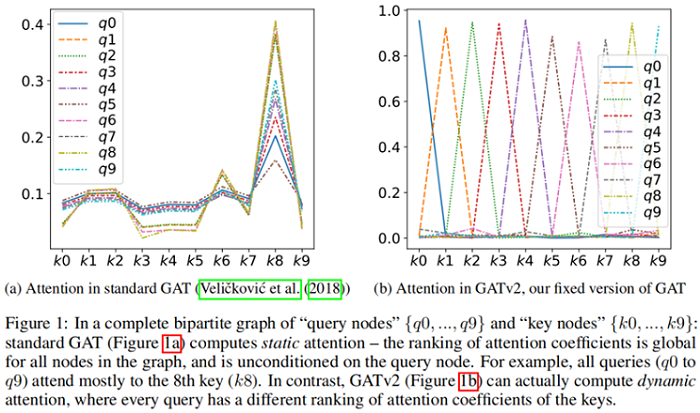
Definition 3.1 (Static attention). A (possibly infinite) family of scoring functions F⊆(Rd×Rd→R)" role="presentation">F⊆(Rd×Rd→R) computes static scoring for a given set of key vectors K={k1,…,kn}⊂Rd" role="presentation">K={k1,…,kn}⊂Rd and query vectors Q={q1,…,qm}⊂Rd" role="presentation">Q={q1,…,qm}⊂Rd , if for every f∈F" role="presentation">f∈F there exists a "highest scoring" key jf∈[n]" role="presentation">jf∈[n] such that for every query i∈[m]" role="presentation">i∈[m] and key j∈[n]" role="presentation">j∈[n] it holds that f(qi,kjf)≥f(qi,kj)" role="presentation">f(qi,kjf)≥f(qi,kj) . We say that a family of attention functions computes static attention given K" role="presentation">K and Q" role="presentation">Q , if its scoring function computes static scoring, possibly followed by monotonic normalization such as softmax.
对动态注意力机制的定义:
Definition 3.2 (Dynamic attention). A (possibly infinite) family of scoring functions F⊆(Rd×Rd→R)" role="presentation">F⊆(Rd×Rd→R) computes dynamic scoring for a given set of key vectors K={k1,…,kn}⊂Rd" role="presentation">K={k1,…,kn}⊂Rd and query vectors Q={q1,…,qm}⊂Rd" role="presentation">Q={q1,…,qm}⊂Rd , if for any mapping φ:[m]→[n]" role="presentation">φ:[m]→[n] there exists f∈F" role="presentation">f∈F such that for any query i∈[m]" role="presentation">i∈[m] and any key j≠φ(i)∈[n]:f(qi,kφ(i))>f(qi,kj)" role="presentation">j≠φ(i)∈[n]:f(qi,kφ(i))>f(qi,kj) . We say that a family of attention functions computes dynamic attention for K" role="presentation">K and Q" role="presentation">Q , if its scoring function computes dynamic scoring, possibly followed by monotonic normalization such as softmax.
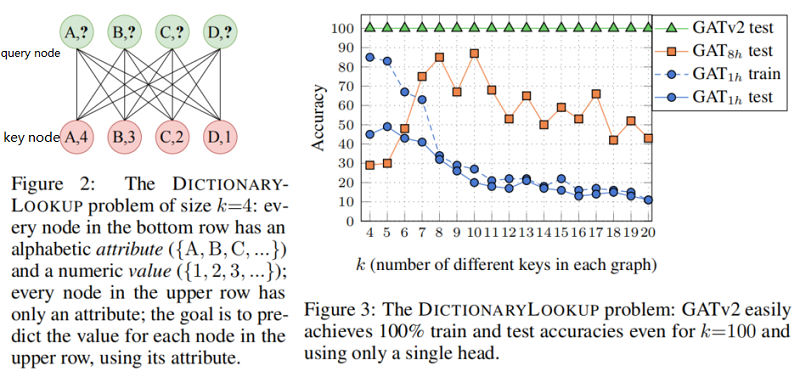
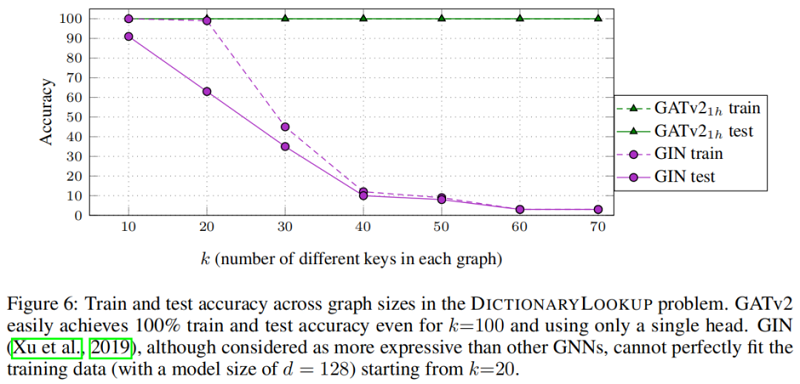
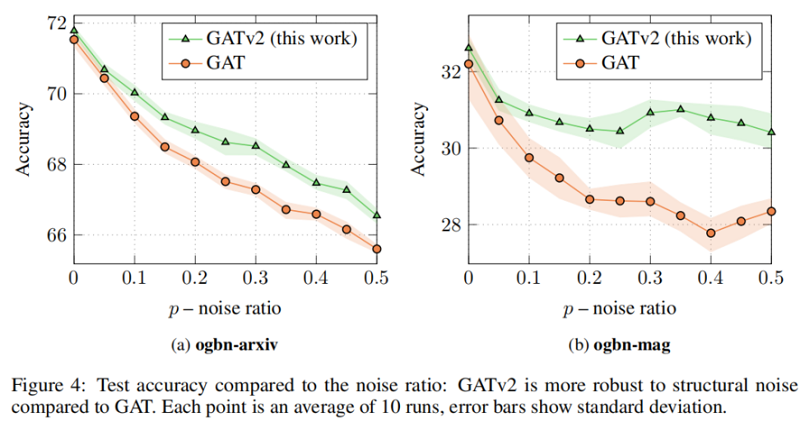
Theorem 1. A GAT layer computes only static attention, for any set of node representations K=Q={h1,…,hn}" role="presentation">K=Q={h1,…,hn} . In particular, for n>1" role="presentation">n>1 , a GAT layer does not compute dynamic attention.