-
通用环形缓冲区 LwRB 使用指南
什么是 LwRB?
LwRB是一个开源、通用环形缓冲区库,为嵌入式系统进行了优化。源码点击这里(Github)。LwRB 特性
- 使用 ANSI
C99编写 FIFO(先进先出)- 无动态内存分配,数据是静态数组
- 只有单个任务写和单个任务读时,线程是安全的
- 只有单个中断写和单个中断读时,中断是安全的
- 支持内存间的 DMA 操作,实现缓冲区和应用程序内存之间零拷贝
- 对于读数据,提供
peek(窥读,读数据但不改变读指针) 、skip(跳读,向前移动读指针,将指定长度的数据标记为已读)函数,对于写数据,提供advance(跳写,向前移动写指针,比如 DMA 硬件向环形缓冲区写入了 10 字节,应用程序需要调用此函数更新写指针)函数。 - 支持事件通知
临界条件
定义
LwRB的 读指针为r,在读写操作时使用r,但仅在读操作时修改r;
定义LwRB的 写指针为w,在读写操作时使用w,但仅在写操作时修改w;
定义LwRB的 环形缓冲区大小为s,所有操作都会使用,决不会修改s。- 环形缓冲区可以容纳的最大字节数总是为
s - 1。这要求在初始化时,环形缓冲区的大小要比实际存储数据多一个字节; w、r指针总是指向下一个可写、可读位置;- 当
w == r时,环形缓冲区为空; - 当
w == r - 1时,环形缓冲区为满;
常规 API 函数
初始化函数
uint8_t lwrb_init(LWRB_VOLATILE lwrb_t* buff, void* buffdata, size_t size)- 1
用法举例:
#define QUEUE_MAX_SIZE (1024) lwrb_t format_rb; uint8_t format_data[sizeof(int) * QUEUE_MAX_SIZE + 1]; void init_format(void) { lwrb_init(&format_rb, format_data, sizeof(format_data)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里需注意环形缓冲区数组
format_data的定义格式:uint8_t format_data[sizeof(int) * QUEUE_MAX_SIZE + 1];- 1
规定写入环形缓冲区或者从环形缓冲区读出的最小数据单位是
数据项。数据项可能为 1 个字节,也可能为多个字节。
这里的例子数据项为int类型数据。
首先用宏QUEUE_MAX_SIZE定义需要保存的最大数据项数目,这里定义1024个数据项。
环形缓冲区定义为uint8_t类型的数组。
环形缓冲区数组大小可以用以下公式确定:
环形缓冲区数组大小 = 数据项大小 ∗ 数据项个数 + 1 环形缓冲区数组大小 = 数据项大小 * 数据项个数 + 1 环形缓冲区数组大小=数据项大小∗数据项个数+1
这里+ 1是因为LwRB的实现特性决定的,详见 临界条件 一节。从环形缓冲区读数据
size_t lwrb_read(LWRB_VOLATILE lwrb_t* buff, void* data, size_t btr)- 1
该函数最多读取
btr字节的数据(如果有的话),数据从环形缓冲区拷贝到data指向的数组。函数返回实际读取的字节数。
用法举例:lwrb_read(&format_rb, data_buf, sizeof(int));- 1
向环形缓冲区写数据
size_t lwrb_write(LWRB_VOLATILE lwrb_t* buff, const void* data, size_t btw)- 1
该函数最多写入
btw字节的数据(如果可以的话),数据从data指向的数组拷贝到环形缓冲区。函数返回实际写入的字节数。
用法举例:lwrb_write(&format_rb, data_buf, sizeof(int));- 1
从环形缓冲区窥读数据
size_t lwrb_peek(LWRB_VOLATILE lwrb_t* buff, size_t skip_count, void* data, size_t btp)- 1
函数
lwrb_peek也可以从环形缓冲区读取最多btp字节的数据,数据被拷贝到data指向的数组。但是它和lwrb_read函数有两点不同:- 第一,
lwrb_read函数读取数据后会移动读指针,也就是读取数据后,环形缓冲区会将这些数据移除掉;而lwrb_peek函数不移动读指针,这就意味着读取数据后,环形缓冲区不会将这些数据移除掉,就好像只是到环形缓冲区中看看这些数据都是什么样子,并不把数据拿出来,所以称为窥读。 - 第二,相比
