-
SAM-DETR源码讲解
一:创新点
论文选自2022 CVPR的
Accelerating DETR Convergence via Semantic-Aligned Matching,提出了SAM-DETR模型,研究方向是缓解传统DETR训练收敛慢的缺陷。最大创新点在我看来,有以下两点:- 作者认为在cross-attn中的query经过了一系列self-attn操作后,和src特征的语义信息不在一个层面,很大程度上影响了训练收敛速度。因此,作者利用了memory中的大量特征,并且也融合了tgt,来构成语义对齐后的q_content。
- 作者对每一个anchor都选取num_heads个显著点,这样也会让网络更好的学到更有意义的特征位置,也会加快注意力的收敛速度和效果。
二:源码分析
作者也使用了Conditional-DETR中一部分的q_content和q_pos的解耦思想,只是没有concat而已。以及CAB-DETR中的(cx,cy,w,h)显式表征的query_embed方式,并迭代更新anchor_box框,可见这些已经慢慢成为一种规范 。
下面步入正题,看fast_detr主模块源码:
fast_detr:
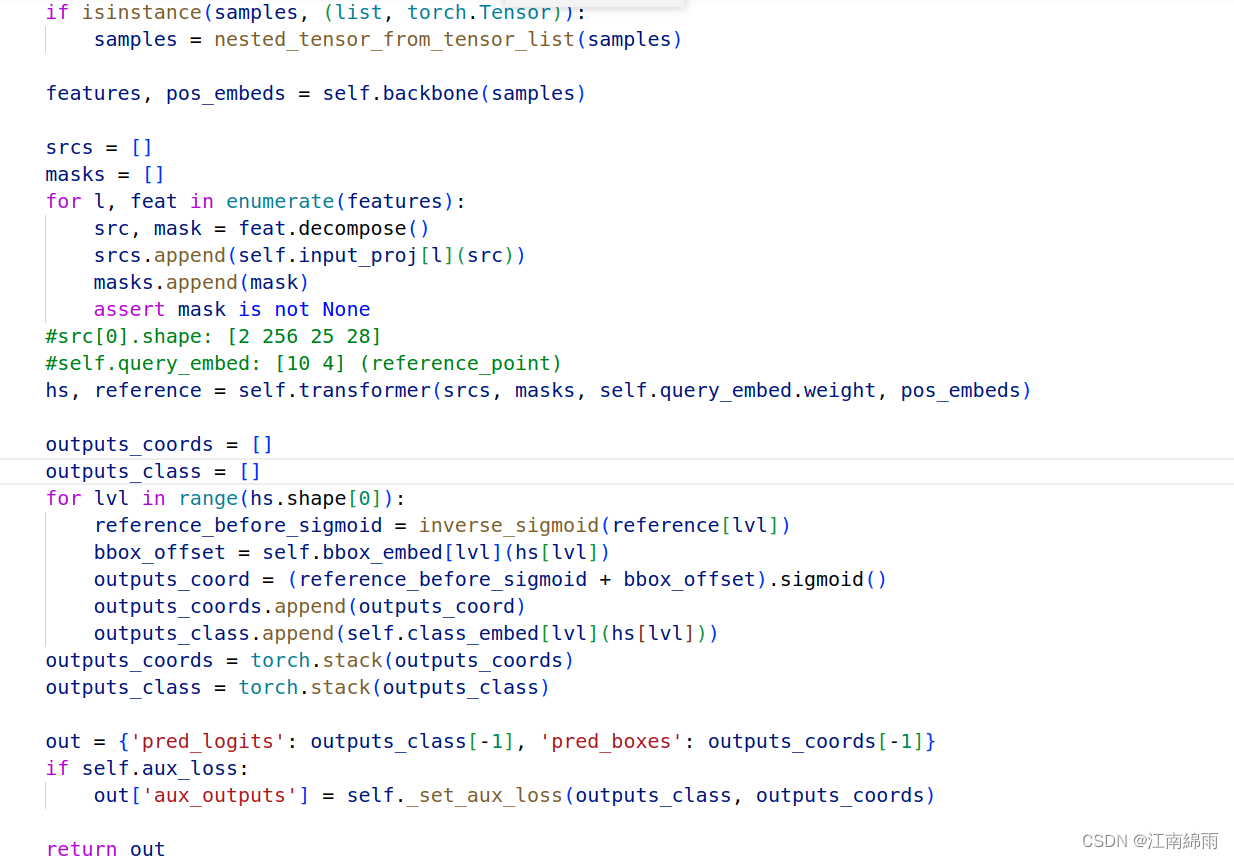
中规中矩,下面看看trans模块:
transformer:
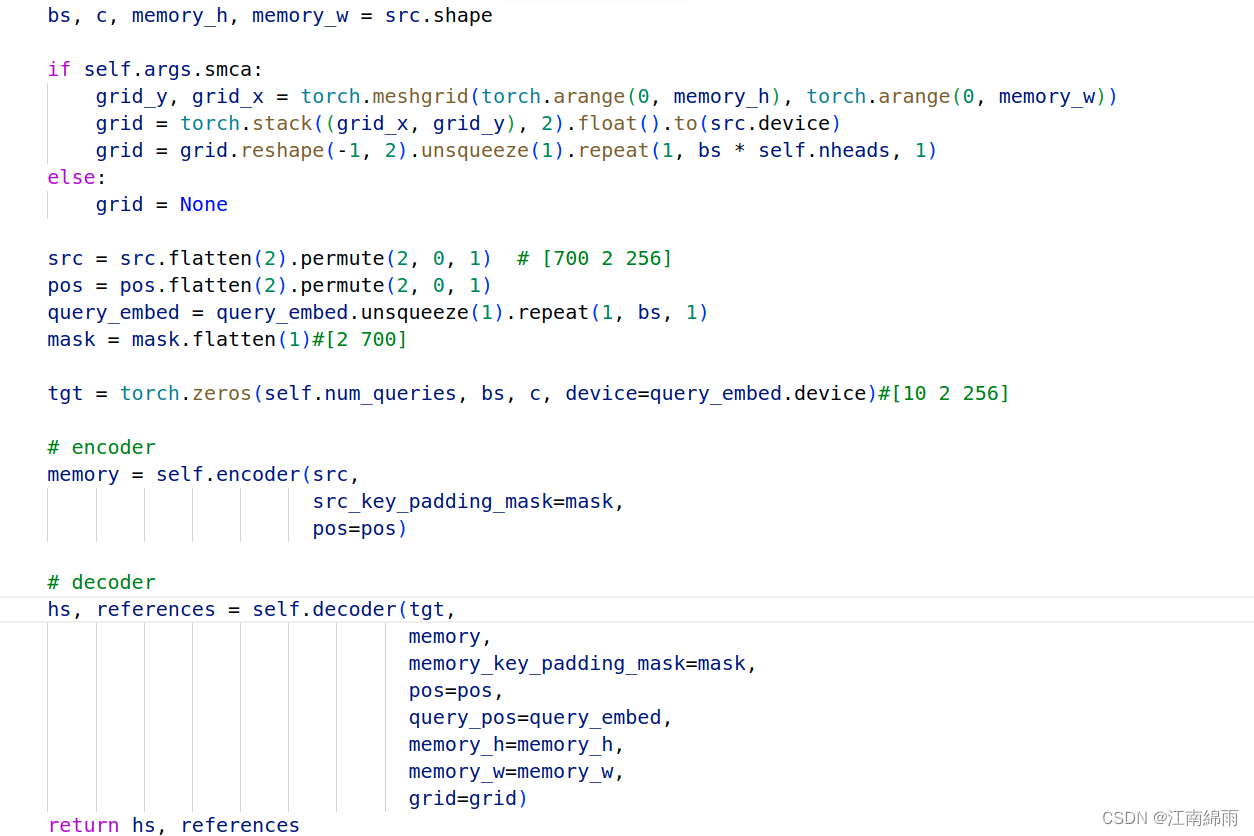 encoder模块和detr基本一致,不讲,直接看decoder模块:
encoder模块和detr基本一致,不讲,直接看decoder模块:decoder:

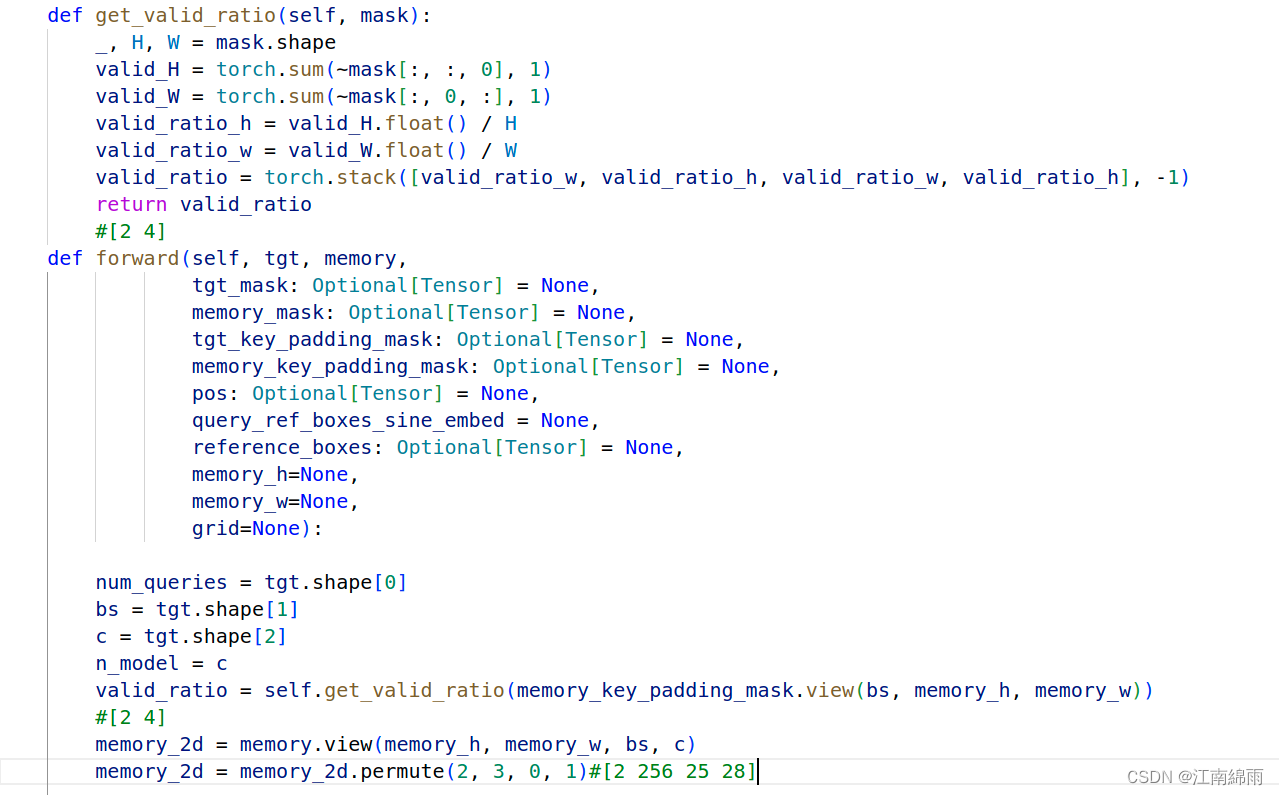
基本没有什么特别之处,但有一个细节,发现还往Layer中输入了memory的实际长、宽,是为了后面RoiAlign的投射服务的。重点到了,让我们看看decoderLayer模块中是如何运作的:

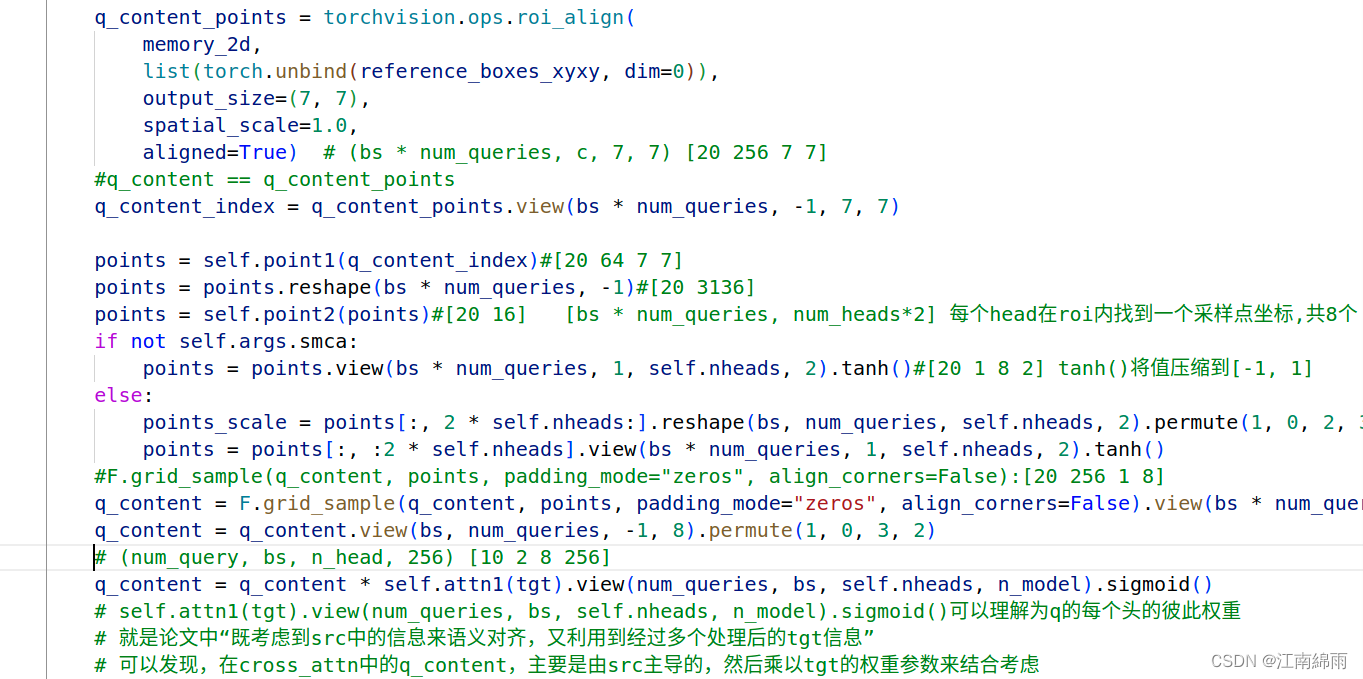

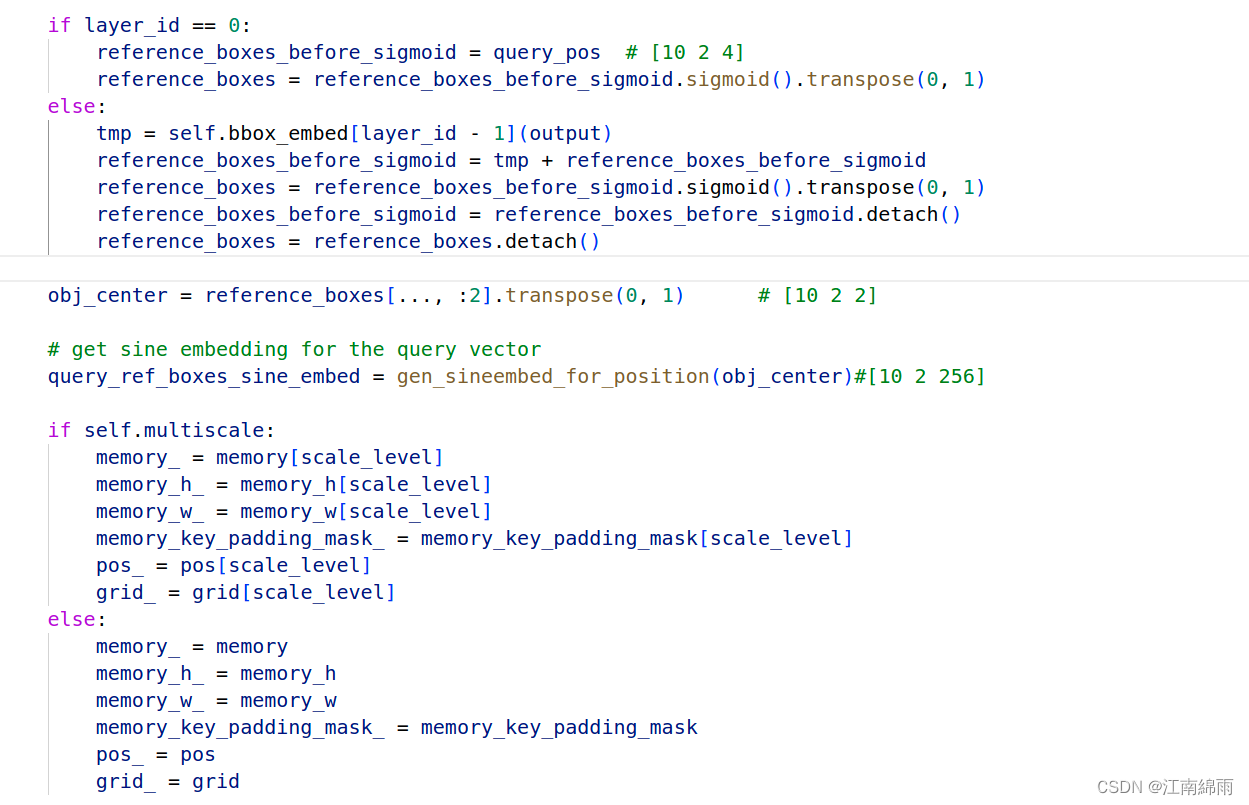
