-
SpringBoot的基本使用
SpringBoot
目录
3.1 继承spring-boot-starter-parent
3.2 依赖spring-boot-dependencies(常常使用)
3.4 创建dao接口extends JpaRepository
一、SpringBoot简介?
1、什么是SpringBoot
spring框架中顶级项目片排名第一,目的是简化Spring框架的开发
设计之初的目的是让spring框架开发更加容易、快速,而不是为了取代spring框架
Spring Boot 是由 Pivotal 团队提供的全新 [ 框架 ] ,其设计目的是用来[简化 ] [Spring] 应用的初始搭建以及开发过程。该框架使用了特定的方式来 进行配置( 自动配置 @Condition( 选择注入)),从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域 成为领导者。Spring框架是由 rod johnson 主导开发的。从 2004年推出,早期版本由于兼容的 JDK 不支持注解, Spring 框架提出了使用xml 来减耦合, jdk5 开始,引入了注解的新特性。此时Spring 团队分成了两个派系,一派支持 xml ;另一派支持注解。受限于 Spring 框架早起的注解比较少、功能不够强大。在实际的开发过程中都以XML 为主,注解辅助开发。spring3.0 开始,引入了更多的注解。项目的 xml 配置 过于繁琐了。共识业务类使用@service @Component @Controller等注解来简化开发,通用的配置使用 xml 。 spring4.0 开始,提出了全注解开发(编程式开发),完全脱离xml 来构建我们的spring 应用。 spring 团队在注解的基础上为了简化spring 框架的开发,推出了 spring boot 项目,启动器和自动配置即springboot给我们默认片配置了一些,我们只需要按照它的规定来使用即可---规定大于配置的原则spring的官网: Spring | Homespringboot的官网: Spring Bootspringboot的开发文档:Spring Boot Reference Documentation

2、SpringBoot的优点
- 创建独立的spring的应用程序
- 内置了tomcat、jetty或undertow等应用服务器,无序将应用打包成war,直接用jar就可以运行web project
- 允许通过maven按需去配置starter【启动器】
- 采用自动配来完成spring框架的配置和其他第三方框架的配置
- 提供了运行时的健康检查
- 没有代码生成,也没有xml的配置需求
- springBoot是SpringCloud 的服务构建的基石
3、SpringBoot的缺点
入门容易,精通难,如果对spring和spring注解不了解,很难看懂springboot的运行原理
二、SpringBoot的创建方式
1.基于官网的Initializr创建
是spring官网提供的boot工厂的构建方式,开源项目基本都采用了这种构建方式
1. 点击springboot官网
2. 在最下面有一个Initializr


例如下面这种


2.基于idea的向导创建



3.基于maven的创建
3.1 继承spring-boot-starter-parent
1.创建maven工程
2.设置父工程
org.springframework.boot 2.6.6 spring-boot-starter- parent jar 3.可以添加依赖和启动器
所有官方启动器都遵循类似的命名模式;
spring-boot-starter-*,其中*是特定类型的应用程序。此命名结构旨在帮助您在需要查找启动器时提供帮助。许多 IDE 中的 Maven 集成允许您按名称搜索依赖项。例如,安装了适当的 Eclipse 或 Spring Tools 插件后,您可以ctrl-space在 POM 编辑器中按下并键入“spring-boot-starter”以获取完整列表。正如“创建您自己的 Starter ”部分所述,第三方 starter 不应以 开头
spring-boot,因为它是为官方 Spring Boot 工件保留的。相反,第三方启动器通常以项目名称开头。例如,一个名为的第三方启动项目thirdpartyproject通常被命名为thirdpartyproject-spring-boot-starter.带starater的是sprignboot的启动器,它会默认进行配置一些设置
org.springframework.boot spring-boot- starter-web 4.启动类
在 boot 中包含了内置的 tomcat ,将项目打包成 jar 格式, 普通的java 类
3.2 依赖spring-boot-dependencies(常常使用)

因为spring-boot-starter-parent的父类是dependencies 这个依赖是进行版本管理的,因此我们直接导入这个依赖即可 因为上一个parent要继承,但是pom只能单继承,所以我们使用导入依赖的方式

在父工程中的pom中加入springboot的依赖的包
注意: 因为spring-boot-dependencies是pom的类型 因此一定要加入type和import才可以

