-
Hadoop系列(一)Hadoop全分布式集群环境搭建
0.准备工作
0.0 准备三台虚拟主机
可以不用直接准备三台,可以先配置一台,然后使用vmware再克隆两台出来,克隆之后要修改他们的“ifcfg-ens-xxx”的网卡配置文件,确保三台主机ip不同。
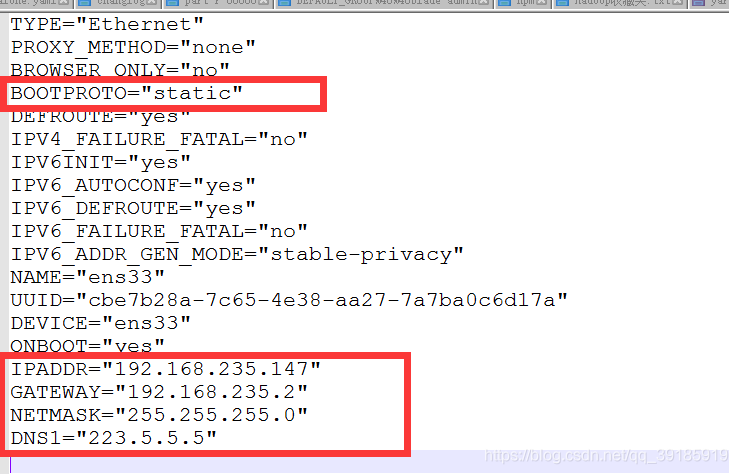
0.1固定ip地址,卸载或禁用防火墙。
修改ifcfg-ens-xxx的网卡配置文件,根据实际情况自行修改
0.2配置主机与宿主机时间同步
如果是三台物理机,可以跳过这个步骤
0.2.1方式一:安装ntp服务(推荐)
yum install -y ntpdate cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ntpdate -u ntp.api.bz- 1
- 2
- 3
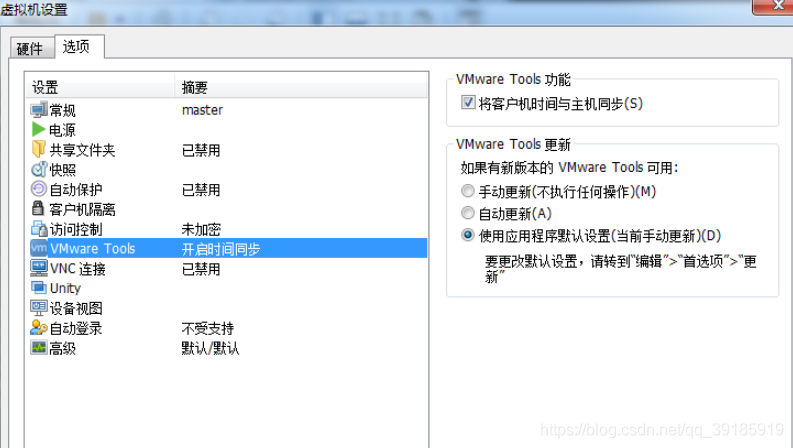
0.2.2方式二:通过设置vmware设置虚拟机时间同步
0.3 安装java环境
直接通过yum安装,可以不用配置环境变量,因为hadoop中需要配置JAVA_HOME的绝对路径,因为使用全局环境变量hadoop可能依然找不到JAVA_HOME
命令:
yum search java | grep -i --color jdk //查看jdk列表 yum install -y java-1.8.0-openjdk* //安装jdk1.8的所有文件- 1
- 2
jdk默认安装路径在/usr/lib/jvm目录中。这个路径后边要用到,需要将绝对路径配置在hadoop以及其生态系统中的其他组件的环境变量配置文件中
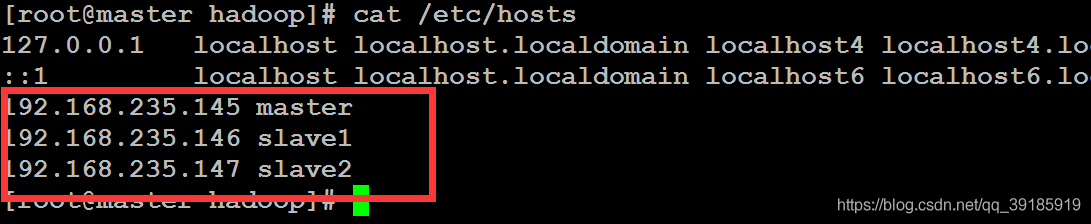
0.4 配置三台主机的hosts文件
命令:
vim /etc/hosts- 1
添加如下配置
# master为主机,其他两个为从机,注意替换成自己的ip地址。 192.168.235.145 master 192.168.235.146 slave1 192.168.235.147 slave2- 1
- 2
- 3
- 4
0.5设置三台主机的ssh互信
0.5.1配置master主机免秘钥登录
命令:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys- 1
- 2
- 3
0.5.2 将公钥发送给其他两台从机
