-
Linux三剑客
Liunx三剑客:
grep:文本过滤工具,( 模式:pattern)工具
sed:stream editor,流编辑器;文本编辑工具
awk: Linux Linux gawk的文本报告生成器(格式化文本),Linux上是gawk正则表达式
Linux三剑客主要分两类:
1.基本正则表达式(BRE basic regular expression)
BRE对应元字符有 ^$.[]*
2.扩展正则表达式(ERE extended regular expression)
ERE在BRE基础上,增加上 (){}?+| 等字符基本正则表达式BRE集合
- 匹配字符
- 匹配次数
- 位置锚定
符号 作用 ^ 尖角号,用于模式的最左侧,如"^ab"匹配以ab单词开头的行 $ 美元符,用于模式的最右侧,如"ab$",表示以ab单词结尾的行 ^$ 组合符,表示空行 . 匹配任意一个且只有一个字符,不能匹配空行 \ 转义字符,让特殊含义的字符,现出原形,还原本意,例如.代表小数点 * 匹配前一个字符(连续出现)0次或1次以上,重复0次代表空,即匹配所有内容 .* 组合符,匹配任意长度的任意字符 [abc] 匹配[]集合内的任意一个字符,a或b或c,可以写[a-c] [^abc] 匹配除了后面的任意字符,a或b或c,表示对[abc]的取反 匹配完整的内容 <或> 定位单词的左侧,和右侧,如可以找出"da chao ge",却找不出"dachaoge" 扩展正则表达式BRE集合
扩展正则必须用grep -E才能生效
符号 作用 + 匹配前一个字符1次或多次,前面字符至少出现1次 [: /]+ 匹配括号内的":“或者”/"字符一次或者多次 ? 匹配前一个字符0次或者1次,前面字符可有可无 竖线 表示或者,同时过滤多个字符串 () 分组过滤,被括起来的内容表示一个整体 a{n,m} 匹配前一个字符最少n次,最多m次 a{n,} 匹配前一个字符最少n次 a{n} 匹配前一个字符正好n次 a{,m} 匹配前一个字符最多m次 Tips:
grep命令需要使用参数 -E即可支持正则表达式
egrep不推荐使用,使用grep -E替代
grep不加参数,得在特殊字符前面""反斜杠,识别为正则三剑客之grep
全拼:Global search REgular expression and Print out the line
作用:文本搜索工具,根据用户指定的”模式(过滤条件)“对目标文本逐行进行匹配检查,打印匹配到的行
模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
语法:
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
-i:ignorecase,忽略字符的大小写
-o:仅显示匹配到的字符串本身;
-v:–invert-match:显示不能被模式匹配的行;
-E:支持使用扩展的正则表达式元字符;
-q,–quiet,–silent:静默模式,即不输出任何信息;
grep命令是Linux系统中最重要的命令之一,功能是从文本文件或管道数据流中筛选匹配的行和数据,如果再配合正则表达式,功能十分强大,是Linux运维人员必备的命令
grep命令里的匹配模式就是你想要找的东西,可以是普通的文字符号,也可以是正则表达式参数选项 解释说明 -v 排除匹配结果 -n 显示匹配行与行号 -i 不区分大小写 -c 只统计匹配的行数 -E 使用egrep命令 -color=auto 为grep过滤结果添加颜色 -w 只匹配过滤的单词 -o 只输出匹配的内容 正则表达式grep实践
创建test.txt文件,内容如下
hello linux. HELLO grep. food foood flad- 1
- 2
- 3
- 4
- 5
- 6
grep “food” test.txt -n #匹配有food的行,并打印行号

grep “food” test.txt -n -v #匹配没有food的行,并打印行号

grep “hello” test.txt -i #匹配hello的行,不区分大小写

grep -E “hello|food” test.txt #匹配hello或food的行

grep -E “hello|food” test.txt -c #统计匹配到的行数

grep -E “hello|food” test.txt -o #-o是输出匹配的内容

grep -E “hello” test.txt -w #-w单词匹配

grep -n ‘^$’ test.txt #匹配空行

grep -Ev “^#|^$” test.txt #过滤掉空行和以#号开头的行(测试过程中可以再文本中加一行#开头的行)

