-
【深度学习】05-02-自注意力机制多种变形-李宏毅老师21&22深度学习课程笔记
文章目录
- 有哪些self-attention变形?
- 如何使得self-attention更高效?- 加快Attention Matrix计算
- 何种情况下需要优化self-attention?- 输入向量维度很大时
- 如何加快self-attention的求解速度呢?- 先验&自学习
- 人类的知识或经验
- 自学习 - 由神经网络NN计算得出哪些地方需要计算 Attention
- 是否需要完整的Attention Matrix?- 不需要,完整AM中存在冗余列可删除
- 回顾
- 必须K和Q求内积才能求出Attention吗?- 不一定,Synthesizer
- Attention存在的意义
- 是否可以不使用Attention?
- 各种自注意力机制变形的效果对比
有哪些self-attention变形?

论文:Long Range Arena: A Benchmark for Efficient Transformers
综述:Efficient Transformers: A Survey
如何使得self-attention更高效?- 加快Attention Matrix计算
How to make self-attention efficient?

先简单复习下之前的self-attention。假设输入序列(query)长度是N,为了捕捉每个value或者token之间的关系,需要对应产生N个key与之对应,并将query与key之间做dot-product,就可以产生一个Attention Matrix(注意力矩阵),维度N×N。这种方式最大的问题就是当序列长度太长的时候,对应的Attention Matrix维度太大,会给计算带来麻烦。
何种情况下需要优化self-attention?- 输入向量维度很大时
对于transformer来说,self-attention只是大的网络架构中的一个module。由上述分析我们知道,对于self-attention的运算量是跟N的平方成正比的。当N很小的时候,单纯增加self-attention的运算效率可能并不会对整个网络的计算效率有太大的影响。因此,提高self-attention的计算效率从而大幅度提高整个网络的效率的前提是N特别大的时候,比如做图像识别(影像辨识、image processing)。
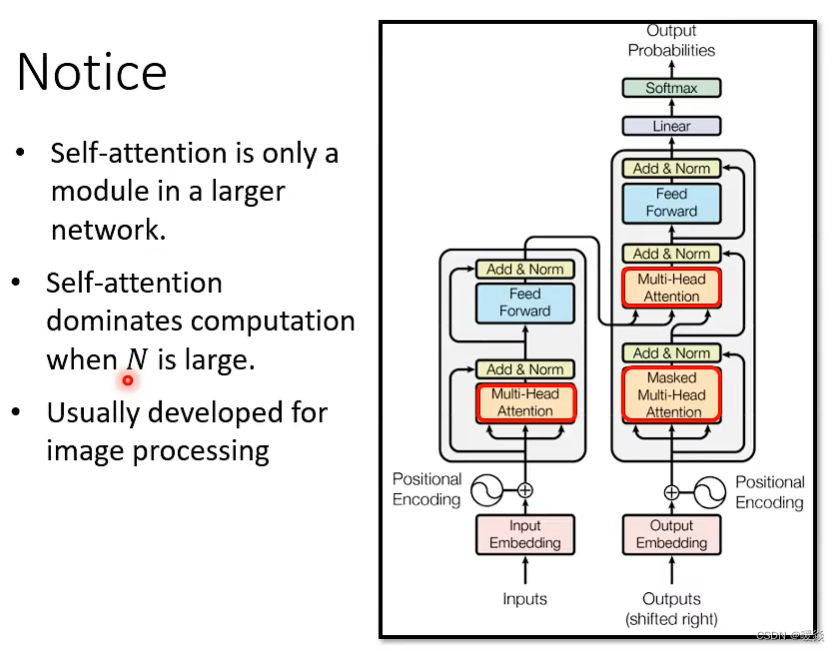
如何加快self-attention的求解速度呢?- 先验&自学习
人类的知识或经验
根据上述分析可以知道,影响self-attention效率最大的一个问题就是Attention Matrix的计算。如果可以根据一些人类的知识或经验,选择性的计算Attention Matrix中的某些数值或者某些数值不需要计算就可以知道数值,理论上可以减小计算量,提高计算效率。
Local Attention/Truncated Attention - 先验(局部Attention适用于当前任务)& 局部Attention
某些任务中,Attention机制并不需要看到整个输入(先验),可能在每个位置上只需要看左右邻居就可以得到正确的答案。
例如,在做文本翻译的时候,有时候在翻译当前的token时不需要给出整个sequence,其实只需要知道这个token两边的邻居,就可以翻译的很准,也就是做局部的attention(local attention),根据这个先验知识,可以设置 Attention Matrix 的非局部 attention 的值为0(下图矩阵中灰色格子),只需要计算蓝色格子即可,这样可以大大提升运算效率,但是缺点就是只关注周围局部的值,这样做法其实跟CNN就没有太大的区别了。