## ssh-copy-id 用户名@机器名 ssh-copy-id root@slave1 ssh-copy-id root@slave2- 1
- 2
- 3
其他两台从机做同样的操作,将公钥发送给另外两台机器。我这里统一使用root用户操作。
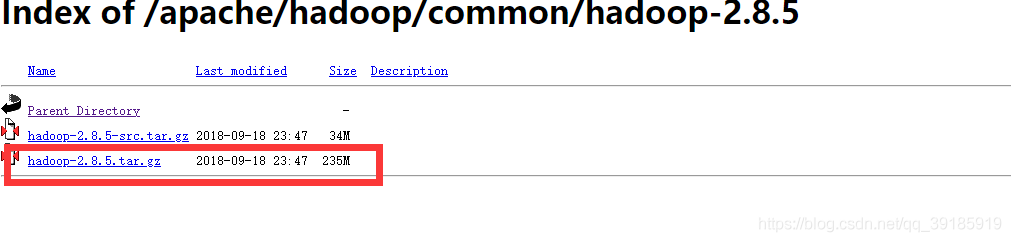
1.Apache官网,下载hadoop镜像资源
hadoop官网地址,建议下载hadop-2.x版本,因为hadoop-2.x对hbase的支持更好,我这里下载hadoop-2.8.5
2.上传服务器指定目录,(如:/usr/local/hadoop)解压下载的镜像压缩包
命令:
tar -xzvf hadoop-2.8.5.tar.gz- 1
解压后的目录名称为hadoop-3.3.0,重命名
mv hadoop-2.8.5 hadoop285- 1
3.修改hadoop330/etc/hadoop下的环境配置文件
包含以下三种:
hadoop-env.sh
yarn-env.sh
mapred-env.sh(可选)
在配置文件中设置本机的JAVA_HOME路径为绝对路径,有则修改替换,没有则添加,如下:
# 添加set to the root of your Java installation export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64- 1
- 2
对应配置文件在/hadoop/hadoop安装/txt/hadoop-env.sh,可修改路径之后,直接覆盖服务器上的其他类似
4.修改四个必要的配置文件
根据官网的描述,hadoop的Java配置有两种重要的配置文件,分别是:
只读配置
core-default.xml
hdfs-default.xml
yarn-default.xml
mapred-default.xml
特定站点的配置
etc/hadoop/core-site.xml
etc/hadoop/hdfs-site.xml
etc/hadoop/yarn-site.xml
etc/hadoop/mapred-site.xml
只读配置不用管,修改后面这四个配置文件
4.1core-site.xml
fs.defaultFS hdfs://master:9000 hadoop.tmp.dir /usr/local/hadoop/tmp - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4.2hdfs-site.xml
