-
Springboot整合Elasticsearch
1.创建工程

目录结构
2.导入依赖
注意依赖版本和安装的版本一致- <properties>
- <java.version>1.8java.version>
- <elasticsearch.version>7.6.1elasticsearch.version>
- properties>
- <dependencies>
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-data-elasticsearchartifactId>
- dependency>
- <dependency>
- <groupId>com.alibabagroupId>
- <artifactId>fastjsonartifactId>
- <version>1.2.80version>
- dependency>
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-webartifactId>
- dependency>
- <dependency>
- <groupId>org.projectlombokgroupId>
- <artifactId>lombokartifactId>
- <optional>trueoptional>
- dependency>
- <dependency>
- <groupId>org.springframework.bootgroupId>
- <artifactId>spring-boot-starter-testartifactId>
- <scope>testscope>
- dependency>
- dependencies>
3.创建并编写配置类
- package com.wzh.config;
- import org.apache.http.HttpHost;
- import org.elasticsearch.client.RestClient;
- import org.elasticsearch.client.RestHighLevelClient;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
- /**
- * @ProjectName: Elasticsearch
- * @Package: com.wzh.config
- * @ClassName: ElasticSearchConfig
- * @Author: 王振华
- * @Description:
- * @Date: 2022/8/16 18:21
- * @Version: 1.0
- */
- @Configuration
- public class ElasticSearchConfig {
- //该对象可以对我们的ES进行相关的操作
- @Bean
- public RestHighLevelClient restHighLevelClient(){
- RestHighLevelClient client = new RestHighLevelClient(
- RestClient.builder(new HttpHost("127.0.0.1",9200,"http")));
- return client;
- }
- }
4.创建并编写实体类
- package com.wzh.entity;
- import lombok.AllArgsConstructor;
- import lombok.Data;
- import lombok.NoArgsConstructor;
- /**
- * @ProjectName: Elasticsearch
- * @Package: com.wzh.entity
- * @ClassName: User
- * @Author: 王振华
- * @Description:
- * @Date: 2022/8/16 18:23
- * @Version: 1.0
- */
- @Data
- @NoArgsConstructor
- @AllArgsConstructor
- public class User {
- private String name;
- private String address;
- private Integer age;
- }
5、测试
所有测试均在ElasticsearchApplicationTests 中编写注入 RestHighLevelClient- //@Autowired
- //直接将@Autowired换成@Resource注解,此注解是JDK中的注解,不会向@Autowired那样去Spring容器中寻找bean。
- @Resource
- public RestHighLevelClient client;
5.1 索引的操作
5.1.1 创建索引
- //创建索引 PUT /索引名称
- @Test
- public void testCreateIndex() throws IOException {
- //该类把创建索引的信息都封装到该类中
- CreateIndexRequest createIndexRequest = new CreateIndexRequest("test-index");
- CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
- System.out.println(createIndexResponse.isAcknowledged());//查看是否创建成功
- client.close();
- }
5.1.2 判断索引是否存在
- //判断索引是否存在
- @Test
- public void testIndexExists() throws IOException {
- GetIndexRequest getIndexRequest = new GetIndexRequest("test-index");
- boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
- System.out.println(exists);
- client.close();
- }
5.1.3 删除索引
- //删除索引
- @Test
- public void testDeleteIndex() throws IOException {
- DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("test-index");
- AcknowledgedResponse delete = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
- System.out.println(delete.isAcknowledged());
- client.close();
- }
5.2 文档的操作
5.2.1 添加文档
- //添加文档 PUT /索引/1 {name:"",age:"",address:""}
- @Test
- public void testInsertDoc() throws IOException {
- IndexRequest indexRequest = new IndexRequest("test-index");
- indexRequest.id("2"); //指定文档的id,不写则随机生成
- //指定文档的内容:String文档的json内容,XContentType xContentType:以什么格式
- indexRequest.source(JSON.toJSONString(new User("张三","郑州",22)), XContentType.JSON);
- IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
- System.out.println(indexResponse.getResult());
- client.close();
- }
5.2.2 判断文档是否存在
- //判断文档是否存在
- @Test
- public void testDocExist() throws IOException {
- GetRequest getRequest = new GetRequest("test-index");
- getRequest.id("2");
- boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
- System.out.println(exists);
- }
5.2.3 根据id查询文档
- //根据id查询文档
- @Test
- public void testGetDoc() throws IOException {
- GetRequest getRequest = new GetRequest("test-index");
- getRequest.id("2");
- GetResponse response = client.get(getRequest, RequestOptions.DEFAULT);
- String source = response.getSourceAsString();//转为字符串
- User user = JSON.parseObject(source, User.class); //转为Java对象
- System.out.println(user.getAddress());
- Map
- System.out.println(map.get("address"));
- client.close();
- }
5.2.4 删除文档
- //删除文档
- @Test
- public void testDeleteDoc() throws IOException {
- DeleteRequest deleteRequest = new DeleteRequest("test-index");
- deleteRequest.id("1");
- DeleteResponse delete = client.delete(deleteRequest, RequestOptions.DEFAULT);
