-
zookeeper学习一
zookeeper集群概念
首先redis是一个单实例的,底层使用的是多路复用,并且使用内存来存入数据(快),因redis有单点问题,衍生出复制集群,并从而衍生出高可用(靠sentinel,主机挂了以后选择相应的从机),复制集群的弊端是数据不是绝对的实时同步【并且由于生产环境服务器有各种挂掉的风险,可能连最终一致性都谈不上】,还有集群模式(sharding分片),从而引出完成分布式协调很难,需要使用分布式锁。

zookeeper分布式协调服务
首先zookeeper里面会有一个leader,是个主角色,此外还有一些zookeeper进程,是一些
follow,客户端想连谁就连谁,最终的写请求是转到leader上面完成的。
并且每一个客户端连接到zk的时候一定会产生一个session来代表客户端。

注意:
1、如果leader挂掉了会带来服务不可用问题,以及不可靠问题,但是
事实上zk集群及其高可用
2、如果有一种方式可以快速的恢复出一个leader,集群又进入了一个可用的状态
如果主挂掉了,zk集群会进入到一个无主模型的状态:
zk中有两种状态:
1、可用状态
2、不可用状态
那么期望不可用状态恢复到可用状态越快越好

看官方文档恢复在200ms左右就能恢复了。且zk集群对外提供的能力还是很好的:

zookeeper结构
zk是一个目录树结构,node可以存数据不超过1MB,它的节点分为持久化节点,以及临时节点(依托于session)还有序列节点()。
要临时节点的目的:
有了session之后zk做分布式协调,可以做分布式事件通知,不用像redis一样引入线程概念,
如果有了session的话,客户端周期判断session是否过期。ZooKeeper 非常快速且非常简单。但是,由于它的目标是成为构建更复杂服务(例如同步)的基础,因此它提供了一组保证。这些是:
顺序一致性 - 来自客户端的更新将按照它们发送的顺序应用。
原子性 - 更新成功或失败。没有部分结果。
单一系统映像 - 客户端将看到相同的服务视图,而不管它连接到的服务器如何。即,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。
可靠性 - 应用更新后,它将从那时起持续存在,直到客户端覆盖更新。
及时性——系统的客户视图保证在一定的时间范围内是最新的【保证最终一致性】。

zookeeper安装和集群配置
首先需要安装jdk,然后解压对应的zookeeper文件

进入zookeeper看一下它的目录结构:

进入bin目录:

再看一下配置文件目录:

有一个zoo_sample.cfg,将它拷贝成zoo.cfg,zk启动默认配置文件为zoo.cfg

syncLimit:2s*5=10s,如果leader下发同步的时候,如果follow十秒没回复的话则认为服务是有问题的。
dataDir =/tmp/zookeeper,持久化目录,最好不用tmp,改成/var/zk
clientPort 客户端连接端口号
maxClientCnxns 代表客户端允许最大连接数

客户端连接server的端口,即对外服务端口,一般设置为2181
clientPort=2183
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那里收到响应,那么就认为这个F已经不在线了
syncLimit=5
ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功能。
autopurge.purgeInterval=1
单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。请注意这个限制的使用范围,仅仅是单台客户端机器与单台ZK服务器之间的连接数限制,不是针对指定客户端IP,也不是ZK集群的连接数限制,也不是单台ZK对所有客户端的连接数限制
maxClientCnxns=0
存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。
dataDir=/usr/local/…
Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit 时间内完成这个工作。通常情况下,我们不用太在意这个参数的设置。如果ZK集群的数据量确实很大了,F在启动的时候,从Leader上同步数据的时间也会相应变长,因此在这种情况下,有必要适当调大这个参数了。
initLimit=10
这个参数指定了需要保留的文件数目。默认是保留3个
autopurge.snapRetainCount=30
这里的x是一个数字,与myid文件中的id是一致的。右边可以配置两个端口,第一个端口用于F和L之间的数据同步和其它通信,第二个端口用于Leader选举过程中投票通信【如果一个server挂掉以后会通过第二个端口去重新选举leadder,然后其他的节点再通过第一个端口去连接传输数据】。
server.x=master:2898:3898
ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime。
tickTime=3000
需要注意的是:dataDir目录下数据文件 myid 文件中的数值在集群zookeeper的配置中是唯一的。退出之后创建如下文件夹:



