-
通过一款插件动态观察ES分片如何分布
欢迎大家关注公众号「JAVA前线」查看更多精彩分享文章,主要包括源码分析、实际应用、架构思维、职场分享、产品思考等等,同时欢迎大家加我微信「java_front」一起交流学习
1 文章概述
1.1 ES基本概念
(1) 索引(Index)
类比关系型数据库概念:数据库(database)
(2) 类型(Type)
类比关系型数据库概念:表(table),类型这个概念已经逐步被官方弱化,7.X不再支持自定义类型,默认类型是_doc,在类型弱化之后也可以把索引(Index)类比为表
(3) 文档(Document)
类比关系型数据库概念:行(row)
(4) 分片(Shard)
类比于关系型数据库分库后数据分片,当一个索引数据量过大时,可以将一个索引拆分为多个数据集合,每一个数据集合只有一部分数据,这种数据集合称为分片
(5) 副本(Replica)
主分片可以有一个或多个副分片,副本有两个作用:第一可以承担读流量,提高系统吞吐量。第二可以提高可用性,如果主分片出现问题,副分片可以晋升为主分片
(6) 集群(Cluster)
一个节点资源是有限的,当数据量和流量达到超过单节点负载时,可以将多个节点组成一个集群,共同承担流量
1.2 两个问题
根据上述概念提出两个问题:
- 一个集群有三个节点,订单索引有三个分片,每个分片有两个副本,这些分片如何分布在集群
- 当请求访问ES集群,怎么确定数据在哪一个分片
2 环境搭建
为了回答上述两个问题,我们首先搭建实验环境,本次实验使用windows环境,ES使用7.11版本。
2.1 集群搭建
ES官网下载64位版本并分别解压到三个文件夹:
- es-node-1
- es-node-2
- es-node-3
编辑文件es-node1/config/elasticsearch.yml
# 集群信息 cluster.name: java-front-cluster # 节点信息 node.name: es-node-1 node.master: true node.data: true network.host: localhost http.port: 8001 # 通信端口 transport.tcp.port: 9001 discovery.zen.ping.unicast.hosts: ["localhost:9001", "localhost:9002", "localhost:9003"] # 跨域配置 http.cors.enabled: true http.cors.allow-origin: "*"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
编辑文件es-node2/config/elasticsearch.yml
# 集群信息 cluster.name: java-front-cluster # 节点信息 node.name: es-node-2 node.master: true node.data: true network.host: localhost http.port: 8002 # 通信端口 transport.tcp.port: 9002 discovery.zen.ping.unicast.hosts: ["localhost:9001", "localhost:9002", "localhost:9003"] # 跨域配置 http.cors.enabled: true http.cors.allow-origin: "*"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
编辑文件es-node3/config/elasticsearch.yml
# 集群信息 cluster.name: java-front-cluster # 节点信息 node.name: es-node-3 node.master: true node.data: true network.host: localhost http.port: 8003 # 通信端口 transport.tcp.port: 9003 discovery.zen.ping.unicast.hosts: ["localhost:9001", "localhost:9002", "localhost:9003"] # 跨域配置 http.cors.enabled: true http.cors.allow-origin: "*"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2.2 启动集群
连续双击下列脚本启动三个节点:
es-node-1/bin/elasticsearch.bat es-node-2/bin/elasticsearch.bat es-node-3/bin/elasticsearch.bat- 1
- 2
- 3
如果只启动一个节点会出现错误:master节点无法发现或者选举,选举需要至少两个节点
[es-node-1] master not discovered or elected yet, an election requires at least 2 nodes- 1
此时依次启动节点二和三就可以解决这个问题。
2.3 查看集群
节点一选举为主节点
GET http://localhost:8001/_cat/nodes 127.0.0.1 34 84 30 dilmrt * es-node-1 127.0.0.1 25 84 31 dilmrt - es-node-2 127.0.0.1 26 84 19 dilmrt - es-node-3- 1
- 2
- 3
- 4
- 5
2.4 创建索引
创建订单索引,包含三个分片和两个副本
PUT http://localhost:8001/order { "settings": { "number_of_shards": 3, "number_of_replicas": 2 } } // 响应结果 { "acknowledged": true, "shards_acknowledged": true, "index": "order" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3 解析问题一
一个集群有三个节点,订单索引有三个分片,每个分片有两个副本,这些分片如何分布在集群?
3.1 安装运行插件
通过扩展程序商店安装Chrome浏览器插件ElasticSearch Head,运行插件并输入节点一地址:

3.2 详细分析
3.2.1 主节点是哪一个
es-node-1
3.2.2 主分片如何分配
order索引有三个主分片,分别对应加粗0、1、2三个分片
P0、P1在节点一,P2在节点二
3.2.3 副分片如何分配
P0有两个副分片R0,分配在节点二和节点三
P1有两个副分片R1,分配在节点二和节点三
P2有两个副分片R1,分配在节点一和节点三
3.2.4 集群健康值
集群健康值有三种颜色:绿色、黄色、红色
- 绿色:所有主分片和副分片都运行正常
- 黄色:所有主分片运行正常,有副分片运行异常
- 红色:有主分片运行异常
3.2.5 关闭一个节点
关闭节点es-node-3并通过插件查看:

集群信息发生变化:
- 集群健康值变成黄色,表示所有主分片运行正常,有副分片运行异常
- 节点三上R0、R1、R2不能正常工作
3.2.6 关闭两个节点
再关闭节点es-node-2并通过插件查看:
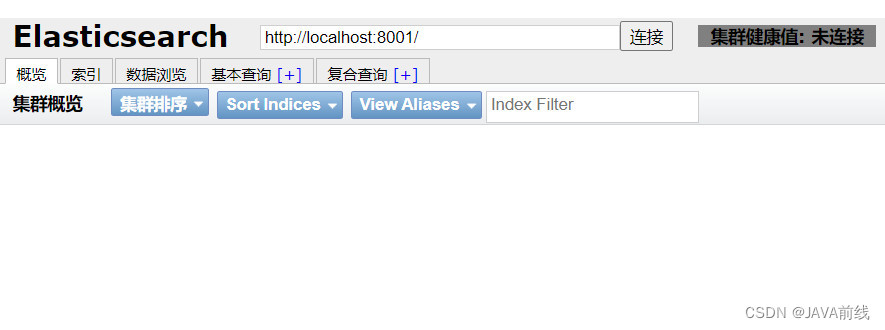
集群信息发生变化:
- 集群健康值变成未连接
- 集群处于不可用状态,无法查询到集群信息
- 查看es-node-1控制面板发现报错信息:[es-node-1] master not discovered or elected yet, an election requires at least 2 nodes
- 报错表示当前配置下master无法发现或者选举,选举至少需要两个节点
4 解析问题二
当请求访问ES集群,怎么确定数据在哪一个分片?
4.1 路由规则
order索引有三个分片,现在新增orderId=100订单数据,这条数据应该保存在哪个分片?
路由规则公式:
shard_number = hash(routing) % number_of_primary_shards- 1
本实例路由公式:
shard_num = hash(100) % 3- 1
路由公式参数说明:
- shard_num:最终选择分片序号
- routing:路由ID,不指定则为文档ID
- number_of_primary_shards:主分片数量
4.2 协调节点
本实例集群中有三个节点,当客户端发送请求至集群,应该发送请求到哪一个节点呢?
客户端也不知道应该发送给哪一个节点,所以会发送至任意一个节点,由这个节点决定处理还是转发,这个节点就是协调节点。
4.3 处理写请求
本章节沿用第二章节集群信息:

orderId=100写请求流程:
- 客户端发送写请求到任意节点,假设为node-3
- node-3作为协调节点,根据路由公式发现应该写入1号主分片
- node-3将写请求转发给node-1
- node-1将orderId=100写入1号主分片成功
- 主分片将数据同步给node-2、node-3节点1号副分片
- 发送响应给客户端
4.4 处理读请求
orderId=100读请求流程:
- 客户端发送写请求到任意节点,假设为node-3
- node-3作为协调节点,根据路由公式发现应该读1号分片
- node-3查询出1号所有主副分片以及所在节点
- 根据负载均衡策略决定路由哪一个分片,假设为node-2的1号副分片
- 转发请求到node-2读取1号副分片
- 发送响应给客户端
4.5 不指定routing怎么路由
这个问题可以类比关系型数据库分库分表,读取是不指定shardingKey会怎么样?答案是会扫描全库全表。ES搜索过程可以分为Query和Fetch两个阶段:
(1) Query
- 查询请求发送到每个分片(主分片或者副分片均可)
- 每个分片在执行查询,结果存放在大小为from + size的优先队列
- 每个分片返回优先队列中所有文档的ID和排序值给协调节点
- 协调节点合并所有文档到其优先队列,整体进行排序
(2) Fetch
- 协调节点决定哪些文档需要取回,向对应分片查询文档信息
- 返回结果给客户端
5 文章总结
第一本文介绍了ES基本概念并提出了两个问题,第二本文为了回答这两个问题搭建了ES集群,第三本文通过六个维度回答了第一个问题,第四本文通过五个维度回答了第二个问题,希望本文对大家有所帮助。
6 延伸阅读
欢迎大家关注公众号「JAVA前线」查看更多精彩分享文章,主要包括源码分析、实际应用、架构思维、职场分享、产品思考等等,同时欢迎大家加我微信「java_front」一起交流学习
-
相关阅读:
C语言黑魔法第三弹——动态内存管理
Windows下配置MySQL源码调试环境
Rocky Linux 运维工具 mv
职场数据汇总,数据汇报,动态大屏可视化制作与数据分析
【iMessage相册推位置推软件】实现 Greetbale 的类型Compiler Error编译器将返回错误Compiler Error
微信小程序开发详细步骤是什么?
【深度学习】 Python 和 NumPy 系列教程(廿六):Matplotlib详解:3、多子图和布局:subplots()函数
【k8s】(一) 使用kubeadm快速部署一个K8s集群
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 概述
13、用JS实现快速排序
- 原文地址:https://blog.csdn.net/woshixuye/article/details/126459014