grep -n -i ‘^hello’ test.txt #匹配以hello开头的行

grep -n -i ‘d$’ test.txt #匹配以d结尾的行

Tip:
注意在Linux平台下,所有文件的结尾都有一个$符
可以cat -A 查看文件
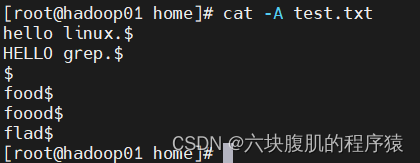
grep -n ‘.$’ test.txt #匹配以小数点为结尾的行,注意如果小数点不加转义符,不加就会匹配任意一个且只有一个字符,除空行

grep -n ‘h*’ test.txt #*是找出前一个字符0次或者多次,找出文中出现”h“的0次或多次。如果是.*组合符,就代表匹配所有内容

grep -n ‘.*o’ test.txt #匹配以任意字符开始,最后一个o字母结束,这种属于贪婪匹配,贪婪匹配可以百度了解下。

- [a-z]匹配所有小写单个字母
- [A-Z]匹配所有单个大写字母
- [a-zA-Z]匹配所有单个大小写字母
- [0-9]匹配所有单个数字
- [a-zA-Z0-9]匹配所有数字和字母
grep ‘[abcd]’ test.txt #匹配包含abcd字母的行
grep ‘[^abcd]’ test.txt #匹配不包含abcd字母的行

扩展正则表达式实践
此处使用grep -E进行实践扩展正则,而egrep官网已经弃用
创建test2.txt文件,内容如下gd god good goood gooood glad I love grep. lover He love sed. lover She dislike awk- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
grep -E ‘go?d’ test2.txt #?是匹配前一个字符0次或1次

grep -E ‘g(oo|la)d’ test2.txt #()小括号是将一个或者捆绑在一起,当作一个整体进行处理;

- 小括号功能之一是分组过滤被括号起来的内容,括号内的内容表示一个整体
- 括号()内的内容可以被后面的"\n"正则引用,n为数字,表示引用第几个括号的内容
- \1:表示从左侧起,第一个括号中的模式所匹配到的字符
- \2:表示从左侧起,第二个括号中的模式所匹配到的字符
grep -E ‘(l…e).*\1’ test2.txt


{n,m}匹配次数,重复前一个字符各种次数
grep -E “o{1,3}” test2.txt #匹配重复前一个字符o的1到3次数的行
grep -E “o{2,3}” test2.txt #匹配重复前一个字符o的2到3次数的行
grep -E “o{2,}” test2.txt #匹配重复前一个字符o的2次数以上的行
grep -E “o{,3}” test2.txt #匹配重复前一个字符o的3次数以下的行

三剑客之sed
注意sed和awk使用单引号,双引号有特殊解释
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具。
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询的功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)。

语法:
sed [选项] [sed内置命令字符] [输入文件]参数选项 解释 -n 取消默认sed的输出,常与sed内置命令p一起用 -i 直接将修改结果写入文件,不用-i,sed修改的是内存数据 -e 多次编辑,不需要管道符了 -r 支持正则扩展 sed的内置命令字符用于对文件进行不同的操作功能,如对文件增删改查
sed常用内置命令字符:sed的内置命令字符 解释 a append,对文本追加,在指定行后面添加一行/多行文本 d Delete,删除匹配行 i insert,表示插入文本,在指定行前添加一行/多行文本 p Print,打印匹配行的内容,通常p与-n一起用 s/正则/替换内容/g 匹配正则内容,然后替换内容(支持正则),结尾g代表全局匹配 sed匹配范围
范围 解释 空地址 全文处理 单地址 指定文件某一行 /pattern/ 被模式匹配到的每一行 范围区间 10,20十到二十行,10,+5第10行向下5行,/pattern2/ ,/pattern2/ 步长 1~2,表示1、3、5、7、9行,2~2 两个步长,表示2、4、6、8、10、偶数行 sed案例
准备测试数据
test3.txtMy name is sg. I learn sed. I like play computer game. My qq is 10000. I love you.- 1
- 2
- 3
- 4
- 5
sed -n ‘2,3p’ test3.txt #输出文件第2,3行的内容
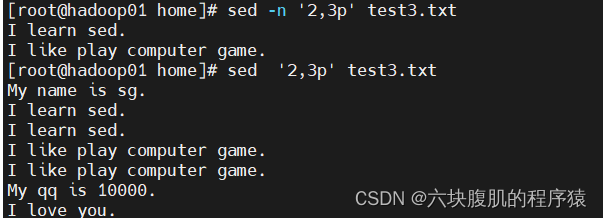
sed -n ‘/sed/p’ test3.txt #sed可以实现grep的过滤效果,必须把要过滤的内容放在双斜杠中