远程拷贝:scp -r ./xxx/ node02:‘pwd’
分别在四台服务器上面配置myid




这里myid的值是和配置文件里面的值是一样的。
接下来配置ZK的环境变量:vi /etc/profile

 将配置文件全部发送。
将配置文件全部发送。

zookeeper使用
分为前台启动和后台启动
启动后可以看到Mode为leader的和Mode为follower

第一次启动的时候会根据基数台机器的id选一个最大的myid作为leader。
然后本地去连接【默认是他自己】:

发现有如下命令:

可以创建节点:

如下可以通过zk去放数据,并且放的数据不超过1M,并且是二进制安全的:

czxid:保证zookeeper顺序执行,所有写操作给到zk的任何一个角色的时候都会递交给leader,leader因为是单机,所以单机维护一个单调递增的计数器很容易【每一个数代表四个二进制位,后三十二位表示事务的递增序列,前三十二位表示leader的纪元,是第几个leader】。
ephemeralOwner = 0x0:当前的节点没有归属者,属于持久节点。【默认】
命令:create -e path data
当创建改znode的client与zookeeper的连接断开时,znode会被自动删除,临时模式znode不能有child node
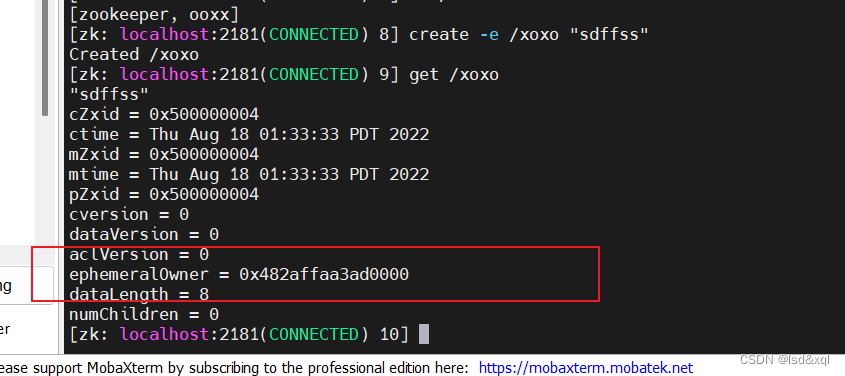
然后当前client关闭连接:

会看到这个sessionId是被回收了的

重新连接就找不到我们的xoxo了。如果客户端连接一个follower创建了一个临时节点,但是当前的这个follower挂掉了,此时客户端需要去连接其他的follower,那么会发现其他的follower也存了当前的session。
先连接第四台:

此时产生一个sessionId:

此时在第四台机器上创建一个xoox

然后启动第二台的客户端

然后创建一个oxxo:

发现事务ID差了一个,原因在于客户端在连接的时候它走到leader将这个连接的sessionId写给所有的节点,这样会消耗一个事务,同理断开连接的时候也会消耗一个事务id去通知所有的节点我这个事务已经没有了。如果多个并发同时创建一个数据的话直接创建会返回一个错误提示:

此时引出持久化序列:持久序列(persistent_sequential)
命令:create -s path data
znode被创建后,znode名称会自动添加一个编号,编号会自动递增。

切换到另一个客户端发现递增:


