-
神经网络(四)前馈神经网络
一、神经元
生物神经元的细胞状态仅有两种:兴奋和抑制
1.人工神经元

 :接收的信号
:接收的信号 w d b " role="presentation">:偏置阈值a " role="presentation">:人工神经元的状态人工神经元可以被视为一个线性模型
2.激活函数的性质
①连续且可导(允许少数点不可导)
②尽可能简单(提升计算效率)
③值域要在一个合适的区间内
④单调递增(整体上升,局部可能下降)
3.常用的激活函数
①S型函数
σ ( x ) = 1 1 + e x p ( − x ) t a n h ( x ) = e x p ( x ) − e x p ( − x ) e x p ( x ) + e x p ( − x ) = 2 σ ( 2 x ) − 1 " role="presentation">
性质:①饱和函数 ②Tanh函数是零中心化的,logistic函数的输出恒大于0
!!! 非0中心化输出会使得下一层神经元出现偏置(使其梯度下降收敛速度减缓)
②斜坡函数
R e L U ( x ) = m a x ( 0 , x ) " role="presentation">
性质:①高效 ②生物学合理性(单侧抑制、宽兴奋边界) ③一定程度上缓解梯度消失问题
死亡ReLU问题:x小于0时,输出为0
解决:①规划-避免参数过于集中
②
L e a k y R e L U ( x ) = m a x ( 0 , x ) + γ m i n ( 0 , x ) " role="presentation"> :使其左端不为0(具有极小的梯度)近似非零中心化的非线性函数
E L U ( x ) = x " role="presentation"> 如果x>0= γ ( e x p ( x ) − 1 ) " role="presentation"> 如果x<=0ReLu函数的平滑版本
S o f t p l u s ( x ) = l o g ( 1 + e x p ( x ) ) " role="presentation">③复合激活函数
1.Swish函数:一种自门控激活函数
S w i s h ( x ) = x σ ( β x ) " role="presentation">σ " role="presentation">即为logsitic函数,近似电路的门电路(软门控,类似于模拟电路)可以通过改变
β " role="presentation">使其在x=y的上半部取值
2.高斯误差线性单元
和Swish函数比较类似
G E L U ( x ) = x P ( X ≤ x ) " role="presentation">其中
P ( X ≤ x ) " role="presentation">是高斯分布N ( μ , σ 2 ) " role="presentation">的累积分布函数μ , σ " role="presentation">是超参数,一般μ = 0 , σ = 1 " role="presentation">即可可以使用Tanh或Logistic函数来近似


4.神经元函数小结

二、神经网络
神经网络由大量神经元及其有向连接构成,需要考虑以下三个方面:
①神经元的激活规则:神经元输入和输出的关系,一般为非线性
②网络的拓扑结构
③学习算法
常见的神经网络结构如下:
①前馈网络:单向流动
②记忆网络:有内部循环
③图网络

神经网络是一种主要的连接主义模型,其具有三个特点:
①信息表示是分布式的
②记忆和知识是存储在单元之间的连接上
③通过逐渐改变单元之间的连接强度来学习新的知识
三、前馈神经网络
之所有叫前馈神经网络,是因为其调优方式是从计算最后一层的导数反过来对激活函数进行调优(即与信息流动方向相反)

特点: ①各神经元属于不同的层,层内无连接
②相邻两层之间的神经元全部两两连接
③无反馈,信号单向传递,可以形成有向无环图
网络的层数不计算输入层
1.前馈神经网络的描述
记号 含义 L 层数 M l 第 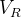 层的神经元个数
层的神经元个数
第 层的激活函数
∈ R M l × M l − 1 b ( l ) ∈ R M l 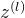
 l 层神经元的净输入(净活性值)
l 层神经元的净输入(净活性值)a ( l ) l 层神经元输出(活性值)2.信息传递过程