lwrb_read函数,lwrb_peek函数多了一个skip_count参数。这个参数允许用户先跳过skip_count指定的字节数,再开始读取。
lwrb_peek对一些场景十分有用。举一个我用到的例子:
设备与上位机通讯故障后,会将本地采集的不定长数据缓存起来,缓存的格式是:

然后将这些数据存储到环形缓冲区。等到设备与上位机恢复通讯,再将这些数据去除长度字段后上传给上位机。为了数据的可靠传输,设备必须等到上位机确认数据已经收到,才能将这些数据删除掉。
所以在程序设计中,先窥读长度字段,确认长度字段合法后,再窥读剩余数据。
因为使用窥读,所以数据仍保存在环形缓冲区中,直到上位机确认数据已经收到后,再将这些数据从环形缓冲区中删除(会用到尚未介绍的 API 函数)。代码如下:#define DATA_LEN_NUM 2 //长度字段占用的字节数 #define DATA_SEND_BUF_NUM 100 //数据字段最大字节数 read_count = lwrb_peek(&resume_rb_s, 0, resume_read_buf, DATA_LEN_NUM); //窥读长度字段 /*环形缓冲区空处理*/ if(read_count != DATA_LEN_NUM) { //处理 return 0; } len = to_uint16_low_first(resume_read_buf); //长度字段 /*长度字段合法性检查*/ if(len == 0 || len > DATA_SEND_BUF_NUM) { ASSERT(0); //错误处理 return 0; } lwrb_peek(&resume_nvrb_s, DATA_LEN_NUM, resume_read_buf, len); //跳过长度字段窥读数据部分 //其它处理- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
从环形缓冲区跳读数据
size_t lwrb_skip(LWRB_VOLATILE lwrb_t* buff, size_t len)- 1
该函数最多读取
len字节的数据(如果有的话),数据并不会被保存到用户层,而是直接丢弃掉(环形缓冲区会删除这些数据),就像跳过了这些数据,所以称为跳读。
跳读一般有两个用处:- 第一,和窥读(
lwrb_peek)函数配合使用,就如窥读举例使用的场景:先窥读出数据,传送给上位机;上位机确认接收后,用跳读将这些数据丢弃掉。 - 第二,使用硬件(比如 DMA )直接读取环形缓冲区数组后,需要用跳读将这些数据丢弃掉。这会在零拷贝一节中讲解。
零拷贝
这是
LwRB的关键特性之一。可以结合 DMA 控制器实现环形缓冲区和用户内存之间的零拷贝。从环形缓冲区零拷贝读取
需要3个函数配合:
/*获取环形缓冲区的线性读地址*/ void* lwrb_get_linear_block_read_address(LWRB_VOLATILE lwrb_t* buff) /*获取读操作用到的线性数据块长度*/ size_t lwrb_get_linear_block_read_length(LWRB_VOLATILE lwrb_t* buff) /*跳读*/ size_t lwrb_skip(LWRB_VOLATILE lwrb_t* buff, size_t len)- 1
- 2
- 3
- 4
- 5
- 6
DMA 读操作需要
源地址和长度,函数lwrb_get_linear_block_read_address用于获取 DMA 需要的源地址,函数lwrb_get_linear_block_read_length用于获取 DMA 需要的长度。DMA 读取成功后,需要调用函数lwrb_skip修改r指针,将 DMA 已经读取的数据从环形缓冲区中删除掉。
DMA 只能操作线性地址,而环形缓冲区会有地址回环,因此,可能需要读取 2 次才能将环形缓冲区数据读取完。下面对这句话举例分析。
假设环形缓冲区大小s = 8(uint8_t buff_data[8]),目前处于满状态(w == r - 1),保存 7 个数据,读指针r == 5,写指针w == 4。如下图所示:
那么函数lwrb_get_linear_block_read_address返回的线性地址为读指针r所在的物理内存地址,这里为&buff_data[5],函数lwrb_get_linear_block_read_length返回的线性数据块长度为3字节(buff_data[5]~buff_data[7])。 要特别注意,虽然现在环形缓冲区有 7 字节可读,但是第一个线性连续的数据块只有 3 个字节,另外 4 字节(buff_data[0]~buff_data[3])虽然也是线性连续的,但两个线性连续数据块之间发生了地址回环(buff_data[7] -> buff_data[0])。