dfs.name.dir /usr/local/hadoop/hadoop285/tmp/dfs/name dfs.data.dir /usr/local/hadoop/hadoop330/tmp/dfs/data dfs.replication 2 dfs.permissions.enabled false dfs.datanode.max.xcievers 4096 Datanode 有一个同时处理文件的上限,至少要有4096 dfs.namenode.secondary.http-address master:9001 dfs.webhdfs.enabled true - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
4.3yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 86400 yarn.resourcemanager.address master:8032 yarn.resourcemanager.scheduler.address master:8030 yarn.resourcemanager.resource-tracker.address master:8031 yarn.resourcemanager.admin.address master:8033 yarn.resourcemanager.webapp.address master:8088 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
4.4mapred-site.xml
mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
5.列出主机所有的从机
hadoop中,除了主机以外的其他服务器被称作员工,这里主要在etc/hadoop下的slaves文件中列出所有的工人,也就是之前在服务器hosts文件中设置的三台主机的ip地址+名称。这里只需列出从机名称即可。
在slaves文件中进行如下配置:

默认会有一行localhost的配置,建议删除。6.添加hadoop到全局环境变量
添加环境变量的目的是为了上系统识别hadoop命令
编辑 ~/.bashrc配置文件
vim ~/.bashrc- 1
添加环境变量HADOOP_HOME指定hadoop的安装目录
export HADOOP_HOME=/usr/local/hadoop/hadoop277 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"- 1