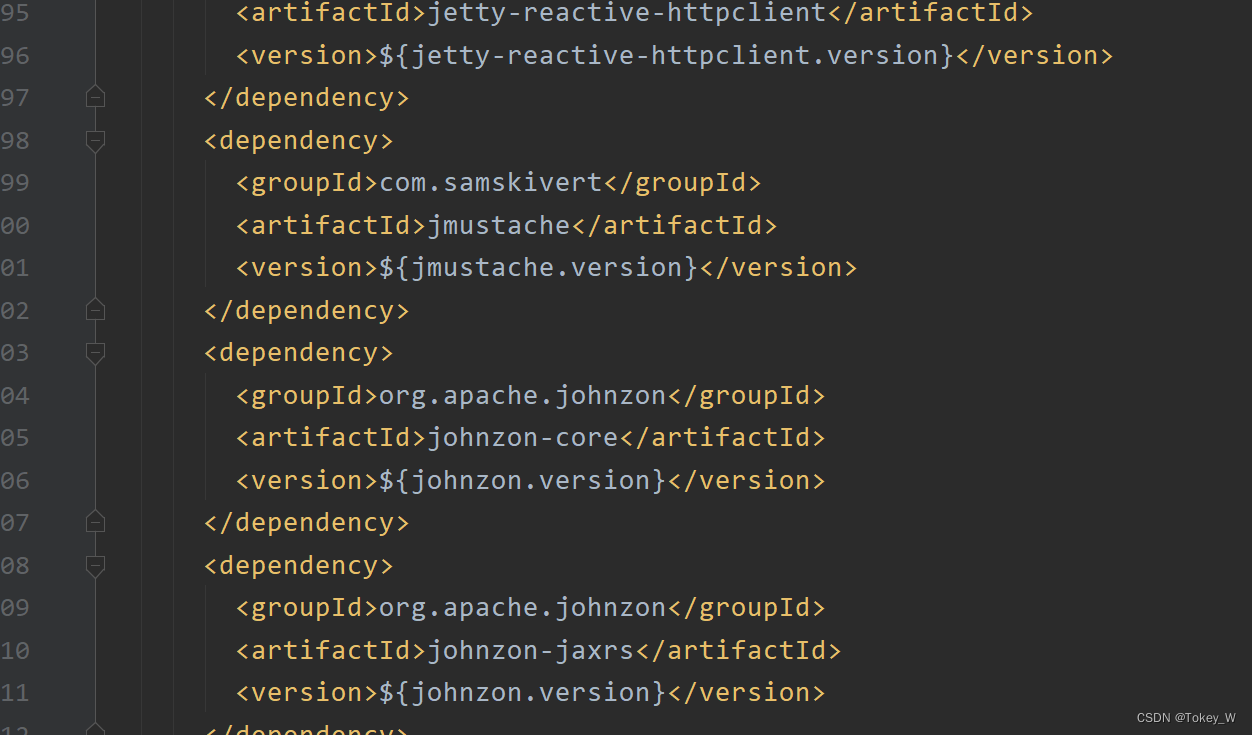 这是spring-boot-dependencies 对各个依赖的版本管理,无序我们在担心版本冲突的问题了
这是spring-boot-dependencies 对各个依赖的版本管理,无序我们在担心版本冲突的问题了
三、springboot的结构分析
|--项目名称
|-- main
|-- java
|--App.java (启动类)
|--resources|-- application.properties或application.yml配置文件
|--static(存放静态资源 css、js、images)
|--public 存放html
|--templates 模板
|--mappers 存放的mapper映射文件
pom.xml
四、配置文件
1.配置文件类型
springboot放弃了spring framework中的xml作为配置文件,改用两种方式:
- .properties配置文件 --使用不多,在企业开放中很少用,但是在开源的项目中使用比较多
# 设置端口号server.port = 8888# 设置项目访问路径server.servlet.context-path = /a因为properties是一行一行的写,无法反映出来层级结构,当配置文件内容很多的时候就会变得很乱,因此出现了yml(yaml)的配置文件
- .yml配置文件(.yaml)【推荐】
server:port: 8888servlet:context-path: /a使用的优先级
.properties 优先级大于 .yml ,高优先级会覆盖低优先级的内容,同时多种配置文件可以互补配置五、YML(YAML)
YAML (/ˈ jæm ə l/ ,尾音类似 camel 骆驼)是一个可读性 高,用来表达数据 序列化 的格式。 YAML 参考了其他多种语言,包括: C 语言 、 Python 、 Perl ,并从 XML 、电子邮件的数据格式(RFC 2822 )中获得灵感。 Clark Evans 在2001 年首次发表了这种语言,另外 Ingy döt Net与 Oren Ben-Kiki 也是这语言的共同设计者。当前已经有数 种编程语言或脚本语言支持(或者说解析)这种语言。
YAML 是 "YAML Ain't a Markup Language" ( YAML 不是 一种 标记语言 )的 递归缩写 。在开发的这种语言时, YAML 的意思其实是: "Yet Another Markup Language" (仍是一种 标记语言 ),但为了强调这种语 言以数据做为中心,而不是以标记语言为重点,而用反
向缩略语重命名。 YAML : 以数据为中心,比 xml 和 json 更适合做配置文 件1、语法
文件必须以.yml或以.yaml作为后缀名
书写规则: K-V ,采用了缩进来描述属性和属性之间的层级关系
K:空格 值 注意: 冒号后面必须有一个空格才能生效
注意:
层级关系使用缩进(不推荐使用TAB),推荐采用空格 (默认2 个空格代表一次缩进),只要在配置文件中同一级所有的缩进使用了相同的个数的空格(可以不遵循2个 空格的要求)yml之间区分大小写
规范写法:
- user:
- userName: admin
- age: 12
- sex: 男
- user1:
- userName: amdin2
- age: 28
- sex: 女
- sex1: 值
2、字面值
userName: admin3、对象或者map
- user:
- userName: admin
- age: 12
或者
user:{userName:admin,age:12} # 不推荐采用这种方式4、数组
- ids:
- - 1
- - 2
- - 3
- #ids是一个数组 数组中包含了1,2,3
- 或者
- ids: [1,2,3]
5、占位符
- springboot配置文件中允许使用占位符, ${random.int} ${random.long}
- ${random.int(值)}
- $ {random.int(值1,值2)}
- ${random.uuid}
- 一般使用在dubbo端口,利用UUID进行随机
6、配置文件的注入
将配置文件的内容注入到容器中
6.1简单类型的属性注入
采用spring中简单类型属性注入的注解@Value来将配置文件中的内容注入到Spring容器中。
例如在Spring整合mybatis时,我们需要定义数据库连接信息,定义在配置文件中
- userName: admin${random.uuid}
- jdbcDriver: com.mysql.cj.jdbc.Driver
- jdbcUrl: jdbc:mysql:///2109q
- jdbcUserName: root
- jdbcPwd: Lh_198571
- @SpringBootApplication
- @RestController
- public class Application {
- @Value("${jdbcDriver}")
- private String driver;
- @Value("${jdbcUrl}")
- private String url;
- @Value("${jdbcUserName}")
- private String userName;
- @Value("${jdbcPwd}")
- private String pwd;
- @GetMapping("/test")
- public String test(){
- return "HelloWorld"+userName+","+pwd+","+url+","+d river;
- }
- public static void main(String[] args) {
- SpringApplication.run(Application.class, args);
- }
- }
注意:
1.ognl表达式中没有任何提示,需要确定配置文件中属性名称是否正确
2.只能注入简单类型
6.2类型安全的属性注入(常用)