许多的实现细节,都可以看我上方截图中的源码注释。这里我囊括一下,首先是q_content的组成,它首先由每个anchor框中重采样的num_heads个点组成,这样按作者论文解释就对齐了src中的语义。然后再乘上利用tgt生成的权重系数矩阵,这样就 是又结合了tgt的内容。
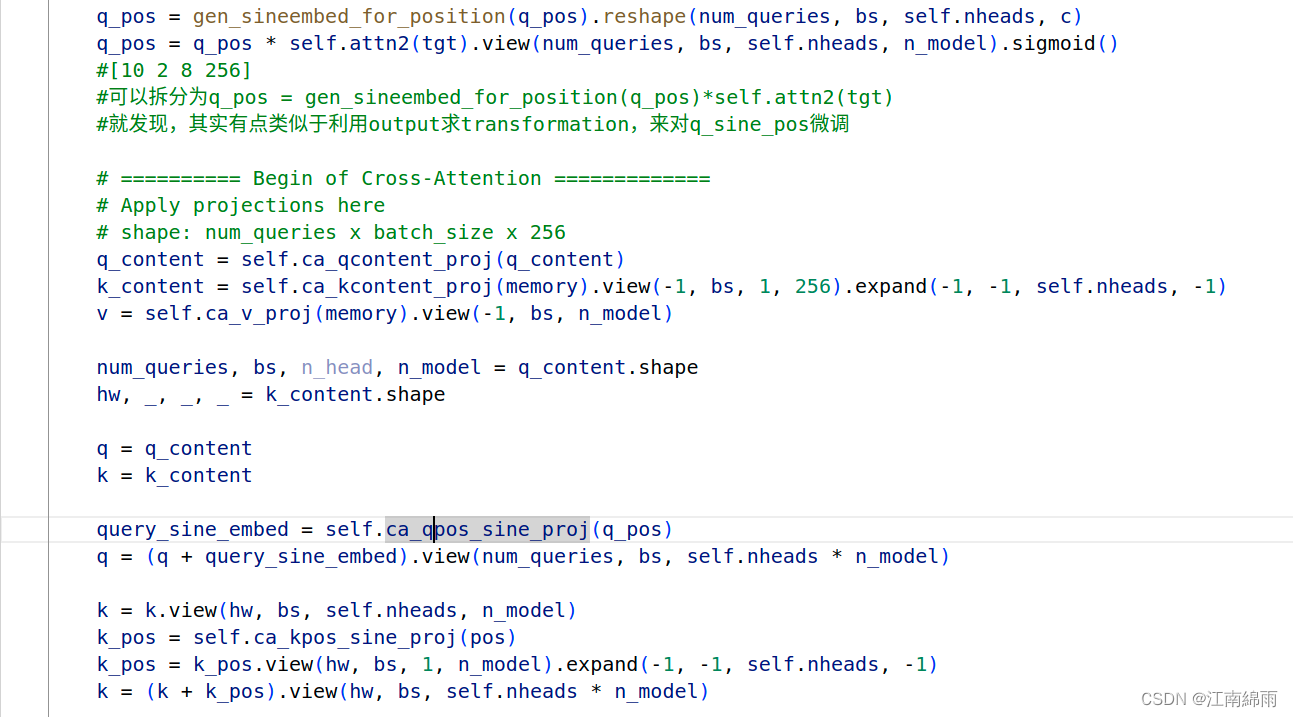
再看看q_pos的构成,这里我觉得很巧妙,每个anchor_box中不是采样了num_heads个点吗,这时利用原reference_points和采样的points结合成全新的q_pos,可以理解为每一个显著点都生成了一个obj_centers,由原来的[10 2 2]变为了[10 2 8 2],妙不可言! 