-
【吃瓜之旅】第三章吃瓜学习
【吃瓜之旅】本系列是针对datawhale《吃瓜教程-西瓜书和南瓜书》的学习笔记。本次是对西瓜书第三章的个人学习总结。第三章打下了回归和分类的理论基础,主要引入基础的一元线性回归,到多元线性回归及回归方程的求解,从逻辑回归的基础引入二分类的分类函数,及引出响应参数如何求解,引入线性判别分析,从二维空间的分类(二分类)到多分类问题。最后介绍数据不平衡问题。这一章是后面章节的核心基础,需要认真学习,虽然用六天学习(最长周期),但是每天其实都需要花费时间理解公式做认真推导。目前已经看完了,在这简单做做总结方便回顾复习。
第三章:线性模型
3.1基本形式
基本形式是f(x) = wx +b


就是可以理解有多个w参数控制,即为多个属性的重要性,可以抽象为一个行向量wT。对应的x也为多维列向量。这样得到的,可以对任意一个x数据列求得在f(x)预测后的回归值。
3.2线性回归
线性回归就是式(3.2)中体现的建模回归函数,通过线性回归的方式对数据进行预测。
就是有很多点,让每个点在平行y轴的线上与直线的平均距离最短,这样就是我们求出来最理想的线性回归函数。相当∑i∈(1,n)(hi-h)^2 (h为平均数)的函数求极小值,这里用到的方法就是最小二乘法。


现在的目的就到了求
 这个函数的最小值问题。
这个函数的最小值问题。此刻引入:极大释然估计 经过层层推导得到函数w,b的对应解。建议参考凸优化相关知识配合学习,或者看视频也可。


为了简便计算,把连乘处理为求和。因为讨论最值问题,可以将L化为lnL不改变单调性同时求出最值。因为后面是对一个正态分布讨论极大似然估计的值,因此这以上都是铺垫哈。

这里就是把e这个随机误差,看成一个正态分布为0的式子,然后替换得到p(y)
意外发现p(y)可以用极大似然估计求出θ(θ是一个向量,也就是我们的w和b)
同样的

 通过极大似然估计也得到了式子3.4。
通过极大似然估计也得到了式子3.4。后面我们求解w和b的值,让我们式3.4取得最小。

如要取得最小需证明这是凸函数,然后凸函数求w b

引入凸集 (凸函数前提条件)



引出海塞矩阵,为求证凸函数做准备。 到现在就证明海塞矩阵正定或半正定。


到这里就是半正定矩阵的公式,顺序主子式求解均非负。就是开始结行列式。得到凸函数后就求得一阶导数为0(梯度为0),带入即可。

开始对其分布求偏导,

b值求出后


带入求出w 和 b的解,以后一元线性回归一下就可以套公式了。
结论如下。

接下来我们求多元线性回归的w和b
这里做了一个操作,对w扩充了一项,把b抹去了

最后就是求
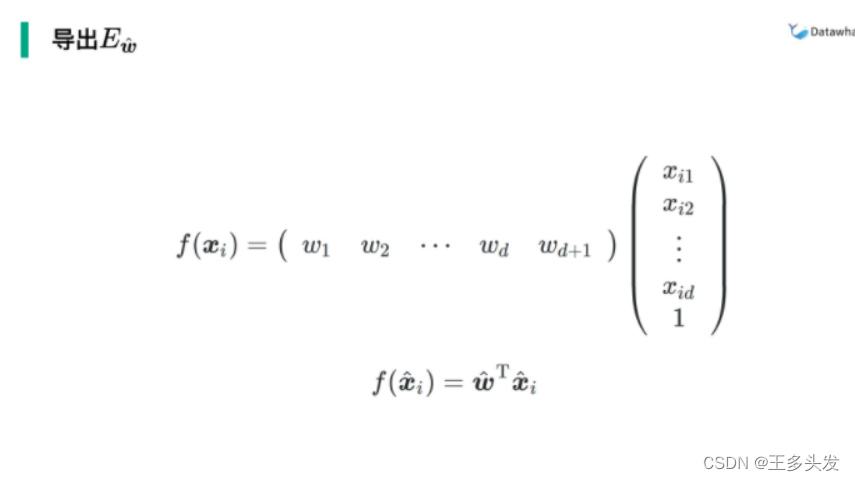
w^ 这个值 这里的x也变了,因为w扩充一项的问题,x多了一维。也为x^



通过对Ew^化简,就是最小二乘法化简,得到

X是x的扩充

这里就求解最值,也是求凸函数,然后求w^




解得w^的值
3.3 对数几率回归
这个就是二分类问题的解决办法,逻辑回归。
引入sigmoid函数,对取值范围做限制,可以做到0,1判断,且求得值是概率。

引入极大似然估计求损失函数


将分段的概率公式合并起来。


这里得到公式。





 同样也可以得到公式。
同样也可以得到公式。
后面就要对β进行求解。也是求最值问题。
3.4线性判别分析
这里就是把数据投影到线上,然后看看分类效果。决定的核心值有两个,一个是方差越小越好,一个是中心点差值越大越好。





这里就是把方差和平均值放一起,组成一个函数。然后求出函数的最大值时即为最优解w(最优投影)。




求出来最优投影。
对于多维向量空间怎么办?



对每一个wi投影,接触一组
 ,最大的对应到wi即可。
,最大的对应到wi即可。3.5 多分类学习问题
对二分类的升级

最简单的OvO OvR

OvO OvR差不多。



并不是说ECOC编码越长越好。

长度也是一个玄学问题。
3.6 类别不平衡问题
其实说了三个处理类别不平衡的办法。

欠采样就是扔掉,过采样就是增加,阈值移动就是用数据量比例对评估值进行调整。
 总结:欠采样可能会丢失重要信息。(做好分类)
总结:欠采样可能会丢失重要信息。(做好分类)过采样会导致过拟合。(避免重复)

再缩放公式(阈值移动)
到这里就学习结束啦!感谢自己的坚持,六天学习结束!
写给自己:本章公式推导复杂且用到大量公式,在后面学习中作为基础需要多复习多思考。把公式理解,化为向上攀登的基石。
-
相关阅读:
又一款机器学习模型解释神器:LIME
独立站SEO推广的正确打开方式
PWC光流估计网络
软件考试:计算机组成原理: 指令&数据
设计程序化交易系统会出现什么误区?
Consistency Models终结扩散模型
基于vue3 + ant-design 自定义SVG图标iconfont的解决方案;ant-design加载本地iconfont.js不显示图标问题
(附源码)计算机毕业设计SSM基于框架的人力资源管理系统
“合”而不同,持“智”以恒,幂律智能2022产品升级发布会全程回顾!
css问题
- 原文地址:https://blog.csdn.net/QAQterrible/article/details/126473769