-
【CV知识点扫盲】|激活函数篇
最近正值秋招季,很多同学都在忙着复习深度学习相关的基础知识应对面试和笔试。这段时间,正好发现自己基础知识也比较薄弱,想系统性的复习和整理一下。基于这样一个出发点,最近准备开始一个名为【CV知识点扫盲】的专题文章,帮助自己和更多人复习计算机视觉中的基础知识,也希望能够对正在找工作的同学有帮助。
1、什么是激活函数?
在神经网络中,一个节点的激活函数(Activation Function)定义了该节点在给定的输入变量或输入集合下的输出。wiki中以计算机芯片电路为例,标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。激活函数主要用于提升神经网络解决非线性问题的能力。激活函数各式各样,各有优缺点,目前常用的有 ReLU、sigmoid、tanh等。
2、为什么需要激活函数?
当不用激活函数时,神经网络的权重和偏差只会进行线性变换。线性方程很简单,但是解决复杂问题的能力有限。没有激活函数的神经网络实质上就是一个线性回归模型。为了方便理解,以一个简单的例子来说明。考虑如下网络
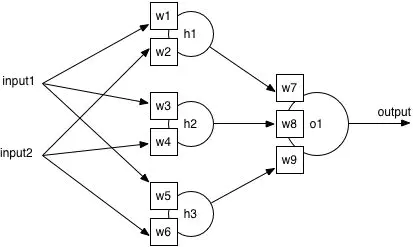
在不用激活函数的情况下,该图可用如下公式表示
o u t p u t = w 7 ( i n p u t 1 ∗ w 1 + i n p u t 2 ∗ w 2 ) + w 8 ( i n p u t 1 ∗ w 3 + i n p u t 2 ∗ w 4 ) + w 9 ( i n p u t 1 ∗ w 5 + i n p u t 2 ∗ w 6 ) output =w 7( input 1 * w 1+i n p u t 2 * w 2)+w 8(i n p u t 1 * w 3+i n p u t 2 * w 4)+w 9(i n p u t 1 * w 5+i n p u t 2 * w 6) output=w7(input1∗w1+input2∗w2)+w8(input1∗w3+input2∗w4)+w9(input1∗w5+input2∗w6)
实质就是下面的线性方程:
o u t p u t = [ w 1 ∗ w 7 + w 3 ∗ w 8 + w 5 ∗ w 9 w 2 ∗ w 7 + w 4 ∗ w 8 + w 6 ∗ w 9 ] ∗ [ input 1 input 2 ] ⟹ Y = W X output =\left[
\right] *\left[w 1 ∗ w 7 + w 3 ∗ w 8 + w 5 ∗ w 9 w 2 ∗ w 7 + w 4 ∗ w 8 + w 6 ∗ w 9 \right] \Longrightarrow Y=W X output=[w1∗w7+w3∗w8+w5∗w9w2∗w7+w4∗w8+w6∗w9]∗[ input 1 input 2]⟹Y=WXinput 1 input 2 若在隐藏层引入激活函数 h ( y ) = max ( y , 0 ) h(y)=\max (y, 0) h(y)=max(y,0),那么原始式子就无法用简单线性方程表示了。
o u t p u t = w 7 ∗ max ( i n p u t 1 ∗ w 1 + i n p u t 2 ∗ w 2 , 0 ) + w B ∗ max ( i n p u t 1 ∗ w 3 + i n p u t 2 ∗ w 4 , 0 ) + w 9 ∗ max ( i n p u t 1 ∗ w 5 + i n p u t 2 ∗ w 6 , 0 ) output =w 7 * \max ( input 1 * w 1+i n p u t 2 * w 2,0)+w B * \max ( input 1 * w 3+i n p u t 2 * w 4,0)+w 9 * \max ( input 1 * w 5+i n p u t 2 * w 6,0) output=w7∗max(input1∗w1+input2∗w2,0)+wB∗max(input1∗w3+input2∗w4,0)+w9∗max(input1∗w5+input2∗w6,0)
3、激活函数的一些特性
非线性(Nonlinear) 当激活函数是非线性的,那么一个两层神经网络也证明是一个通用近似函数通用近似理论。而恒等激活函数则无法满足这一特性,当多层网络的每一层都是恒等激活函数时,该网络实质等同于一个单层网络。
连续可微(Continuously differentiable) 通常情况下,当激活函数连续可微,则可以用基于梯度的优化方法。(也有例外,如ReLU函数虽不是连续可微,使用梯度优化也存在一些问题,如ReLU存在由于梯度过大或学习率过大而导致某个神经元输出小于0,从而使得该神经元输出始终是0,并且无法对与其相连的神经元参数进行更新,相当于该神经元进入了“休眠”状态,但ReLU还是可以使用梯度优化的。)二值阶跃函数在0处不可微,并且在其他地方的导数是零,所以梯度优化方法不适用于该激活函数。
**单调(Monotonic) **当激活函数为单调函数时,单层模型的误差曲面一定是凸面。即对应的误差函数是凸函数,求得的最小值一定是全局最小值。
**一阶导单调(Smooth functions with a monotonic derivative) **通常情况下,这些函数表现更好。
原点近似恒等函数(Approximates identity near the origin) 若激活函数有这一特性,神经网络在随机初始化较小的权重时学习更高效。若激活函数不具备这一特性,初始化权重时必须特别小心。
4、机器学习领域常见的激活函数?