- System.out.println(delete.getResult());
- client.close();
- }
5.2.5 修改文档(1条消息) com.alibaba.fastjson.JSONObject之对象与JSON转换方法_beidaol的博客-CSDN博客_com.alibaba.fastjson.jsonobject
 https://blog.csdn.net/beidaol/article/details/104491950
https://blog.csdn.net/beidaol/article/details/104491950- //修改文档
- // POST /test01/_doc/2/_update
- //{
- // "doc":{
- // "name":"周星驰"
- // }
- //}
- @Test
- public void testUpdateDoc() throws IOException {
- UpdateRequest updateRequest = new UpdateRequest("test-index","2");
- User user = new User();
- user.setName("李四");
- //updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
- updateRequest.doc((JSONObject)JSONObject.toJSON(user));
- UpdateResponse update = client.update(updateRequest, RequestOptions.DEFAULT);
- System.out.println(update.getResult());
- client.close();
- }
5.2.6 批量添加文档
- //批量添加文档
- @Test
- public void testBulkDoc() throws IOException {
- BulkRequest bulkRequest = new BulkRequest("test-index");
- List
list = new ArrayList<>(); - list.add(new User("张三","上海",21));
- list.add(new User("李四","浙江",22));
- list.add(new User("王五","深圳",23));
- list.add(new User("赵六","北京",24));
- list.add(new User("孙七","南京",25));
- /* for(User user:list){
- IndexRequest indexRequest=new IndexRequest();
- indexRequest.source(JSON.toJSONString(user),XContentType.JSON);
- bulkRequest.add(indexRequest);
- }*/
- //(JSONObject)JSONObject.toJSON(item) java对象转为json对象
- list.stream().forEach(item->bulkRequest.add(new IndexRequest().source((JSONObject)JSONObject.toJSON(item))));
- BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
- System.out.println(bulkResponse.hasFailures());
- client.close();
- }
5.2.7 复杂查询
- //复杂查询 -GET /索引/_search
- // {
- // "query":{
- // "":{}
- // },
- // "from":
- // "size":
- // "_source":["",""],
- // "sort":{}
- // }
- //1. 搜索请求对象SearchRequest
- //2. 构建一个条件对象SearchSourceBuilder
- //3. 把条件对象放入搜索请求对象中
- //4. 执行搜索功能
- @Test
- public void testSearch() throws IOException {
- // 1.创建查询请求对象
- SearchRequest searchRequest = new SearchRequest("test-index");
- // 2.创建一个条件对象
- SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
- // (1)查询条件 使用QueryBuilders工具类创建
- //匹配查询
- //MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("name", "张 ");
- //精准查询
- TermQueryBuilder queryBuilder = QueryBuilders.termQuery("name", "张");
- // 条件投入
- sourceBuilder.query(queryBuilder);
- // (2)其他<可有可无>:(可以参考 SearchSourceBuilder 的 字段部分)
- //分页
- sourceBuilder.from(0);
- sourceBuilder.size(1);
- //排序
- sourceBuilder.sort("age", SortOrder.ASC);
- //高亮显示
- HighlightBuilder highlightBuilder = new HighlightBuilder();
- highlightBuilder.field("name");
- highlightBuilder.preTags("");
- highlightBuilder.postTags("");
- sourceBuilder.highlighter(highlightBuilder);
- //3. 把条件对象放入搜索请求对象中
- searchRequest.source(sourceBuilder);
- //4. 执行搜索功能
- SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
- System.out.println("总条数:"+search.getHits().getTotalHits().value);
- SearchHit[] hits = search.getHits().getHits();
- Arrays.stream(hits).forEach(item-> System.out.println(item.getSourceAsString()));
- Arrays.stream(hits).forEach(item-> System.out.println(item.getHighlightFields()));
- client.close();
- }
多条件查找
- //多条件查询
- @Test
- public void testSearch02() throws IOException {
- SearchRequest searchRequest = new SearchRequest("qy151-index");
- //创建一个条件对象
- SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
- BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "李 "))
- .should(QueryBuilders.termQuery("name", "三"));
- sourceBuilder.query(queryBuilder);
- //把条件对象放入搜索请求对象中
- searchRequest.source(sourceBuilder);
- SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
- SearchHit[] hits = search.getHits().getHits();
- Arrays.stream(hits).forEach(item-> System.out.println(item.getSourceAsMap()));
- client.close();
- }
6.IK分词器:中文分词器
6.1 什么是IK分词器
ElasticSearch 几种常用分词器如下:
分词器 分词方式 StandardAnalyzer 单字分词 CJKAnalyzer 二分法 IKAnalyzer 词库分词 分词∶即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱中国"会被分为"我""爱""中""国”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik smart为最少切分,ik_max_word为最细粒度划分!
ik_max_word: 会将文本做最细粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌",会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,国歌"。
6.2 Ik分词器的下载安装
注意:IK分词器插件的版本要和ElasticSearch的版本一致

下载完后,解压安装包到 ElasticSearch 所在文件夹中的plugins目录中:

再启动ElasticSearch,查看IK分词器插件是否安装成功:
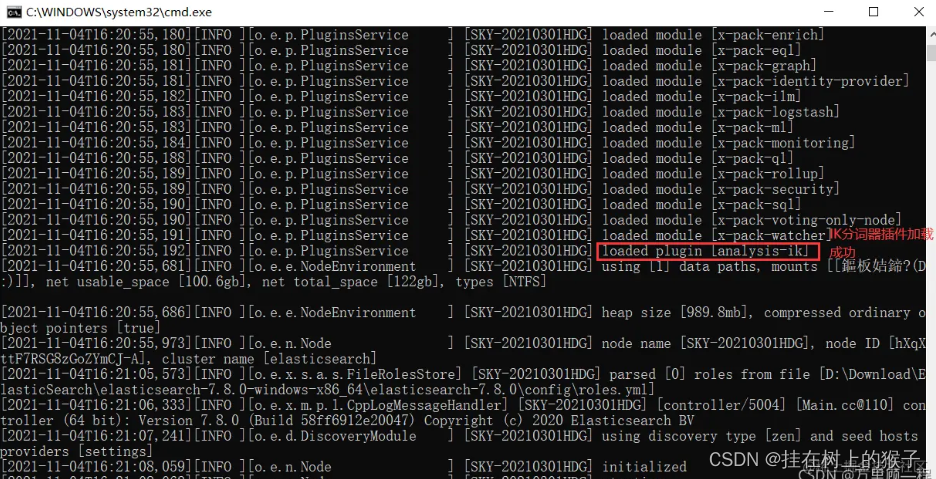
安装成功!
6.3 使用Kibana测试IK
1、启动Kibana
2、访问请求:http://localhost:5601/
3、选择开发工具Dev Tools,点击控制台

4、在控制台编写分词请求,进行测试
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik smart为最少切分,ik_max_word为最细粒度划分!
