-
6.4-为何要深度学习
一、模型对比
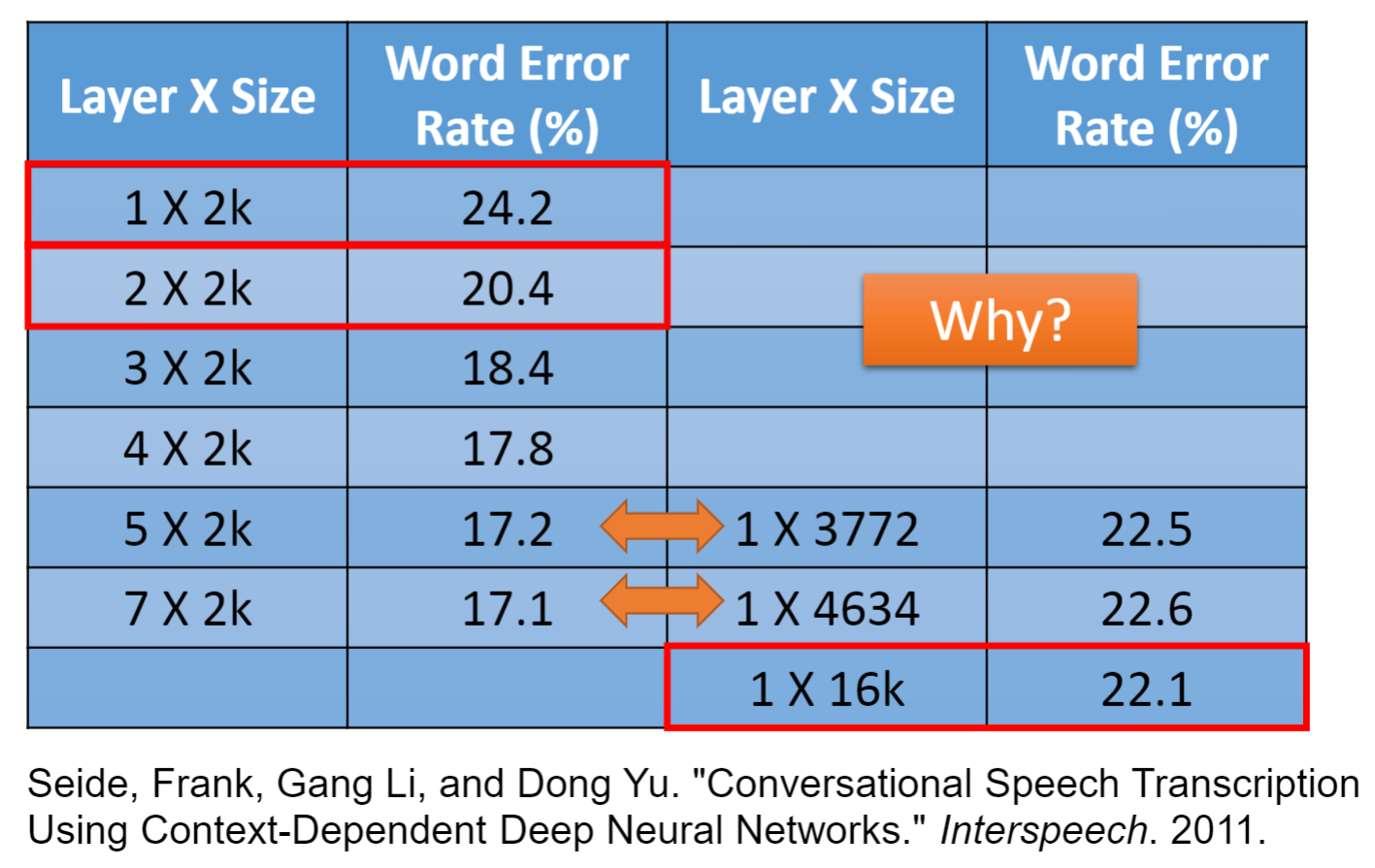
- 在参数量相同的条件下,究竟是深度越深的模型越好,还是宽度越宽的模型越好?