Stride Attention - 先验(间隔Attention适用于当前任务)& 间隔Attenion
某些任务中,Attention只看相邻信息效果不好,可以换一种思路,就是在计算Attention时,计算空一定间隔(stride)的左右邻居(先验),此时可设置Attention Matrix中一部分值为0(下图灰色格子),从而捕获当前与过去和未来的关系。当然stride的数值可以自己确定。

Global Attention - 先验(使用何种Special Token策略) & Special Token

可能token与其他token没有计算关系,甚至跟相邻token也没有计算关系,special token的作用就是可以使得这些token间产生关系。
方式一:指定一些token作为special token与序列产生全局关系
选择sequence中的某些token作为special token(比如标点符号),或者在原始的sequence中增加special token。让special token与序列产生全局的关系,但是其他不是special token的token之间没有attention。以指定原始sequence最前面两个special token为例,如下图所示。


Attention Matrix中,前两行有值,表示前两个token与所有token计算关系。
Attention Matrix中,前两列有值,表示所有token只与前两个token计算关系。方式二:插入一些token作为special token与序列产生全局关系

到底哪种attention最好呢? - 不同的head使用不同的方式
对于一个网络,可以考虑使用所有的改进版 attention 优化 Attention Matrix 计算,有的 head 可以做 local attention,有的 head 可以做 global attention…。看下面几个例子:
Longformer就是组合了上面三种attention。
[Longformer 论文:https://arxiv.org/abs/ 2004.05150](https://arxiv.org/abs/ 2004.05150)

Big Bird就是在Longformer基础上增加了随机选择attention赋值,进一步提高计算效率。
Big Bird 论文:https://arxiv.org/abs/2007.14062

求最小值置0 - 先验(最小值对结果没有太大影响)
上面三种方法(Local Attention,Stride Attention,Global Attention)都是人为设定的哪些地方需要计算attention,哪些地方不需要计算attention,但是这样算并不一定是最好的方法。
一种思路是:找到图中特别小的值,这些值对最后的结果影响很小,所以可以将这些值设置为0,优化 Attention Matrix 计算。
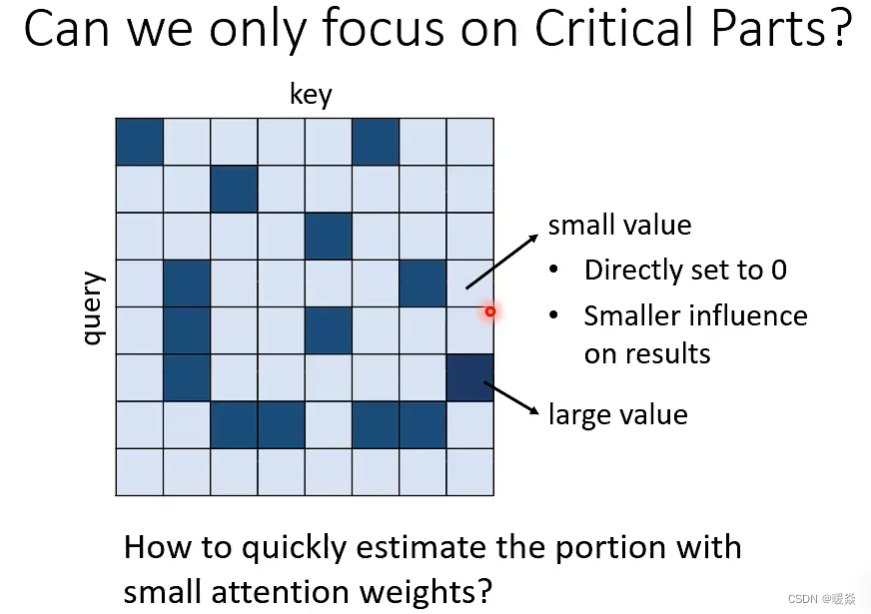
Clustering - 先验(如何定义相似及相似程度?)
Reformer和Routing Transformer两篇论文中使用一种Clustering(聚类)的方案。
Clustering思想
1 先对query和key进行Clustering聚类

