-
YOLO系列的Backbone改进历史
Backbone决定了模型的特征提取精度,backbone后面一般接的就是检测头Head。
YOLO v1只是把最后的特征分成了 7x7 个grid,到了YOLO v2就变成了13x13 个grid,再到YOLO v3 v4 v5就变成了多尺度的(strides=8,16,32),更加复杂了。那为什么一代比一代检测头更加复杂呢?
答案是:因为它们的提特征网络更加强大了,能够支撑起检测头做更加复杂的操作。换句话说,如果没有backbone方面的优化,你即使用这么复杂的检测头,可能性能还会更弱。所以引出了今天的话题:yolo系列中的backbone的改进历史。Yolov1
图一

可以看到首先是7x7的卷积核,后面是3x3的卷积核,中间穿插1x1的卷积来节约参数,最后2层是全连接层。
画图的规律是安装feature map的分辨率来,两个分辨率之间的卷积操作数目不同,但是在代码里面他们都会被放在一起进行运算。比如从28x28到14x14的操作,实际上是经过了四次gap层,举例对于vgg13来说:# vgg13 不加bn 的配置 cfg =[64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'] def make_layers(cfg, batch_norm=False): layers = [] in_channels = 3 s = 1 first_flag=True for v in cfg: s=1 if (v==64 and first_flag): s=2 #第一层的时候,stride是2,同时进行一次maxpooling,所以feature map从448到了112 first_flag=False if v == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: conv2d = nn.Conv2d(in_channels, v, kernel_size=3, stride=s, padding=1) layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v return nn.Sequential(*layers)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
VGG_Yolo 完整详细代码地址