- 很显然,右图的实验数据告诉我们深度是更好的选择,但为什么会这样呢?答案是模块化

二、模块化(Modularization)
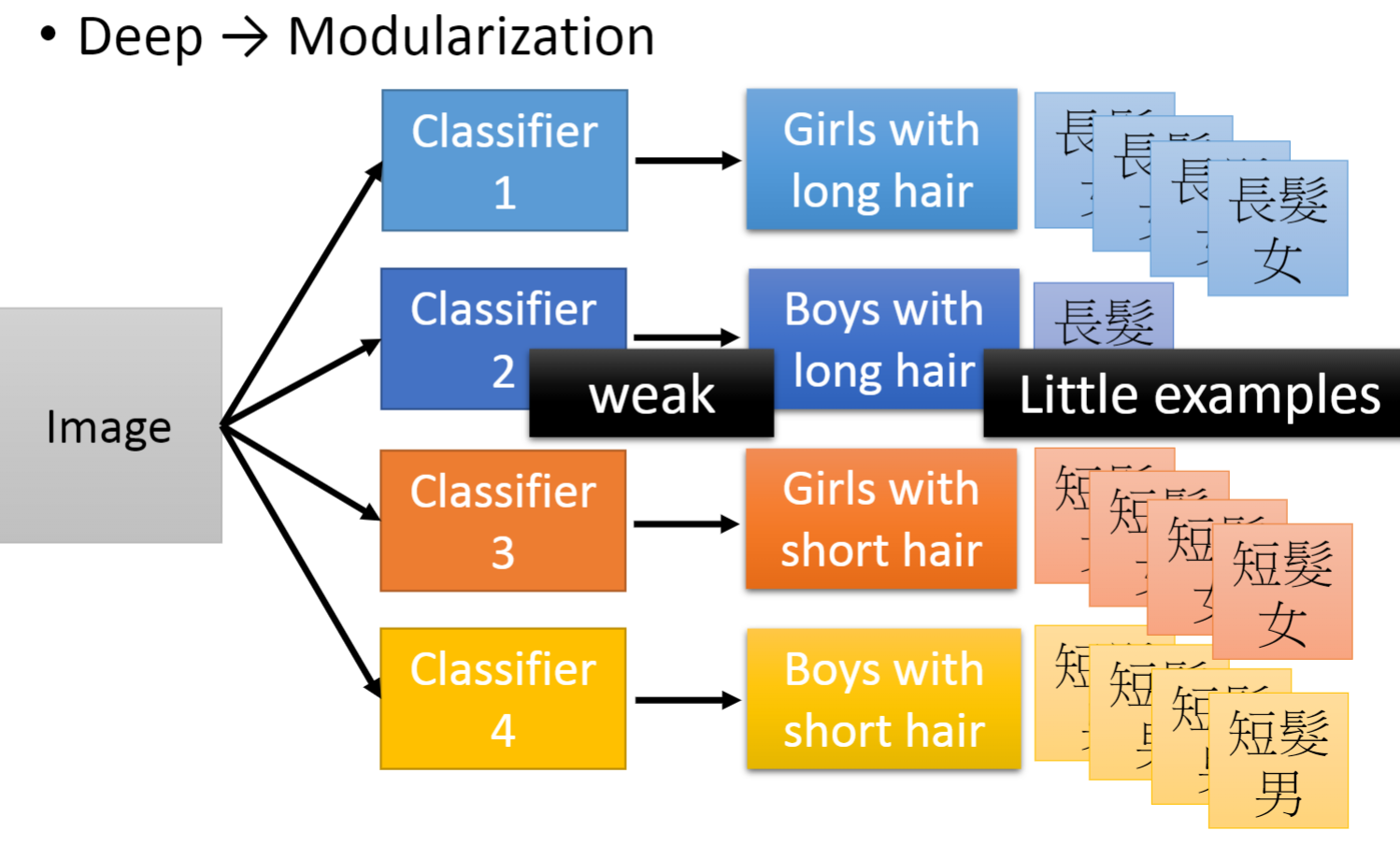
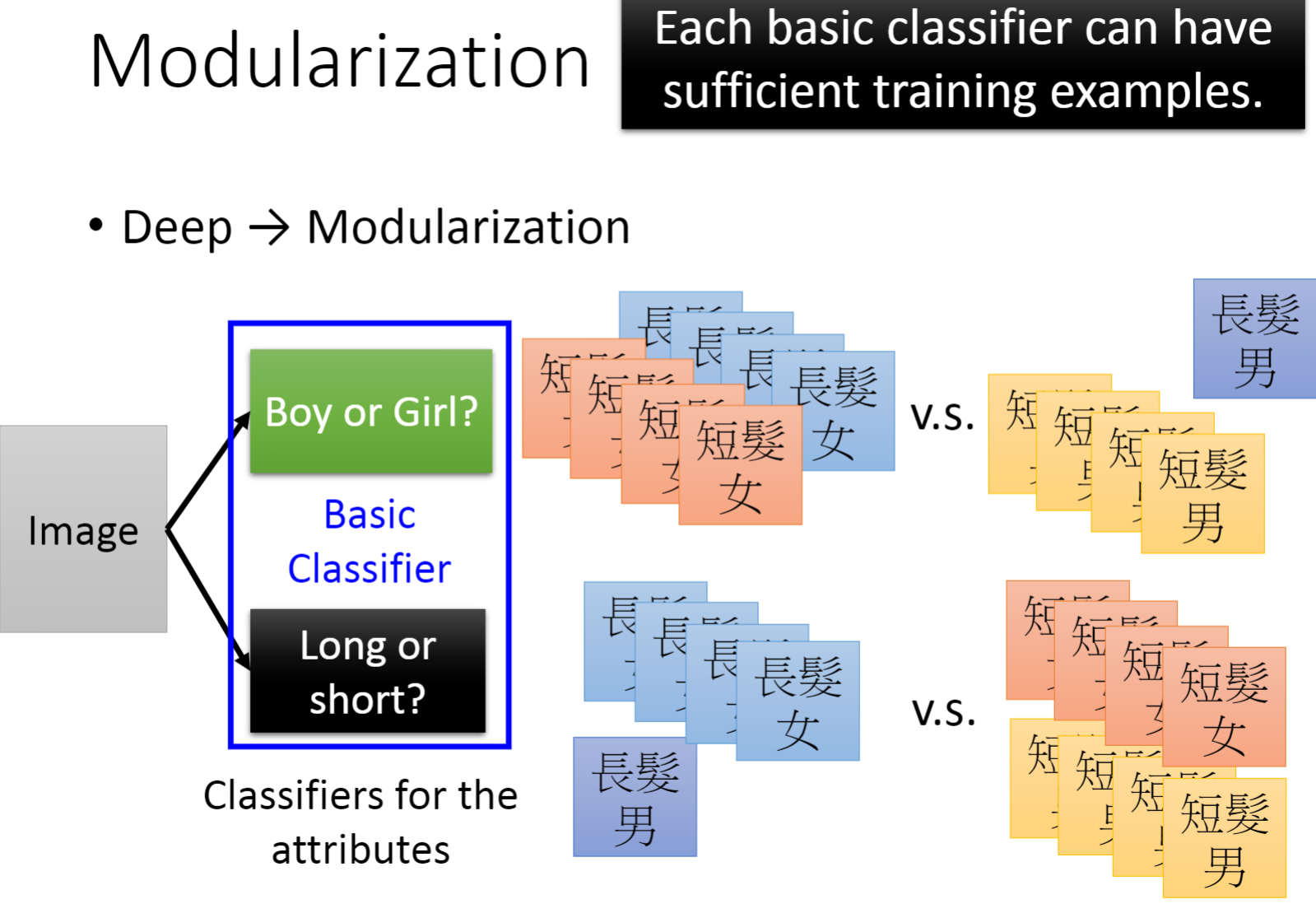
- 根据编程的模块化思想,我们很容易想到的一点是模块化能大大降低系统开发的复杂度,便于管理,并且代码可重用,提高开发效率等等。
- 而对于深度学习来说也是如此,网络中的每一个神经元都可以视为一个模块,前面的模块将数据一步一步处理,最终得到预测结果,尽管每个模块都只做了很小的一件事,但他们集合起来就是一件十分复杂的事情。
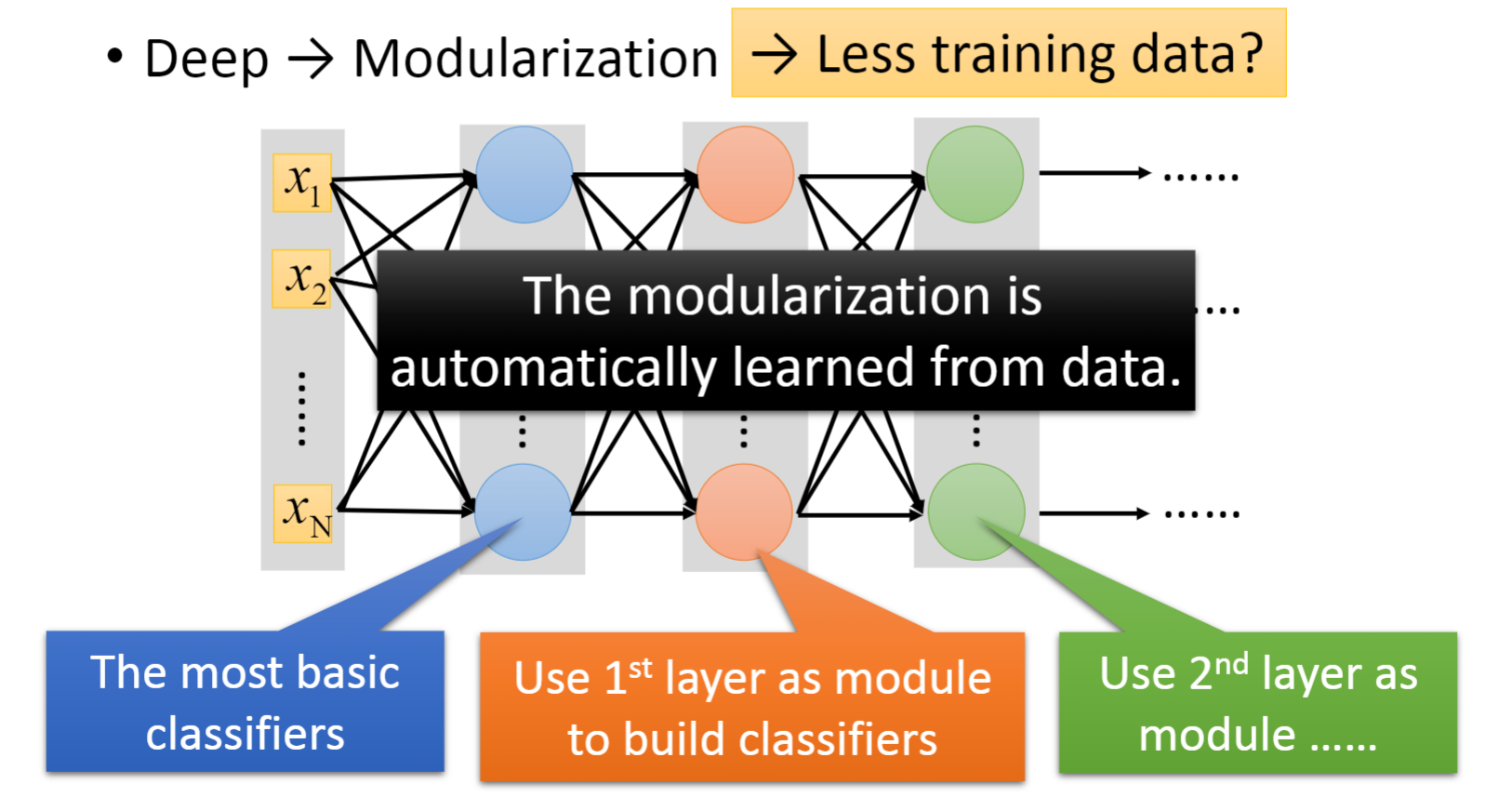
- 通过模块化的网络,我们只需要少量的数据就能训练到一个很好的模型。



三、语音辨识