然后再对新的obj_centers生成query_sine_pos,同时利用了tgt生成transformation矩阵微调query_sine_pos,完全效仿Conditional-DETR。
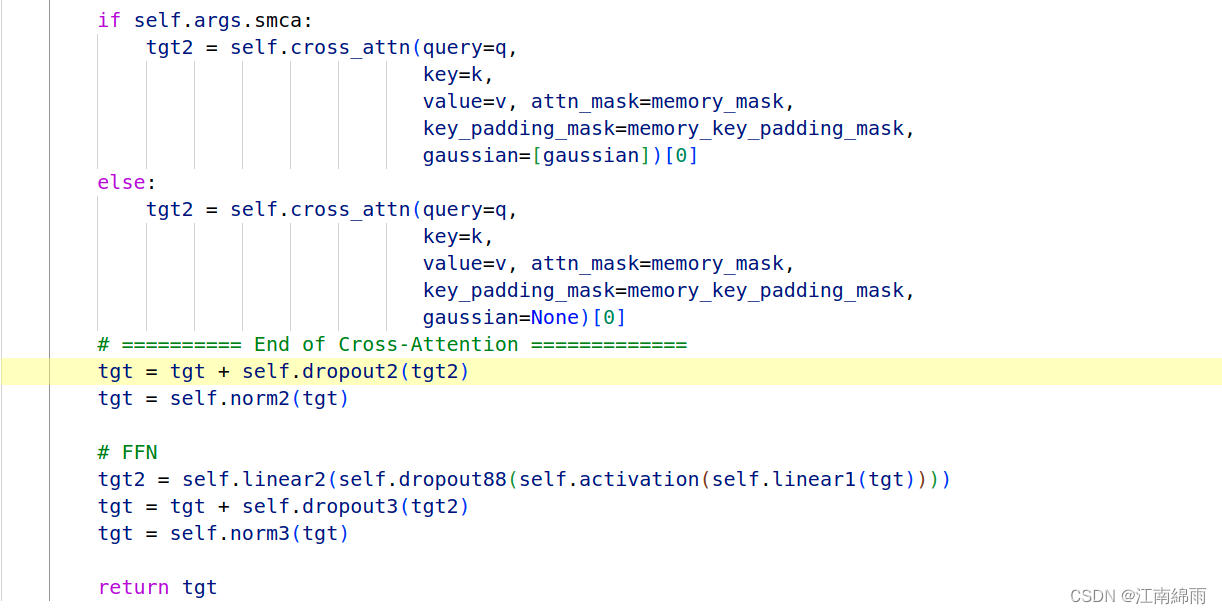
别的就不讲了,传入cross_attn中的q和k是8✖256维的,v是256维,稍微注意一下,这也是8个显著点结合在一起组成q和k的体现。
至此我对SAM-DETR源码中全部的流程与细节,进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!
-
相关阅读:
使用老北鼻CharGPT对话查询 Qt/C++ 使用gumbo-parse解析加载的html全过程
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
DOM property 和 attribute 的区别
Qt 把.exe打包成安装文件形式
java-php-python-ssm写手管理平台计算机毕业设计
工具链 之 Vite 开发服务器所有选项解析(三)
K8S 证书替换
apollo学习之:如何测试canbus模块
MacOS通过命令行开启关闭向日葵远程控制的后台服务
【译】.NET 7 中的性能改进(十三)
- 原文地址:https://blog.csdn.net/weixin_43702653/article/details/126404646