- 2
- 3
追加PATH变量
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:- 1
使环境生效
source ~/.bashrc- 1
测试hadoop命令,查看版本
hadoop version- 1

7.分发配置
完成所有必要配置之后,将文件分发给其他服务器
可以利用scp命令进行文件分发。
命令:
# scp -r 本地目录 用户名@从机名称:远程目录 scp -r /usr/local/hadoop/hadoop285 root@slave1:/usr/local/hadoop scp -r /usr/local/hadoop/hadoop285 root@slave2:/usr/local/hadoop- 1
- 2
- 3
7.1 同步Haddop全局环境变量
这里需要三台机器都具有Hadoop的环境变量,建议每个都配置一遍,因为通过
scp命令分发的话可能会覆盖从机原来的环境变量
添加环境变量同第5步一致。
8.启动集群
启动集群之前首先要在主节点对HDFS进行格式化,这里是在配置了三台机器
ssh可信访问的情况下可以使用如下命令进行格式化,如果没有配置ssh可信访问,使用官网提供的方式进行格式化
命令:
hadoop namenode -format- 1
启动,也可以分开依次启动start-dfs.sh和start-yarn.sh
./start-all.sh- 1
可能会出现以下错误,没有错误就跳过此步骤
因为我安装了三个版本的hadoop,分别是hadoop-3.3.0、hadoop-2.7.7和
hadoop-2.8.5,这个错误是3.x版本才有的。最终整理出来的文档是2.8.5版本的。
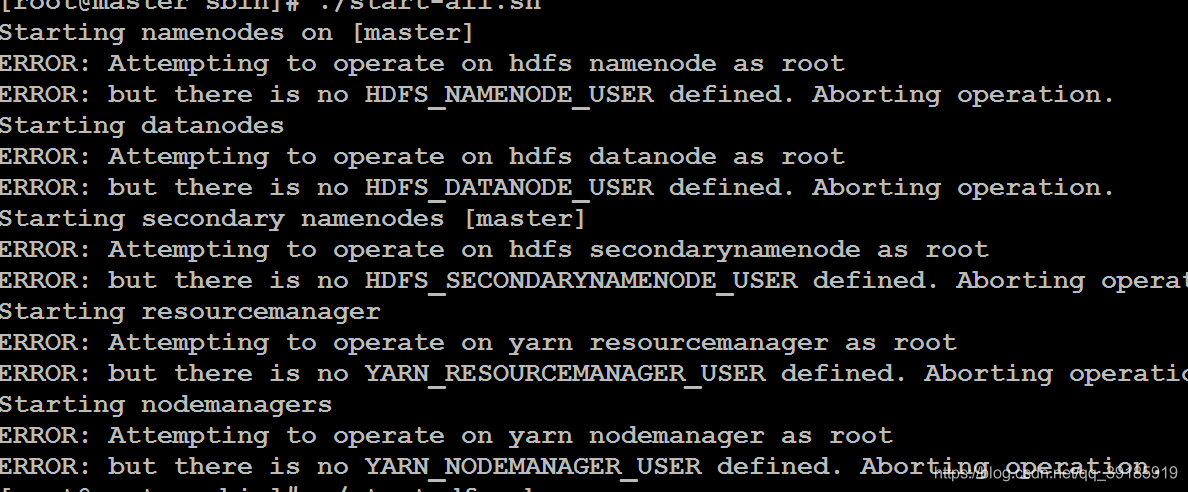
翻译过来是,“尝试以root用户操作hdfs namenode结点,但是
HDFS_NAMENODE_USER并未定义为root”,之前并没遇到过这种错误。网上
查找的解决办法,修改一下配置文件。
需要修改四个启动/停止文件
start-dfs.sh和stop-dfs.sh添加如下配置
#!/usr/bin/env bash HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root- 1
- 2
- 3
- 4
- 5
start-yarn.sh和stop-yarn.sh添加如下配置