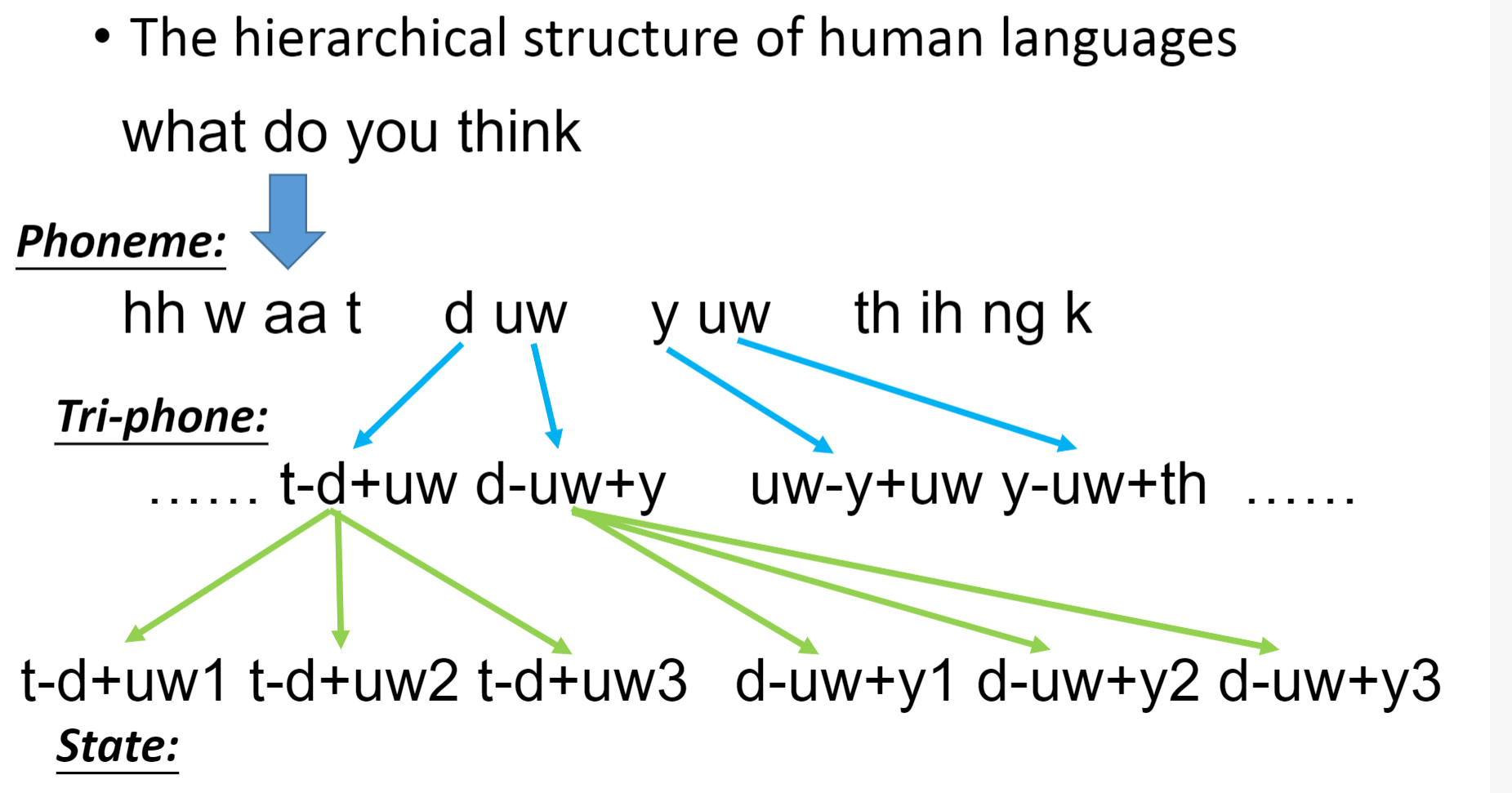
- 人类的语言是一个多层次(hierarchical)的结构
- Phoneme:音素 ,Tri-phone:3个音素 ,State:状态
- 语音辨识的第一个阶段:
- 每一时刻的声音都对应着一组声学特征(acoustic feature)向量,每一组向量对应着一个状态
- 分类: 输入→声学特征,输出→状态
- 确定每个声学特征所属的状态

- 每个状态的声学特征都有一个固定的分布
- 下面是高斯混合模型(Gaussian Mixture Model ),也叫GMM
- 平局状态(Tied-state):不同的状态共用同样的模型分布,就和写程序一样,不同的指针(pointer)指向同样的地址(Same Address)


- 在HMM-GMM中,所有的音素都是模拟独立的
- 这不是模拟人类声音的有效方法