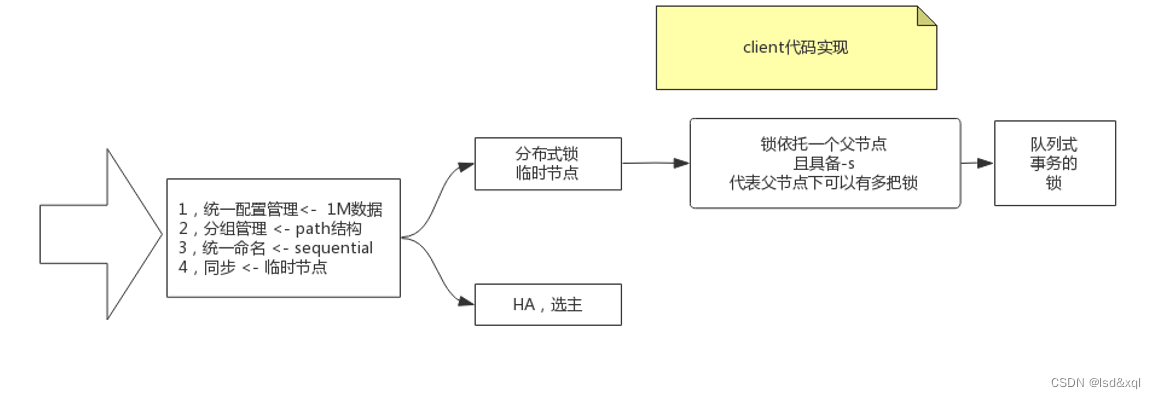
这样就避免了覆盖创建,并且这个数量会在leader内部维护。ZK目录结构可以应用于哪些功能
1、统一配置管理:分布式服务器只需要记住节点就可以得到1M数据
2、分组管理(它有一个path的树结构)
3、统一命名(sequential序列能力)
4、分布式同步(通过临时节点来实现,用于分布式锁)【如果这个锁依托于一个父节点,且具备
-s,代表这个父节点下面可以有多把锁,队列式事务的锁 create -s -e】(但是需要客户端代码自己去实现)
5、HA、选主
关于3888端口连接:
首先1会连接2,3,4
2会连接3,4
3.会连接4
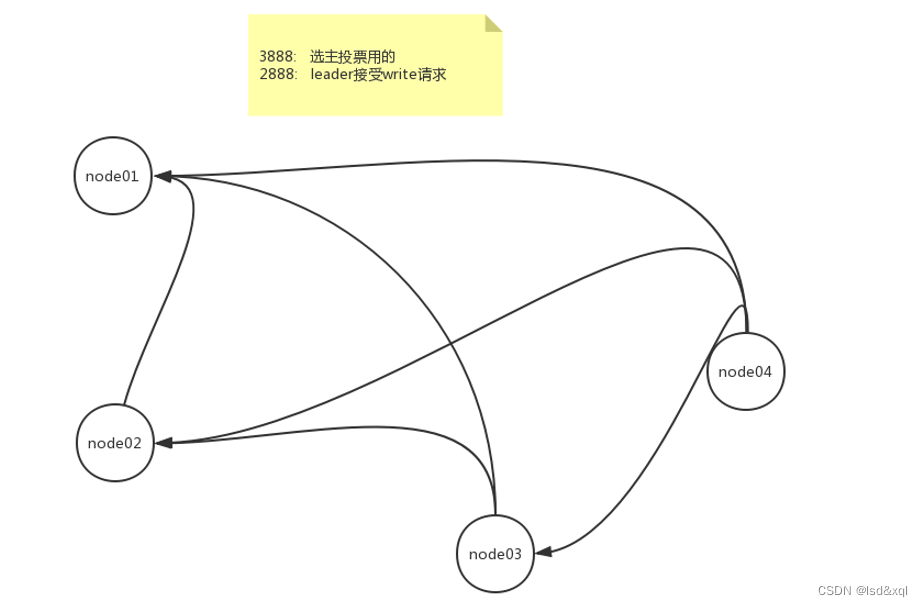
每个节点关于3888的socket都有三个。 -
相关阅读:
Java程序员进阶架构师必备实践指南(值得收藏)
shiro学习33-shiro的工具类-webUtils
CSS基础参考笔记
2022年湖北省科技计划项目“包干制”管理申报条件以及流程
使用Redis查询数据库数据增加访问速度小案例
RabbitMQ 消息队列中间件详解
C语言描述数据结构 —— 二叉树(3)普通二叉树
Android UI界面去除标题栏的方法
docker安装网易云音乐(yesplaymusic)
Linux下的静态链接库和动态链接库
- 原文地址:https://blog.csdn.net/lsdstone/article/details/126355879