2 同Clustering计算Attention
属于同一Clustering的query和key来计算attention,不属于同一Clustering的就不参与计算,这样可以加快Attention Matrix的计算。
比如图示例子中,分为4类:1(红框)、2(紫框)、3(绿框)、4(黄框)。相同Clustering计算关系,不同Clustering格子对应的值设置为0。

Clustering聚类计算量是否很大?- Clustering 有很多优化方法
如果Clustering聚类计算量很大,那么使用Clustering优化Attention Matrix计算将失去意义。事实上,Clustering有很多优化方法,Reformer和Routing Transformer两篇论文中使用了不同的Clustering优化方法。
自学习 - 由神经网络NN计算得出哪些地方需要计算 Attention
单独训练一个网络,输入是input sequence,输出是相同长度的weight sequence。将所有weight sequence拼接起来(拼起来必须跟Attention Matrix同形),再经过特殊方式进行转换(从continual matrix 到 binary matrix),就可以得到一个哪些地方需要算attention,哪些地方不需要算attention的Attention Matrix矩阵。整个过程可以微分,所以训练该网络是跟整个网络一起训练。
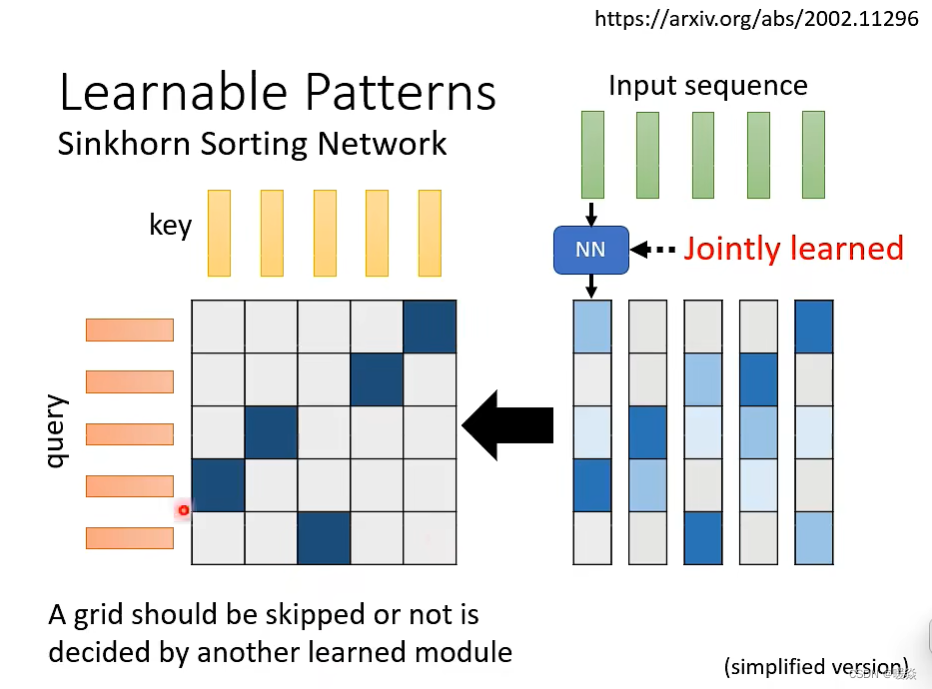
NN计算出向量再转换为 Attention Matrix 是否比直接计算 Attention Matrix 复杂?
有一个细节是:某些不同的sequence会共用NN,经过NN输出同一个weight sequence,这样可以大大减小计算量。