- 元音的发音只受几个因素的控制:舌头的卷曲程度,在口腔中的位置,以及发声的嘴型
- 右图中DNN的输出层大小等于状态的数量:输入为一个声学特征,输出为每个状态的概率


- 将DNN的隐层输出减少到二维,然后输出到图上
- 较低的层检测发音的方式
- 所有的音素共享来自同一套探测器的结果
- 有效地使用参数
- 普遍性定理(Universality Theorem)
- 虽然任意连续函数 f 都可以通过一个只有一个隐藏层的网络实现(给定足够多的隐藏神经元)
- 然而,使用深层结构是更有效率的


3.1 类比(Analogy)
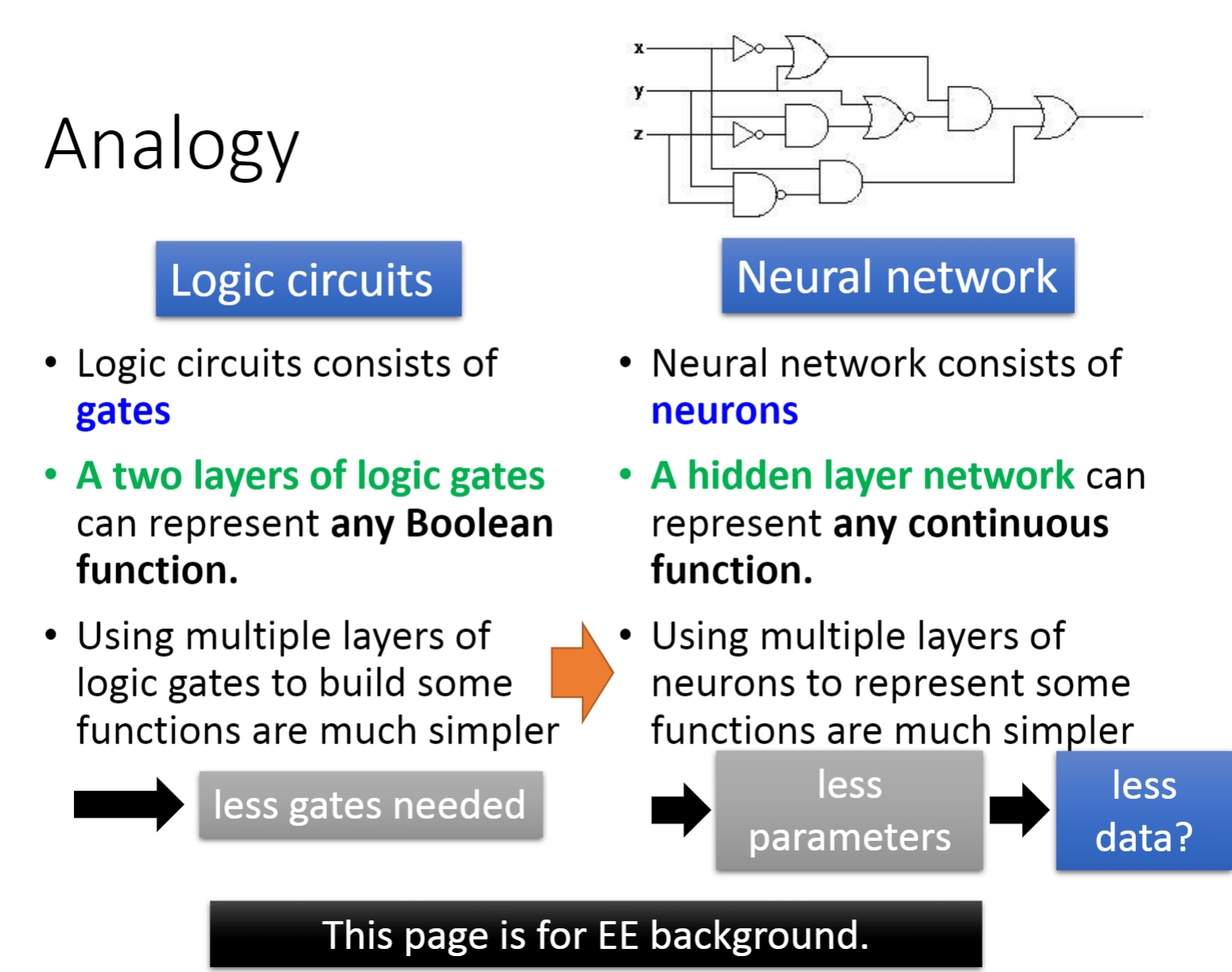
- 逻辑电路(Logic circuits):
- 逻辑电路由门(gate)组成,而神经网络由神经元组成
- 两层逻辑门可以表示任何布尔函数,而只有一层隐层的网络可以表示任意连续函数