sed ‘/game/d’ test3.txt #删除含有game的行,只是将删除game行打印出来,并没有实际删除,如果需要删除文本内容,需要加入参数-i。
sed ‘3,$d’ test3.txt #删除第三行到结尾

sed ‘s/My/His/g’ test3.txt #将My全部替换为His

sed -e ‘s/My/His/g’ -e ‘s/10000/88888/g’ test3.txt #将My全部替换为His,将10000全部替换为88888,-e参数:多次编辑,不需要管道符

sed -i ‘2a I am useing sed command’ test3.txt #在文件第二行追加 I am useing sed command内容(a字符功能)并写入到文件(i字符功能)

sed -i ‘3a i like linux very much.\nand you?’ test3.txt #添加多行信息,用换行符”\n“

sed “a ----------” test3.txt #在每一行插入新内容

sed ‘2i i am 18’ test3.txt #在第二行前面插入新内容

sed配合正则表达式企业案例
取出linux的IP地址
ifconfig echo 0|sed -ne ‘2s/^.inet//g’ -e '2s/net.$//gp’

解释
-n:取消默认输出
s/正则/替换内容/g : 匹配正则内容,然后替换内容(支持正则),结尾g代表全局匹配
2s:处理第二行内容
^.*inet:匹配inet前所有的内容
net.*$:匹配net到结尾的内容
gp:全局替换且打印替换结果三剑客之awk
awk是一个强大的Linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表的样式
awk早期在Unix上实现,我们用的awk是gawk,是GUNawk的意思

awk更是一门编程语言,支持条件判断、数组、循环等功能
再谈三剑客:- grep,更擅长单纯的查找或匹配文本内容
- sed,更适合编辑、处理匹配到的文本内容
- awk,更适合格式化文本内容,对文本进行复杂处理
语法:

Action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作是print和printf创建文件test4.txt
hadoop01 hadoop02 hadoop03 hadoop04 hadoop05 hadoop11 hadoop12 hadoop13 hadoop14 hadoop15 hadoop21 hadoop22 hadoop23 hadoop24 hadoop25 hadoop31 hadoop32 hadoop33 hadoop34 hadoop35 hadoop41 hadoop42 hadoop43 hadoop44 hadoop45- 1
- 2
- 3
- 4
- 5
小试牛刀:
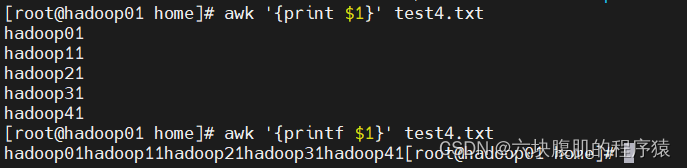
cat test4.txt |awk ‘{print $2}’

我们执行的命令是awk ‘{print $2}’ ,,没有使用参数和模式,$2表示输出文本的第二列信息
awk默认以空格为分隔符,且多个空格也识别为一个空格,作为分隔符
awk是按行处理文件,一行处理完毕,处理下一行,根据用户指定的分隔符去工作,没有指定则默认空格
指定了分隔符后,awk把每一行切割后的数据对应到内置变量

awk的内置变量
内置变量 解释 $n 指定分隔符后,当前记录的第n个字段 $0 完整的输入记录 FS 字段分割符,模式是空格 NF(Number of fields) 分割后,当前行一共有多少个字段 NR(Number of records) 当前记录数,行数 更多内置变量可以man手册查看 man awk 需求:一次性输出多列:
cat test4.txt |awk ‘{print $2,$3}’
awk ‘{print $2,$3}’ test4.txt

需求:自定义输出内容:
awk,必须外层单引号,内层双引号
内置变量$1,$2都不得添加双引号,否则会识别为文本,尽量别加引号
awk ‘{print “第一列”,$1,“第二列”,$2,“第三列”,$3}’ test4.txt

