-
机器学习算法——分类问题1(类别不平衡问题--欠采样方法)
类别不平衡(class-imbalance)就是指分类任务中不同类别的训练样例数目差别很大的情况。
欠采样法是解决类别不平衡问题之一。
欠采样法是直接对训练集中多数样本进行“欠采样”,即去除一些多数类中的样本使得正例、反例数目接近,然后再进行学习。
随机欠采样顾名思义即从多数类
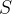 中随机选择一些样本组成样本集
中随机选择一些样本组成样本集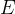 ,然后将样本集E从S中移除。新的数据集
,然后将样本集E从S中移除。新的数据集 。
。缺点:
随机欠采样方法通过改变多数类样本比例以达到修改样本分布的目的,从而使样本分布较为均匀,但也存在一些问题,对于随机采样,由于采样的样本集合少于原来的样本集合,会造成数据缺失。
目前代表性的算法是EasyEnsemble和BalanceCascade。
一、EasyEnsemble算法
EasyEnsemeble的原理是通过重复组合正样本与随机抽样的同样数量的负样本,训练若干数量分类器进行集成学习。
这个算法的流程如下:

解释一下,数据中,少数类别为P;多数类别为N;从N中分出多个子集,数量为T;
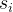 代表基分类器,
代表基分类器,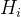 为训练基分类器的训练迭代次数。然后根据少数类别P的数量对多数类别N进行随机采样产生
为训练基分类器的训练迭代次数。然后根据少数类别P的数量对多数类别N进行随机采样产生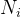 ,使得
,使得 。然后把和P结合起来,给基分类器进行学习。这里引入了下标j,是由于默认的基分类器是AdaBoost,而AdaBoost是由N个弱基分类器组成的,j表示AdaBoost基分类器里的第j个弱分类器。
。然后把和P结合起来,给基分类器进行学习。这里引入了下标j,是由于默认的基分类器是AdaBoost,而AdaBoost是由N个弱基分类器组成的,j表示AdaBoost基分类器里的第j个弱分类器。二、BalanceCascade算法
基本架构与EasyEnsemble相同,不同的地方在于每训练一个(AdaBoost)分类器后就将正确分类的样本去掉,错误分类的样本放回到原样本空间中,通过调整阈值来筛选出分类错误的样本将其保留,阈值调整为:
![\sqrt[T-1]{|P|/|N|}](https://1000bd.com/contentImg/2023/10/26/030602049.png)
这个算法的流程如下:

这两种算法实现在imblearn包中,具体调用如下:
from imblearn.ensemble import EasyEnsembleClassifier
-
相关阅读:
【Kafka一】概述
Redis——Lettuce连接redis集群
面试专区|【32道接口API测试基础高频题整理(附答案背诵版)】
Pytorch实现线性回归模型
基于PSO的UAV三维路径规划(Matlab代码实现)
Audition RMS计算原理解析
numpy教程:The NumPy ndarray
ceph高可用
帧结构的串行数据接收器——Verilog实现
基于Keil a51汇编 —— 控制语句
- 原文地址:https://blog.csdn.net/Vicky_xiduoduo/article/details/126380152