-
神经网络(三)分类器与线性模型
一、线性分类
线性分类器:属于监督学习
1.线性分类模型


 称判别函数,因其由一根直线将平面划分成两份,所以称线性分类模型
称判别函数,因其由一根直线将平面划分成两份,所以称线性分类模型
线性分类模型 = 线性判别函数 + 线性决策边界
2.二分类问题
①模型

②损失函数
0-1损失函数:
 (判定是否正确,但是不能求导)
(判定是否正确,但是不能求导)3.多分类问题
①模型

a)一对其余:转换为多个二分类。有几类需要构建几种分类器,但是交叉区域可能才出现未知。
b)一对一:每两个类之间建立分类器(
 个分类器),采用投票的方式决定分类。同样存在不明的交叉区域(略小),且对于多中分类过于复杂。
个分类器),采用投票的方式决定分类。同样存在不明的交叉区域(略小),且对于多中分类过于复杂。c)argmax:对一对其余的改进,由其在各区域得分作为分类依据(分数最高)
预测函数:

二、交叉熵与对数似然
1.交叉熵
熵:用以衡量一个随机事件的不确定性,熵↑,随机信息越多(干扰信息)
自信息:一个随机时间包含的信息量 I(x) =-log p(x)
熵可以描述为:随机变量X的自信息的数学期望
其分布为:
![H(X)=E_X[-log p(x)]=-\sum_{x\in X}p(x)logp(x)](https://1000bd.com/contentImg/2022/08/19/084433203.gif)
熵编码:在对分布p(y)的符号进行编码时,熵H(p)也是理论上最优的平均编码长度
交叉熵:按照概率分布q的最优编码对真实分布为p的信息进行编码的长度。
![H(p,q)=E_p[-logq(x)]=-\sum_xp(x)logq(x)](https://1000bd.com/contentImg/2022/08/19/084434000.gif)
在给定q的情况下,若p和q越接近,交叉熵越小
KL散度:用概率分布q来近似p时所造成的信息损失量

2.对数似然
交叉熵在机器学习的应用
真实分布
 预测分布
预测分布
 KL散度
KL散度 交叉熵损失
交叉熵损失 负对数似然
负对数似然三、Logistic回归
①模型

②损失函数
将分类问题看作条件概率估计问题,通过引入激活函数g,将线性函数f转换为概率
以二分类为例,问题将会变为估测两个概率
 和
和
激活函数g:将线性函数的值域挤压到(0,1)之间,以表示概率。
③Logistic函数

Logistic回归:

④学习准则
预测条件概率:

真实条件概率:


交叉熵:

梯度下降:
风险函数:
 交叉熵的平均值的负数
交叉熵的平均值的负数梯度:对风险函数求导->

迭代更新:


四、Softmax回归
应用于多分类问题
①模型

②学习准则
转换为条件概率建模:

③Softnax函数
对于K个标量x1,...xk


④Softmax回归


向量表示:

⑤交叉熵损失

向量表示:

⑥学习准则
风险函数:

梯度下降:

五、感知器
①模型
模拟生物神经元行为,包含权重(突出)、偏置(阈值)、激活函数(细胞体),输出结果为+1或-1


类似于Logistic函数
②学习目标
找到权重
 使得
使得 
③学习方法
错误驱动的在线学习算法。
1.初始化一个权重向量w<-0(一般为零向量)
2.每次分错一个样本(x,y)时,即
 ,则使用这个样本来更新权重
,则使用这个样本来更新权重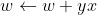
④损失函数
由错误驱动的在线学习算法反推得到
 (不更新时为0)
(不更新时为0)
⑤学习过程


⑥收敛性
对于给定的训练集D且线性可分,令R是训练集中最大的特征向量的模,即
 ,感知器使用错误驱动在线学习算法时权重更新次数不超过
,感知器使用错误驱动在线学习算法时权重更新次数不超过
六、支持向量机
①最大间隔
间隔:决策边界到分类样本的最短距离

②支持向量机
点
 到超平面的距离:
到超平面的距离:
支持向量机的目的是寻找一个超平面使得
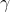 最大
最大
③软间隔
为了容忍部分不满足约束的样本,可以引入松弛变量
原式:

转换为:

④损失函数

七、小结

-
相关阅读:
淘宝API接口介绍
mysql日常优化的总结
Linux驱动开发(十四)---USB驱动开发学习(键盘+鼠标)
springAOP和AspectJ有关系吗?如何使用springAOP面向切面编程
C //例5.11 译密码。为使电文保密,往往按一定规律将其转换成密码,收报人再按约定的规律将其译回原文。
数据结构与算法基础(王卓)(5)
PMP每日一练 | 考试不迷路-8.17(包含敏捷+多选)
最成熟的前端换肤方案
【C++】STL简介(了解)
1个月时间整理了2019年上千道Java面试题,近500页文档!
- 原文地址:https://blog.csdn.net/weixin_37878740/article/details/126378495