可以注入引用数据类型,将在yml中定义的对象可以直接封装到实体类中
步骤:
- 项目中引入安全类型注入的依赖
其实不加入这个依赖也是可以实现安全属性的注入的(spring内部有配偶)这个依赖的作用是当我们自定义的时候,在yml中配置会有提示,springboot官网说这个依赖主要目的就是方便我们更便捷的使用自定义---这个依赖仅仅是在编译期间起作用
具体可以参考这个博客:
spring-boot-configuration-processor的作用_码上得天下的博客-CSDN博客_configuration-processor
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-configuration-processorartifactId>
- <dependency>
- 创建实体类,并进行设置
- @Data
- // 将配置文件中指定的内容绑定到该实体类中
- // prefix 规定绑定哪个属性下的属性 --配置文件中前缀是user的
- // 将配置文件中User实体类的所有的属性按属性名绑定到当前实体类中
- @Component
- @ConfigurationProperties(prefix = "user")
- public class User {
- private Integer id;
- private String userName;
- private String user_name1;
- private Map map;
- private Integer[] ids;
- }
松散绑定:可以将user_name转为userName绑定
- user:
- id: 1
- userName: zhangsan
- # 松散绑定 springboot 默认绑定 相同的属性名和 带_的
- userName1: '我的 \n hh'
- map:
- key1: "我的 \n hh"
- key2: www
- ids:
- - 1
- - 2
- - 3
注意: 这里value如果是字符串 可以不加引号直接写值
也可以使用单引号 但是单引号中转义字符是直接输入,不会其效果,而双引号是有效果的
例如上面的 单号封装进去后的结果:我的 \n hh
双引号是: 我的 hh
7、多环境的配置
7.1 多properties或多yml
springboot 中默认加载的配置文件 application.yml 或 application.properties。可以通过配置文件名来区分不同的环境。- application.yml(默认加载)
- application-dev.yml(开发环境)
- application-test.yml(测试环境)
- application-prod.yml(生产环境)
7.2 yml支持多文档块的形式
- #---代表的是分模块 但是一般企业开发中不使用这种方法(代码多的时候会非常的乱,因此我们常常使用多配置文件的)
- ---
- spring:
- profiles: dev
- server:
- servlet:
- context-path: /a
- ---
- spring:
- profiles: test
- server:
- servlet:
- context-path: /b
- ---
- spring:
- profiles: prod
- server:
- servlet:
- context-path: /c
7.3通过yml的配置来指定是哪个环境
- # 指定开发环境
- spring:
- profiles:
- active: dev
- # 指定开发环境
- spring:
- profiles:
- active: test
- # 指定开发环境
- spring:
- profiles:
- active: prod
- 不配置是默认
- 上面三种配置哪个就使用那个环境
实际开发的时候,如果打包后发现环境不对,可以通过命令行进行修改,因为命令行的配置是高于配置文件的
使用 --spring.profiles.active=环境名(dev、test、prod等等)
8、配置文件的加载顺序
springboot 自动扫描和加载的路径分别 4 个- file:/config/application.properties|application.yml
- file:application.properties|application.yml
classpath:
- /config/application.properties|application.yml
- classpath:application.properties|application.yml
springboot 扫描时以上是优先级从高到低的顺序,高优先级会覆盖低优先级,多个配置文件中的配置可以互补六、SpringBoot的日志管理
常见的日志框架:JUL,JCL,jboss-logging,log4j,log4j2,logback,slf4j
1、日志冲突问题
由于不同的框架采用了默认的不同的日志框架,如果我 们不对其进行处理话,会导致冲突,也会导致项目中日志的混乱解决办法:1.通过maven中排除依赖,来排除默认的日志依赖 (exclutions)2.用中间依赖来替代原有的日志实现3.导入需要的日志框架2、Springboot中的日志
通过 spring-boot-starter-logging 启动器来管理日志org.springframework.boot spring-boot- starter-logging 一般是spring-boot-starter 或者spring-boot-starter-web
3、日志级别
3.1 为什么要使用日志级别
无论将日志输出到控制台还是日志文件,输出都会降低程序的运行效率。由于调试、运维时,都需要必要的输出,需要在代码中加入输出语句。这些输出语句如果在脱离了调试和运维时,依旧会执行。唯一的解决办法是在测试、调试、运维结束后将输出语句删除。将日志分级别管理,可以根据级别来控制输出的内容以及输出的位置。我们只需要在配置文件中修改日志级别。3.2 日志级别