测试 ik_smart 分词算法,最少切分:
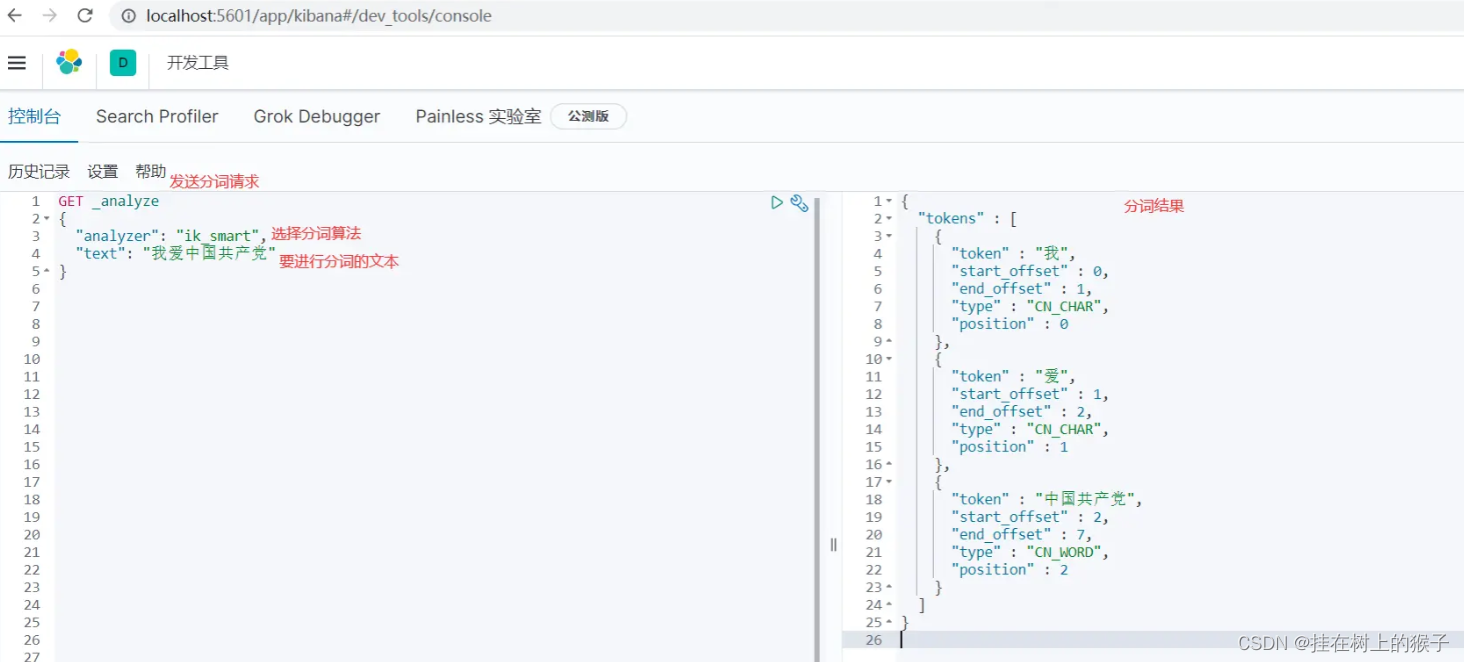
测试 ik_max_word 分词算法,最细粒度划分:
分词请求:
- GET _analyze
- {
- "analyzer": "ik_max_word",
- "text": "我爱中国共产党"
- }
分词结果:
- {
- "tokens" : [
- {
- "token" : "我",
- "start_offset" : 0,
- "end_offset" : 1,
- "type" : "CN_CHAR",
- "position" : 0
- },
- {
- "token" : "爱",
- "start_offset" : 1,
- "end_offset" : 2,
- "type" : "CN_CHAR",
- "position" : 1
- },
- {
- "token" : "中国共产党",
- "start_offset" : 2,
- "end_offset" : 7,
- "type" : "CN_WORD",
- "position" : 2
- },
- {
- "token" : "中国",
- "start_offset" : 2,
- "end_offset" : 4,
- "type" : "CN_WORD",
- "position" : 3
- },
- {
- "token" : "国共",
- "start_offset" : 3,
- "end_offset" : 5,
- "type" : "CN_WORD",
- "position" : 4
- },
- {
- "token" : "共产党",
- "start_offset" : 4,
- "end_offset" : 7,
- "type" : "CN_WORD",
- "position" : 5
- },
- {
- "token" : "共产",
- "start_offset" : 4,
- "end_offset" : 6,
- "type" : "CN_WORD",
- "position" : 6
- },
- {
- "token" : "党",
- "start_offset" : 6,
- "end_offset" : 7,
- "type" : "CN_CHAR",
- "position" : 7
- }
- ]
- }
比较两个分词算法对同一句中文的分词结果,ik_max_word比ik_smart得到的中文词更多(从两者的英文名含义就可看出来),但这样也带来一个问题,使用ik_max_word会占用更多的存储空间。
6.4 扩展字典
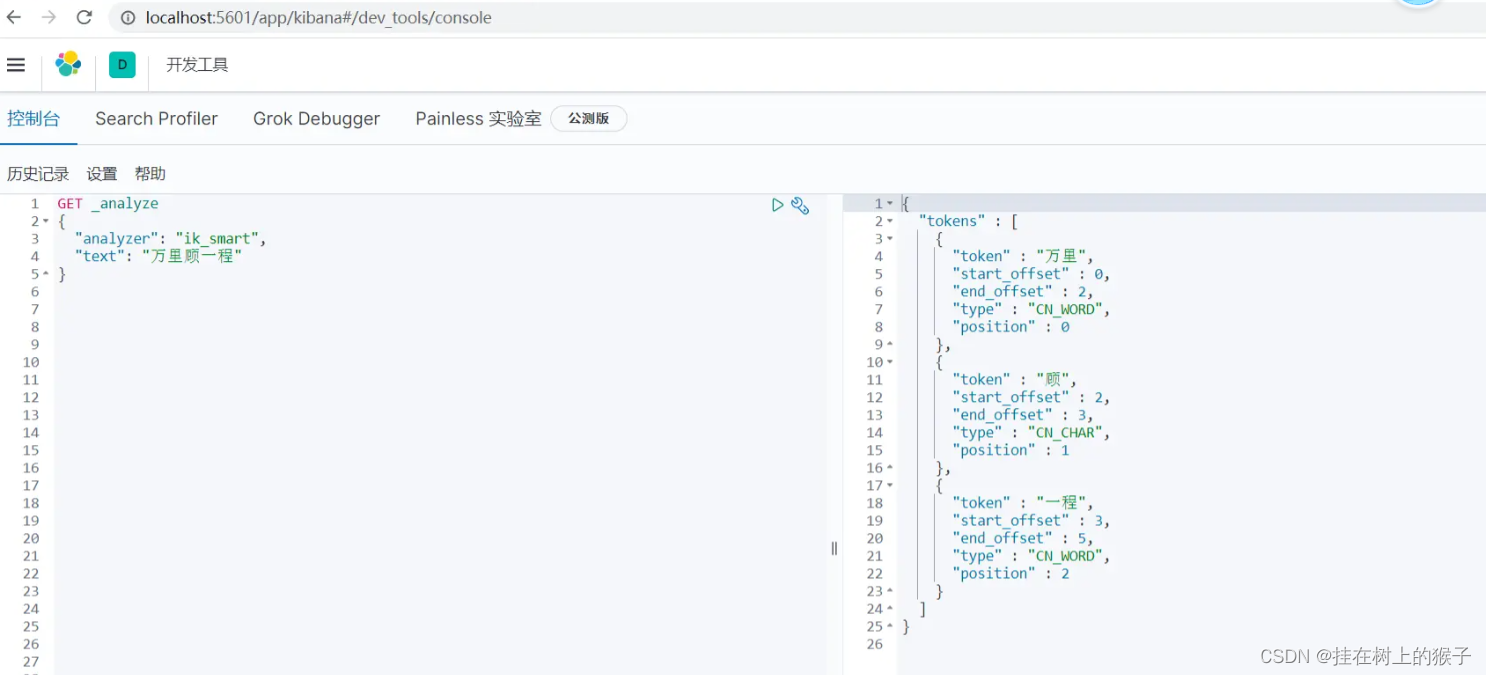
我们用分词器对 “万里顾一程” 进行分词:先使用 ik_smart 分词算法
在使用 ik_max_word分词算法,进行细粒度的划分:
- GET _analyze
- {
- "analyzer": "ik_max_word",
- "text": "万里顾一程"
- }
分词结果:
- {
- "tokens" : [
- {
- "token" : "万里",
- "start_offset" : 0,
- "end_offset" : 2,
- "type" : "CN_WORD",
- "position" : 0
- },
- {
- "token" : "万",
- "start_offset" : 0,
- "end_offset" : 1,
- "type" : "TYPE_CNUM",
- "position" : 1
- },
- {
- "token" : "里",
- "start_offset" : 1,
- "end_offset" : 2,
- "type" : "COUNT",
- "position" : 2
- },
- {
- "token" : "顾",
- "start_offset" : 2,
- "end_offset" : 3,
- "type" : "CN_CHAR",
- "position" : 3
- },
- {
- "token" : "一程",
- "start_offset" : 3,
- "end_offset" : 5,
- "type" : "CN_WORD",
- "position" : 4
- },
- {
- "token" : "一",
- "start_offset" : 3,
- "end_offset" : 4,
- "type" : "TYPE_CNUM",
- "position" : 5
- },
- {
- "token" : "程",
- "start_offset" : 4,
- "end_offset" : 5,
- "type" : "CN_CHAR",
- "position" : 6
- }
- ]
- }
使用上面两种分词算法后,发现 “万里顾一程”被分成了“万里”、“顾”、“一程”,这是因为在IK自带的字典中没有“顾一程”这个词,如果想得到“顾一程”这个词,怎么办呢?