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root- 1
- 2
- 3
- 4
重新启动
./start-all.sh- 1
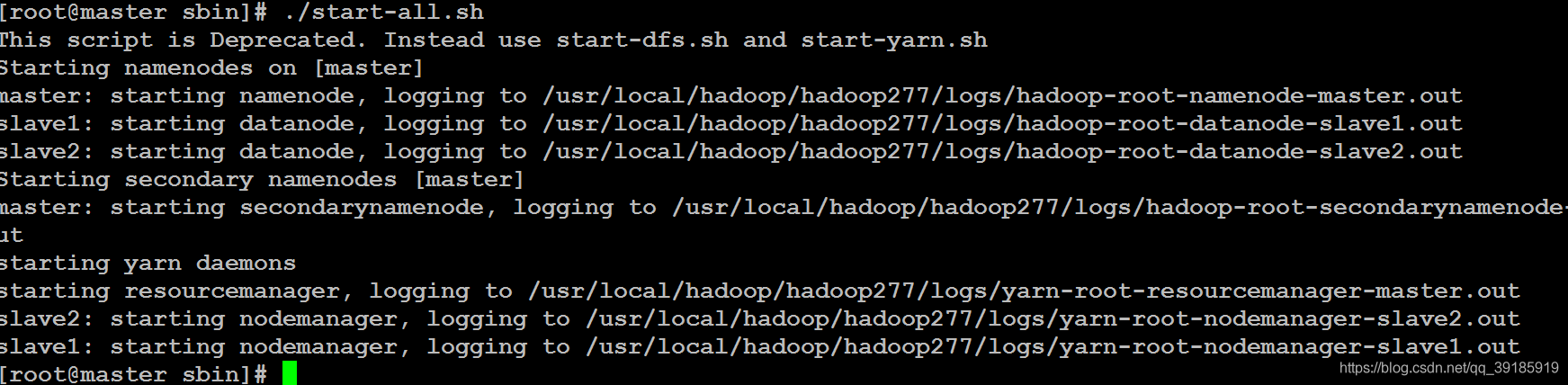
启动成功
访问hdfs文件系统默认端口是50070,hdoop-3.x之后,默认端口为9870
主机ip+50700即可访问
9.测试hadoop自带mapreduce实例
9.1 在本地创建三个文件,写入内容
f1.txt 内容:hello world
f2.txt 内容:hello brother
f3.txt 内容:hello world,mybrother
这个文件目录自定义,我的目录地址在/usr/local/hadoop/test
9.2 将三个文件上传进hdfs文件系统
命令:
#hdfs dfs -put 文件的目录 输出值hdfs文件系统的目录,我这里已经进入/usr/local/hadoop,否则需要写绝对路径 hdfs dfs -put test/ /test- 1
- 2
执行mapreduce,这里要注意jar包的名称要保持一致
#其中末尾的/test hdfs文件系统中的三个文件的路径 /output是结果输出的路径 hadoop jar /usr/local/hadoop/hadoop285/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /test /output- 1
- 2
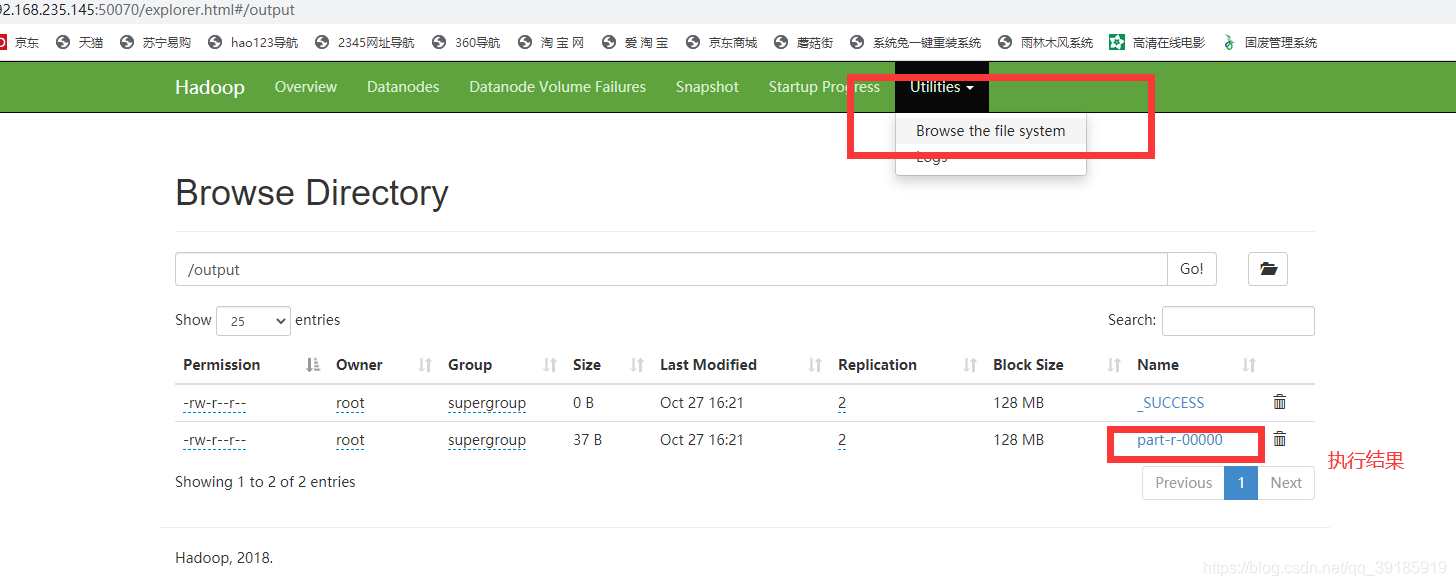
执行结果

出现INFO mapreduce.Job: map 100% reduce 100%- 1
说明执行成功,去文件系统查看日志,需要下载查看词频统计结果
文件系统访问路径在第8步末尾

10.常见问题汇总
10.1:Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : 错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
这个错误是在yarn-site.xml配置文件中没有指定classpath导致程序找不到主类,无法加载。
解决办法:执行
hadoop classpath- 1
yarn-site.xml文件中添加配置
yarn.application.classpath 【hadoop classpath命令输出的结果粘贴至此处】 - 1
- 2
- 3
- 4
然后重启hadoop,建议修改配置之前就把hadoop停止。
