-
24、D-NeRF: Neural Radiance Fields for Dynamic Scenes
简介
主页:https://www.albertpumarola.com/research/D-NeRF/index.html

NeRF只能重建静态场景,论文提出的方法可以把神经辐射场扩展到动态领域,可以在单相机围绕场景旋转一周的情况下重建物体的刚性和非刚性运动。由此把时间作为附加维度加到输入中,同时把学习过程分为两个阶段:第一个把场景编码到基准空间,另一个在特定时间把这种基准表达形式map到变形场景中。两个map都用fcn学习,训练完后可以通过控制相机视角和时间变量达到物体运动的效果。和已有的4d方式不同点有:
- 只需要一台摄像机
- 不需要预先计算三维重建
- 方法是端到端训练的
实现流程
D-NeRF可以学习一个连续的非刚性场景的体积密度表示,每个时间瞬间训练一个视图

给定一组由单目相机捕获的动态场景非刚性运动的稀疏图像,旨在设计一个深度学习模型来隐式编码场景,并在任意时间合成新的视图。

该架构由两个主要部分组成:一个变形网络Ψt,将所有场景变形映射到一个共同的正则配置,为了不失一般性,选择t = 0作为规范场景Ψt:(x, 0)→0;以及一个规范网络Ψx从每个相机射线回归体积密度和视相关的RGB颜色。给定一个3D点x = (x, y, z),预测在时间瞬间t和视图方向d = (θ, φ)的发射颜色c = (r, g, b)和体积密度σ,简单理解为映射M:(x, d, t)→(c, σ),显然可以直接学习从6D空间(x,d,t)到4D空间(c,σ)的转换M,但是效果不好,所以论文采用上述结构,将单个网络拆分为一个变形网络Ψt,规范网络Ψx。
Canonical Network and Deformation Network
变形网络Ψt(x, t)→∆x,规范网络Ψx(x +∆x, d)→(c, σ)
规范网络 Ψx 和变形网络 Ψt 都由具有 ReLU 激活的简单 8 层 MLP 组成,规范网络 Ψx可以理解为原始NeRF
变形网络 Ψt,通过给定t时刻的3D点x,训练Ψt输出位移∆x,由于选择t = 0作为规范场景,当t=0时,Ψt = 0
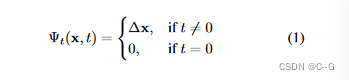
与NeRF一样,x、d和t进入网络前被编码到一个更高的维空间,γ§ =< (sin(2lπp), cos(2lπp)) >L0,L = 10表示x, L = 4表示d和tVolume Rendering
积分形式

离散形式

损失函数
最小化场景的T RGB图像{It}Tt=1及其对应的相机姿态矩阵{Tt}Tt=1的均方误差,同时学习规范Ψx和变形Ψt网络的参数

效果
使用单个Nvidia® GTX 1080进行2天的训练


-
相关阅读:
[学习记录] 设计模式 1. 设计模式介绍
Windows DHCP 筛选池同步
数据结构之二叉搜索树
1秒破解iPhone 13 Pro:可任意获取并删除设备上的数据
线上应用故障排查之一:高CPU占用
Vue中的侦听器 Watch
Unity --- 基本键鼠操作
网络安全(黑客)自学
摘要,签名、加密方式、证书
JAVA计算机毕业设计养老机构服务信息管理Mybatis+源码+数据库+lw文档+系统+调试部署
- 原文地址:https://blog.csdn.net/weixin_50973728/article/details/126524998