-
clickhouse--join操作汇总【semi、anti、any、asof、global、colocate、cross】
1. 测试的初始化数据
--表tb1 CREATE TABLE tb1( `id` UInt32, `name` String, `time` DateTime ) ENGINE = MergeTree() PARTITION BY toYYYYMM(time) ORDER BY id; --表 tb2 CREATE TABLE tb2( `id` UInt32, `rate` UInt8, `time` DateTime ) ENGINE = MergeTree() PARTITION BY toYYYYMM(time) ORDER BY id; --表 tb3 CREATE TABLE tb3( `id` UInt32, `star` UInt8 ) ENGINE = MergeTree() ORDER BY id; --插入数据 INSERT INTO tb1 VALUES (1, 'ClickHouse', '2022-08-01 12:00:00') (2, 'Spark', '2022-08-01 12:30:00') (3, 'ElasticSearch', '2022-08-01 13:00:00') (4, 'HBase', '2022-08-01 13:30:00') (7, 'ClickHouse', '2022-08-01 14:00:00') (8, 'Spark', '2022-08-01 14:30:00'); INSERT INTO tb2 VALUES (1, 100, '2022-08-01 11:55:00') (1, 105, '2022-08-01 11:50:00') (2, 90, '2022-08-01 12:01:00') (3, 80, '2022-08-01 13:10:00') (5, 70, '2022-08-01 14:00:00') (6, 60, '2022-08-01 13:55:00'); INSERT INTO tb3 VALUES (1, 1000) (2, 900);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
2. join操作
官方文档详见join clause
2.1. join语法
SELECT <expr_list> FROM <left_table> [GLOBAL] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI|ANY|ASOF] JOIN <right_table> (ON <expr_list>)|(USING <column_list>) ...- 1
- 2
- 3
- 4
join_default_strictness,默认为ALL,可能的行为包括如下:ALL—如果右表有几个匹配的行,ClickHouse就会从匹配的行创建一个笛卡尔积。这是标准SQL中的正常JOIN行为。ANY—如果右表有几个匹配的行,则只连接第一个找到的行。如果右表只有一行匹配,则ANY和ALL的结果是相同的。ASOF—用于连接不确定匹配的序列。Empty string—如果查询中没有指定ALL或ANY, ClickHouse将抛出异常。
- INNER、OUTER、CROSS
- JOIN without specified type implies INNER.
- Keyword OUTER can be safely omitted.
- Alternative syntax for CROSS JOIN is specifying multiple tables in FROM clause separated by commas.
2.2. ALL、ANY、ASOF
- ALL: 如果左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表种全部连接的数据。连接依据为:left.key=right.key。
select a.id,a.name,b.rate from tb1 a inner join tb2 b using id; select a.id,a.name,b.rate from tb1 a all inner join tb2 b using id;- 1
- 2
- 3
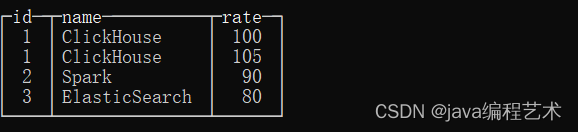
- ANY 如果左表内的一行数据,在右表中有多行数据与之连接匹配,则仅返回右表中第一行连接的数据。连接依据同样为:left.key=right.key
如果左表内的一行数据,在右表中有多行数据与之连接匹配,则仅返回右表中第一行连接的数据。连接依据同样为:left.key=right.key- 1

- ASOF 是一种模糊连接,允许在连接键之后追加定义一个模糊连接的匹配条件asof_column
- ASOF会先以 left.key = right.key 进行连接匹配,然后根据AND 后面的 closest_match_cond(也就是这里的a.time >= b.time)过滤出最符合此条件的第一行连接匹配的数据。
- 对 asof_colum 字段的使用有3点需要注意:
- 必须包含一个有序的序列【Must contain an ordered sequence.】
- asof_column 必须Int, UInt, Float, Date, DateTime, Decimal.
- asof_column不能是数据表内的唯一字段【Can’t be the only column in the JOIN clause】,也就是说连接键(JOIN KEY)和asof_column不能是同一字段
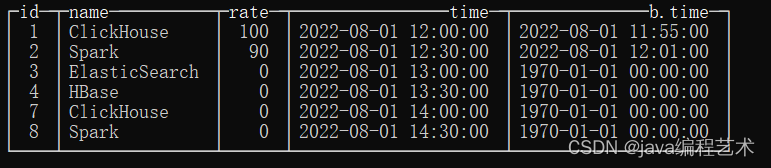
select a.id,a.name,b.rate,a.time,b.time from tb1 a asof join tb2 b on a.id=b.id and a.time>=b.time select a.id,a.name,b.rate,a.time,b.time from tb1 a asof join tb2 b using(id,time)- 1
- 2
- 3

