-
http(请求方法,状态码,Cookie与Session)
1.http中常见的Header(KV结构)
Content-Length:该结构的作用是表示正文有多少个字节。空行的作用是保证可以识别报文被读完,而报文中的ContentLength保证报文被读完,防止将下一个http请求读到,保证信息的完整性。如果报头中的ContentLength不存在,则代表报文为空。
Content-Type:正文的类型,使用Content-Type对照表进行查询。
Location:当发生跳转时,跳转的位置。
Connection:判断是否有长链接。2.http请求方法
2.1请求方法
GET:获取资源。
POST:传输资源主体。
PUT:传输文件。
HEAD:获得报头。
DELETE:删除文件。
OPTIONS:询问支持的方法。
TRACE:追踪路径。
CONNECT:要求用隧道协议连接代理。
LINK:建立和资源之间的联系。
UNLINK:断开连接关系。
其中网站可以暴露给用户的方法一般只有三个:GET,POST,HEAD。2.2 telnet
使用telnet指令可以作为客户端,向网页的服务端申请服务,首先对telnet指令进行安装:
yum -y install telnet
yum -y install xinetd
telnet www.baidu.com 80//连接百度网站的端口号80
ctrl+]进入telnet命令行,回车进入下一行。HEAD / HTTP/1.0
向百度服务器申请网页根目录(/)下信息,客户会接收到一个1.0版本的http协议的信息。注意,是使用HEAD方法来进行申请的,因此只会得到一个报头信息:

当我们使用GET方法就会得到报头和资源(报文信息):

2.3网页根目录
2.3.1概念
注意我们发送的请求中,有一个’/'代表网页根目录,网页根目录即.server所在的文件夹:

但是我们要向服务器申请的,一般是一个资源,最终应该是/a/b/c类似的东西,即访问c资源。因此就会有一个规定:
规定,申请网页根目录的时候,访问的是根目录中的首页资源,通常是一个html。
比如我们在浏览器中输入:IP地址:8080/,就会拿到对应浏览器的首页资源。基本所有的网站都有其对应的首页。2.3.2构建一个首页
同理,我们也可以在我们的云服务器上的网页根目录来构建一个首页资源:
string html_file=WWWROOT; html_file+=HOMEPAGE; //if(method=='\') path=./index.html //会获取报头中的method信息,此时将路径设为首页。 struct stat st; stat(html_file.c_str(),&st); std::string http_response = "http/1.0 200 OK\n"; http_response += "Content-Type: text/html;charset=utf8\n"; // text/plain,正文是普通的文本 http_response+="Content-Length: "; http_response+=to_string(st.st_size); http_response+="\n"; http_response += "\n"; //空行 std::ifstream in(html_file); if(!in.is_open()) { cerr<<"open html error"<<endl; } else { string content; string line; while(getline(in,line)) { content+=line; } http_response+=content; in.close(); } send(sock,http_response.c_str(),http_response.size(),0); close(sock);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
建立一个html的文件,在服务端打开它,并读取其中的内容,放在正文中发送给客户端。客户端会自行解析html文件。
DOCTYPE html> <html> <head> <meta charset="utf_8"> head> <body> <h3>hello myfriend!h3> body> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.4GET与POST方法
2.4.1 提交参数
修改html代码,达到可以提交参数的目的:
DOCTYPE html> <html> <head> <meta charset="utf-8"> head> <body> <h5>hello 我是首页!h5> <h5>hello 我是表单!h5> <form action="/a/b/handler_from" method="GET"> 姓名: <input type="text" name="name"><br/> 密码: <input type="password" name="passwd"><br/> <input type="submit" value="登陆"> form> body> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
此时再进行访问,就可以看到这个界面:

2.4.2GET与POST提交参数对比
当使用GET方法提交参数(输入姓名和密码)的时候,提交的信息会显示在URL中。
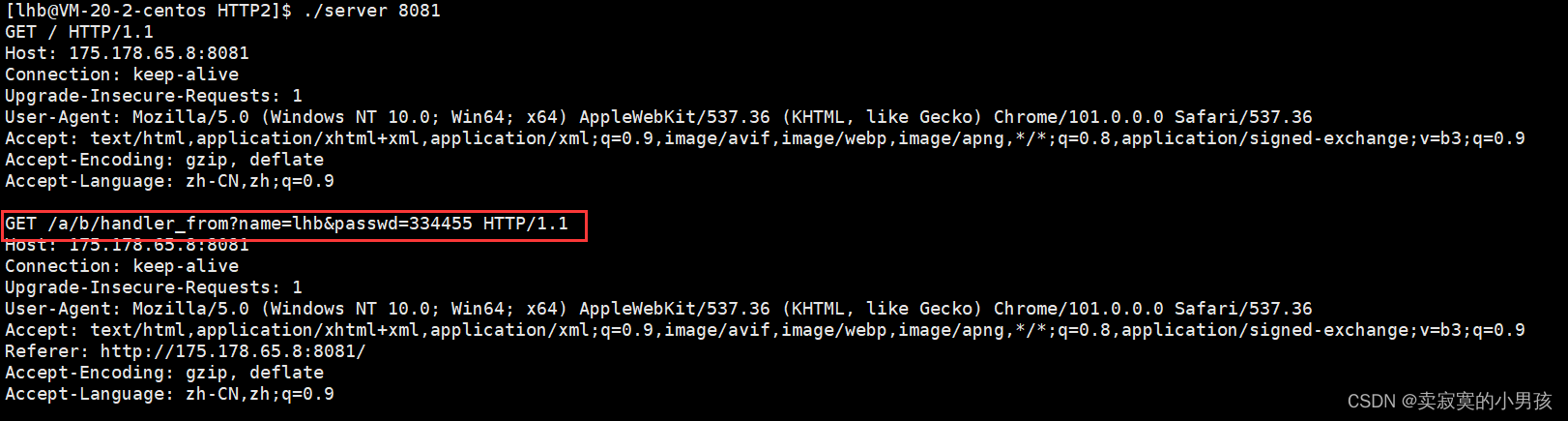
如果以POST方法提交参数(将method改成POST),提交的信息会显示在正文中。