设置日志级别 设置info info下面的debug 和trace就不会进行打印 都是只会打印设置级别的上面
- @Slf4j ---该类中可以直接使用log对象进行日志操作
- 默认级别是info
3.3 日志的设置级别(yml配置)
- logging:
- level:
- root: info # 项目根采用的日志级别
- com.sofwin: debugh # 为不同的包设置不同的日志级别
3.4 日志打印到文件中
打印到指定文件中 默认位置是在根目录下
- logging:
- level:
- root: info
- com.sofwin: debug
- file:
- name: a.log
没有指定日志的名称,默认采用的名称是spring.log
3.5 日志打印到指定位置
- logging:
- level:
- root: info
- # 设置包的日志界别
- com.sofwin: debug
- # 设置日志输出的目录 --- 不指定名称 默认名称是spring.log
- # 默认切割大小10M
- file:
- path: d:\\log\
注意:
在实际开发中推荐设置日志答应到指定位置,但是不设置日志的名称,以保持默认的日志文件名称供后续分析日志。
默认采用日志滚动存储,当日志文件达到10mb的时候,会将老的配置文件按照时间命名,超出10mb保存在spring.log的压缩文件中 ---spring.log 只保存最新的日志
七、针对不同的操作系统实现不同的方法
接口
- public interface UserService {
- String test();
- }
两个实现类 对应的分别是windows系统和Linux系统
- //windows系统
- public class UserServiceImpl implements UserService {
- public String test() {
- return "aaaaa";
- }
- }
- //Linux系统
- public class UserServiceImpl2 implements UserService {
- public String test() {
- return "bbbbb";
- }
- }
App启动类 --通过@Conditional来实现多环境
WindowService和LinuxService是自定义判断类 要实现 implements Condition接口才可以
如果返回true就执行该方法 将指定的实现类加入到spring容器中
- @SpringBootApplication
- public class App {
- public static void main(String[]args){
- SpringApplication.run(App.class,args);
- }
- //多环境的开发
- @Conditional(WindowService.class)
- @Bean
- public UserService getUserService1(){
- return new UserServiceImpl();
- }
- @Conditional(LinuxService.class)
- @Bean
- public UserService getUserService2(){
- return new UserServiceImpl();
- }
- }
WindowService
- public class WindowService implements Condition {
- public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
- //通过context的方法获取环境 然后通过属性(os.name)得到当前操作系统的名称是
- String property = context.getEnvironment().getProperty("os.name");
- if (property.contains("Window")){
- return true;
- }
- return false;
- }
- }
LinuxService
- public class LinuxService implements Condition {
- public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
- String property = context.getEnvironment().getProperty("os.name");
- if (property.contains("Linnux")){
- return true;
- }
- return false;
- }
- }
Controller 测试
- @RestController
- public class TestController {
- //日志打印
- private Logger logger=LoggerFactory.getLogger(getClass());
- @Autowired
- private User user;
- @Autowired
- private UserService uwwww;
- @GetMapping("/test")
- public String test01(){
- logger.debug("测试日志");
- return uwwww.test();
- }
- }
八、SpringBoot集成jdbc
1.spring集成jdbc
添加依赖
mysql-java-connector.jar
druid.jar
spring-jdbc.jar
spring-tx.jar
创建数据源 datasource
将数据源设置到jdbcTemplate中
2.springboot集成jdbc
添加启动器和mysql的连接
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-jdbcartifactId>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- dependency>
在yml中添加datasource的信息
- spring:
- datasource:
- driver-class-name: com.mysql.cj.jdbc.Driver
- url: jdbc:mysql://localhost:3306/dubbotest?serverTimezone=UTC
- username: root
- password: root
设置数据源后springboot会自动设置JdbcTemplate
springboot的自动配置都是在这里找的