YoloV2
图二
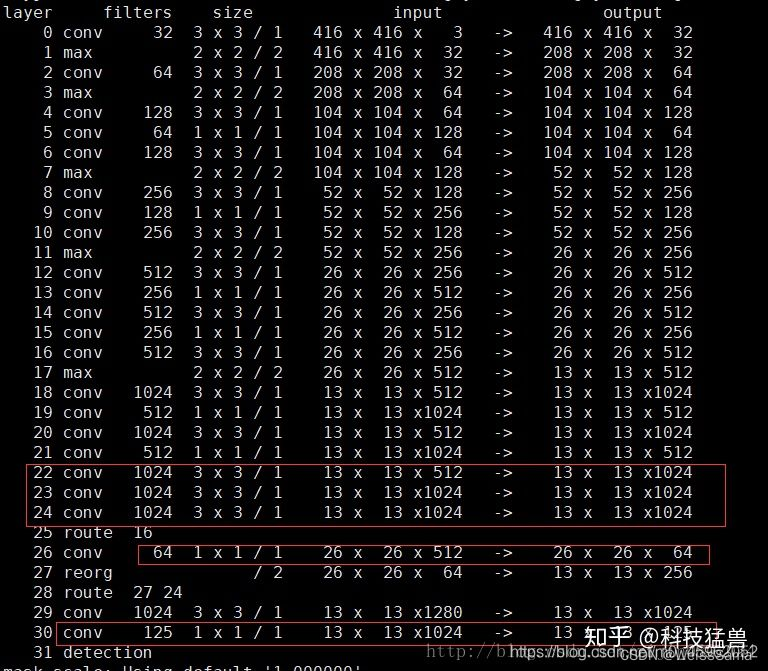
YoloV1 使用的backbone是GoogleNet,而YoloV2 使用的backbone是Darknet19,DarkNet系列结合了VGG和GoogleNet的特征,Darknet19有19个conv层,5个maxpooling层,也就是上面图二中的0 ~ 23层。23 ~ 25层开始是检测头Head,当然和检测头并列的也有一个global average pooling+softmax的分类层,检测层和分类层的loss会一起进行训练。
DarkNet相对于GoogleNet 有几个比较大的改进。
- 首先是Darknet比GoogleNet要先进,Darknet不使用7x7卷积核了,因为VGG论文指出,7x7卷积可以使用两个3x3卷积来代替【同样的,5x5卷积可以用两个3x3卷积替代】,带来的优点有两个,一是参数数目减少in_channels x 5 x 5 x out_channels > n_channels x 2 x 3 x 3 x out_channels ; 二是多次小卷积带来了多次激活函数的非线性操作。参考 知乎回答
- 用global average pooling【gap层】层替代了FC层。假如最后一个conv层输出是13x13x1000 ,那么经过gap层,就变成1x1x1000,进一步变成1x1000。取消FC层主要是为了让输入图片的大小可变,这样对于同一张图片,可以进行放大缩小作为输入,对于小目标检测有帮助。
在YoloV2的训练中,是先训练一个分类模型,再训练一个检测模型,具体的分类模型如下:
图三
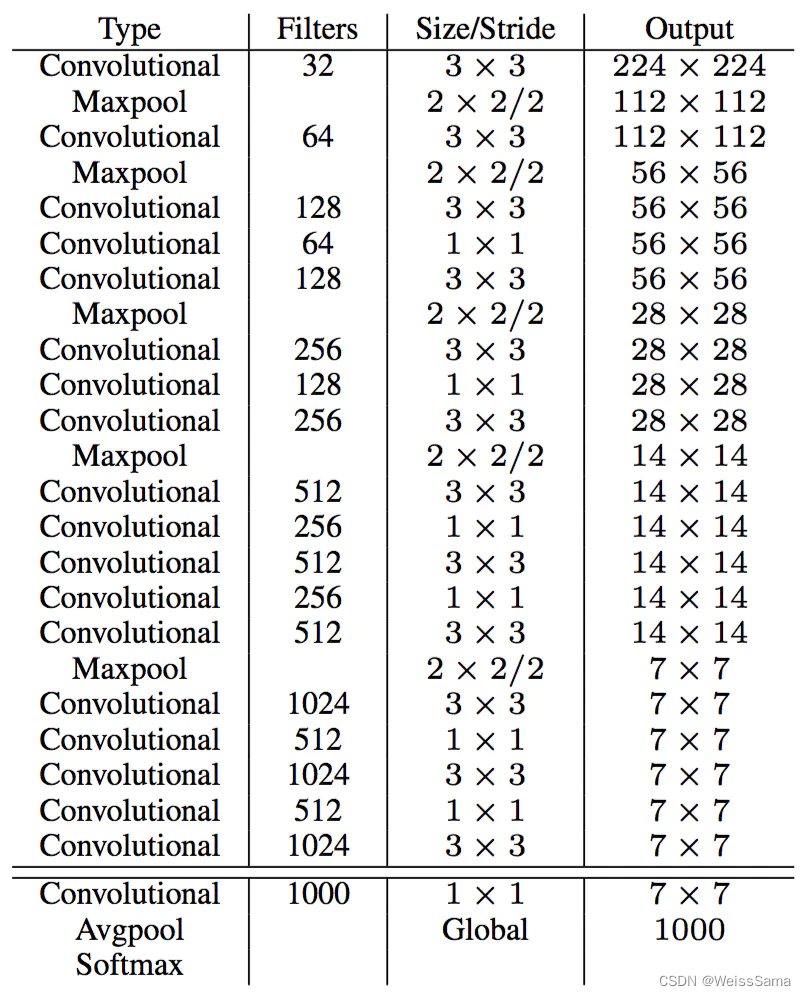
Train for Classification:
分类模型是在ImageNet数据集上训练得到的,先用224x224大小的输入图像进行训练,初始学习率也比较大,设为0.1 ,而接下来是finetune网络,输入图像大小是448x448,并且学习率变小为0.001。Train for Detection:
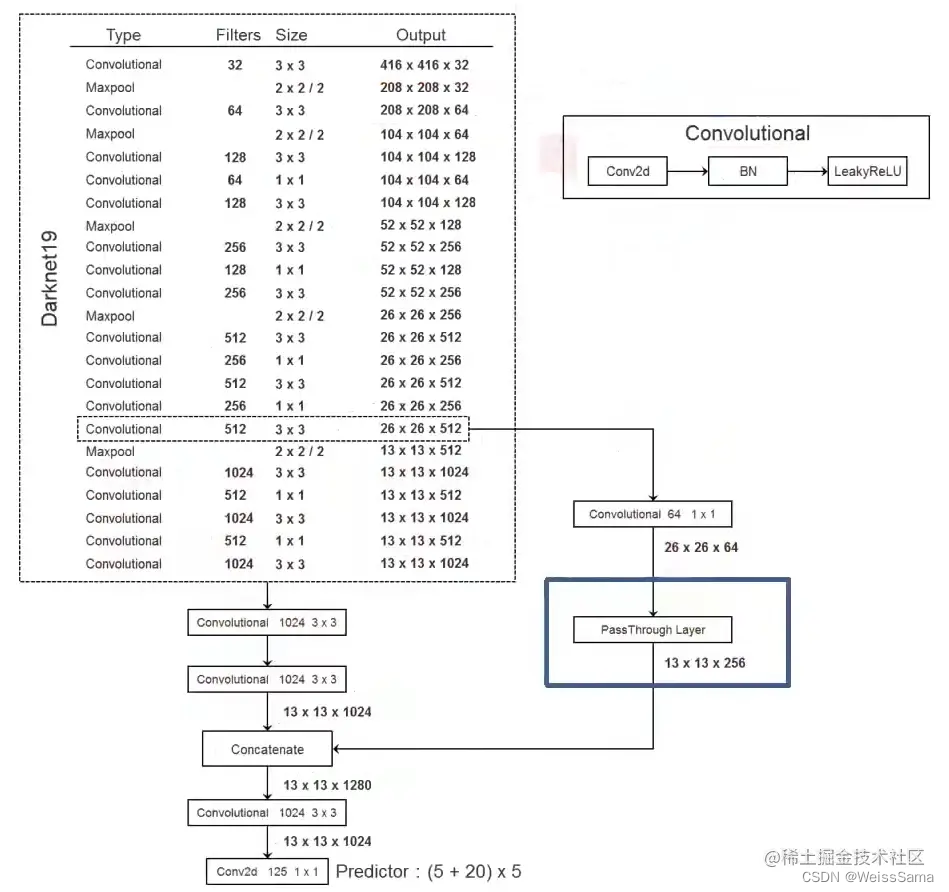