例如:对输入的100个向量进行分组,假设每组10个向量,每组共用一个NN,每组输出一个向量,该组的10个输入向量对应的输出都是这一个输出向量。
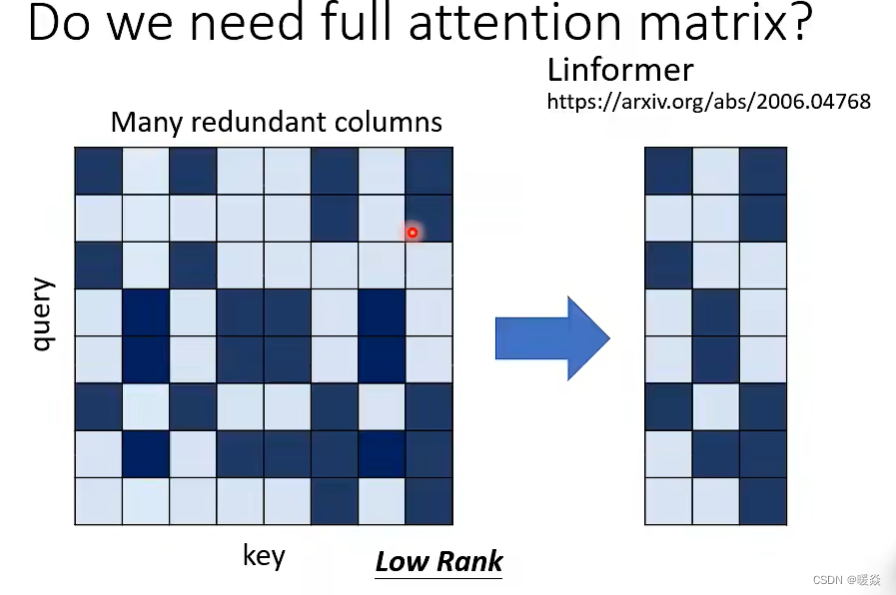
是否需要完整的Attention Matrix?- 不需要,完整AM中存在冗余列可删除
完整AM列冗余
在论文Linformer中,计算Attention Matrix的rank,发现Attention Matrix都是low rank的,即Attention Matrix中很多列都是线性相关(当前列可以被其他列的线性组合表示),最后提出,完整的 Attention Matrix中有很多冗余的列,可以删除这些列,加快运算速度。
如何使 Attention Matrix 列不冗余?- 只选择代表性key,value参与计算
计算K点乘Query过程中,从N个key中选出K个具有代表性的key,用key与所有Query相乘得到中间值矩阵,从value中选出k个具有代表性的value,中间值矩阵的每一行与对应的一个value相乘,得到最终的attention matrix。
为什么选有代表性的key,value不选有代表性的query?- 输出维度与query维度一致
因为query跟output是对应的,这样output的维度变少(在有些任务中,如seq2seq要求输入与输出维度相同时),output维度变少会损失信息。
如何选出有代表性的key,value? - key做卷积 or key乘矩阵
方式一:直接对key做卷积(conv)
[论文:Compressed Attention](https://arxiv.org/abs/ 1801.10198)
用卷积网络扫过所有的输入向量,筛选后输出向量。