需求:输出整行信息
awk ‘{print }’ test4.txt #两种写法都可以
awk ‘{print $0}’ test4.txt

awk ‘{print NR,$0}’ test4.txt #给每一行加个行号,NR等于行号,$0表示一整行内容

awk参数
参数 解释 -F 指定分割字段符 -v 定义或修改一个awk内置的变量 -f 从脚本文件中读取awk命令 需求:显示文件第三行
awk 'NR3’ test4.txt
#NR在awk中表示行号,NR3表示行号是3的那一行
#注意一个等于号,是修改变量值的意思,两个等于号是关系运算符,是“等于”的意思
awk ‘NR2,NR4’ test4.txt #显示2-4行

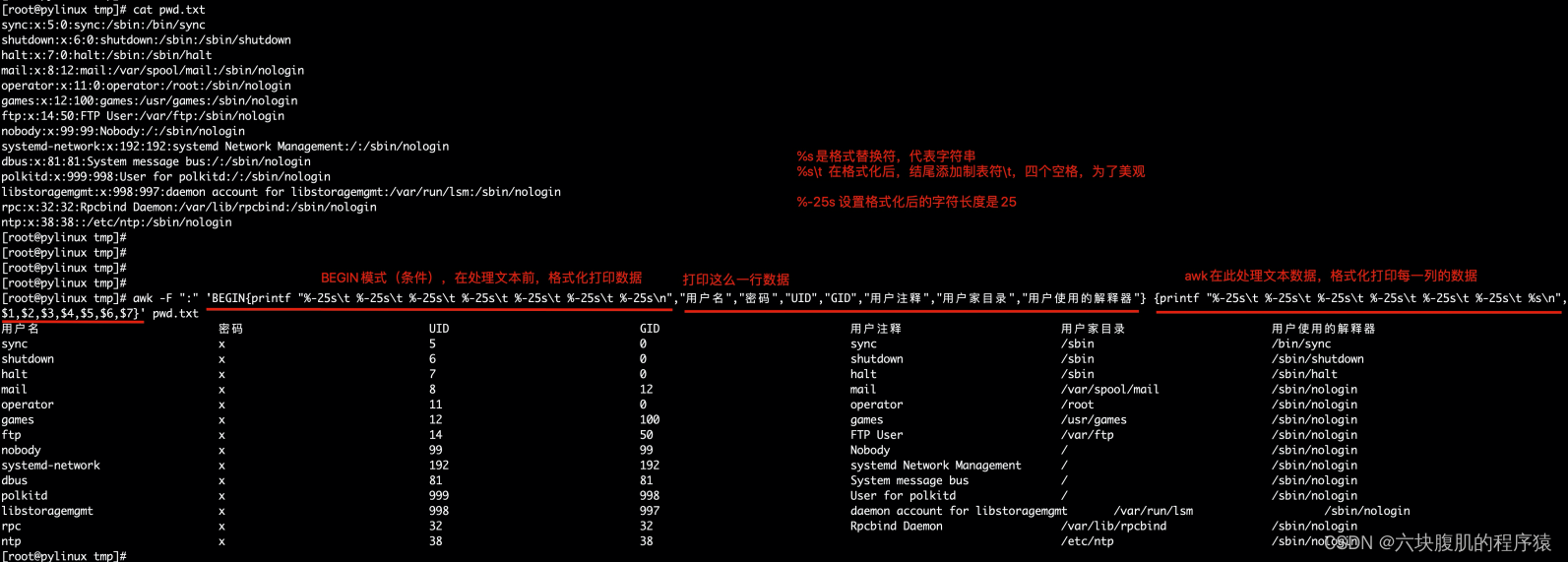
以":"分隔。显示/etc/passwd文件的第一列,倒数第二和最后一列
awk -F ‘:’ ‘{print $1,$(NF-1),$NF}’ pwd.txt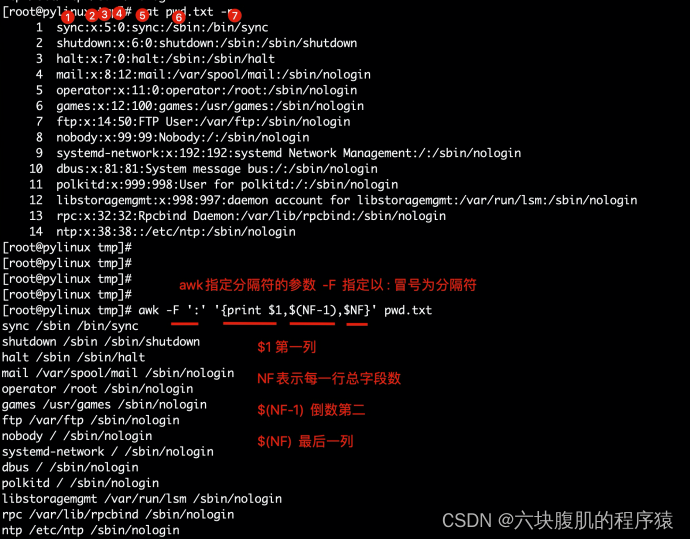
awk的分隔符有两种:输入输出分隔符
- 输入分隔符:awk默认是空格,空白字符,英文是field separator,变量名是FS
- 输出分隔符:output field separator,简称OFS
创建文件test5.txt
hadoop01#hadoop02#hadoop03#hadoop04#hadoop05 hadoop11#hadoop12#hadoop13#hadoop14#hadoop15 hadoop21#hadoop22#hadoop23#hadoop24#hadoop25 hadoop31#hadoop32#hadoop33#hadoop34#hadoop35 hadoop41#hadoop42#hadoop43#hadoop44#hadoop45- 1
- 2
- 3
- 4
- 5
FS输入分隔符
awk逐行处理文本的时候,以输入分隔符为准,把文本切成多个片段,默认符号是空格
当我们处理特殊文件,没有空格的时候,可以自由指定分隔符特点
awk -F ‘#’ ‘{print $1}’ test5.txt