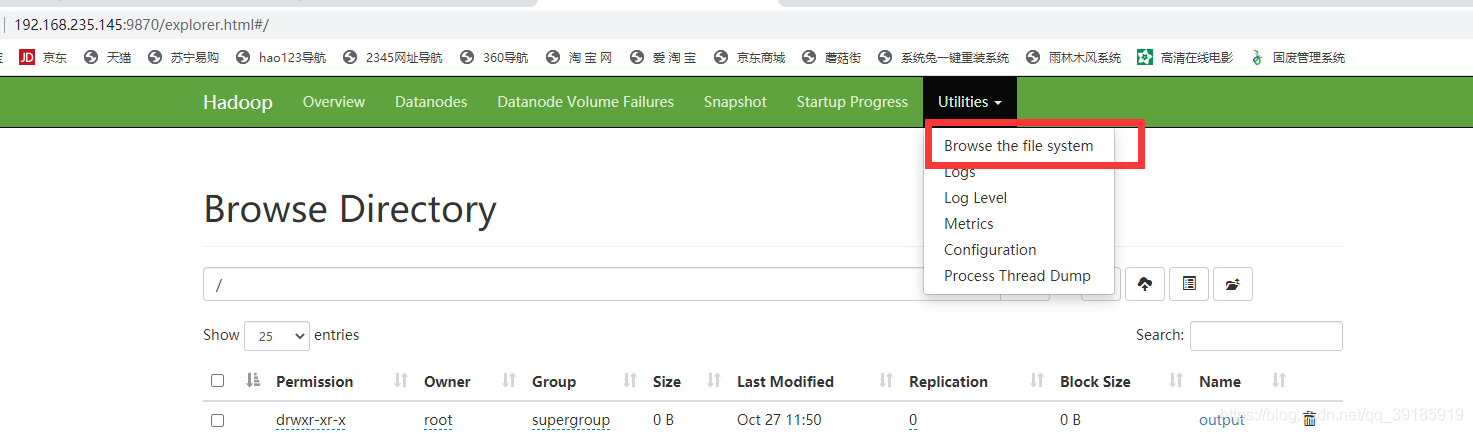
10.2:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/output already exists
这个错误是在hdfs文件系统中,该目录(Output)已经存在,所以在执行命令时,必须选择一个没有创建过的目录
解决办法:
1.更换一个新的目录2.通过浏览器把hdfs中的该目录删除,hdfs文件浏览器地址:
10.3:org.apache.hadoop.hdfs.server.common.IncorrectVersionException: Unexpected version of storage directory /usr/local/hadoop/tmp/dfs/namesecondary. Reported: -65. Expecting = -63.
这个错误,不太常见,涉及到两个配置dfs.name.dir和hadoop.tmp.dir,分别在hdfs-site.xml和core-site.xml文件中这个错误导致SecondaryNameNode一致无法启动成功,所以在查看jps是看不到SecondaryNameNode。因为我重复安装了不同版本导致的,如果第一次安装应该不会有这种错误。
hdfs-site.xml
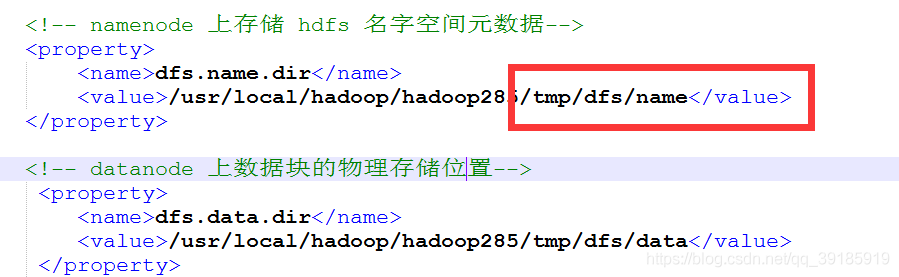
core-site.xml

他们俩最里边都有一个VERSION文件,里边声明了版本,如果两个版本不一致,就会这种错误。
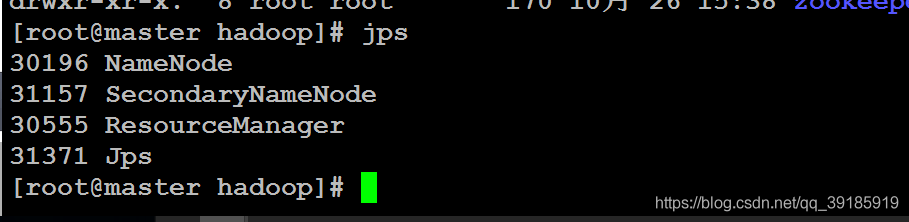
解决办法,把这俩文件全删了,两个从机也要删。重新格式化hdfs,格式化命令参考第8步启动集群。然后就可以了。
jps查看,SecondaryNameNode启动成功
-
相关阅读:
排序算法(1)
古人会“温酒”,为什么当代人喝酒不烫了?喝酒伤肝如何缓解?
5.Array扩展
什么是缓存架构,什么是后端分布式多级缓存架构,全文解析带你了解其中门道
Docker-compose部署XWiki
mybatis入门
webpack原理篇(五十八):实战开发一个简易的webpack
程序流程控制
NPM 使用入门
一位3年经验的测试工程师水平能差到什么程度?面试后,感叹都是人才呀...
- 原文地址:https://blog.csdn.net/m0_67393828/article/details/126371324