方式二:对key与矩阵相乘
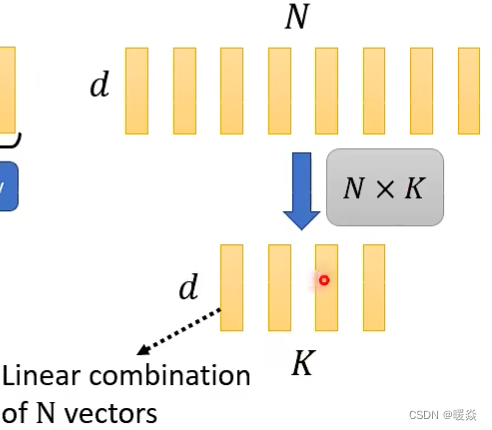
回顾
Attention 计算过程

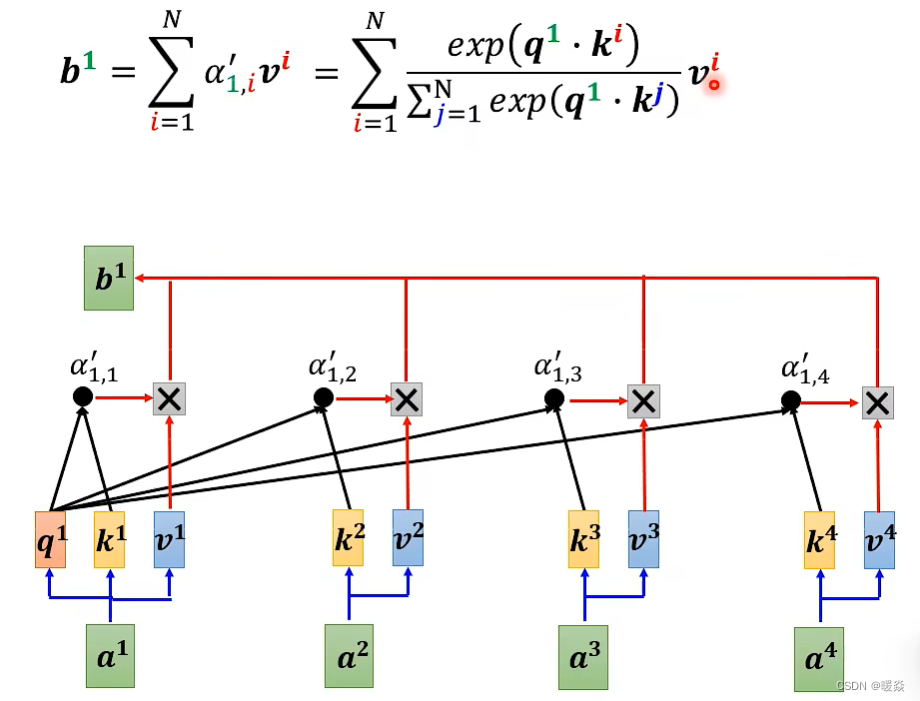
如果对 Attention 计算过程加速?
初略证明:假设先忽略softmax

优化的方法:先进行VK^T乘法,再与Q相乘。

(VKT)Q VS V(KTQ)
结果一样,运算量不一样。

N是Sequence长度(即输入向量的个数),d是输入向量的维度。

V(KTQ)

(VKT)Q

严格证明:不忽略softmax
原始的Attention计算过程如下图所示。
下面对原始Attention计算过程进行简化。
简化核心: e ( q ⋅ k ) ≈ Φ ( q ) ⋅ Φ ( k ) e^{(q \cdot k)} \approx \Phi(q) \cdot \Phi(k) e(q⋅k)≈Φ(q)⋅Φ(k)