直接使用jdbcTemplate即可
 取完
取完九、springboot继承mybatis
1.spring集成mybatis
添加依赖
mybatis
mybatis-spring
druid
spring的依赖
创建sqlSessionFatoryBean
创建发现映射器
2.springBoot集成mybatis
导入启动器和测试依赖
mybatis-spring-boot-starter
mysql-java-connector
spring-boot-starter-test
pagehelper-spring-boot-starter 分页的启动器
lombok
- <dependency>
- <groupId>org.projectlombokgroupId>
- <artifactId>lombokartifactId>
- dependency>
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-testartifactId>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- dependency>
- <dependency>
- <groupId>org.mybatis.spring.bootgroupId>
- <artifactId>mybatis-spring-boot-starterartifactId>
- <version>2.2.2version>
- dependency>
- <dependency>
- <groupId>com.github.pagehelpergroupId>
- <artifactId>pagehelper-spring-boot-starterartifactId>
- <version>1.4.3version>
- dependency>
设置数据库
- spring:
- datasource:
- driver-class-name: com.mysql.cj.jdbc.Driver
- url: jdbc:mysql://localhost:3306/dubbotest?serverTimezone=UTC
- username: root
- password: root
2.1 纯注解版
mapper接口
- package com.sofwin.mapper;
- import com.sofwin.pojo.User;
- import org.apache.ibatis.annotations.Insert;
- import org.apache.ibatis.annotations.Select;
- import java.util.List;
- /**
- * @author : wentao
- * @version : 1.0
- */
- public interface UserMapper {
- @Select("select count(*) from sys_user")
- int selectCount();
- @Select("select id,user_name userName,pwd,real_name realName,dept_id deptId,create_date createDate from sys_user")
- List
selectByUsers(); - @Insert(
- " insert into sys_user (id, user_name, pwd, real_name, dept_id, create_date) values (#{id,jdbcType=INTEGER}, #{userName,jdbcType=VARCHAR}, #{pwd,jdbcType=VARCHAR}," +
- "#{realName,jdbcType=VARCHAR}, #{deptId,jdbcType=INTEGER}, #{createDate,jdbcType=VARCHAR}" +
- ") "
- )
- int insertSelective(User user);
- }
App启动类中使用@MapperScan发现映射器