因此,第 1 次使用 DMA ,可以一次性读取 3 个字节数据,DMA读取成功后,调用函数lwrb_skip修改读(r)指针,修改后,读指针r == 0,环形缓冲区变为:
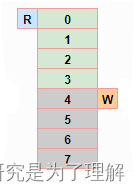
这里需要再次重复一次上面的操作,函数lwrb_get_linear_block_read_address返回的线性地址为读指针r所在的物理内存地址,这里为&buff_data[0],函数lwrb_get_linear_block_read_length返回的线性数据块长度为4字节(buff_data[0]~buff_data[3])。
第 2 次使用 DMA ,可以一次性读取 4 个字节数据,DMA读取成功后,调用函数lwrb_skip修改r指针,修改后,读指针r == 4,环形缓冲区为空:
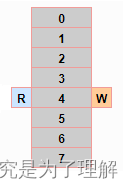
从环形缓冲区零拷贝读取的一般使用方法:/* Initialization part skipped */ /* Get length of linear memory at read pointer */ /* When function returns 0, there is no memory available in the buffer for read anymore */ while ((len = lwrb_get_linear_block_read_length(&buff)) > 0) { /* Get pointer to first element in linear block at read address */ data = lwrb_get_linear_block_read_address(&buff); /* If max length needs to be considered */ /* simply decrease it and use smaller len on skip function */ if (len > max_len) { len = max_len; } /* Send data via DMA and wait to finish (for sake of example) */ send_data(data, len); /* Now skip sent bytes from buffer = move read pointer */ lwrb_skip(&buff, len); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
向环形缓冲区零拷贝写入
需要3个函数配合:
/*获取环形缓冲区的线性写地址*/ void* lwrb_get_linear_block_write_address(LWRB_VOLATILE lwrb_t* buff) /*获取写操作用到的线性数据块长度*/ size_t lwrb_get_linear_block_write_length(LWRB_VOLATILE lwrb_t* buff) /*跳写*/ size_t lwrb_advance(LWRB_VOLATILE lwrb_t* buff, size_t len)- 1
- 2
- 3
- 4
- 5
- 6
DMA 写操作需要
目的地址和长度,函数lwrb_get_linear_block_write_address用于获取 DMA 需要的目的地址,函数lwrb_get_linear_block_write_length用于获取 DMA 需要的长度。DMA 写入成功后,需要调用函数lwrb_advance修改写(w)指针,将 DMA 已经写入的数据更新到环形缓冲区控制块中。
DMA 只能操作线性地址,而环形缓冲区会有地址回环,因此,可能需要写入 2 次才能将环形缓冲区写满(与从环形缓冲区零拷贝读取类似)。线程安全
LwRB的一个重要特性是支持边写边读或者边读边写操作,这个操作有前提条件,即只有存在单个写入入口点和单个读取出口点时才可以。换句话说,在此条件下,LwRB是线程安全的、中断安全的。
只有单个任务写和单个任务读时满足单个写入入口点和单个读取出口点条件;
只有单个中断写和单个中断读时满足单个写入入口点和单个读取出口点条件;
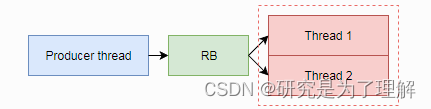
多个任务写或者多个任务读、多个中断写或者多个中断读都不满足单个写入入口点和单个读取出口点条件,比如:- 多个线程写

- 多个线程读
- 多个线程写多个线程读
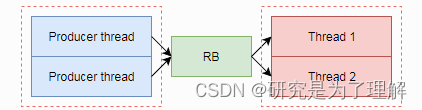