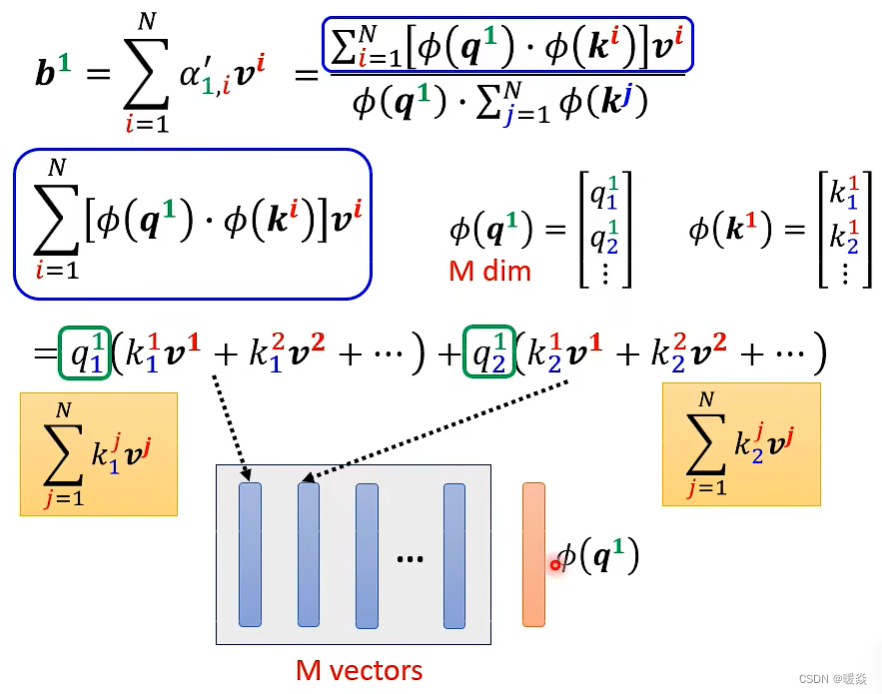
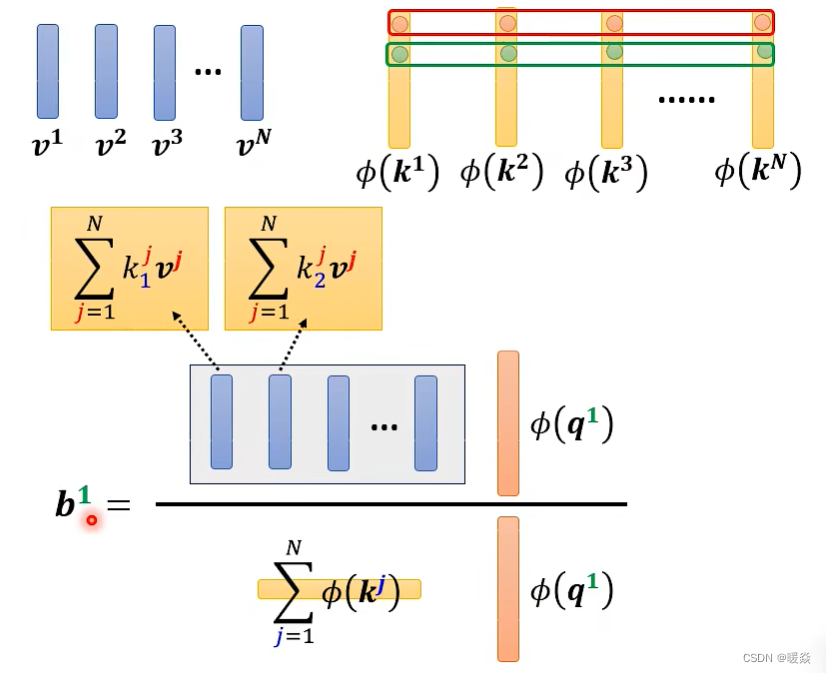
分子的蓝色矩阵和分母的黄色部分与上标索引 j 无关,所以只需要计算一次,多个 b i b^i bi的计算可以共享使用这两部分计算结果。

对于【如何优化self-attention的计算?】,上面是从公式角度讲解,下面从直观理解的角度分析V(KTQ)到(VKT)Q 优化后的 self-attention 计算过程。



如何实现 e ( q ⋅ k ) ≈ Φ ( q ) ⋅ Φ ( k ) e^{(q \cdot k)} \approx \Phi(q) \cdot \Phi(k) e(q⋅k)≈Φ(q)⋅Φ(k)? - 很多实现方案

必须K和Q求内积才能求出Attention吗?- 不一定,Synthesizer
不一定。在论文 Synthesizer 中,对于 attention matrix 不是通过q和k得到的,而是作为网络参数学习得到。虽然不同的 input sequence 对应的 attention weight 是一样的,但是 performance 不会变差太多。其实这也引发一个思考,attention的价值到底是什么?
Attention存在的意义
[待补充]
是否可以不使用Attention?
下面有几篇论文,用mlp的方法代替attention来处理sequence。

各种自注意力机制变形的效果对比
下图中,纵轴的LRA score数值越大,网络表现越好;横轴表示每秒可以处理多少sequence,越往右速度越快;圈圈越大,代表用到的memory越多(计算量越大)。

-
相关阅读:
23、mysql数据库的安装
10.4作业
MySQL binlog集市的项目小结
d3dx9_43.dll缺失怎么办?教你一分钟修复d3dx9_43.dll丢失问题
基于django电影推荐系统
设计模式-责任链设计模式
BCC源码内容概览(1)
Django 入门学习总结7-静态文件管理
数据分析思维分析方法和业务知识——分析方法(三)
多线程8锁案例演示
- 原文地址:https://blog.csdn.net/guai7guai11/article/details/126485549