2.4.3GET和POST对比
对比一:
GET主要用于获取,是最常用的,默认一般获取所有的网页都是GET方法,如果GET提交参数(它可以提交的!!),通过URL进行参数拼接,然后传递给服务端。
POST主要用于推送,是提交参数的常用的方法,如果提交参数,一般是通过正文提交的。
对比二:
参数提交的位置不同,GET不私密,会将重要的信息回显到输入框中,增加了被盗取的危险。POST比较私密(不代表安全),不会回显到浏览器URL的输入框中。
GET通过url传参,而url是有大小限制的
对比三:
如何选择:如果提交的参数不敏感,数量非常少,可以采用GET,否则使用POST。
GET和POST是前后端数据交换的重要方式。3.状态码
3.1状态码分类
通常来说,状态码分为五类:
1XX:information(信息性状态码),接收的请求正在处理。
2XX:Success(成功状态码),请求正常处理完毕。
3XX:Redirection(重定向状态码),需要进行附加操作以完成请求。
4XX:Client Error(客户端错误状态码),服务器无法处理请求。
5XX:Server Error(服务器错误状态码),服务器处理请求出错。
注意:由于应用层是人要参与的,人的水平参差不齐,http的状态码很多人不清楚该如何使用,又因为浏览器的种类太多了,导致可能对状态码的支持没有那么好,类似于404的状态码对浏览器没有指导意义,浏览器只会正常显示网页。这也就意味着404的页面需要程序员来编写。3.2 3XXX状态码
3XXX状态码是有特殊的意义的,代表重定向。
301:永久重定向。
302或307:代表临时重定向。
重定向:当访问一个网站的时候,会让我们跳转到另一个网址。
永久重定向:当用户访问一些老网址的时候,老网址会告诉浏览器,资源已经被搬运到其他的网址去了,此时会更新一些浏览器的缓存,然后跳转到新网址。当再次访问老网址的时候,就不会访问老网址了而是直接访问新网址。
临时重定向:当我们访问某种资源的时候,提示登录,跳转到登录页面,输入用户名和密码之后,再跳转回原来的页面。跳转网址是为了执行某一个任务,而不是资源搬迁。
重定向是需要浏览器提供支持的,浏览器必须能够识别状态码,由服务端告知浏览器应该跳转到哪里。string response="http/1/1 301 Permanently moved\n"; response+="Location: https://www.qq.com/\n"; response+="\n"; send(sock,response.c_str(),response.size(),0);- 1
- 2
- 3
- 4
使用Location来将网页重定向到腾讯首页,此时访问该网站就会直接跳转到腾讯的首页了。
3.3 长链接与短链接
注意这里使用的是1.1,我们之前使用的都是1.0版本,而1.0版本代表的是短链接。
短链接的作用在于,我们申请服务器上所有资源的时候都是请求,响应然后断开链接。当访问一个由多个元素构成的网页的时候,http/1.0需要多次进行http请求。http是基于TCP进行通信的,TCP通信的时候就要经过(建立链接,传输数据,断开链接),每一次http都需要执行这一过程。
当网页上有图片的时候(在html页面添加):<img src="https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwww.2008php.com%2F09_Website_appreciate%2F10-07-11%2F1278861720_g.jpg&refer=http%3A%2F%2Fwww.2008php.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1663734890&t=27a504cab6d3d39a9b1d65cdf171784e" alt>- 1
对于短链接来说,此时客户端在申请网页的同时,还会申请图片(在对应图片网站的客户端申请)。
服务器上有很多资源,一个网页中有很多资源,如果堆每一个资源都这样发起http请求,是很麻烦的事情,因此引入了长链接。在通信的时候会复用同一个链接。
长链接可以减少频繁建立TCP链接,达到提高效率的目的。在报头属性中的Connection=keep-alive表示支持长链接,如果没有Connection属性或者Connection=close不支持长链接,我们的代码是短链接代码,如果想支持长链接需要在代码上做修改。4.Cookie与Session
4.1Cookie
4.1.1Cookie的作用
在我们访问网站的时候,登录之后,访问该网站的其他内容,网站是如何识别我们已经登录了呢?注意,http协议是不记录历史上的http的信息的。这并不是http协议本身需要解决的问题,但是http可以提供一些技术支持来保证网站具有会话保持(会话管理)的功能。
比如我们登录我们的CSDN网站,刷新一次页面(重新进行一次资源请求),此时就不需要再进行登录了,这就是Cookie的作用。
在谷歌浏览器的上方有一个锁的图标,点击它就可以看到正在使用的Cookie了。