除了使用-F选项,还可以使用变量的形式,制定分隔符,使用-v选项搭配,修改FS变量

OFS输出分隔符
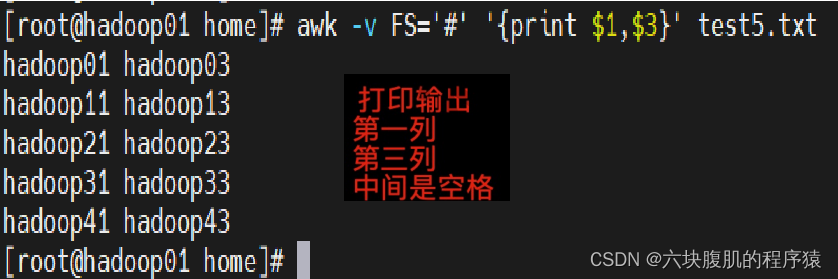
awk执行完命令,默认用空格隔开每一列,这个空格就是awk默认输出符,例如
awk -v FS=‘#’ ‘{print $1,$3}’ test5.txt
通过OFS设置输出分隔符,记住修改变量必须搭配选项-v
awk -v FS=‘#’ -v OFS=‘—’ ‘{print $1,$3}’ test5.txt

输出分隔符与逗号
awd是否存在输出分隔符,特点在于’{print $1,$3}'是否添加逗号,不添加逗号就不输出分隔符

awk变量
参数 解释 -F 指定分割字段符 -v 定义或修改一个awk内置的变量 -f 从脚本文件中读取awk命令 对awk而言,变量分为
- 内置变量
- 自定义变量
内置变量 解释 FS 输入字符分割符,默认为空白符 OFS 输出字段分隔符,默认为空白字符 RS 输入记录分隔符(输入换行符),指定输入时的换行符 ORS 输出记录分隔符(输出换行符),输出时用指定符号代替换行符 NF NF:number of Filed,当前行的字段的个数(即当前行被分割成了几列),字段数量 NR NR:行号,当前处理的文本行的行号。 FNR FNR:个文件分别技术的行号 FILENAME FILENAME:当前文件名 ARGC ARGC:命令行参数的个数 ARGV ARGV:数组,保存的是命令行所给定的各参数 内置变量
NR,NF、FNR
- awk的内置变量NR、NF是不用添加$符号的
- 而$0 $1 $2 $3…是需要添加$符号的
输出每行行号,以及字段总个数
awk ‘{print NR,NF}’ test4.txt

输出每行行号,以及指定列
awk ‘{print NR,$1,$5}’ test4.txt

处理多个文件显示行号
awk ‘{print FNR,$0}’ test4.txt test6.txt

内置变量RS
RS变量作用是输入分隔符,默认是回车符,也就是回车(Enter键)换行符
我们也可以自定义空格作为行分隔符,每遇见一个空格,就换行处理
awk -v RS=’ ’ ‘{print NR,$0}’ test4.txt