2.2 xml版
接口
- /**
- * @author : wentao
- * @version : 1.0
- */
- public interface DeptMapper {
- int selectCount();
- List
selectByDepts(); - }
一般xml版使用的都是同名不通报 ,映射文件统一设置在resources中
- "1.0" encoding="UTF-8"?>
- "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
"com.sofwin.mapper.DeptMapper"> - select count(*) from sys_dept
- select id,dept_name deptName,flag,prent_id prentId from sys_dept

设置映射文件的位置(因为不是同包同名,要设置一下)

十、 springboot继承jpa
1、JPA
JPA 是 Java Persistence API 的简称,中文名 Java 持久层API,是 JDK 5.0 注解或 XML 描述对象-关系表的映射关系,并将运行期的实体 对象持久化 到数据库中。 [1] Sun引入新的 JPA ORM 规范出于两个原因:其一,简化现有Java EE 和 Java SE 应用开发工作;其二, Sun 希望整合ORM 技术,实现天下归一。通俗的说就是实现写一次,可以操作不同的数据库
2、spring data
Spring Data 项目目的是为了简化基于 spring 框架对持久化层的操作技术,包含了关系型数据库、非关系型数据库,map-reduce 框架等。1. Spring Data 特定提供了统一的api 对持久化层进行操作;主要是通过spring data commons项目实现。让我们使用关系型数据库或非关系型数据库时都能给予一个统一的标准,这个标准中包含了 crud ,分页排序等。2. Spring Data 提供了统一的 Repository 接口,可以实现对关系型数据库或非关系型数据库的操作3. Spring Data 提供了数据访问的模版 如:RedisTemplate MongoDbTemplate3、步骤
3.1 添加启动器
spring-boot-starter-data-jpa
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-testartifactId>
- dependency>
- <dependency>
- <groupId>org.projectlombokgroupId>
- <artifactId>lombokartifactId>
- dependency>
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-data-jpaartifactId>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- dependency>
3.2配置jpa
- spring:
- datasource:
- driver-class-name: com.mysql.cj.jdbc.Driver
- url: jdbc:mysql://localhost:3306/dubbotest?serverTimezone=UTC
- username: root
- password: root
- jpa:
- show-sql: true # 显示sql语句
- hibernate:
- ddl-auto: none # 主要是基于hibernate orm框 对象关系模型
- # none 不对数据库中的表 进行新增和更新 默认
- # create 每次启动项目都 根据对象关系模型来生成数据库中的表 --先drop 在create
- # update 每次启动项目都 根据对象关系模型来更新数据库中的表 --如果表结构修改,就进行修改
3.3创建实体类完善对象关系模型
- package com.sofwin.pojo;
- import lombok.Data;
- import javax.persistence.*;
- /**
- * @author : wentao
- * @version : 1.0
- */
- @Data
- @Entity
- @Table(name = "s_user")
- public class User {
- @Id //声明为主键列
- //设置主键生成策略
- @GeneratedValue(strategy =GenerationType.IDENTITY )
- private Integer id;
- @Column(name = "user_name")
- private String userName;
- @Column(name = "pwd")
- private String pwd;
- @Column(name = "real_name")
- private String realName;
- @Column(name = "dept_id")
- private Integer deptId;
- @Column(name = "create_date")
- private String createDate;
- // @Transient //该属性不序列化 这样就不会报错了
- @Column(name = "age")
- private Integer age;
- }
- @Entity 声明当前类为实体类,也就是说这个类需要和数据库中的某个表进行映射
- @Table 声明当前实体类和那个表进行关系映射 --如果没有这个表,并且在yml中设置了ddl-auto:create,会自动声明一个表--实现了正向工程
- @Id 声明属性是用于映射主键的属性
- @GeneratedValue 声明主键自增策略
table:从一个张表中获取主键信息
IDENTITY:主键自动 支持mysql
SEQUENCE:根据数据库的序列来生成主键 一般支持oracle
AUTO:右程序来控制主键的生成
- @Column 声明属性和字段的映射关系
3.4 创建dao接口extends JpaRepository
第一个泛型是对应的实体类的类型 第二个是id的类型
- public interface UserMapper extends JpaRepository
- //jql语句
- // form不能是表 而是对象
- // 不能写*
- // ?1代表第一个参数
- @Query("select a from User a where a.id=?1")
- User selectUserById(Integer id);
- //也可以这样写 :id 必须要写 @Param才可以使用
- @Query("select a from User a where a.id=:id")
- User selectUserById2(@Param("id") Integer id);
- }
4.Jpa的api
-
新增和修改
save(object obj)
可以讲数据insert到数据库
当id为null的时候是新增 当id不为null的时候为修改
- 删除
delete(Object) 无返回结果 ----可以通过操作是否出现异常判断是否执行成功
- 查询
fingById(Integer id)
findAll() 查询所有
findAll(Example example) 自定义查询
- @SpringBootTest
- public class JpaTest {
- @Autowired
- private UserMapper mapper;
- //查找
- @Test
- public void test01(){
- User user = mapper.findById(1).get();
- System.out.println(user);
- }
- //增加
- @Test
- public void test02(){
- //jpa中修改和新增在同一个方法
- //如果id为null就是新增 id不为null就是修改
- User user =new User();
- user.setUserName("admin");
- user.setPwd("123");
- user.setRealName("zs");
- user.setDeptId(1);
- user.setCreateDate("2022-2-2");
- User user2 = mapper.save(user);
- System.out.println(user2);
- }
- //修改
- @Test
- public void test03(){
- //jpa中修改和新增在同一个方法
- //如果id为null就是新增 id不为null就是修改
- User user =new User();
- user.setId(1);
- user.setUserName("admin");
- user.setPwd("123");
- user.setRealName("zswwww");
- user.setDeptId(1);
- user.setCreateDate("2022-2-2");
- User user2 = mapper.save(user);
- System.out.println(user2);
- }
- //删除
- @Test
- public void test04(){
- mapper.deleteById(1);
- }
- //删除全部
- @Test
- public void test05(){
- mapper.deleteAll();
- }
- //按照条件查询
- @Test
- public void test06(){
- User user =new User();
- user.setUserName("admin");
- //这种是 where的情况
- Example
example=Example.of(user); - List
all = mapper.findAll(example); - System.out.println(all);
- }
- //按照条件查询
- @Test
- public void test07(){
- User user =new User();
- user.setUserName("admin1");
- //这种是 添加自定义匹配器
- ExampleMatcher matcher =ExampleMatcher.matching()
- .withMatcher("userName",ExampleMatcher.GenericPropertyMatchers.contains());
- Example
example=Example.of(user,matcher); - List
all = mapper.findAll(example); - System.out.println(all);
- }
- //@Query 自定义的 在mapper中
- @Test
- public void test08(){
- User user = mapper.selectUserById(2);
- System.out.println(user);
- }
- @Test
- public void test09(){
- User user = mapper.selectUserById2(2);
- System.out.println(user);
- }
十一、Redis
remote Dictionary server ,redid ,跨平台的 非关系型数据库,采用c 语言编写,数据存储采用 key- value形式,支持各种开发语言有的人也叫缓存数据库1、特点
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启Redis时可以再次被加载
不仅通过了简单的key value,还提供了list set hash等数据结构
支持高可用(redis集群,哨兵--master-slave)
2、优点
性能快
有丰富的数据类型
原子性
有丰富的特性--支持订阅 通知 过去的特性
3、缺点
不能向关系型数据库一样采用关联查询,通过固定的查询命令
查询到的数据需要手动进行解析
数据是非结构化的
4.安装
安装我们使用docker容器化
4.1 pull redis