注意训练Classification用448x448的图像,而训练Detection用416x416图像。在ImageNet上训练好的分类模型,我们保存权重,将分类模型的最后一个conv层,也就是那个卷积核是1x1x1000的层去掉。并且去掉gap层和softmax层。然后在13x13x1024的feature后面添加3个 3x3x1024卷积,也就是图二中的22 23 24层。接下来有一个层融合的过程,如下图四所示 首先对大小为 26x26x512的feature map 进行1x1x64卷积 得到26x26x64的feature,接下来接passthrough层 ,也就是图二中的27层。
https://zhuanlan.zhihu.com/p/55896919 【这里需要介绍 20220915 mark 】
在图二和图四中,passthrough layer的过程看起来就是一个feature变小一半,然后channel从64变成256的过程,实际上的过程是:将26x26x64的feature 划分成4个小feature,它们的大小都是13x13x64,然后把这四个小feature串联起来得到13x13x256;整个passthrough layer本身是不学习参数的,直接用前面的层(图二中的16层) 的特征重排后拼接到后面的层,越在网络前面的层,感受野越小,有利于小目标的检测,这是passthrough的目的,层融合。
接下来再把图二中的第27层和第24层进行串联,得到13x13x(1024+256)=13x13x1280的feature ; 后面接一个3x3x1024卷积核,再接一个3x3x125的卷积核,得到最终结果3x3x125 ;
其中125的由来是nums_anchor * (5+num_classes)=5x(5+20)=125
图四
说到这里,再介绍一下YoloV2的anchors,这是和YoloV1 的一个很大的不同;
还记得V1是怎么预测坐标点的吗?参考
https://zhuanlan.zhihu.com/p/186014243 -
相关阅读:
支持向量机(SVM)预测模型及其Python和MATLAB实现
【牛客算法-二分查找】刷题和面试兼顾还得看你啊
网络工程师练习题
真是绝了,做了这么多年程序员第一次搞懂微服务架构的数据一致性
vscode前端常用插件
web练习
C#的数据集:DataSet对象
C++之红黑树
Java基础32 this关键字
盘点≠走过场,哪些功能可以进行高效库存盘点?
- 原文地址:https://blog.csdn.net/Bismarckczy/article/details/126461826