这就要配置自己的扩展字典了,就是在IK分词器字典中加入我们自定义的字典,在词典中加入想要的词。
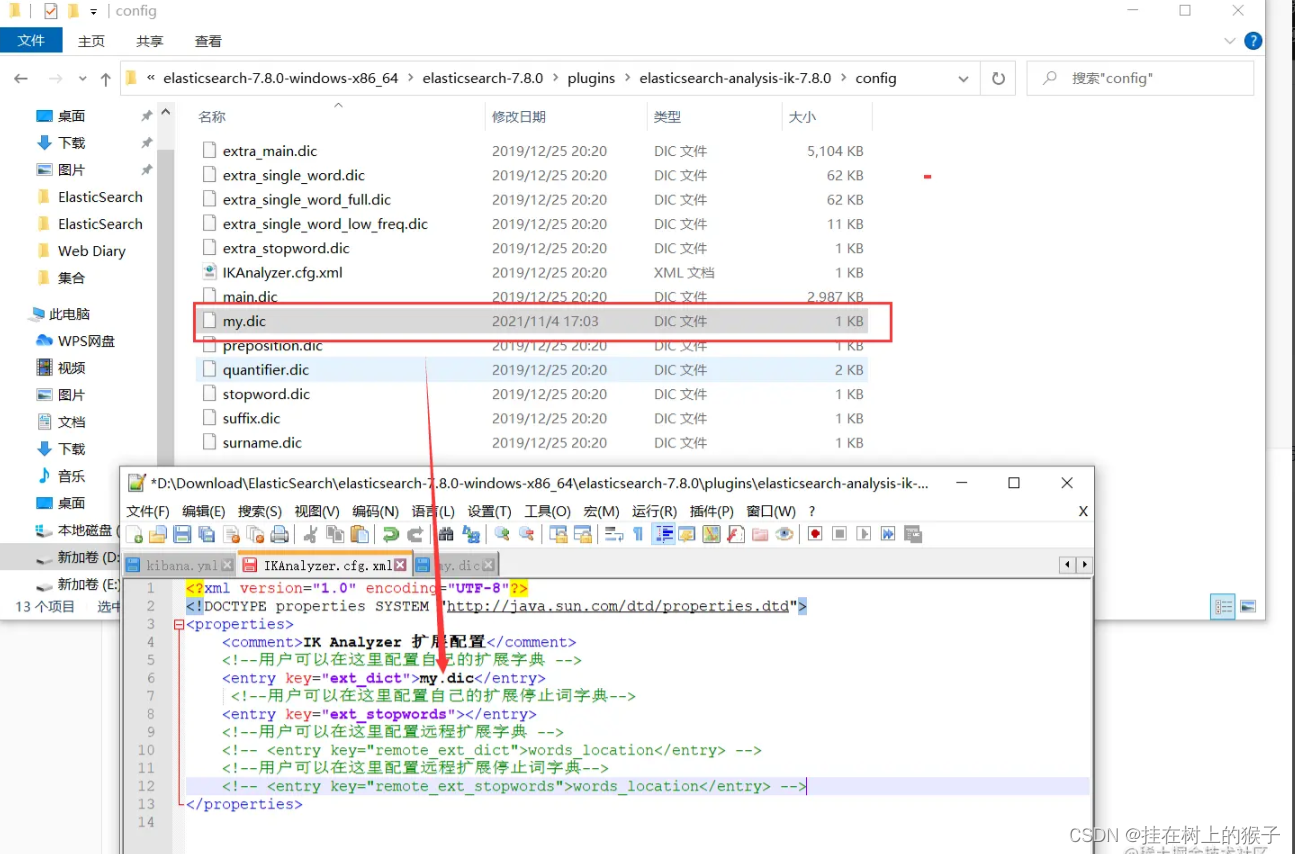
在ik分词器文件的config目录中新建自定义的字典文件,以.dic为后缀,并在文件中加入“顾一程”:

然后打开 IKAnalyzer.cfg.xml 文件,把自定义的字典添加到IK的字典中:
 重启ES和Kibana,再用分词器对 “万里顾一程” 进行分词:此时“顾一程”就是一个词了。
重启ES和Kibana,再用分词器对 “万里顾一程” 进行分词:此时“顾一程”就是一个词了。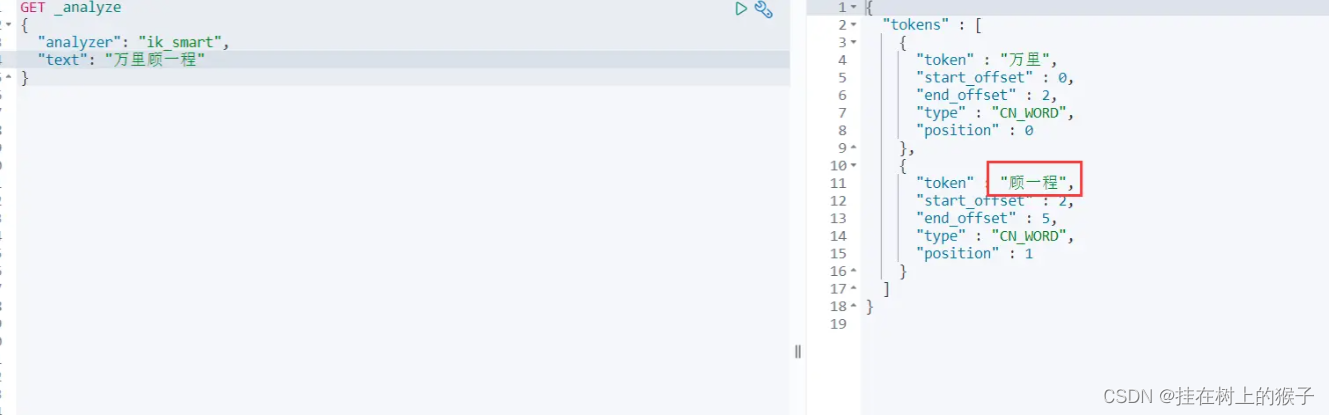
7. 综合案例---京东搜索
7.1 创建springboot项目
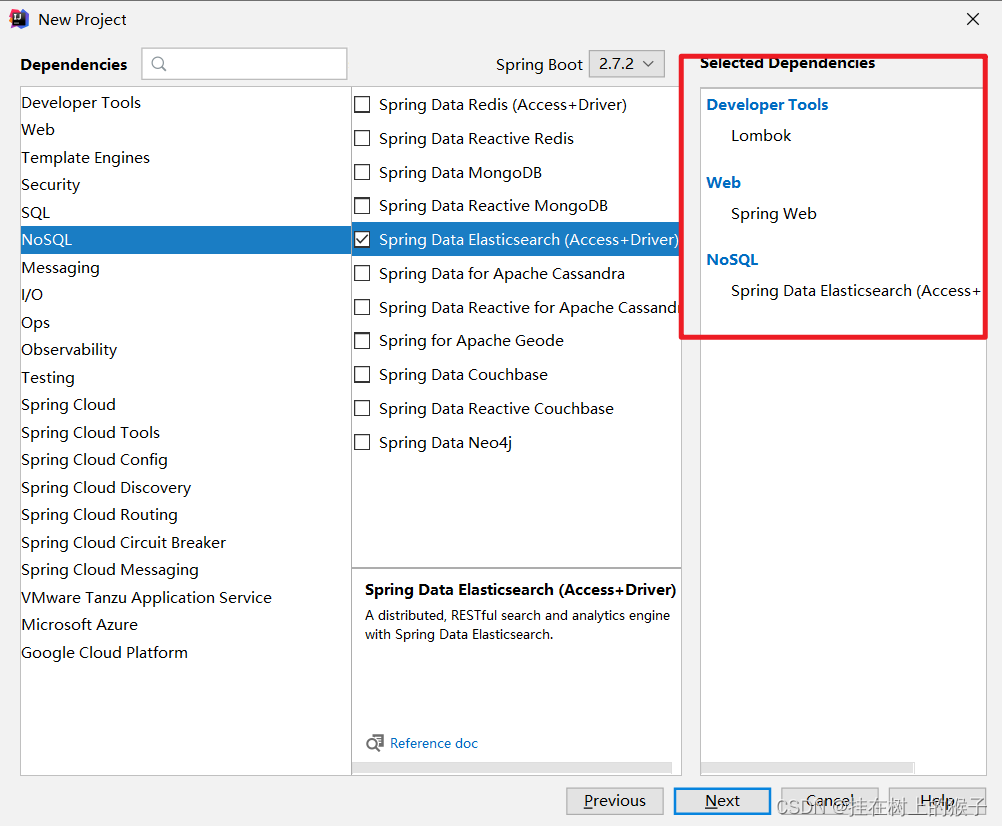
7.2 引入依赖
jsoup是一款Java的html解析工具,主要是对html和xml文件进行解析
在写爬虫的时候,当我们用HttpClient之类的框架,得到目标网页的源码后,需要从网页源码中取得我们想要的内容。就可以使用jsoup轻松获取想要的内容。- <dependency>
- <groupId>org.jsoupgroupId>
- <artifactId>jsoupartifactId>
- <version>1.11.3version>
- dependency>
7.3 创建实体类
- package com.wzh.entity;
- import lombok.AllArgsConstructor;
- import lombok.Data;
- import lombok.NoArgsConstructor;
- /**
- * @ProjectName: jd-ES
- * @Package: com.wzh.entity
- * @ClassName: Product
- * @Author: 王振华
- * @Description:
- * @Date: 2022/8/16 20:23
- * @Version: 1.0
- */
- @Data
- @NoArgsConstructor
- @AllArgsConstructor
- public class Product {
- private String title;
- private String price;
- private String imgUrl;
- }
7.4 创建公共类
- <div id="header" class=" header-list-app">
- <div class="headerLayout">
- <div class="headerCon ">
- <h1 id="mallLogo">
- <img src="../assets/jd.png" alt="">
- h1>
- <div class="header-extra">
- <div id="mallSearch" class="mall-search">
- <form name="searchTop" class="mallSearch-form clearfix">
- <fieldset>
- <legend>天猫搜索legend>
- <div class="mallSearch-input clearfix">
- <div class="s-combobox" id="s-combobox-685">
- <div class="s-combobox-input-wrap">
- <input v-model="keyword" type="text" autocomplete="off" id="mq"
- class="s-combobox-input" aria-haspopup="true">
- div>
- div>
- <button type="submit" @click.prevent="searchKey" id="searchbtn">搜索button>
- div>
- fieldset>
- form>
- <ul class="relKeyTop">
- <li><a>老闫说Javaa>li>
- <li><a>老闫说前端a>li>
- <li><a>老闫说Linuxa>li>
- <li><a>老闫说大数据a>li>
- <li><a>老闫聊理财a>li>
- ul>
- div>
- div>
- div>
- div>
- div>
- <div id="content">
- <div class="main">
- <form class="navAttrsForm">
- <div class="attrs j_NavAttrs" style="display:block">
- <div class="brandAttr j_nav_brand">
- <div class="j_Brand attr">
- <div class="attrKey">
- 品牌
- div>
- <div class="attrValues">
- <ul class="av-collapse row-2">
- <li><a href="#"> 老闫说 a>li>
- <li><a href="#"> Java a>li>
- ul>
- div>
- div>
- div>
- div>
- form>
- <div class="filter clearfix">
- <a class="fSort fSort-cur">综合<i class="f-ico-arrow-d">i>a>
- <a class="fSort">人气<i class="f-ico-arrow-d">i>a>
- <a class="fSort">新品<i class="f-ico-arrow-d">i>a>
- <a class="fSort">销量<i class="f-ico-arrow-d">i>a>
- <a class="fSort">价格<i class="f-ico-triangle-mt">i><i class="f-ico-triangle-mb">i>a>
- div>
- <div class="view grid-nosku" >
- <div class="product" v-for="item in results">
- <div class="product-iWrap">
- <div class="productImg-wrap">
- <a class="productImg">
- <img :src="item.imgUrl">
- a>
- div>
- <p class="productPrice">
- <em>{{item.price}}em>
- p>
- <p class="productTitle">
- <a v-html="item.title"> a>