4.2 run redis

4.3 使用redis


4.4 测试redis是否启动成功

出现pong代表成功启动
5、Redis命令
w3c redis官网:Redis 字符串(String)_w3cschool
5.1 String类型
set key value 设置 key value mset key value key value 同时设置多个 get key 通过key获取value
getset key value 通过key 设置value 并返回之前的value mget key key 获取通过多个key获取多个value 5.2 hash类型
hmset key filed value filed value 设置多个 key value的hash hget key filed 获取key中 hash指定filed 的value hkeys key 获取key中所有哈希的key
hvals key 通过key中所有哈希的value hlen key 获取key中hash的个数 hgetall key 获取key中的所有字段 5.3 list类型
lpush key value value 设置设置一个或多个值 l代表头插 r代表尾插 lpop key 删除头 r代表删除尾 llen key 获取集合的个数 lrange key start end 获取key中安装索引的范围 5.4 set类型
sadd key value value 设置设置一个或多个值 无序 无法重复 sinter key1 key2 取key1 key2 的交集 sunion 取key1 key2的并集 5.5 sorted Set类型(set有序)
zadd key score value score value 设置设置一个或多个值 score代表分值,分值按照从小到大排序 zcount key min max 计算有序集合中在min到max之间的 zrange key start end 取key中索引在start到end之间的 6、缓存穿透、缓存雪崩、缓存击穿及解决办法
6.1、缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到的时候会从数据库进行获取,数据库取到后更新缓存,并返回结果,数据库也没取到,那就直接返回空结果

6.2、缓存穿透
描述:缓存穿透是指缓存和数据库都没有数据,而用户不断发起请求,如发起id为-1的数据或者id为特别大并且不存在的数据的时候,这时用户可能是攻击者,攻击会导致数据库压力过大。
解决方案:
第一种:接口处增加校验,如用户鉴权校验,id做基础校验,id<=0的时候直接拦截,不进行访问后端
第二种:从缓存中取不到数据,在数据库中也没有取到,这时也可以将key value对写为key-null的形式,放在一直访问数据库,并将缓存有效时间设置短点,如30秒(设置太长会导致正常情况下也没法使用).这样就放在攻击用户返回用同一个id暴力攻击
6.3、缓存击穿
描述:缓存击穿是指缓存中没有但是数据库中有数据(一般都是缓存时间到期),这时候由于并发用户特别多,同时读缓存没读到数据,有同时去数据库去取数据,因此其数据库压力瞬间增大,造成过大压力
解决方案:
第一种 设置热点数据永不过期
第二种 加互斥锁,互斥锁参考代码如下:

6.4、缓存雪崩
描述:缓存雪崩是指缓存中数据大批量到期,而查询数据量很大,引起了数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿是并发查同一条数据,缓存雪崩是并发查不同的数据,很多数据都查不到缓存,从而查询数据库
解决方案:
第一种: 缓存数据的过去时间设置随机,放在同一时间大量数据过期事件发生
第二种: 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中 ,设置热点数据永不过期
7、springboot使用redis
导入依赖
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-testartifactId>
- dependency>
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-data-redisartifactId>
- dependency>
设置yml
- spring:
- redis:
- host: 192.168.119.120 #设置host
- port: 6379 #设置端口
测试
- package com.sofwin.test;
- import org.junit.jupiter.api.Test;
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.boot.test.context.SpringBootTest;
- import org.springframework.data.redis.core.StringRedisTemplate;
- import java.util.Iterator;
- import java.util.List;
- import java.util.Map;
- import java.util.Set;
- /**
- * @author : wentao
- * @version : 1.0
- */
- @SpringBootTest
- public class ReidsTest {
- @Autowired
- private StringRedisTemplate stringRedisTemplate;
- //-----string-----
- @Test
- public void test01(){
- // set(K key, V value, Duration timeout)
- stringRedisTemplate.opsForValue().set("string","1");
- }
- @Test
- public void test02(){
- String string = stringRedisTemplate.opsForValue().get("string");
- System.out.println(string);
- }
- //-----hash---------
- @Test
- public void test03(){
- stringRedisTemplate.opsForHash().put("hash","username","zhangsna ");
- stringRedisTemplate.opsForHash().put("hash","pwd","111 ");
- stringRedisTemplate.opsForHash().put("hash","age","12 ");
- }
- @Test
- public void test04(){
- Object o = stringRedisTemplate.opsForHash().get("hash", "username");
- System.out.println(o);
- //获取键值对
- Set
- System.out.println(hash);
- }
- //----list----
- @Test
- public void test05(){
- stringRedisTemplate.opsForList().leftPush("list","1");
- stringRedisTemplate.opsForList().leftPush("list","1");
- stringRedisTemplate.opsForList().leftPush("list","2");
- stringRedisTemplate.opsForList().leftPush("list","3");
- }
- @Test
- public void test06(){
- Long size = stringRedisTemplate.opsForList().size("list");
- List
list = stringRedisTemplate.opsForList().range("list", 0, size - 1); - for (String s : list) {
- System.out.println(s);
- }
- }
- //----set
- @Test
- public void test07(){
- stringRedisTemplate.opsForSet().add("set","1");
- stringRedisTemplate.opsForSet().add("set","1");
- stringRedisTemplate.opsForSet().add("set","2");
- stringRedisTemplate.opsForSet().add("set","4");
- }
- @Test
- public void test08(){
- Set
set = stringRedisTemplate.opsForSet().members("set"); - Iterator
iterator = set.iterator(); - while (iterator.hasNext()){
- System.out.println(iterator.next());
- }
- }
- //----sortSet
- @Test
- public void test09(){
- stringRedisTemplate.opsForZSet().add("zset","1",1);
- stringRedisTemplate.opsForZSet().add("zset","2",5);
- stringRedisTemplate.opsForZSet().add("zset","3",3);
- stringRedisTemplate.opsForZSet().add("zset","4",1);
- }
- @Test
- public void test10(){
- Set
zset = stringRedisTemplate.opsForZSet().range("zset", 0, 3); - Iterator
iterator = zset.iterator(); - while (iterator.hasNext()){
- System.out.println(iterator.next());
- }
- }
- }
十二、缓存
这里说的缓存是spring本地缓存,适用于单体应用,不适合分布式应用。分布式应用,应该使用分布式缓存如:Redis




1、开启缓存
在启动类上添加@EnableCaching注解 ---表示开启缓存

在业务方法上添加注解 启动缓存
@Cacheable 启动缓存
这个注解会检查缓存,如果缓存中有数据,则直接返回,不在调用方法,即不在访问数据库;否则就先调用方法,访问数据库,然后将结果放置到缓存中

这样的话当访问一次时候 返回数据库,缓存
第二次在访问你的时候就直接可以在缓存中获取了
测试
- @Test
- public void test11(){
- User user = service.queryById(2);
- User user2 = service.queryById(2);
- }

打印一次sql 说明第二次的时候没有访问数据库
@CachePut 更新缓存
CachePut会先执行方法,将返回值放置到缓存,一会用于更新操作

- @Test
- public void test10(){
- User user = service.queryById(2);
- System.out.println(user);
- User user1 =new User();
- user1.setUserName("www");
- user1.setId(2);
- service.update(user1);
- User user2 = service.queryById(2);
- System.out.println(user2);
- }

第二次直接在缓存中取,因为设置了 CachePut,因此更加了缓存 所以username才能更新为qqq
清除缓存 @CacheEvict
用于清除缓存,一般用户的删除操作

- @Test
- public void test11(){
- User user = service.queryById(2);
- User user1 = service.queryById2(2);
- User user2 = service.queryById(2);
- }
如果正常情况下是打印2条 sql语句
但是由于第二个 queryById2 执行后会将量缓存清除 ,因此会打印3条sql语句

-
相关阅读:
CS资质证书获证后企业需要注意哪些问题?
存在重复元素(C++解法)
你好呀,看到你的《发卡系统微信小程序,支持流量主广告和官方支付》这篇文章
vim字符串全局替换
目标检测4--Adaptive Training Sample Selection(ATSS)算法
蓝桥杯-队列
[MAUI]深入了解.NET MAUI Blazor与Vue的混合开发
C语言基础篇 —— 3-1 一文秒懂指针数组与数组指针
onnx-modifier使用
订单及其状态机的设计实现
- 原文地址:https://blog.csdn.net/weixin_52574640/article/details/126462910
