-
拯救pandas计划(25)——向量化运算优化循环代码
拯救pandas计划(25)——向量化运算优化循环代码
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
- windows 10
- python 3.8
- pandas >=1.2.4
/ 数据需求
最近处理了一段代码,值得注意的是,原有代码是依赖pandas进行处理的,而其中有部分为for循环处理了数据框的内容,本篇对此次优化过程进行一个梳理,过程中如有不满意处请多多理解。
注:本篇不提供数据。
处理前代码如下:
# encoding=utf-8 # File: 修改前代码.py from time import perf_counter import pandas as pd import math from matplotlib.path import Path # 地位围栏表 coorgd_filename = ... coorgd = pd.read_csv(coorgd_filename) print(coorgd.info()) # 6066, dtypes: object(6) # 待清洗表 project_filename = ... project_df = pd.read_csv(project_filename, encoding='gb18030') print(project_df.info()) # 20, dtypes: float64(2), int64(1), object(1) # 经纬度转换 def long_lat_transf(long, lat): PI = 3.14159265358979324 * 3000.0 / 180.0 x = long - 0.0065 y = lat - 0.006 z = math.sqrt(x * x + y * y) - 0.00002 * math.sin(y * PI) theta = math.atan2(y, x) - 0.000003 * math.cos(x * PI) long_out = z * math.cos(theta) lat_out = z * math.sin(theta) return long_out, lat_out # 判断转换后的经纬度在哪个围栏里并返回对应的uuid def coorgd_contains_point(aa): for bb in coorgd.coorgd: try: p = Path(list(eval(bb))) a = p.contains_point((eval(aa))) if a is True: dff = coorgd[coorgd['coorgd'] == bb].head(1) return dff.itemid.iloc[0] else: pass except: pass start_time = perf_counter() # 处理围栏表字段为函数中的格式 coorgd['coorgd'] = '(' + coorgd['coorgd'] + ')' coorgd['coorgd'] = coorgd['coorgd'].str.replace(';', '),(') project_df['gd_lng_lat'] = project_df[['lng', 'lat']].apply(lambda x: long_lat_transf(x[0], x[1]), axis=1).astype( str).str.replace(r"\(|\)", "", regex=True) project_df[['gd_lng', 'gd_lat']] = project_df['gd_lng_lat'].str.split(',', expand=True) print(f'long_lat_transf耗时:{perf_counter() - start_time:.6f}s') start_time2 = perf_counter() project_df['itemid'] = project_df['gd_lng_lat'].apply(coorgd_contains_point) print(f'coorgd_contains_point耗时:{perf_counter() - start_time2:.6f}s') print(f'总耗时:{perf_counter() - start_time:.6f}s')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
执行耗时:
# ----------------------------------- # long_lat_transf 耗时:0.091602s # coorgd_contains_point 耗时:63.234401s # 总耗时:63.326075s- 1
- 2
- 3
- 4
大致看下来,整段代码的主要耗时部分在第二段函数
coorgd_contains_point,接下来对整体代码进行剖析,对可以改进的部分进行优化。/ 函数优化
在优化代码前,需要理解这段代码处理的情景以及代码之间的关联。
函数
long_lat_transf:内容是将一个数通过三角函数转换成目标值,而且是调用math包中的函数进行计算,在pandas中对比math可能更倾向于用numpy进行计算,优化时将其更改成numpy对应的函数,再看到调用部分,
project_df[['lng', 'lat']].apply,是按行进行遍历,计算每一行,project_df的行数并不多,仅20行,然而却有一定的耗时,在整个运算过程中并没有使用向量化进行运算,即使将math改为numpy,如何改变?可以联想到numpy的数据特性,直接用列与列进行计算,在此次中直接调用.value使用numpy.array对象计算。在计算结果后转换列类型为
str,并且将两端括号进行了去除,整体观察下来,发现为eval(aa)做了数据准备,而在实际运行eval(aa)那行代码时,是不需要进行去除。函数
long_lat_transf及调用方式更改对比如下: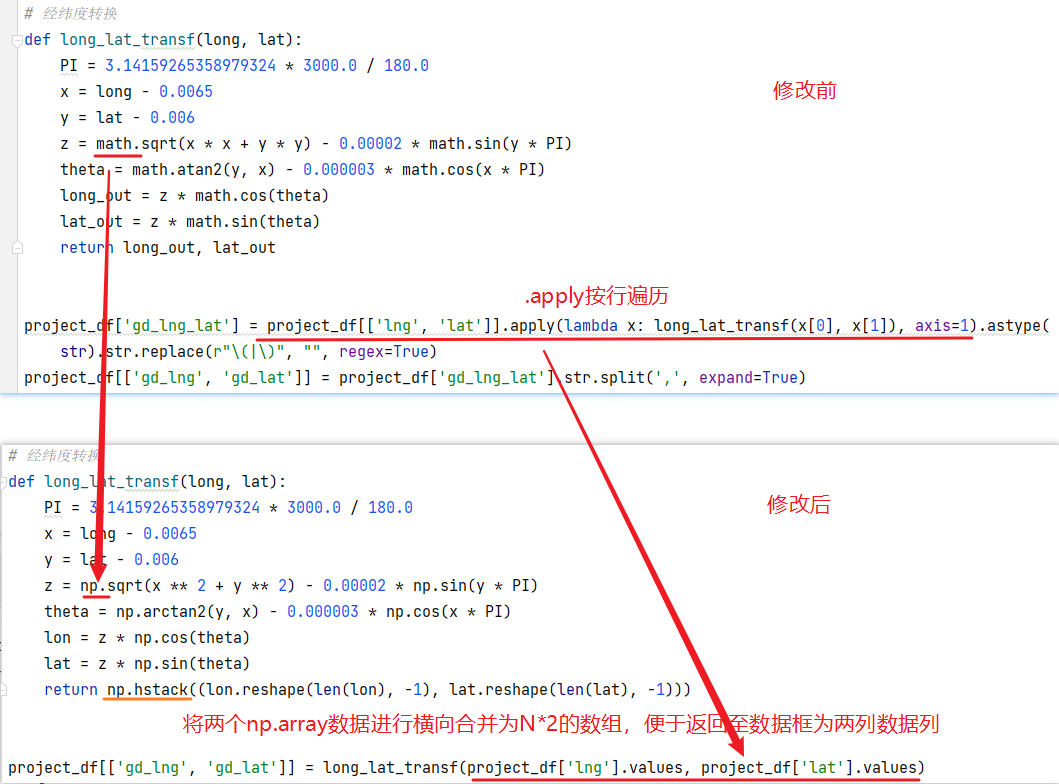
整体代码部分并未发生较大变化,只是将入参的值由单行改成列传入,通过向量化的计算,使之前的0.091602s耗时缩减至0.001272s,提升了近100倍。
函数
coorgd_contains_point:这个函数主要功能是判断传入的点是否在一组点圈住的范围内,
coorgd['coorgd']中每一行值为组成一个围栏表的点。在原函数中每次判断点时都会为每一行重新生成围栏表,无疑增加了计算耗时,并且用eval函数转换字符串为python列表对象是消耗内存和时间的,由此,这部分的代码优化则是减少eval的使用,和每次判断点是否在某个围栏表中,只需要生成一次围栏表对象。函数
coorgd_contains_point及调用方式更改对比如下:
橘色框中,修改前代码为了将一组点能够正常的被Path函数解析,需要转换成列表样式的字符串格式数据,通过eval函数转换成list对象,虽说橘色框耗时不长,但此处完全可以避免eval解析,修改后代码,以每组点之间的分号
;作为分隔符分隔成列表,但列表的内容还是字符串,Path函数不接受,使用explode列转行,一组点中由逗号,进行分隔,同时转换数据类型为浮点数。这样构造出Path所能接收的数据类型。减少了eval解析,同时也用到了pandas中.str向量化计算,运行效率大幅提高。判断点是否在围栏表中,由于仅需要生成一次围栏表,相比修改前,是直接在判断处进行布尔索引,可读性相对较好,在上一个函数中已经将点处理成浮点数类型,按行遍历时不用再用eval进行解析。
抛弃了不必要的
try代码。在调用函数时,传入了主程序中的数据框,避免函数内部的修改影响数据框内容,对数据框进行了复制再运算。
修改后的代码如下:
# encoding=utf-8 # File: 修改后代码.py from time import perf_counter import numpy as np import pandas as pd from matplotlib.path import Path pd.set_option('display.float_format', None) pd.set_option('precision', 6) # 地位围栏表 coorgd_filename = ... coorgd = pd.read_csv(coorgd_filename) # 待清洗表 project_filename = ... project_df = pd.read_csv(project_filename, encoding='gb18030') # 经纬度转换 def long_lat_transf(long, lat): PI = 3.14159265358979324 * 3000.0 / 180.0 x = long - 0.0065 y = lat - 0.006 z = np.sqrt(x ** 2 + y ** 2) - 0.00002 * np.sin(y * PI) theta = np.arctan2(y, x) - 0.000003 * np.cos(x * PI) lon = z * np.cos(theta) lat = z * np.sin(theta) return np.hstack((lon.reshape(len(lon), -1), lat.reshape(len(lat), -1))) # 判断转换后的经纬度在哪个围栏里并返回对应的uuid def coorgd_contains_point(gd_df, df): dfc = df.copy() dfc['coorgd'] = dfc['coorgd'].str.split(';') dfc = dfc.explode('coorgd') # 不重置索引,原列数据的索引与拆分后数据列索引相同 dfc[['coorgd_lon', 'coorgd_lat']] = dfc['coorgd'].str.split(',', expand=True).astype('float64') dfc_Path = dfc.groupby(level=0, sort=False)[['coorgd_lon', 'coorgd_lat']].apply(Path) dfc_Path.index = df['itemid'] def get_itemid(s, path_df): dff = path_df[path_df.map(lambda x: x.contains_point(s))] if dff.empty: return return dff.index[0] return gd_df[['gd_lng', 'gd_lat']].apply(get_itemid, args=(dfc_Path,), axis=1) start_time = perf_counter() project_df[['gd_lng', 'gd_lat']] = long_lat_transf(project_df['lng'].values, project_df['lat'].values) print(f'long_lat_transf耗时:{perf_counter() - start_time:.6f}s') start_time2 = perf_counter() project_df['itemid'] = project_df.pipe(coorgd_contains_point, coorgd) print(f'coorgd_contains_point耗时:{perf_counter() - start_time2:.6f}s') print(f'总耗时:{perf_counter() - start_time:.6f}s') print(project_df['itemid'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
执行耗时:
# ------------------------ # long_lat_transf耗时:0.000892s # coorgd_contains_point耗时:4.509768s # 总耗时:4.510704s- 1
- 2
- 3
- 4
消除部分耗时较长的代码,并尽可能地更改为向量化的计算,执行耗时较少至4.5s,效率提高了近14倍,效果是非常可观的。
/ 总结
之前在翻看pandas处理效率上的文章时,有注意到向量化计算对比for循环能极高的提高运行效率,在编写逻辑代码时,将耗时长的部分能否让其只生成一次,循环计算部分是否可以用numpy的数学函数进行替代,数字的计算比字符串的解析耗时会少很多。通过本篇的优化,能够明显的感受到减少冗余代码是能够提高代码的运行效率,同样地,减少时间可能会增加空间的使用,需要权衡利弊。
-青砖玉瓦,笑看古今风流。-
于二零二二年八月二十日作
-
相关阅读:
【业务安全-02】业务数据安全测试及商品订购数量篡改实例
基于C语言的词法分析实验
anaconda下载与spyder的报错解决
渗透测试与HTTP中的PUT请求
论文复现--VideoTo3dPoseAndBvh(视频转BVH和3D关键点开源项目)
pdf如何加密码保护?
有关python的代码执行顺序以及多线程
idea常用配置 | 快捷注释
论文写作——ICASSP论文写作及投稿
JAVA“陶瓷的世界”网页的实际与实现计算机毕业设计Mybatis+系统+数据库+调试部署
- 原文地址:https://blog.csdn.net/weixin_46281427/article/details/126441654
