-
DAT:Vision Transformer with Deformable Attention详解
源码即示例数据见文末
Windows环境下可运行
1.概述
最近,Transformer被广泛应用于视觉领域中,使用大规模数据集训练的Tranformer深度模型性能已经具备一定的优越性。但是Transformer的计算量巨大,对设备的要求更高(显存),这主要是由于每个queries patch要参加的keys过多,会导致计算成本高,收敛速度慢,并增加了过拟合的风险。并且我们往往过多的考虑了不相干的部分。
现有的研究,如swin transformer和PVT虽然有效,但手工制作的注意力模式(Swin transformer主要采用窗口,而PVT使用卷积或池化对Key和Values进行下采样)是与数据无关的,可能不是最佳的。相关的keys/values很可能被删除,而不那么重要的keys仍然被保留。
受可变形卷积的启发,作者希望能够设计出一种可变形的Transformer。但是与DCN保留卷积核的大小,而使用偏置和插值法重构卷积核内部的特征点的做法不同,作者并不是希望采用类似的方式重构每一个Patch的特征点,这在计算成本上是巨大的。作者希望能够找到最具代表性的Keys和Values,使用这些具有代表性的Keys和Values参与运算,以实现缩减计算量的目的。
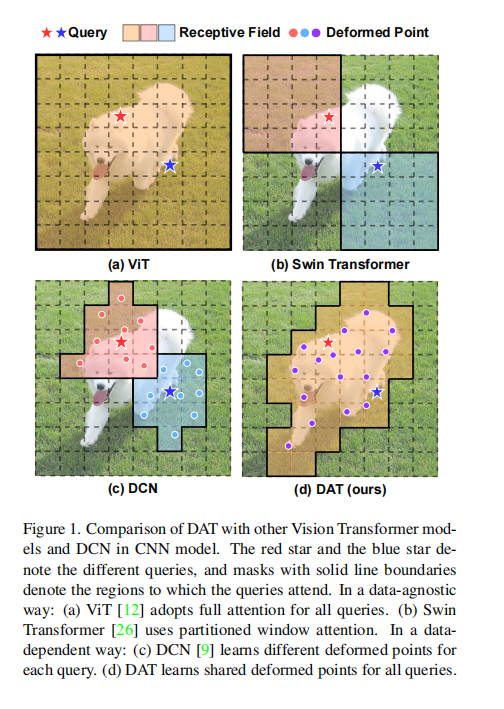
具体来说,从实现的角度,首先,初始化一组keys和values关键点,它的个数是可以进行设置的,然后使用一个网络学
-
相关阅读:
计算机毕业设计springboot+vue基本微信小程序的云宠物小程序-宠物领养
fragment如何获取activity的点击事件
C++程序设计
功能强大的开源网络监控工具:LibreNMS,牛逼!
Java并发基础
Prometheus PromQL
分词工具使用系列——sentencepiece使用
ES6空值合并运算符(??)
01. Kubernetes基础入门
Spring Boot
- 原文地址:https://blog.csdn.net/qq_52053775/article/details/126539034