本神经元输入 = 上一层的输入向量 X 权重矩阵 + 偏置

输出 = 以本神经元输入为因变量的激活函数

前馈计算

3.通用近似定理
对于具有线性输出层和使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其中隐藏神经元的数量足够,它可以以任意的精度来近似任何一个定义在实数空间中的有界闭集函数。
人话:拥有此性质的神经网络可以近似任意函数
4.应用
神经网络可以作为一个“万能”函数 / 进行复杂特征转换 / 逼近复杂条件分布
y ^ = g ( Φ ( x ) ; θ ) " role="presentation"> 其中 为神经网路、
为神经网路、θ " role="presentation">为分类器!!!若
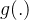 为Logistic回归,则Logistic回归分类器可以视为神经网络的最后一层
为Logistic回归,则Logistic回归分类器可以视为神经网络的最后一层
越往后层,提取的特征越高级,最后一层为分类器
5.参数学习
对于多分类问题
①若使用Softmax回归分类器,相当于在网络最后一层设置C个神经元,

②若采用交叉熵损失函数
损失函数为:
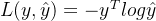
③对于给定的训练集D,输入样本
x ( n ) 
| | W | | F 2 = ∑ l = 1 L ∑ i = 1 M l ∑ j = 1 M l − 1 ( w i j ( l ) ) 2 ④梯度下降
计算:
σ R ( W , b ) σ W ( l ) σ R ( W , b ) σ b ( l ) 链式法则:

可以使用反向传播算法 或 自动微分
6.反向传播算法
!!!矩阵微积分:以向量来表示,使用分母布局
①矩阵偏导数:
∂ y ∂ x = [ ∂ y ∂ x 1 , . . . , ∂ y ∂ x M ] T ②向量的偏导数:

可以使用链式法则:求复合导 ->
∂ z ∂ x = ∂ y ∂ x ∂ z ∂ y ①梯度计算

∂ L ( y , y ^ ) ∂ w i j ( l ) = ∂ z ( l ) ∂ w i j ( l ) ∂ L ( y , y ^ ) ∂ z ( l ) ∂ L ( y , y ^ ) ∂ b ( l ) = ∂ z ( l ) ∂ b ( l ) ∂ L ( y , y ^ ) ∂ z ( l ) 

②计算误差项
误差项:
∂ L ( y , y ^ ) ∂ z ( l ) 
∂ L ( y , y ^ ) ∂ W ( l ) = δ ( l ) ( a ( l − 1 ) ) T ③利用反向传播算法训练

7.计算图与自动微分(优先使用)
利用链式法则,自动计算一个复合函数的梯度,计算图如下:

可以将每一步对应的函数的和导数记录,需要计算时候,由链式法则连乘即可


①前向模式
计算方向与信息传播的方向一致(每走一步算一个导数)
②反向模式
计算方向与信息传播的方向相反(先计算出h6,再返过去算导数--等同于反向传播算法)
③静态计算图
编译时构建的,程序运行时不再改变
优点:构建时可以进行优化,并行能力强
缺点:灵活性较差
④动态计算图
程序运行时动态构建
优点:灵活性高
缺点:不易优化,难以并行计算
8.优化问题
①非凸优化
y = σ ( w 2 σ ( w 1 x ) ) " role="presentation" style="position: relative;">
②梯度消失
y = f ( 5 f 4 ( f 3 ( f 2 ( f 1 ( x ) ) ) ) ) " role="presentation" style="position: relative;">

③难点
非凸优化问题:存在局部最优解和全局最优解,影响迭代
梯度消失问题:下层参数较难调(多段导数连乘容易趋近于0)
参数过多,影响训练。参数的解释也较为麻烦
需求:①计算资源大 ②数据多 ③算法效率高(快速收敛)
-
相关阅读:
CMT2380F32模块开发2-IDE软件配置
Jmeter分布式压测
基于SqlSugar的开发框架循序渐进介绍(17)-- 基于CSRedis实现缓存的处理
西班牙知名导演:电影产业应与NFT及社区做结合
VoIP之前向纠错(FEC)
【快速上手系列】使用支付宝沙箱环境进行支付测试的快速上手
什么是CMDB?为什么企业需要CMDB?
基于JavaWeb的智慧停车管理系统设计与实现
SpringBoot SpringBoot 开发实用篇 1 热部署 1.2 自动启动热部署
【YOLO】YOLO简介
- 原文地址:https://blog.csdn.net/weixin_37878740/article/details/126435688