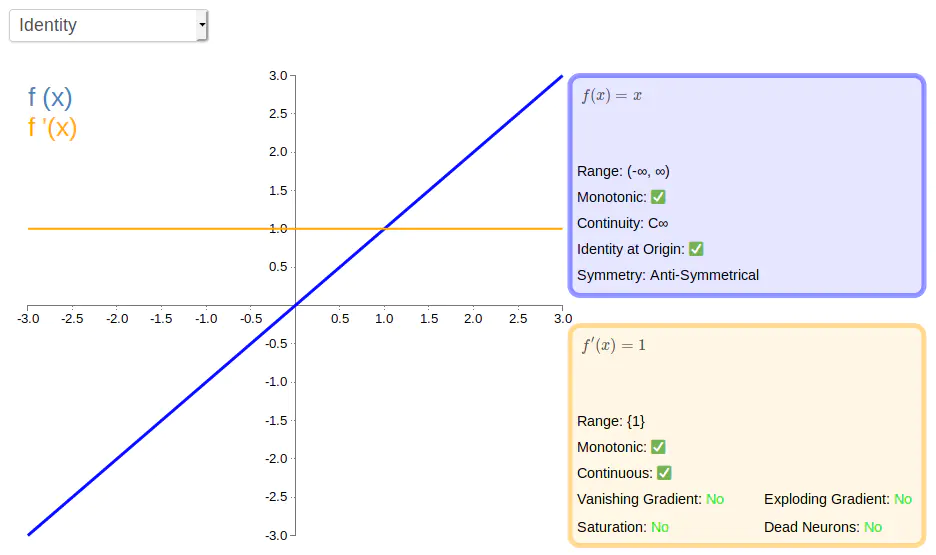
Identity(恒等函数)
描述: 一种输入和输出相等的激活函数,比较适合线性问题,如线性回归问题。但不适用于解决非线性问题。
方程式: f ( x ) = x f(x)=x f(x)=x
一阶导: f ′ ( x ) = 1 f^{\prime}(x)=1 f′(x)=1
图形:
Binary step(单位阶跃函数)
描述: step与神经元激活的含义最贴近,指当刺激超过阈值时才会激发。但是由于该函数的梯度始终为0,不能作为深度网络的激活函数
方程式: f ( x ) = { 0 for x < 0 1 for x ≥ 0 f(x)=\left\{
\right. f(x)={01 for x<0 for x≥00 for x < 0 1 for x ≥ 0 一阶导: f ′ ( x ) = { 0 for x ≠ 0 ? for x = 0 f^{\prime}(x)=\left\{
\right. f′(x)={0? for x=0 for x=00 for x ≠ 0 ? for x = 0 图形:

Sigmoid(S函数又称Logistic逻辑函数)
描述: 使用很广的一类激活函数,具有指数函数形状,在物理意义上最接近生物神经元。并且值域在(0,1)之间,可以作为概率表示。该函数也通常用于对输入的归一化,如Sigmoid交叉熵损失函数。Sigmoid激活函数具有梯度消失和饱和的问题,一般来说,sigmoid网络在5层之内就会产生梯度消失现象。
方程式: f ( x ) = σ ( x ) = 1 1 + e − x f(x)=\sigma(x)=\frac{1}{1+e^{-x}} f(x)=σ(x)=1+e−x1
一阶导: f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f^{\prime}(x)=f(x)(1-f(x)) f′(x)=f(x)(1−f(x))
图形:

TanH(双曲正切函数)
描述: TanH与Sigmoid函数类似,在输入很大或很小时,输出几乎平滑,梯度很小,不利于权重更新,容易出现梯度消失和饱和的问题。不过TanH函数值域在(-1,1)之间,以0为中心反对称,且原点近似恒等,这些点是加分项。一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数。
方程式: f ( x ) = tanh ( x ) = ( e x − e − x ) ( e x + e − x ) f(x)=\tanh (x)=\frac{\left(e^{x}-e^{-x}\right)}{\left(e^{x}+e^{-x}\right)} f(x)=tanh(x)=(ex+e−x)(ex−e−x)
一阶导: f ′ ( x ) = 1 − f ( x ) 2 f^{\prime}(x)=1-f(x)^{2} f′(x)=1−f(x)2
图形:

ArcTan(反正切函数)
描述: ArcTen从图形上看类似TanH函数,只是比TanH平缓,值域更大。从一阶导看出导数趋于零的速度比较慢,因此训练比较快。
方程式: f ( x ) = tan − 1 ( x ) f(x)=\tan ^{-1}(x) f(x)=tan−1(x)
一阶导: f ′ ( x ) = 1 x 2 + 1 f^{\prime}(x)=\frac{1}{x^{2}+1} f′(x)=x2+11
图形:

Softsign函数
描述: Softsign从图形上看也类似TanH函数,以0为中心反对称,训练比较快。
方程式: f ( x ) = x 1 + ∥ x ∥ f(x)=\frac{x}{1+\|x\|} f(x)=1+∥x∥x
一阶导: f ′ ( x ) = 1 ( 1 + ∥ x ∥ ) 2 f^{\prime}(x)=\frac{1}{(1+\|x\|)^{2}} f′(x)=(1+∥x∥)21
图形:

Rectified linear unit(线性整流函数,ReLU)
描述: 比较流行的激活函数,该函数保留了类似step那样的生物学神经元机制,即高于0才激活,不过因在0以下的导数都是0,可能会引起学习缓慢甚至神经元死亡的情况。
方程式: f ( x ) = { 0 for x ≤ 0 x for x > 0 f(x)=\left\{
\right. f(x)={0x for x≤0 for x>00 for x ≤ 0 x for x > 0 一阶导: f ′ ( x ) = { 0 for x ≤ 0 1 for x > 0 f^{\prime}(x)=\left\{
\right. f′(x)={01 for x≤0 for x>00 for x ≤ 0 1 for x > 0 图形:

Leaky rectified linear unit(带泄露随机线性整流函数,Leaky ReLU)
描述: relu的一个变化,即在小于0部分不等于0,而是加一个很小的不为零的斜率,减少神经元死亡带来的影响。
方程式: f ( x ) = { 0.01 x for x < 0 x for x ≥ 0 f(x)=\left\{
\right. f(x)={0.01xx for x<0 for x≥00.01 x for x < 0 x for x ≥ 0 一阶导: f ′ ( x ) = { 0.01 for x < 0 1 for x ≥ 0 f^{\prime}(x)=\left\{
\right. f′(x)={0.011 for x<0 for x≥00.01 for x < 0 1 for x ≥ 0 图形:

Parameteric rectified linear unit(参数化线性整流函数,PReLU)
描述: 也是ReLU的一个变化,与Leaky ReLU类似,只不过PReLU将小于零部分的斜率换成了可变参数α。这种变化使值域会依据α不同而不同。
方程式: f ( α , x ) = { α x for x < 0 x for x ⩾ 0 f(\alpha, x)=\left\{
\right. f(α,x)={αxx for x<0 for x⩾0α x for x < 0 x for x ⩾ 0 一阶导: f ′ ( α , x ) = { α for x < 0 1 for x ≥ 0 f^{\prime}(\alpha, x)=\left\{
\right. f′(α,x)={α1 for x<0 for x≥0α for x < 0 1 for x ≥ 0 图形:

Randomized leaky rectified linear unit(带泄露随机线性整流函数,RReLU)
描述: 在PReLU基础上将α变成了随机数。
方程式: f ( α , x ) = { α x for x < 0 x for x ⩾ 0 f(\alpha, x)=\left\{
\right. f(α,x)={αxx for x<0 for x⩾0α x for x < 0 x for x ⩾ 0 一阶导: f ′ ( α , x ) = { α for x < 0 1 for x ≥ 0 f^{\prime}(\alpha, x)=\left\{
\right. f′(α,x)={α1 for x<0 for x≥0α for x < 0 1 for x ≥ 0 图形:

Exponential linear unit(指数线性函数,ELU)
描述: ELU小于零的部分采用了负指数形式,相较于ReLU权重可以有负值,并且在输入取较小值时具有软饱和的特性,提升了对噪声的鲁棒性
方程式: f ( α , x ) = { α ( e x − 1 ) for x ≤ 0 x for x > 0 f(\alpha, x)=\left\{
\right. f(α,x)={α(ex−1)x for x≤0 for x>0α ( e x − 1 ) for x ≤ 0 x for x > 0 一阶导: f ′ ( α , x ) = { f ( α , x ) + α for x ≤ 0 1 for x > 0 f^{\prime}(\alpha, x)=\left\{
\right. f′(α,x)={f(α,x)+α1 for x≤0 for x>0f ( α , x ) + α for x ≤ 0 1 for x > 0 图形:

Scaled exponential linear unit(扩展指数线性函数,SELU)
描述: ELU的一种变化,引入超参λ和α,并给出了相应取值,这些取值在原论文中(Self-Normalizing Neural Networks)详细推导过程
方程式: f ( α , x ) = λ { α ( e x − 1 ) for x < 0 x for x ≥ 0 f(\alpha, x)=\lambda\left\{
\right. f(α,x)=λ{α(ex−1)x for x<0 for x≥0 w i t h λ = 1.0507 a n d α = 1.67326 with \quad \lambda=1.0507 \quad and \quad \alpha=1.67326 withλ=1.0507andα=1.67326α ( e x − 1 ) for x < 0 x for x ≥ 0 一阶导: f ′ ( α , x ) = λ { α ( e x ) for x < 0 1 for x ≥ 0 f^{\prime}(\alpha, x)=\lambda\left\{
\right. f′(α,x)=λ{α(ex)1 for x<0 for x≥0α ( e x ) for x < 0 1 for x ≥ 0 图形:

SoftPlus函数
描述: 是ReLU的平滑替代,函数在任何地方连续且值域非零,避免了死神经元。不过因不对称且不以零为中心,可以影响网络学习。由于导数必然小于1,所以也存在梯度消失问题。
方程式:
f ( x ) = ln ( 1 + e x ) f(x)=\ln \left(1+e^{x}\right) f(x)=ln(1+ex)
一阶导:
f ′ ( x ) = 1 1 + e − x f^{\prime}(x)=\frac{1}{1+e^{-x}} f′(x)=1+e−x1
图形:

Bent identity(弯曲恒等函数)
描述: 可以理解为identity和ReLU之间的一种折中,不会出现死神经元的问题,不过存在梯度消失和梯度爆炸风险。
方程式:
f ( x ) = x 2 + 1 − 1 2 + x f(x)=\frac{\sqrt{x^{2}+1}-1}{2}+x f(x)=2x2+1−1+x
一阶导:
f ′ ( x ) = x 2 x 2 + 1 + 1 f^{\prime}(x)=\frac{x}{2 \sqrt{x^{2}+1}}+1 f′(x)=2x2+1x+1
图形:

Sinusoid(正弦函数)
描述: Sinusoid作为激活函数,为神经网络引入了周期性,且该函数处处联系,以零点对称。
方程式:
f ( x ) = sin ( x ) f(x)=\sin (x) f(x)=sin(x)
一阶导:
f ′ ( x ) = cos ( x ) f^{\prime}(x)=\cos (x) f′(x)=cos(x)
图形:

Sinc函数
描述: Sinc函数在信号处理中尤为重要,因为它表征了矩形函数的傅立叶变换。作为激活函数,它的优势在于处处可微和对称的特性,不过容易产生梯度消失的问题。
方程式:
f ( x ) = { 1 for x = 0 sin ( x ) x for x ≠ 0 f(x)=\left\{
\right. f(x)={1xsin(x) for x=0 for x=01 for x = 0 sin ( x ) x for x ≠ 0 一阶导:
f ′ ( x ) = { 0 for x = 0 cos ( x ) x − sin ( x ) x 2 for x ≠ 0 f^{\prime}(x)=\left\{
\right. f′(x)={0xcos(x)−x2sin(x) for x=0 for x=00 for x = 0 cos ( x ) x − sin ( x ) x 2 for x ≠ 0 图形:

Gaussian(高斯函数)
描述: 高斯激活函数不常用。
方程式:
f ( x ) = e − x 2 f(x)=e^{-x^{2}} f(x)=e−x2
一阶导:
f ′ ( x ) = − 2 x e − x 2 f^{\prime}(x)=-2 x e^{-x^{2}} f′(x)=−2xe−x2
图形:

Hard Sigmoid(分段近似Sigmoid函数)
描述: 是Sigmoid函数的分段线性近似,更容易计算,不过存在梯度消失和神经元死亡的问题
方程式:f ( x ) = { 0 for x < − 2.5 0.2 x + 0.5 for − 2.5 ≥ x ≤ 2.5 1 for x > 2.5 f(x)=\left\{
\right. f(x)=⎩ ⎨ ⎧00.2x+0.51 for x<−2.5 for −2.5≥x≤2.5 for x>2.50 for x < − 2.5 0.2 x + 0.5 for − 2.5 ≥ x ≤ 2.5 1 for x > 2.5 一阶导:
f ′ ( x ) = { 0 for x < − 2.5 0.2 for − 2.5 ≥ x ≤ 2.5 0 for x > 2.5 f^{\prime}(x)=\left\{
\right. f′(x)=⎩ ⎨ ⎧00.20 for x<−2.5 for −2.5≥x≤2.5 for x>2.50 for x < − 2.5 0.2 for − 2.5 ≥ x ≤ 2.5 0 for x > 2.5 图形:

Hard Tanh(分段近似Tanh函数)
描述: Tanh激活函数的分段线性近似。
方程式:
f ( x ) = { − 1 for x < − 1 x for − 1 ≥ x ≤ 1 1 for x > 1 f(x)=\left\{
\right. f(x)=⎩ ⎨ ⎧−1x1 for x<−1 for −1≥x≤1 for x>1− 1 for x < − 1 x for − 1 ≥ x ≤ 1 1 for x > 1 一阶导:
f ′ ( x ) = { 0 for x < − 1 1 for − 1 ≥ x ≤ 1 0 for x > 1 f^{\prime}(x)=\left\{
\right. f′(x)=⎩ ⎨ ⎧010 for x<−1 for −1≥x≤1 for x>10 for x < − 1 1 for − 1 ≥ x ≤ 1 0 for x > 1 图形:

LeCun Tanh(也称Scaled Tanh,按比例缩放的Tanh函数)
描述: Tanh的缩放版本
方程式:
f ( x ) = 1.7519 tanh ( 2 3 x ) f(x)=1.7519 \tanh \left(\frac{2}{3} x\right) f(x)=1.7519tanh(32x)
一阶导:
f ′ ( x ) = 1.7519 ∗ 2 3 ( 1 − tanh 2 ( 2 3 x ) ) = 1.7519 ∗ 2 3 − 2 3 ∗ 1.7519 f ( x ) 2
f′(x)=1.7519∗32(1−tanh2(32x))=1.7519∗32−3∗1.75192f(x)2f ′ ( x ) = 1.7519 ∗ 2 3 ( 1 − tanh 2 ( 2 3 x ) ) = 1.7519 ∗ 2 3 − 2 3 ∗ 1.7519 f ( x ) 2 图形:

Symmetrical Sigmoid(对称Sigmoid函数)
描述: 是Tanh的一种替代方法,比Tanh形状更扁平,导数更小,下降更缓慢。
方程式:
f ( x ) = tanh ( x / 2 ) = 1 − e − x 1 + e − x
f(x)=tanh(x/2)=1+e−x1−e−xf ( x ) = tanh ( x / 2 ) = 1 − e − x 1 + e − x 一阶导:
f ′ ( x ) = 0.5 ( 1 − tanh 2 ( x / 2 ) ) = 0.5 ( 1 − f ( x ) 2 )
f′(x)=0.5(1−tanh2(x/2))=0.5(1−f(x)2)f ′ ( x ) = 0.5 ( 1 − tanh 2 ( x / 2 ) ) = 0.5 ( 1 − f ( x ) 2 ) 图形:

Complementary Log Log函数
描述: 是Sigmoid的一种替代,相较于Sigmoid更饱和。
方程式:
f ( x ) = 1 − e − e x f(x)=1-e^{-e^{x}} f(x)=1−e−ex
一阶导:
f ′ ( x ) = e x ( e − e x ) = e x − e x f^{\prime}(x)=e^{x}\left(e^{-e^{x}}\right)=e^{x-e^{x}} f′(x)=ex(e−ex)=ex−ex
图形:

Absolute(绝对值函数)
描述: 导数只有两个值。
方程式:
f ( x ) = ∣ x ∣ f(x)=|x| f(x)=∣x∣
一阶导:
f ′ ( x ) = { − 1 for x < 0 1 for x > 0 ? for x = 0 f^{\prime}(x)=\left\{
\right. f′(x)=⎩ ⎨ ⎧−11? for x<0 for x>0 for x=0− 1 for x < 0 1 for x > 0 ? for x = 0 图形:

5、transformer FFN层用的激活函数是什么?为什么?
ReLU。ReLU的优点是收敛速度快、不会出现梯度消失or爆炸的问题、计算复杂度低。
6、 Bert、GPT、GPT2中用的激活函数是什么?为什么?
Bert、GPT、GPT2、RoBERTa、ALBERT都是用的Gelu。
GELU ( x ) = x P ( X ≤ x ) = x Φ ( x ) \operatorname{GELU}(x)=x P(X \leq x)=x \Phi(x) GELU(x)=xP(X≤x)=xΦ(x)
直观理解:x做为神经元的输入,P(X<=x)越大,x就越有可能被保留;否则越小,激活函数输出就趋近于0.
7、如何选择激活函数
-
用于分类器时,二分类为Sigmoid,多分类为Softmax,这两类一般用于输出层;
-
对于长序列的问题,隐藏层中尽量避免使用Sigmoid和Tanh,会造成梯度消失的问题;
-
Relu在Gelu出现之前在大多数情况下比较通用,但也只能在隐层中使用;
-
现在2022年了,隐藏层中主要的选择肯定优先是Gelu、Swish了。
8、ReLU的优缺点?
优点:
-
从计算的角度上,Sigmoid和Tanh激活函数均需要计算指数,复杂度高,而ReLU输入一个数值即可得到激活值;
-
ReLU函数被认为有生物上的解释性,比如单侧抑制、宽兴奋边界(即兴奋程度 也可以非常高)人脑中在同一时刻大概只有1 ∼ 4%的神经元处于活跃状态,所以单侧抑制提供了网络的稀疏表达能力,宽激活边界则能有效解决梯度消失等问题。
缺点:
-
ReLU和Sigmoid一样,每次输出都会给后一层的神经网络引入偏置偏移, 会影响梯度下降的效率。
-
ReLU神经元死亡的问题,不正常的一次参数更新,可能是使得激活项为0,以后的梯度更新也为0,神经元死亡。
【技术交流】
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!!
推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向科研小白的YOLO目标检测库:https://github.com/iscyy/yoloair

参考:
https://www.jianshu.com/p/466e54432bac
-
-
相关阅读:
【vue3】10-vue组件化额外知识补充(下)-动态组件-组件缓存-v-model在组件上的应用
CScrollBar 滚动条
go使用dlib人脸检测和人脸识别
Redis安装到Windows系统上的详细步骤
牛客刷题<九>使用子模块实现三输入数的大小比较
CAD如何转PDF?接下来分享这三个方法和操作步骤给你
在MongoDB中,您可以通过以下步骤来创建账号密码,并限制其在特定数据库上的访问权限
springboot shiro vue使用websocket案例
AutoGPT:自动化GPT原理及应用实践
【JAVA UI】HarmonyOS怎么判断Service怎么在后台运行
- 原文地址:https://blog.csdn.net/Jason_android98/article/details/126518066