当我们将这些Cookie移除的时候(移除了所有Cookie信息,其中包括登录信息)时,再次刷新网站,就会发现需要我们来进行登录了。
登录之后发现Cookie信息又被重新存储了。4.1.2Cookie的存在形式
Cookie有两种存在形式,可以是一个文件(在主机的用户文件夹下可以找到),也可以是一个内存,它是与浏览器同生命周期的,当把浏览器关掉,就没有Cookie信息了。
4.1.3Cookie的原理
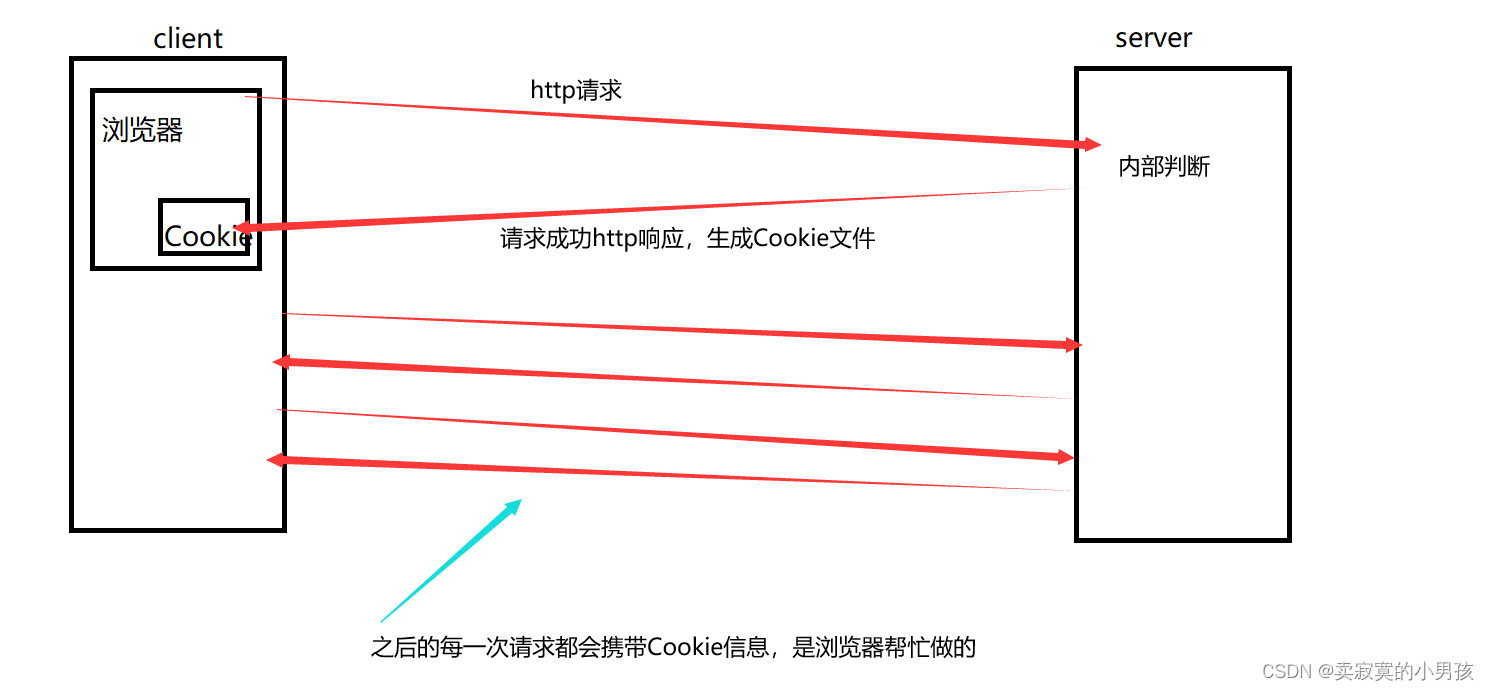
在浏览器角度看来,Cookie是一个浏览器中的文件,文件中存放的是用户的私密信息。
在http通信的接哦度,一旦该网站有Cookie,在发起任何请求的时候,都会在报头中自动携带Cookie信息。
4.1.4设置Cookie
在服务端向客户端的响应中,可以使用Set-Cookie设置Cookie:
http_response+="Set-Cookie: id=1111\n"; http_response+="Set-Cookie: password=2222\n";- 1
- 2
此时可以发现,进行访问的时候,浏览器处就有了Cookie的信息:

当再次进行访问的时候,服务器会接收到Cookie的内容:

4.2Session
4.2.1Session的引入
在了解了Cookie之后,如果有人盗取了我的Cookie文件,以我的身份来认证访问特定的资源,那么就会有安全隐患。
因此我们引入了Session,核心思路是将用户的私密信息保存在服务端。4.2.1Session的原理

此时就可以保证浏览器中的Cookie的信息是服务端文件的session_id,所有的http请求都会有浏览器自动携带cookie中的session_id,后序server依旧可以认识client,,也是一种会话保持的功能,但是我们还有cookie文件被泄漏的风险。 -
相关阅读:
排序算法——快速排序
数据结构与算法【递归】Java实现
数据库——知识1
基于Matlab实现图像配准技术(附上源码+图像)
CMMI/ASPICE认证咨询及工具服务
Clickhouse通过命令导入导出文件(在Linux命令窗口)
ETL调度同步工具比较-Kettle、DolphinSchedule、DataX
Java-设计Bird/Fish类
【linux】初识进程
d3dcompiler_43.dll是什么文件?缺失d3dcompiler_43.dll文件修复与解决方法
- 原文地址:https://blog.csdn.net/qq_51492202/article/details/126431365