内置变量ORS
ORS输出分隔符的意思,awk默认认为,每一行结束了,就得添加回车换行符
ORS变量可以更改输出符
awk -v ORS=‘@@@’ ‘{print NR,$0}’ test4.txt

内置变量FILENAME
显示awk正在处理的名字
awk ‘{print FILENAME NR,$0}’ test4.txt

变量ARGC、ARGV
ARGV表示的是一个数组,数组中保存的的是命令行所给的参数
awk ‘BEGIN{print “awk的内置变量”,ARGV[0]}’ test4.txt
awk ‘BEGIN{print “awk的内置变量”,ARGV[0],ARGV[1]}’ test4.txt
awk ‘BEGIN{print “awk的内置变量”,ARGV[0],ARGV[1],ARGB[2]}’ test4.txt

自定义变量
顾名思义,是我们自定义变量
- 方法一,-v varName=value
- 方法二,在程序中直接定义
awk -v varName=“你好帅!” ‘BEGIN{print varName}’
awk -v varName=“你好帅!” ‘BEGIN{print varName}’ test4.txt
awk -v varName=“你好帅!” ‘BEGIN{print varName}{print $0}’ test4.txt

awk ‘BEGIN{varName1=“你好帅!”;varName2=“你也是!”;print varName1,varName2}’

方法三:间接引用shell变量

awk格式化
前面我们接触到awk的输出功能,是{print}的功能,只能对文本简单的输出,并不能美化或者修改格式
printf格式化输出
如果你学过C语言或是go语言,一定见识过printf()函数,能够对文本格式化输出
printf和print的区别
format使用:
要点:
1 、其中print命令的最大不同是, printf 需要指定format;
2 、format用于指定后面的每个 item的输出格式;
3 、printf 语句不会自动打印换行符;\n
format格式的指示符都以 %开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学技术法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串
%u: 无符号整数;
%%: %显示%自身printf修饰符:
-: 左对齐;默认右对齐,
+:显示数值符号; printf “%+d”- printf动作默认不会添加换行符
- print默认添加空格换行符
给printf添加格式
格式化字符串%s代表字符串的意思

对多个变量进行格式化
当我们使用linux命令printf时,是这样的,一个%s格式替换符,可以对多个参数进行格式化
然而awk的格式替换符想要修改多个变量,必须传入多个
awk ‘BEGIN{printf “%d\n%d\n%d\n%d\n%d\n”,1,2,3,4,5}’

- printf对输出的文本不会换行,必须添加对应的格式替换符和 \n
- 使用printf动作, ‘{printf “%s\n”,$1}’,替换的格式和变量之间得有逗号,
- 使用printf动作,%s %d等格式化替换符必须和被格式化的数据一一对应
printf案例
awk ‘{printf “第一列:%s 第二列:%s 第三列:%s\n”,$1,$2,$3}’ test4.txt

- awk通过空格切割文档
- printf动作对数据格式化
awk -F “:” ‘BEGIN{printf “%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n”,“用户名”,“密码”,“UID”,“GID”,“用户注释”,“用户家目录”,“用户使用的解释器”} {printf “%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n”,$1,$2,$3,$4,$5,$6,$7}’ pwd.txt
awk模式pattern
再来回顾下awk的语法

awk是按行处理文本,刚才讲解了print动作,现在讲解特殊的pattern:BEGIN和END- BEGIN模式是处理文本之前需要执行的操作
- END模式是处理完所有行之后执行的操作
awk ‘BEGIN{print “开始处理文本!”}{print $1,$2}END{print “结束处理文本!”}’ test4.txt

awk模式pattern讲解
再来看一下awk的语法,模式也可以理解为是条件
awk [option] ‘pattern[action]’ file …
awk ‘NF==5 {print $1}’ test4.txt

awk的模式

awk ‘NR>3 {print $0}’ test4.txt
awk ‘$1==“hadoop11” {print $0}’ test4.txt

awk与正则表达式
正则表达式主要与awk的pattern模式(条件)结合使用
- 不指定模式,awk每一行都会执行对应的动作
- 指定了模式,只有被模式匹配到的、符合条件的行才会执行动作
找出/etc/passwd中以sync开头的行
1.用grep过滤