以上三种情况均违反了单个写入入口点和单个读取出口点条件。这时代码不属于线程安全代码,红色虚线框住的部分,需要应用程序进行额外的资源互斥操作。
lwrb_t rb; /* 2 个互斥量, 一个用于写操作一个用于读操作 */ mutex_t m_w, m_r; /* 以下 4 个线程, 2 个写, 2 个读 */ void thread_write_1(void* arg) { /* 使用写互斥 */ while (1) { mutex_get(&m_w); lwrb_write(&rb, ...); mutex_give(&m_w); } } void thread_write_2(void* arg) { /* 使用写互斥 */ while (1) { mutex_get(&m_w); lwrb_write(&rb, ...); mutex_give(&m_w); } } void thread_read_1(void* arg) { /* 使用读互斥 */ while (1) { mutex_get(&m_r); lwrb_read(&rb, ...); mutex_give(&m_r); } } void thread_read_2(void* arg) { /* 使用读互斥 */ while (1) { mutex_get(&m_r); lwrb_read(&rb, ...); mutex_give(&m_r); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
事件
事件是一个回调函数,函数原型为:
typedef void (*lwrb_evt_fn)(LWRB_VOLATILE struct lwrb* buff, lwrb_evt_type_t evt, size_t bp);- 1
事件分为:读事件、写事件和复位事件。由枚举类型
lwrb_evt_type_t定义:typedef enum { LWRB_EVT_READ, /*!< Read event */ LWRB_EVT_WRITE, /*!< Write event */ LWRB_EVT_RESET, /*!< Reset event */ } lwrb_evt_type_t;- 1
- 2
- 3
- 4
- 5
一个典型的事件函数实现为:
/** * \brief Buffer event function */ void my_buff_evt_fn(lwrb_t* buff, lwrb_evt_type_t type, size_t len) { switch (type) { case LWRB_EVT_RESET: printf("[EVT] Buffer reset event!\r\n"); break; case LWRB_EVT_READ: printf("[EVT] Buffer read event: %d byte(s)!\r\n", (int)len); break; case LWRB_EVT_WRITE: printf("[EVT] Buffer write event: %d byte(s)!\r\n", (int)len); break; default: break; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
事件函数通过注册的方式提交给环形缓冲区,注册函数为
lwrb_set_evt_fn,一个注册事件函数的例子:lwrb_set_evt_fn(&buff, my_buff_evt_fn);- 1
事件函数注册成功后,
LwRB在每次修改读写指针时,都会调用这个事件函数,具体为:- 读事件:
lwrb_read函数、lwrb_peek函数 - 写事件:
lwrb_write函数、lwrb_advance函数 - 复位事件:
lwrb_reset函数(将读写指针设置为 0 )
读后有收获,资助博主养娃 - 千金难买知识,但可以买好多奶粉 (〃‘▽’〃)

- 使用 ANSI
-
相关阅读:
每天五分钟机器学习:支持向量机和逻辑回归损失函数的区别和联系
Unity-自定义事件派发器的两次尝试
《中华人民共和国网络安全法》
PDF图片提取的方法有什么?这个方法1分钟提取完毕
Mybatis-Plus入门(1)
拖拽页面元素+flip动画的案例
从零开始学习 Java:简单易懂的入门指南之Stream流(二十七)
300万赛事门票上链,杭州亚运会打造史上首个“链上亚运”
基于智能优化算法的机器人路径优化(Matlab代码实现)
2023南京审计大学计算机考研信息汇总
- 原文地址:https://blog.csdn.net/zhzht19861011/article/details/126524101