- 使用多层逻辑门来构建一些函数要简单得多,而使用多层神经元来表示某些函数要简单得多
- 对于逻辑电路设计来说就只需要更少的逻辑门,而对于神经网络而言也只需要更少的参数,从而就只需要更少的数据
- 奇偶校验(parity check):
- 对于具有d位的输入序列(sequence),两层电路需要O(2d)门。
- 而对于多层,我们只需要O(d)门,门的数量减少了一半
- 剪窗花:
- 剪窗花时并不是将花的形状全部剪出来,只需要剪出一部分即可,这就反映了使用数据是更有效率的
- 最后一图清楚的展示了多层网络同单层网络的不同数据量下的区别,突出了多层网络的优点




3.2 端到端学习(End-to-end Learning)
- 生产线:
- 每个函数应该做的是自动学习,我们只给输入和输出,让模型自己去寻找每一层都是最好的函数
- 右图是做传统的语音辨识方法,对于影像辨识也是一样
- 每个盒子都是生产线上的一个简单功能
- 绿色的盒子都是人工制作的,只有一个蓝色盒子是机器从数据中学习




- 深度学习
- 所有的函数都是从数据中学习的
- 更少的工程劳动,但机器能学到更多

四、复杂任务
- 相同的输入,输出要不同
- 不同的输入,输出要相同
- 右图是在DNN中,不同的人说同样的话的声学特征分布,很显然只有一层隐藏层是无法区分的,而8层就可以明显区分了。
- 手写数字辨识:下图minst数据集上的表现也说明了多层网络的优势




五、更多的原因
- 深度学习:理论动机(Yoshua Bengio)
- http://videolectures.net/deeplearning2015_bengio_theoretical_motivations/
- 物理和深度学习之间的联系
- https://www.youtube.com/watch?v=5MdSE-N0bxs
- 深度学习为何有效:理论化学的视角
- https://www.youtube.com/watch?v=kIbKHIPbxiU

- https://www.youtube.com/watch?v=kIbKHIPbxiU
-
相关阅读:
Linux--进程--进程-父进程退出
编码技巧——使用Easypoi导出Excel
智安网络|揭秘安全测试和渗透测试的异同点
linux系统-----------搭建LNMP 架构
求链表的倒数第m个元素(递归 / 双指针)
蓝牙协议栈分层
Grid布局介绍
Kubernetes实战(三)-k8s节点设置cpu高于多少就不调度
苏州科技大学、和数联合获得国家知识产权局颁发的3项发明专利证书
设置服务账号Service Accounts(sa)的token不挂载到pod
- 原文地址:https://blog.csdn.net/weixin_46227276/article/details/126409402