它就像是线性变换在矩阵中留下的“痕迹”
- 对于同一个线性变换,假如我们依赖的坐标系/基向量不同,这个变换对应的矩阵也就不同,但这两个矩阵是相似矩阵
- 相似矩阵的迹相同(迹与坐标系的选择无关)
- 类似的,特征值、行列式(描述某个变换的面积/体积缩放比例)、秩(描述列空间的维数)都是相似不变量
为什么会有相似不变量?
抓住核心:相似矩阵,始终描述同一个线性变换,因此这个线性变换虽然有不同的表现形式(相似矩阵),但其某些核心特性是固定了的
根据 特征值分解,矩阵 A = P − 1 Λ P \mathbf{A=P^{-1}\Lambda P} A=P−1ΛP,其中 Λ \Lambda Λ为 d a i g ( λ 1 , λ 2 , . . . , λ n ) daig(\lambda_1,\lambda_2,...,\lambda_n) daig(λ1,λ2,...,λn),而 P P P为对应的特征向量组成的矩阵,显然这里 A A A和 Λ \Lambda Λ也是相似矩阵,可见, Λ \Lambda Λ将同一个线性变换对应的各个相似矩阵联系起来(不同的相似矩阵, Λ \Lambda Λ相同,i.e.它们都有相同的特征值,但 P P P不同,因为同一个变换,特征向量缩放比例一致,但是不同坐标系下观察到的特征向量不同)
进一步的,不同相似矩阵,其特征值固定,才导致了:
- 迹= λ 1 + λ 2 + . . . + λ n \lambda_1+\lambda_2+...+\lambda_n λ1+λ2+...+λn是相似不变量
- 行列式= λ 1 ⋅ λ 2 ⋅ . . . ⋅ λ n \lambda_1\cdot\lambda_2\cdot...\cdot\lambda_n λ1⋅λ2⋅...⋅λn是相似不变量
同一个变换,不管在什么坐标系下进行(表现为不同的相似矩阵),其“核心特性”——特征值始终不变,(这就是为什么要称之为“特征”),特征值不变也决定了行列式、迹不变,他们都是相似不变量
- 特别注意,特征值
λ
=
0
\lambda=0
λ=0的特征向量,意味着它是
A
v
⃗
=
0
\mathbf A \vec v=0
Av=0的解,则特征向量
v
⃗
\vec v
v位于
A
\mathbf A
A的零空间中;
-
相关阅读:
7、python中的多进程的创建与启动
数仓项目拉链表
跬智信息(Kyligence)成为信创工委会技术活动单位
不适用于云的应用程序有哪些?
编程逻辑入门必备:演绎推理
【FPGA】zynq 单端口RAM 双端口RAM 读写冲突 写写冲突
【目标检测算法】YOLO-V1~V3原理梳理
web实现usb扫码枪读取二维码数据功能
java授权码方案 软件实现时间授权 离线授权 夏末版
使用Docker部署Consul集群并由Ocelot调用
- 原文地址:https://blog.csdn.net/Insomnia_X/article/details/125492177