select a.id,a.name,b.rate,a.time,b.time from tb1 a left asof join tb2 b on a.id=b.id and a.time>=b.time select a.id,a.name,b.rate,a.time,b.time from tb1 a left asof join tb2 b using(id,time)- 1
- 2
- 3
2.3. semi、anti
- semi: 类似于mysql的exists、in查询,“连接键”上的白名单,不产生笛卡尔积【a whitelist on “join keys”, without producing a cartesian product.】
select a.id,a.name from tb1 a semi join tb2 b on(a.id=b.id); select a.id,a.name from tb1 a semi join tb2 b using id; select a.id,a.name from tb1 a semi join tb2 b on(a.id=b.id);- 1
- 2
- 3
- 4
- 5

- anti 类似于mysql的not exists、not in查询,“连接键”上的黑名单,不产生笛卡尔积【a blacklist on “join keys”, without producing a cartesian product.】
select a.id,a.name from tb1 a anti join tb2 b using id; select a.id,a.name from tb1 a anti join tb2 b on(a.id=b.id);- 1
- 2
- 3

3. 分布式join
3.1. streaming算子
ClicHouse分布式join通常涉及到左右表为分布式表,分布式执行过程中需要将数据在节点间进行交换,
将数据在节点间交换的动作在分布式执行计划中称为数据的流动streaming算子,
ClickHouse支持的streaming算子有如下三种:- Broadcast Join 数据广播算子
- Shuffer Join 数据重分布算子
- Colocate Join 数据存储在本地不需要进行分布式交换
其实对于ClickHouse来说,说是实现了Shuffle JOIN还比较勉强,其只实现了类Broadcast JOIN类型,ClickHouse当前的分布式join查询框架更多的还是实现了两阶段查询任务
与ClickHouse相比通常业界MPP数据库分布式join查询框架模型的数据在节点间交换Streaming算子通常为以下几种:

- Gather算子类似于在ClickHouse中的SQL发起initiator节点,第一阶段在各个节点完成本地join后,会将各节点结果发送给initiator节点进行第二阶段的汇总工作,initiator节点再将结果发送给客户端;
- Broadcast算子 数据广播算子,每个节点将自己拥有的分片数据发送给目标节点,对应到ClickHouse为Broadcast JOIN
- Redistribute算子 数据重分布算子,数据重分布会将数据按照一定的重分布规则重新发送到对应的目标节点,对应到ClickHouse为Shuffer JOIN;
- Local join,数据会在本地进行join,对应到ClickHouse为Colocate join,其不需要数据重分布或广播,节点间和网络上无数据交换和传播,此实现方式的join性能也最佳
3.2. GLOBAL JOIN
Broadcast join对于大小表关联,需要将小表数据放在右边;
1)有如下分布式Join SQL语句:

2)执行过程如下:

- ① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
- ② host-0节点将任务改写为SQL2子查询任务;
- ③ Coordinator节点将SQL2子查询任务下发到集群各个节点执行;
- ④ 各子节点任务执行完成之后将结果发回到协调节点;
- ⑤ 协调节点将上一步接收到的结果汇总为结果集;
- ⑥ 协调节点将结果集发送到集群各个节点,同时将SQL3任务下发到各个节点;
- ⑦ 各节点在本地将左表的分片和右表子查询结果集进行join计算,然后将结果及发回到协调节点;
- ⑧ 协调节点将最终结果返回给客户端。
3)总结:
- 右表的查询在initiator节点完成后,通过网络发送到其他节点,避免其他节点重复计算,从而避免查询放大问题;
- GLOBAL JOIN 可以看做一个不完整的Broadcast JOIN实现。如果JOIN的右表数据量较大,就会占用大量网络带宽,导致查询性能–
- ClickHouse的global join方式和业界MPP的区别:
- ClickHouse会将右表过滤结果汇总到一个节点,然后又发送到所有节点,对单节点内存/磁盘空间占用较大,全量数据发送到所有节点,对网络带宽消耗也较大;
- 业界MPP数据库每个节点并行的将自己一部分数据广播发到所有节点,之后就可以直接进行下一阶段的本地join动作,多个节点都能并行执行,同时数据也不需要从一个节点发送到所有节点,对网络和单节点磁盘及内存消耗较少。
3.3. Colocate Join
Colocate join需要将join key字段使用相同的分布算法,将分布键相同数据分布在同一个计算节点。
1) 有如下分布式Join SQL语句:
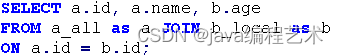
2) 执行过程如下:
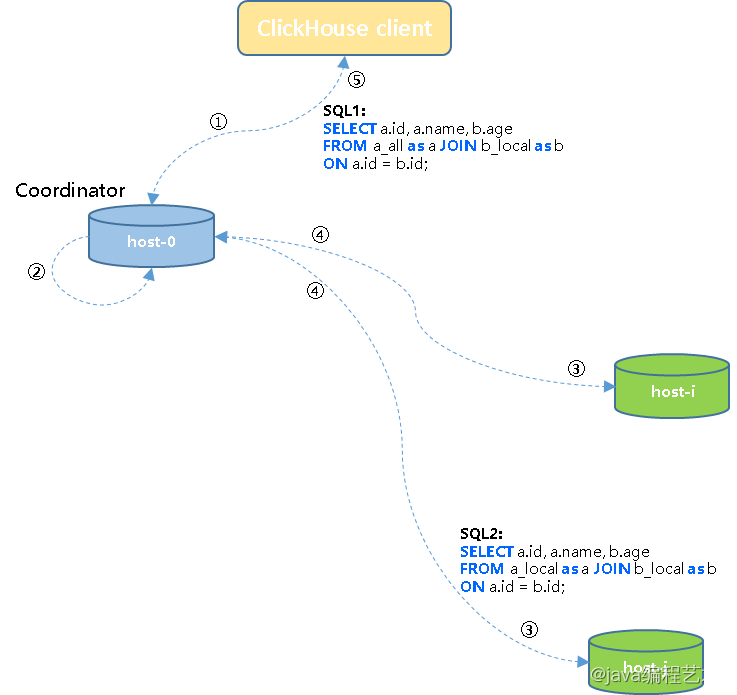
- ① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
- ② host-0节点将任务改写为SQL2子查询任务;
- ③ Coordinator节点将SQL2子查询任务下发到集群各个节点执行;
- ④ 各子节点任务执行完成之后将结果发回到协调节点;
- ⑤ 协调节点将上一步接收到的结果汇总为结果集返回给客户端。
3) 总结:
由于数据已经进行了预分区/分布,相同的JOIN KEY对应的数据一定存储在同一个计算节点,join计算过程中不会进行跨节点的数据交换工作,所以无需对右表做分布式查询,也能获得正确结果,并且性能较优。4) Colocate JOIN原理:
根据“相同JOIN KEY必定相同分片”原理,
将涉及JOIN计算的表,按JOIN KEY在集群维度作分片。将分布式JOIN转为节点的本地JOIN,极大减少了查询放大问题。按如下操作:- 将涉及JOIN的表字段按JOIN KEY用同样分片算法进行分片;
- 将JOIN SQL中右表换成相应的本地表名称进行join。
5) Colocate Join场景约束
- 数据写入
- Colocate join场景需要用户在系统建设前提前进行数据规划,数据写入时join的左右表join条件字段需要使用相同哈希算法入库分布,保证join key相同数据写入到同一个计算节点上。
- 如果对数据写入时效性要求不太高的场景,可通过分布式表进行生成数据,生成数据简单快捷,性能较慢;
- 如果对数据写入时效性要求较高的场景,可通过应用/中间件写入数据到local表,中间件需要实现入库数据分布算法,入库性能较好。
- 扩缩容
- 扩缩容完成后,需要将全部数据重写/重分布一遍,缺点:耗时长,占用存储可能暂时会翻倍,
- 一种节省空间的方式是:逐个表进行重分布,每个表数据重分布完成后可删除重分布前的数据,避免占用过多存储。
- 将来的改进/增强:重分布过程中支持可写在线,重分布尽量少或不影响写入查询的在线操作,减少重分布过程中对客户业务的影响。
3.2. cross JOIN
生成整个表的笛卡尔积,不需要指定“连接键”。【 produces cartesian product of whole tables, “join keys” are not specified.】
select a.id,a.name,b.rate,b.time from tb1 a cross join tb2 b;- 1
参考
-
相关阅读:
LeetCode_快速幂_递归_中等_50.Pow(x, n)
GBRank:一种基于回归的排序方法
C++【STL】【STL容器的使用与实现】
【算法基础】用数组模拟栈和队列
Docker SpringBoot项目连接本地数据库
null跟undefined的区别
TTS行业调研20221201
mysql执行拼接的sql语句
MySQL向自增列插入0失败问题
echarts 水球示例
- 原文地址:https://blog.csdn.net/penriver/article/details/126482333