- p>
- <div class="productShop">
- <span>店铺: 老闫说Java span>
- div>
- <p class="productStatus">
- <span>月成交<em>999笔em>span>
- <span>评价 <a>3a>span>
- p>
- div>
- div>
- div>
- <el-pagination
- @size-change="handleSizeChange"
- @current-change="handleCurrentChange"
- :current-page="currentPage"
- :page-sizes="pageSizes"
- :page-size="pageSize"
- layout="total, sizes, prev, pager, next, jumper"
- :total="total">
- el-pagination>
- div>
- div>
- div>
- div>
- template>
- <script>
- export default {
- name: "jd",
- data(){
- return {
- keyword: '', // 搜索的关键字
- results:[], // 后端返回的结果
- currentPage:1,
- pageSizes:[10,20,30,40],
- pageSize:10,
- total:0,
- }
- },
- methods:{
- searchKey(){
- var keyword = this.keyword;
- this.$http.get('/product/search/'+keyword+"/"+this.currentPage+"/"+this.pageSize).then(response=>{
- //console.log(response.data.result);
- this.results=response.data.result.result;
- this.total=response.data.result.total;
- })
- },
- handleSizeChange(val) {
- this.pageSize = val;
- this.searchKey();
- },
- handleCurrentChange(val) {
- this.currentPage=val;
- this.searchKey();
- }
- }
- }
- script>
- <style>
- /*** uncss> filename: http://localhost:9090/css/global.css ***/body,button,fieldset,form,h1,input,legend,li,p,ul{margin:0;padding:0}body,button,input{font:12px/1.5 tahoma,arial,"\5b8b\4f53";-ms-overflow-style:scrollbar}button,h1,input{font-size:100%}em{font-style:normal}ul{list-style:none}a{text-decoration:none}a:hover{text-decoration:underline}legend{color:#000}fieldset,img{border:0}#content,#header{margin-left:auto;margin-right:auto}html{zoom:expression(function(ele){ ele.style.zoom = "1"; document.execCommand("BackgroundImageCache", false, true); }(this))}@font-face{font-family:mui-global-iconfont;src:url(//at.alicdn.com/t/font_1401963178_8135476.eot);src:url(//at.alicdn.com/t/font_1401963178_8135476.eot?#iefix) format('embedded-opentype'),url(//at.alicdn.com/t/font_1401963178_8135476.woff) format('woff'),url(//at.alicdn.com/t/font_1401963178_8135476.ttf) format('truetype'),url(//at.alicdn.com/t/font_1401963178_8135476.svg#iconfont) format('svg')}#mallPage{width:auto;min-width:990px;background-color:transparent}#content{width:990px;margin:auto}#mallLogo{float:left;z-index:9;padding-top:28px;width:280px;height:64px;line-height:64px;position:relative}.page-not-market #mallLogo{width:400px}.clearfix:after,.clearfix:before,.headerCon:after,.headerCon:before{display:table;content:"";overflow:hidden}#mallSearch legend{display:none}.clearfix:after,.headerCon:after{clear:both}.clearfix,.headerCon{zoom:1}#mallPage #header{margin-top:-30px;width:auto;margin-bottom:0;min-width:990px;background:#fff}#header{height:122px;margin-top:-26px!important;background:#fff;min-width:990px;width:auto!important;position:relative;z-index:1000}#mallSearch #mq,#mallSearch fieldset,.mallSearch-input{position:relative}.headerLayout{width:990px;padding-top:26px;margin:0 auto}.header-extra{overflow:hidden}#mallSearch{float:right;padding-top:25px;width:390px;overflow:hidden}.mallSearch-form{border:solid #FF0036;border-width:3px 0 3px 3px}.mallSearch-input{background:#fff;height:30px}#mallSearch #mq{color:#000;margin:0;z-index:2;width:289px;height:20px;line-height:20px;padding:5px 3px 5px 5px;outline:0;border:none;font-weight:900;background:url(data:image/gif;base64,R0lGODlhAQADAJEAAObm5t3d3ff39wAAACH5BAAAAAAALAAAAAABAAMAAAICDFQAOw==) repeat-x;-webkit-box-sizing:content-box;-moz-box-sizing:content-box;box-sizing:content-box}#mallSearch button{position:absolute;right:0;top:0;width:90px;border:0;font-size:16px;letter-spacing:4px;cursor:pointer;color:#fff;background-color:#FF0036;height:30px;overflow:hidden;font-family:'\5FAE\8F6F\96C5\9ED1',arial,"\5b8b\4f53"}#mallSearch .s-combobox{height:30px}#mallSearch .s-combobox .s-combobox-input:focus{outline:0}button::-moz-focus-inner{border:0;padding:0;margin:0}.page-not-market #mallSearch{width:540px!important}.page-not-market #mq{width:439px!important;float: left;}
- /*** uncss> filename: http://localhost:9090/css/test.css ***/#mallSearch{float:none}.page-not-market #mallLogo{width:280px}.header-list-app #mallSearch{width:448px!important}.header-list-app #mq{width:347px!important}@media (min-width:1210px){#header .headerCon,#header .headerLayout,.main{width:1190px!important}.header-list-app #mallSearch{width:597px!important}.header-list-app #mq{width:496px!important}}@media (min-width:600px) and (max-width:800px) and (orientation:portrait){.pg .page{min-width:inherit!important}.pg #mallPage,.pg #mallPage #header{min-width:740px!important}.pg #header .headerCon,.pg #header .headerLayout,.pg .main{width:740px!important}.pg #mallPage #mallLogo{width:260px}.pg #header{min-width:inherit}.pg #mallSearch .mallSearch-input{padding-right:95px}.pg #mallSearch .s-combobox{width:100%!important}.pg #mallPage .header-list-app #mallSearch{width:auto!important}.pg #mallPage .header-list-app #mallSearch #mq{width:100%!important;padding:5px 0 5px 5px}}i{font-style:normal}.main,.page{position:relative}.page{overflow:hidden}@font-face{font-family:tm-list-font;src:url(//at.alicdn.com/t/font_1442456441_338337.eot);src:url(//at.alicdn.com/t/font_1442456441_338337.eot?#iefix) format('embedded-opentype'),url(//at.alicdn.com/t/font_1442456441_338337.woff) format('woff'),url(//at.alicdn.com/t/font_1442456441_338337.ttf) format('truetype'),url(//at.alicdn.com/t/font_1442456441_338337.svg#iconfont) format('svg')}::selection{background:rgba(0,0,0,.1)}*{-webkit-tap-highlight-color:rgba(0,0,0,.3)}b{font-weight:400}.page{background:#fff;min-width:990px}#content{margin:0!important;width:100%!important}.main{margin:auto;width:990px}.main img{-ms-interpolation-mode:bicubic}.fSort i{background:url(//img.alicdn.com/tfs/TB1XClLeAY2gK0jSZFgXXc5OFXa-165-206.png) 9999px 9999px no-repeat}#mallSearch .s-combobox{width:auto}::-ms-clear,::-ms-reveal{display:none}.attrKey{white-space:nowrap;text-overflow:ellipsis}.attrs{border-top:1px solid #E6E2E1}.attrs a{outline:0}.attr{background-color:#F7F5F5;border-color:#E6E2E1 #E6E2E1 #D1CCC7;border-style:solid solid dotted;border-width:0 1px 1px}.attr ul:after,.attr:after{display:block;clear:both;height:0;content:' '}.attrKey{float:left;padding:7px 0 0;width:10%;color:#B0A59F;text-indent:13px}.attrKey{display:block;height:16px;line-height:16px;overflow:hidden}.attrValues{position:relative;float:left;background-color:#FFF;width:90%;padding:4px 0 0;overflow:hidden}.attrValues ul{position:relative;margin-right:105px;margin-left:25px}.attrValues ul.av-collapse{overflow:hidden}.attrValues li{float:left;height:22px;line-height:22px}.attrValues li a{position:relative;color:#806F66;display:inline-block;padding:1px 20px 1px 4px;line-height:20px;height:20px;white-space:nowrap}.attrValues li a:hover{color:#ff0036;text-decoration:none}.brandAttr .attr{border:2px solid #D1CCC7;margin-top:-1px}.brandAttr .attrKey{padding-top:9px}.brandAttr .attrValues{padding-top:6px}.brandAttr .av-collapse{overflow:hidden;max-height:60px}.brandAttr li{margin:0 8px 8px 0}.brandAttr li a{text-overflow:ellipsis;overflow:hidden}.navAttrsForm{position:relative}.relKeyTop{padding:4px 0 0;margin-left:-13px;height:16px;overflow:hidden;width:100%}.relKeyTop li{display:inline-block;border-left:1px solid #ccc;line-height:1.1;padding:0 12px}.relKeyTop li a{color:#999}.relKeyTop li a:hover{color:#ff0036;text-decoration:none}.filter i{display:inline-block;overflow:hidden}.filter{margin:10px 0;padding:5px;position:relative;z-index:10;background:#faf9f9;color:#806f66}.filter i{position:absolute}.filter a{color:#806f66;cursor:pointer}.filter a:hover{color:#ff0036;text-decoration:none}.fSort{float:left;height:22px;line-height:20px;line-height:24px\9;border:1px solid #ccc;background-color:#fff;z-index:10}.fSort{position:relative}.fSort{display:inline-block;margin-left:-1px;overflow:hidden;padding:0 15px 0 5px}.fSort:hover,a.fSort-cur{color:#ff0036;background:#F1EDEC}.fSort i{top:6px;right:5px;width:7px;height:10px;line-height:10px}.fSort .f-ico-arrow-d{background-position:-22px -23px}.fSort-cur .f-ico-arrow-d,.fSort:hover .f-ico-arrow-d{background-position:-30px -23px}i.f-ico-triangle-mb,i.f-ico-triangle-mt{border:4px solid transparent;height:0;width:0}i.f-ico-triangle-mt{border-bottom:4px solid #806F66;top:2px}i.f-ico-triangle-mb{border-top:4px solid #806F66;border-width:3px\9;right:6px\9;top:12px}:root i.f-ico-triangle-mb{border-width:4px\9;right:5px\9}i.f-ico-triangle-mb,i.f-ico-triangle-mt{border:4px solid transparent;height:0;width:0}i.f-ico-triangle-mt{border-bottom:4px solid #806F66;top:2px}i.f-ico-triangle-mb{border-top:4px solid #806F66;border-width:3px\9;right:6px\9;top:12px}:root i.f-ico-triangle-mb{border-width:4px\9;right:5px\9}.view:after{clear:both;content:' '}.productImg,.productPrice em b{vertical-align:middle}.product{position:relative;float:left;padding:0;margin:0 0 20px;line-height:1.5;overflow:visible;z-index:1}.product:hover{overflow:visible;z-index:3;background:#fff}.product-iWrap{position:absolute;background-color:#fff;margin:0;padding:4px 4px 0;font-size:0;border:1px solid #f5f5f5;border-radius:3px}.product-iWrap *{font-size:12px}.product:hover .product-iWrap{height:auto;margin:-3px;border:4px solid #ff0036;border-radius:0;-webkit-transition:border-color .2s ease-in;-moz-transition:border-color .2s ease-in;-ms-transition:border-color .2s ease-in;-o-transition:border-color .2s ease-in;transition:border-color .2s ease-in}.productPrice,.productShop,.productStatus,.productTitle{display:block;overflow:hidden;margin-bottom:3px}.view:after{display:block}.view{margin-top:10px}.view:after{height:0}.productImg-wrap{display:table;table-layout:fixed;height:210px;width:100%;padding:0;margin:0 0 5px}.productImg-wrap a,.productImg-wrap img{max-width:100%;max-height:210px}.productImg{display:table-cell;width:100%;text-align:center}.productImg img{display:block;margin:0 auto}.productPrice{font-family:arial,verdana,sans-serif!important;color:#ff0036;font-size:14px;height:30px;line-height:30px;margin:0 0 5px;letter-spacing:normal;overflow:inherit!important;white-space:nowrap}.productPrice *{height:30px}.productPrice em{float:left;font-family:arial;font-weight:400;font-size:20px;color:#ff0036}.productPrice em b{margin-right:2px;font-weight:700;font-size:14px}.productTitle{display:block;color:#666;height:14px;line-height:12px;margin-bottom:3px;word-break:break-all;font-size:0;position:relative}.productTitle *{font-size:12px;font-family:\5FAE\8F6F\96C5\9ED1;line-height:14px}.productTitle a{color:#333}.productTitle a:hover{color:#ff0036!important}.productTitle a:visited{color:#551A8B!important}.product:hover .productTitle{height:14px}.productShop{position:relative;height:22px;line-height:20px;margin-bottom:5px;color:#999;white-space:nowrap;overflow:visible}.productStatus{position:relative;height:32px;border:none;border-top:1px solid #eee;margin-bottom:0;color:#999}.productStatus span{float:left;display:inline-block;border-right:1px solid #eee;width:39%;padding:10px 1px;margin-right:6px;line-height:12px;text-align:left;white-space:nowrap}.productStatus a,.productStatus em{margin-top:-8px;font-family:arial;font-size:12px;font-weight:700}.productStatus em{color:#b57c5b}.productStatus a{color:#38b}.productImg-wrap{position:relative}.product-iWrap{min-height:98%;width:210px}.view{padding-left:5px;padding-right:5px}.view{width:1023px}.view .product{width:220px;margin-right:33px}@media (min-width:1210px){.view{width:1210px;padding-left:5px;padding-right:5px}.view .product{width:220px;margin-right:20px}}@media (min-width:600px) and (max-width:800px) and (orientation:portrait){.view{width:775px;padding-left:5px;padding-right:5px}.view .product{width:220px;margin-right:35px}}.product{height:372px}.grid-nosku .product{height:333px}
- style>


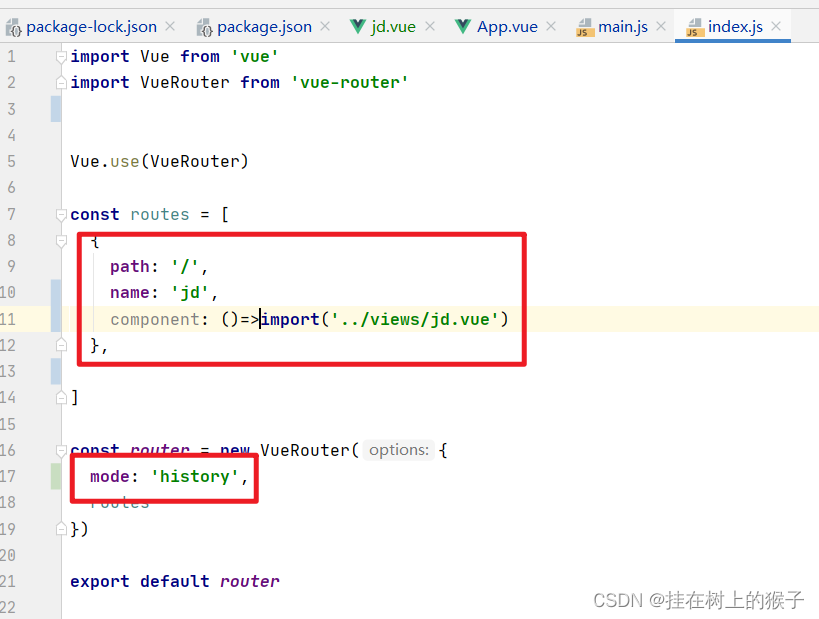
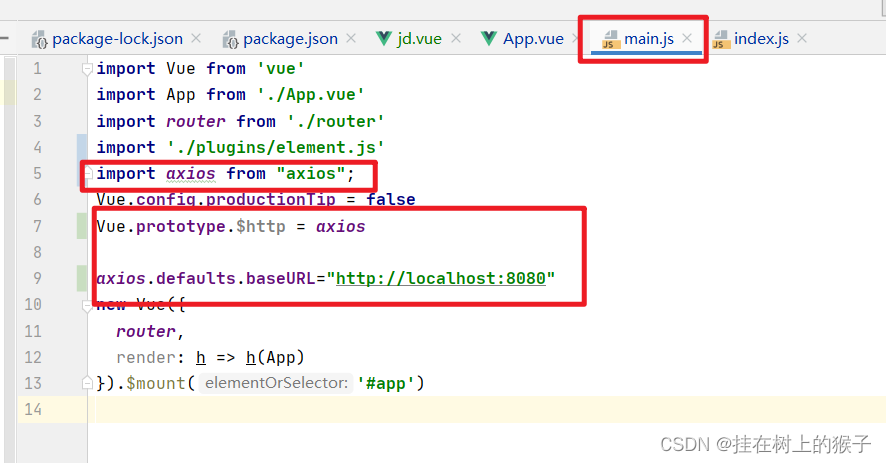
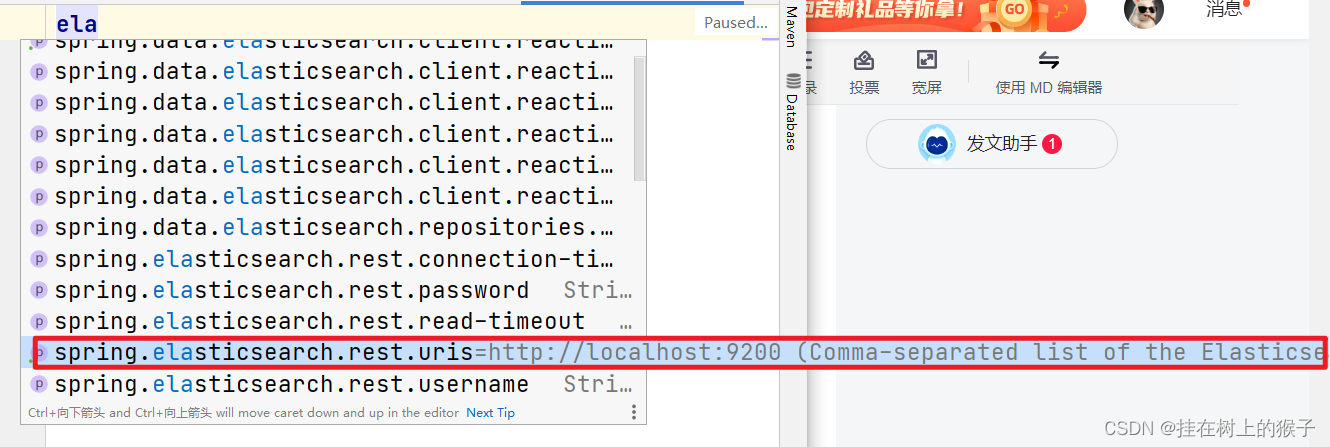
这里没有ES配置文件,因为有默认值
Docker学习笔记
c++无痛实现日期类
金蝶云星空生产管理(冲刺学习)
JavaWeb项目(登录注册页面)全过程详细总结
LeetCode34 在排序数组中寻找元素的第一个和最后一个位置
laravel框架介绍(一)
Linux之虚拟主机功能
Vue中使用pdf.js实现在线预览pdf文件流
anaconda环境更改gcc版本并编译Pytorch3D 0.4.0