2.awk实现

awk使用正则语法
grep ‘正则表达式’ pwd.txt
awk ‘/正则表达式/动作’ /etc/passwd
awk命令使用正则表达式,必须把正则放入"//"双斜杠中,匹配到结果后执行动作{print $0},打印整行信息
grep可以过滤,那我们还用awk干啥?
awk强大的格式化文本
匹配/^n/开头的行,并格式化展示
awk -F “:” ‘BEGIN{printf “%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n”,“用户名”,“密码”,“UID”,“GID”,“用户注释”,“用户家目录”}/^n/ {printf “%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n”,$1,$2,$3,$4,$5,$6}’ /etc/passwd

awk命令执行流程
解读需求:从/etc/passwd文件中,寻找我们想要的信息,按照以下顺序执行
awk ‘BEGIN{ commands } pattern{ commands } END{ commands }’- 优先执行BEGIN{}模式中的语句
- 从/etc/passwd文件中读取第一行,然后执行pattern{commands}进行正则匹配/^n/寻找n开头的行,找到了执行{print}进行打印
- 当awk读取到文件数据流的结尾时,会执行END{commands}
找出/etc/passed文件中禁止登陆的用户(/sbin/nologin)
分别用grep和awk实现:
grep ‘/bashKaTeX parse error: Undefined control sequence: \/ at position 21: …c/passwd awk '/\̲/̲bash/{print $0}’ /etc/passwd

找出文件区间内容
1.找出halt用户到games用户之间的内容
正则模式
awk ‘/正则表达式/{动作}’ file.txt
行范围模式
awk ‘/正则1/,/正则2/{动作}’ file.txt
2.关系表达式模式
awk ‘NR>=4 && NR<=8 {print $0}’ /etc/passwd

awk企业实战nginx日志
nginx的日志文件access.log
192.168.100.175 - - [22/Aug/2022:20:18:59 +0800] "POST /mall_open_api.php?token=9f1063d6bf1ec1 HTTP/1.0" 300 1829 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.556" "0.556" "0.000" "0.556" 192.168.100.173 - - [22/Aug/2022:20:18:59 +0800] "POST /mall_open_api.php?token=a3a9c69 HTTP/1.0" 200 1829 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.446" "0.445" "0.000" "0.445" 192.168.100.171 - - [22/Aug/2022:20:19:03 +0800] "POST /mall_open_api.php?token=b9b0eadf7 HTTP/1.0" 200 731 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.153" "0.154" "0.000" "0.154" 192.168.100.173 - - [22/Aug/2022:20:19:14 +0800] "POST /mall_open_api.php?token=242b947c HTTP/1.0" 200 97 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.425" "0.425" "0.000" "0.425" 192.168.100.175 - - [22/Aug/2022:20:19:59 +0800] "POST /mall_open_api.php?token=9f1063d6bf1ec1 HTTP/1.0" 300 1829 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.556" "0.556" "0.000" "0.556" 192.168.100.176 - - [22/Aug/2022:20:20:59 +0800] "POST /mall_open_api.php?token=a3a9c69 HTTP/1.0" 200 1829 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.446" "0.445" "0.000" "0.445" 192.168.100.175 - - [22/Aug/2022:20:21:03 +0800] "POST /mall_open_api.php?token=b9b0eadf7 HTTP/1.0" 200 731 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.153" "0.154" "0.000" "0.154" 192.168.100.176 - - [22/Aug/2022:20:21:14 +0800] "POST /mall_open_api.php?token=242b947c HTTP/1.0" 200 97 "-" "Dart/2.8 (dart:io)" "-" "mall-api.carisok.com" "0.425" "0.425" "0.000" "0.425"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
统计日志的访问ip数量
awk ‘{print $1}’ access.log |sort -n|uniq|wc -l

查询访问最频繁的前3个ip
#uniq -c 去重显示次数
#sort -n 从大到小排序
awk ‘{print $1}’ access.log |sort -n|uniq -c|sort -nr|head -3

-
相关阅读:
Python入门教程
Chapter 3 New Optimizers for Deep Learning
2.1.6.15 漏洞利用-smb-RCE远程命令执行
关于集群和分布式部署
压缩和解压类指令
React - 01
PHP:json_encode和json_decode用法
架构道术-企业选择Dubbo作为分布式服务框架的10个理由
python打包和发布package
python 操作windows的Wlan
- 原文地址:https://blog.csdn.net/weixin_44468025/article/details/126400594